1. Pandas
데이터 전처리
구조화된 데이터의 처리를 지원하는 python 라이브러리
python계의 엑셀이라고 생각하면 된다.
- 특징
고성능 Array 계산 라이브러리인 Numpy와 통합하여 강력한 스프레드시트 처리 기능 제공
인덱싱, 연산용 함수, 전처리 함수 등을 제공
#라이브러리 호출
import pandas as pd
#Data URL
data_url = 'https://...'
# data가 csv 타입 일 때 데이터 가져오는 방법
# seperate(데이터 나누는 기준) : 빈공간으로 지정
# header : 첫 칸에 column 이름이 없는 데이터 가져온다.
df_data = pd.read_csv(data_url, sep='\s+', header = None2. Pandas의 구성
Series object들이 모여 하나의 DataFrame을 만든다.
Series는 numpy의 subclass이다.
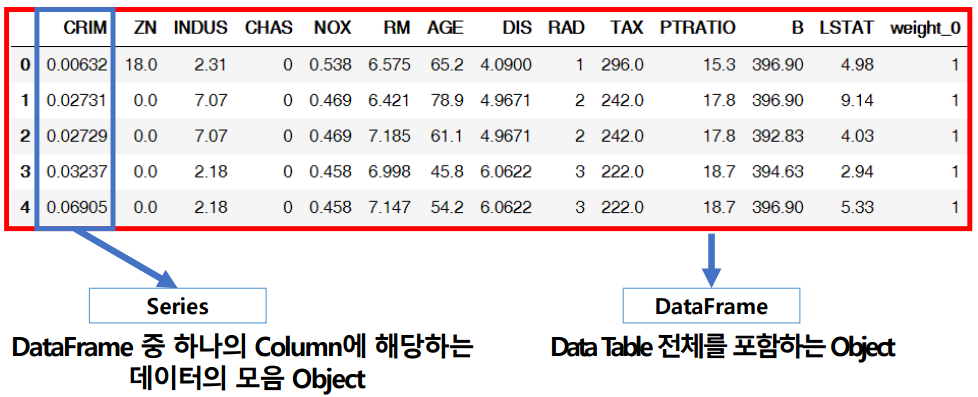
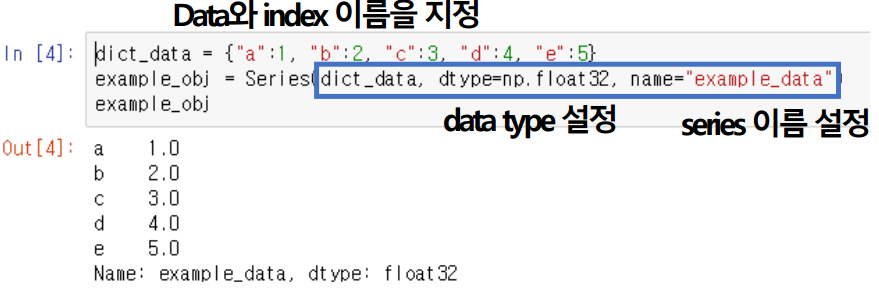
- Series
인덱스와 data가 같이 출력되는 형태from pandas import Series, DataFrame list_data = [1,2,3,4,5] example_obj = Series(data = list_data) print(example_obj)
-
Data Frame
2차원 matrix라고 가정한다.
👉 row, column 값을 알면 data를 찾아낼 수 있다.DataFrame(raw_data, columns = ["age","city"]) #value: age와 city의 column data 선택 DataFrame(raw_data, columns=["first_name","last_name","age","city","debt"]) #value: debt라는 새로운 column 추가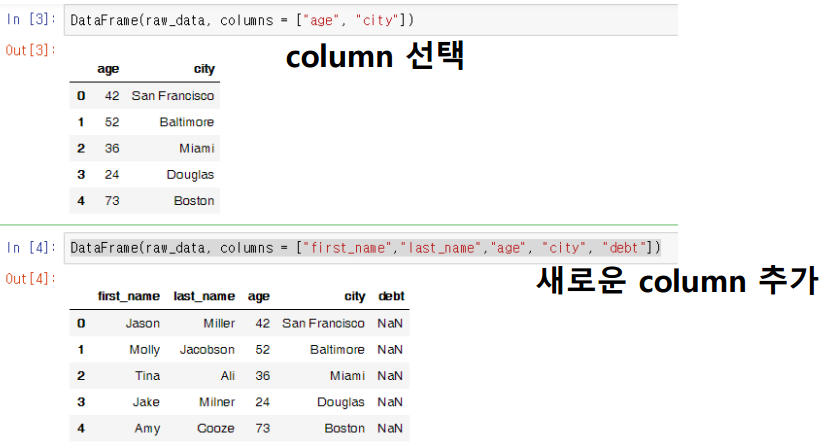
df = DataFrame(raw_data, columns=["first_name","last_name","age","city","debt"]) df.first_name df.["first_name"] # 둘다 같은 방식 # value: first_name이름을 가진 column 선택(series로 추출)
1) loc
index location 인덱스의 이름으로 가져온다

