MySQL의 스토리지 엔진 중 기본적으로 가장 많이 사용되는 엔진은 InnoDB 이다.
InnoDB는 MySQL의 스토리지 엔진 중 거의 유일하게 레코드 기반의 잠금을 제공하며, 그 때문에 높은 동시성 처리가 가능하고 안정적이며 성능이 뛰어나다.
InnoDB 아키텍처 및 특징
프라이머리 키에 의한 클러스터링
클러스터링이란 여러 개를 하나로 묶는다는 의미이다.
클러스터링 인덱스(키)는 인덱스(키) 값이 비슷한 레코드끼리 묶어서 저장하는 형태를 의미한다. (공간적 지역성)
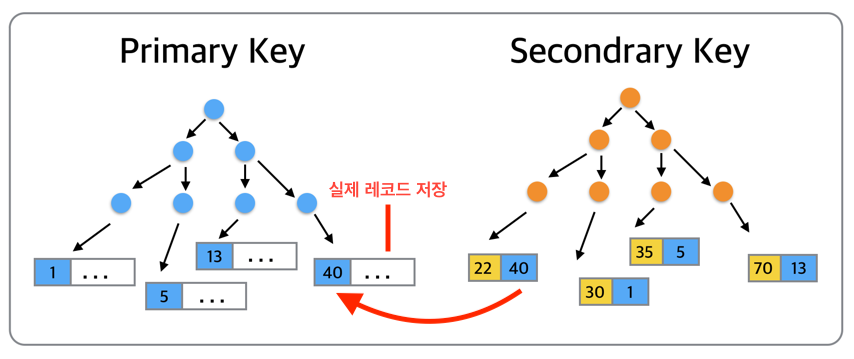
InnoDB의 모든 테이블은 PK를 기준으로 클러스터링 되어 저장된다.
즉, PK 값에 의해 실제 레코드의 물리적 저장 위치가 결정된다.
반면, 세컨더리 키는 실제 레코드의 주소가 아닌 PK를 참조한다.
클러스터링 인덱스의 장단점
장점
-
PK(클러스터링 키)로 검색할 때 처리 성능이 매우 빠름(특히, PK에 의한 범위 검색)
-
모든 세컨더리 인덱스가 PK를 가지고 있기 때문에, 인덱스 만으로 처리될 수 있는 경우가 많음. (커버링 인덱스)
단점
-
PK 값이 클 경우, 모든 세컨더리 인덱스 저장 공간이 커짐
-
세컨더리 인덱스를 통해 검색할 때, PK 를 통해 다시 한 번 검색해야함
-
INSERT 할 때, PK 값에 의해 레코드 저장 위치가 결정되므로 처리 성능이 느림
-
PK 변경 시(잘 일어나진 않지만) 레코드를 DELETE 하고 INSERT 해야하므로 처리 성능이 느림
커버링 인덱스란, 인덱스만으로 필요한 데이터를 가져올 수 있는 인덱스를 의미한다. 만약 age에 인덱스가 걸려있고, age > 30 이상인 모든 유저의 PK를 알고 싶다면, InnoDB는 age 인덱스가 PK를 참조하므로 실제 데이터가 있는 테이블을 조회하지 않아도 된다.
클러스터링 인덱스의 장점은 빠른 읽기(SELECT)이며, 단점은 느린 쓰기(INSERT, UPDATE, DELETE)라는 것을 알 수 있다.
일반적인 웹 서비스는 읽기와 쓰기의 비율이 8:2 혹은 9:1 정도이기 때문에 조금 느린 쓰기를 감수하고 읽기를 빠르게 유지하는 것이 좋다고 한다.
InnoDB와 달리 MyISAM 엔진은 클러스터링 키를 지원하지 않으며, 모든 인덱스는 물리적인 레코드의 주소 값(ROWID)를 가진다.
외래 키(FK) 지원
MyISAM, MEMORY 스토리지 엔진과 달리 InnoDB는 외래 키를 지원한다.
외래 키는 부모와 자식 테이블 모두 해당 칼럼에 인덱스 생성이 필요하고, 변경 시 잠금이 여러 테이블로 전파되므로 데드락 발생을 유념해야 한다.
