대규모시스템설계(1)- MySQL Query Plan, 쿼리 튜닝
Article 테이블
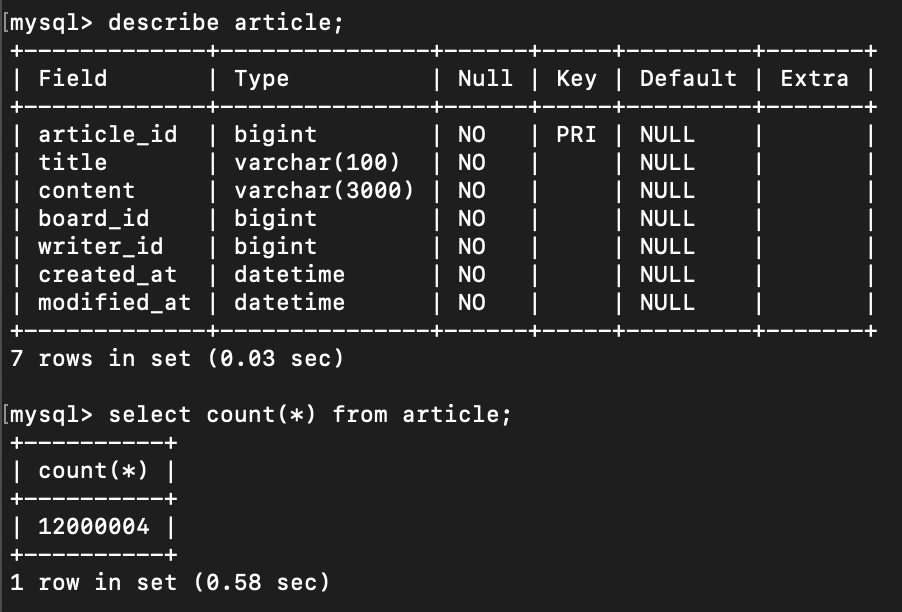
게시글 정보를 담는 article 테이블에 약 1200만건의 데이터를 삽입하였다.
분산 데이터베이스 환경(샤딩)을 고려하여 FK는 설정하지 않았다.(board_id, writer_id)
QueryPlan을 확인하고, 인덱스를 설정하는 등 테스트를 진행하며 성능을 개선해보자.
페이징 구현
특정 게시판의 N번 페이지에서 M개의 게시글을 불러오는 쿼리는 아래와 같다. (최신순 정렬)
select * from article
where board_id = {board_id}
order by created_at desc
limit M offset (N-1) * M위 쿼리 그대로 4번 페이지에서 30개의 게시글을 조회했다.
페이지 조회 결과
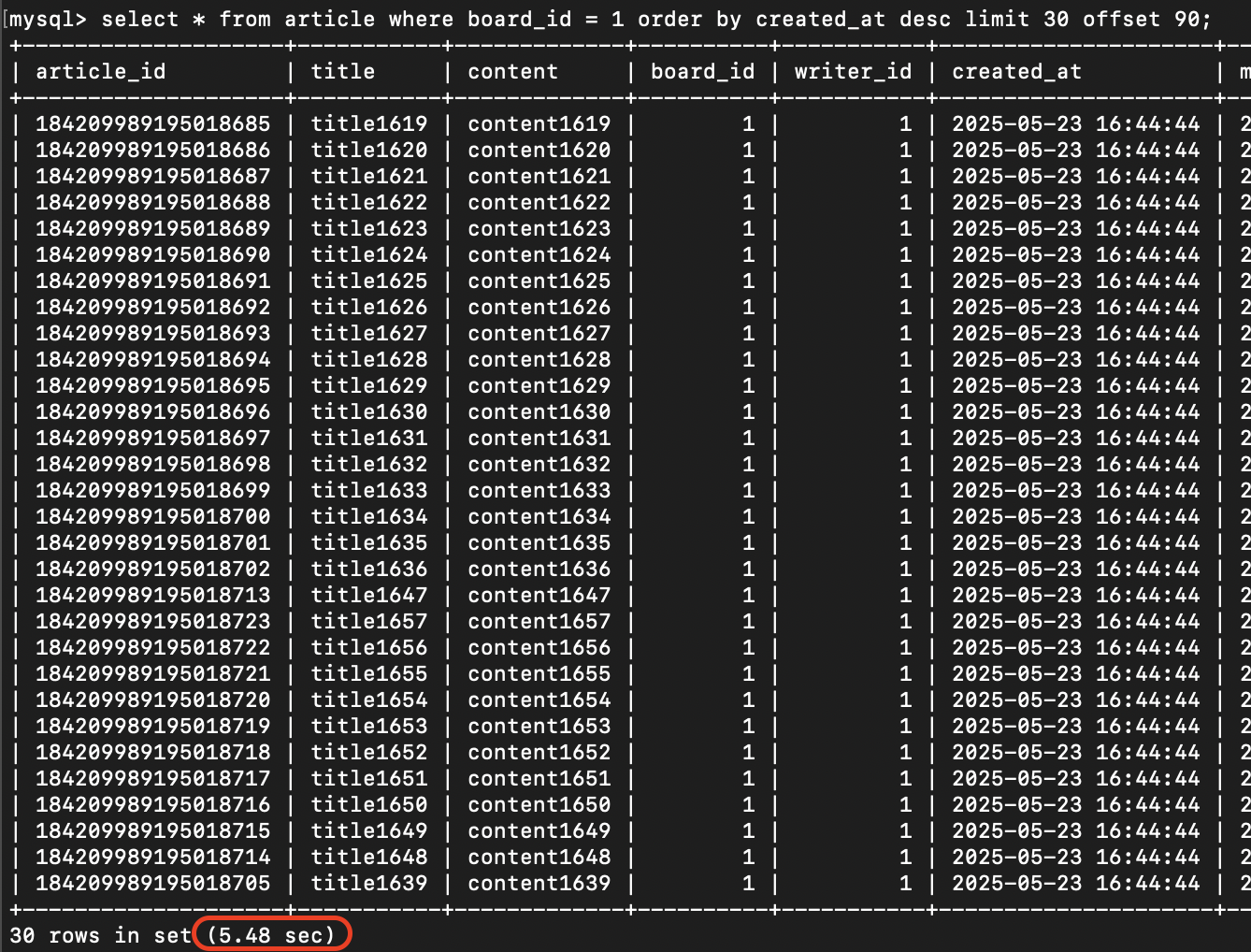
고작 1200만건의 데이터에서 30개의 게시글을 조회하는데 실행에 5.48초가 걸렸다.
정상적인 서비스가 어려운 수준이다.
실행계획(Query Plan)
explain키워드를 통해 실행계획을 확인해보자.

