1. 수치형 연속형 데이터 구간 나누기
1) 수치형 범위 설정
"""
Description:
pd.cut(x=Series,
bins=[나눌구간범위],
labels=['범위별 이름'])
"""
tp_series = pd.Series([1,56,23,41,33,10])
pd.cut(x=tp_series,
bins=[0,10,20,30,40,50, np.inf],
labels=['1~10','11~20','21~30','31~40','41~50','50이상'])2) 특정 수치만을 포함한 범위 설정
"""
Description:
tp_series = [1,56,23,41,33,10] 일 때,
pd.cut() : [1, 50이상, 21~30, 41~50, 31~40, 1~10]
"""
cut_df = pd.cut(x=tp_series,
bins=[-np.inf, 0, 1, 10, 20, 30, 40, 50, np.inf],
labels=['0이하', '1', '1~10', '11~20', '31~40', '41~50', '50이상'])2. barplot에 수치 표기
def add_value_label(x_list, y_list):
for i in range(1, len(x_list)+1):
plt.text(x=i-1,
y=y_list[i-1]/2,
s=f'{bar에 들어갈 수치}%',
ha='center')
plt.figure(figsize=(10,5)),
x_list = cut_df.value_counts().sort_index().index
y_list = cut_df.value_counts().sort_index().values
plt.bar(
x=x_list,
height=y_list,
color='light_gray'
)
add_value_label(x_list, y_list)
plt.title('barplot제목')
plt.xticks(rotation=45)
plt.show()3. 한글 깨짐 현상
3-1) mac 기본 font 경로
~/library/Fonts/
3-2) 로컬 환경에 있는 한글파일.ttf 파일을 docker 컨테이너 내부에 복사
docker cp \
/...폰트경로/NanumGothic.ttf \
컨테이너명:/....폰트를 넣을 경로/- 로컬에 있는 /...폰트경로/NanumGothic.ttf 파일이 docker container안에 ....폰트를 넣을 경로/로 .ttf 파일 복사
3-3) 한글 설정 후 시각화
# 한글 설정
import matplotlib.pyplot as plt
import matplotlib as mpl
from matplotlib import rc, font_manager
font_fname = '/.....폰트경로/NanumGothic.ttf'
prop = font_manager.FontProperties(fname=font_fname)
mpl.rcParams['font.family'] = 'NanumGothic'
mpl.rcParams['axes.unicode_minus'] = False
font_manager._rebuild() # 캐시 삭제✔️ 캐시 삭제 처리가 안될 경우 : 캐시 경로(컨테이터 내부 root/.cache)에서 직접 삭제 후 rebuild()
4. 그래프를 한번에 모아서 그리기
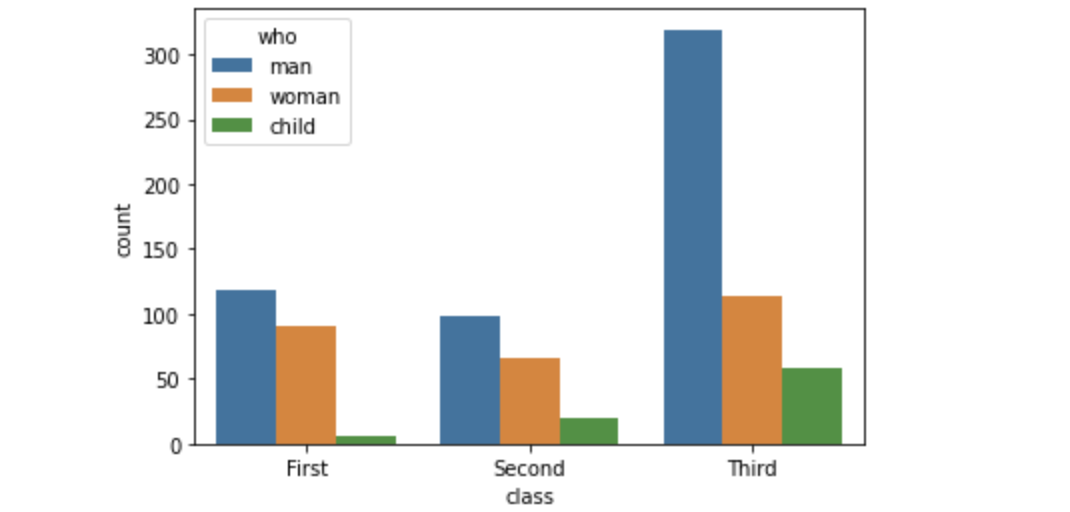 위 그림의 형식처럼 세가지 class를 가진 그래프로 나타내기
위 그림의 형식처럼 세가지 class를 가진 그래프로 나타내기
1) pd.melt
- melt :
"""
Description:
(AS-IS)
| index_id | column1 | column2 | column3 | ...
|----------|---------|---------|---------| ...
| 'a' | 1 | 3 | 7 | ...
| 'b' | 10 | 30 | 70 | ...
| 'c' | 100 | 300 | 700 | ...
(TO-BE)
| index_id | variable | value |
| 'a' | 'column1' | 1 |
| 'b' | 'column1' | 10 |
| 'c' | 'column1' | 100 |
| 'a' | 'column2' | 3 |
| 'b' | 'column2' | 30 |
| 'c' | 'column2' | 300 |
| 'a' | 'column3' | 7 |
| 'b' | 'column3' | 70 |
| 'c' | 'column3' | 700 |
"""
melt_df = pd.melt(df,
id_vars='index_id',
value_vars=[col for col in df.columns][1:])2) 시각화
import seaborn as sns
plt.figure(figsize=(10,5))
ax = sns.barplot(x='index_id',
y='value',
data=melt_df,
hue='variable')- x축에 'a', 'b', 'c'(index_id) 값이 있고
- x축 중 하나의 class에는 variable 값(column1, column2, column3)이 하나의 그룹으로 존재
- 즉 variable이 범례가 됨.

Data Engineer