MVCC(Multi Version Concurrency Control)
MVCC는 레코드 레벨의 트랜잭션을 지원하는 DBMS가 제공하는 기능이며, 가장 큰 목적은 잠금을 사용하지 않는 일관된 읽기를 제공하는 것이다.
하나의 레코드에 대해 여러 버전이 동시에 관리되며,
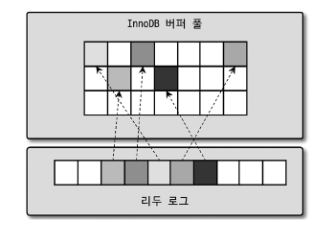
InnoDB는 InnoDB 버퍼풀과 Undo Log를 사용하여 이를 구현한다.
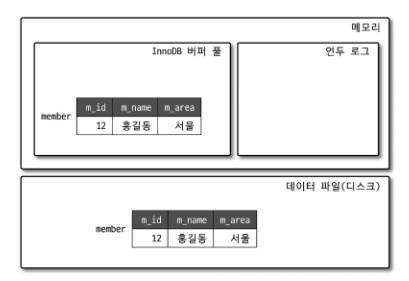
위와 같이 INSERT 문이 실행된 이후의 상황에서, 버퍼 풀에 있는 특정 레코드를 업데이트 한다면 어떻게 될까? (m_area 서울 -> 경기)
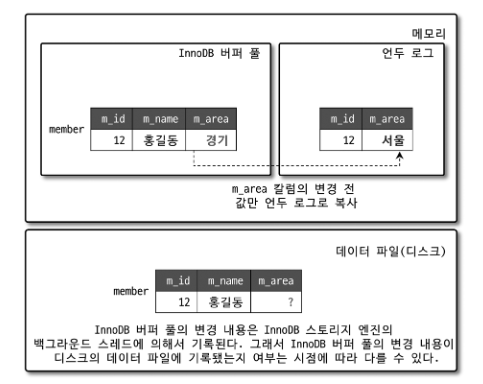
UPDATE가 실행되면, 커밋 여부와 관계없이 버퍼 풀의 데이터를 즉시 수정하고, 언두 로그에 변경 이전 값을 복사한다.
만약 커밋이 일어나기 전에 다른 트랜잭션에서 레코드를 조회하면,
READ_UNCOMMITTED 격리 수준에서는 버퍼 풀에 있는 값을,
READ_COMMITTED, REPEATABLE_READ, SERIALIZABLE 에서는 아직 커밋되지 않았기 때문에, 변경 이전인 언두 로그에서 값을 읽어서 반환한다.
잠금 없는 일관된 읽기
트랜잭션 격리수준을 보장하기 위해 락을 활용하는 기법들이 있지만, 동시성 처리 성능이 떨어진다.
InnoDB에서 READ_COMMITTED, REPEATABLE_READ 수준의 읽기 작업은 잠금을 대기하지 않고 곧바로 실행되기 때문에 동시 처리 성능이 뛰어나다.
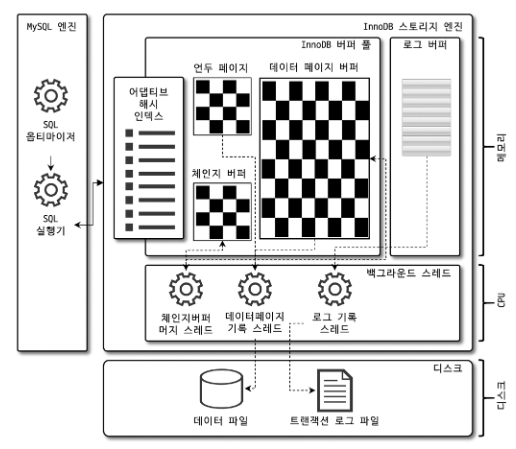
InnoDB 버퍼 풀
이점
InnoDB 버퍼 풀은 디스크의 데이터 파일이나 인덱스 정보를 메모리에 캐시해 두는 공간이다. 쓰기 작업을 지연시켜 일괄 작업으로 처리할 수 있게 해주는 버퍼 역할도 같이 한다.
쓰기 작업의 지연은 어떤 이점을 가져올까?
Data Access Patterns
디스크에 저장된 데이터에 접근하는 패턴은 Random과 Sequential이 있다.

HDD와 같은 저장장치에서 Random Access는 데이터가 존재하는 위치로 헤더가 물리적으로 이동하는데 시간이 소모된다.