df.loc[1]
#value: 인덱스가 1인 Molly의 정보를 가져온다.2) iloc
index position 인덱스의 위치를 선택
df["age"].iloc[1:]
#df["age"] : series 형태로 데이터 출력
#value: age column의 값들을 series 데이터 형태로 추출3) Column에 새로운 data 할당

age>40 일때, 값을 true or false로 반환하고 반환된 값을 새로 debt에 할당.
4) Column을 삭제
debt column 삭제
del df["debt"]3. Selection & Drop
Nonpy에서 indexing과 비슷
-
한개의 column 선택시
account column에 있는 data 중 3개의 값을 가져온다.
하나의 series data를 가져올 때 사용
series 객체를 가져온다.

-
1개 이상의 column 선택
여러개의 column을 가져올 때 사용
dataframe 객체를 가져온다.

-
row 선택
row index를 기준으로 값을 가져온다.
df[:3]
df["account(칼럼명)"][:3]- index 변경
기본 index(0,1,2,3..)를 identity한 값으로 바꿔준다.ex)학번, 주민번호
df.index = df["account"] #account값이 index로 들어간다.
del.df["account"] #account가 중복되기 때문에 column 삭제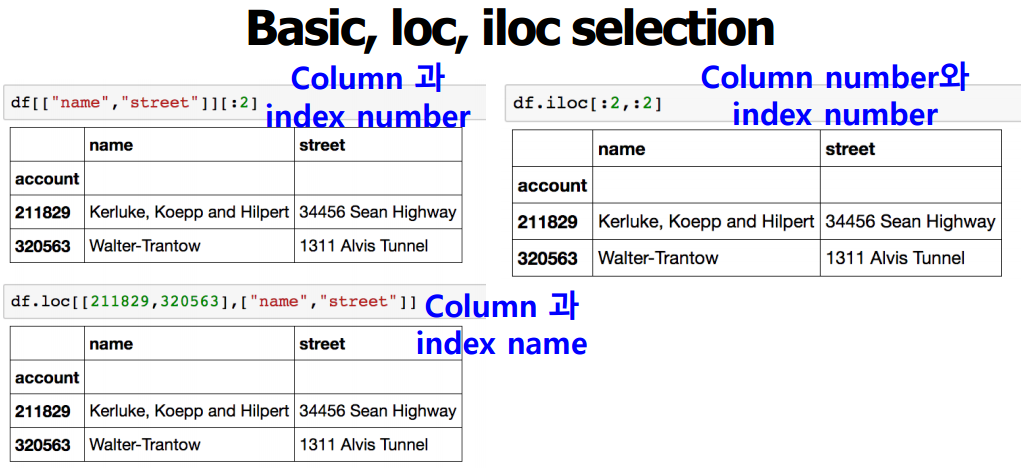 df.drop(1) : index number로 drop(row drop방식)
df.drop(1) : index number로 drop(row drop방식)
✔ data를 drop해도 원본데이터는 남아있다.
4. Dataframe Operations
-
Series Operation
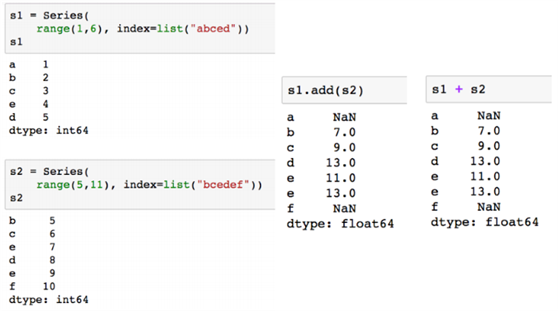 인덱스의 이름이 같은 것 끼리 더해준다.
인덱스의 이름이 같은 것 끼리 더해준다.
한쪽이라도 인덱스가 존재하지 않을 시 NaN값으로 반환된다. -
Dataframe Operation
 fill_value=0 : non값을 없애주기 위해
fill_value=0 : non값을 없애주기 위해
5. Lambda, map, apply(실용적)
-
map 함수
각 element마다 입력받은 함수를 적용하여 list로 반환
map(function/dict, sequence)
딕트타입으로 map 변환 가장 많이 사용

 👉 df.set.map({"male":0 "female":1}) 문자를 숫자로 바꿔준다
👉 df.set.map({"male":0 "female":1}) 문자를 숫자로 바꿔준다
sex male → sex_code 0
sex female → sex_code

-
apply for dataframe
column 전체, dataframe 전체에 있는 통계값 뽑을 때 가장 많이 사용
 earn, height, age 각 column에 대한 평균값을 가진다
earn, height, age 각 column에 대한 평균값을 가진다