반면 Sequential Access는 마지막으로 헤더가 움직인 위치에 지속적으로 데이터를 쓰기 때문에, 헤더가 움직이는 물리적 시간이 소모되지 않는다.
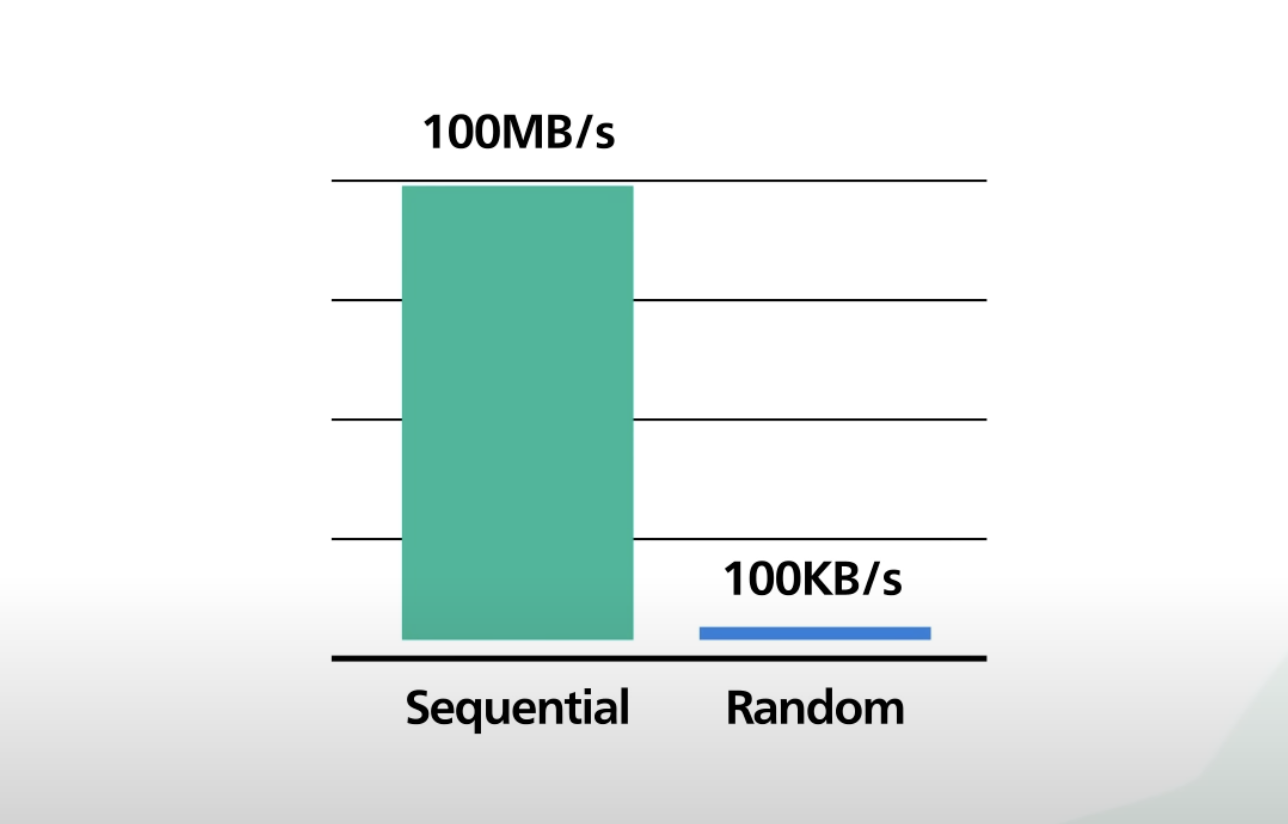
System Design: Why is Kafka fast? 에 따르면 두 패턴은 성능에 엄청난 차이를 보인다.
일반적인 애플리케이션에서는 INSERT, UPDATE, DELETE 처럼 데이터를 변경하는 쿼리는 데이터 파일의 이곳저곳에 위치한 레코드를 변경하기 때문에 Random Access 작업을 발생시킨다.
InnoDB 버퍼 풀과 쓰기 지연을 통해 이러한 Random Access를 모아서 처리하면 그 횟수를 줄여 성능이 개선된다.
버퍼 풀과 리두 로그