type = ALL
- 테이블 전체 순회 - Full Table Scan
Extra = Using where; Using filesort
- where 절을 사용하며, 데이터가 많아 메모리에서 정렬할 수 없어서, 파일(디스크)에서 데이터를 정렬한다.
전체 데이터에 대해 필터링 및 정렬을 수행하므로 아주 큰 비용이 든 것을 확인할 수 있다.
Using filesort
MySQL InnoDB 스토리지 엔진은Order by사용시 기본적으로 메모리의 정렬 버퍼(sort_buffer)를 사용한다.
하지만 정렬할 레코드 양이 너무 많아 정렬 버퍼의 크기를 초과할 경우,
디스크의 임시공간을 만들어 그곳에서 정렬을 한다.
: Disk I/O가 다수 발생 -> 속도 저하
인덱스
이를 개선하기 위해 인덱스를 사용할 수 있다.
create index idx_board_id_article_id
on article(board_id asc, article_id desc);
인덱스를 통해
board_id에 대해 오름차순 정렬,
board_id가 같다면 article_id에 대해 내림차순 정렬된 B+ tree가 생성된다.
article_id는 Snowflake 알고리즘을 사용하기 때문에
article_id에 대한 정렬이 곧 시간순 정렬이다.

인덱스를 걸고 동일한 쿼리를 실행한 결과 아주 빠르게 조회되는 것을 확인할 수 있다.
하지만 이것으로 모든 문제가 해결되었을까?
동일한 쿼리로 50000번째 페이지를 조회해보자.
offset = (50000 - 1) * 30


실행 시간은 1.83초로 매우 느려졌다.
Query Plan을 살펴봐도 인덱스가 사용되는 것을 확인할 수 있다.
인덱스가 제대로 적용되었다면, offset이 늘어났다고해서 실행 시간에 유의미한 변화가 없을 것으로 기대했다.
왜 이런 문제가 발생할까?
Clustered Index / Secondary Index
MySQL InnoDB 스토리지 엔진에는 두가지 주요한 인덱스가 존재한다.
| Clustered Index | Secondary Index | |
|---|---|---|
| 생성 | 테이블의 PK로 자동생성 | 컬럼으로 직접 생성 |
| 포함 데이터 | 실제 행 데이터(row data) | 포인터 + 인덱스 값 |
| 개수 | 테이블 당 1개 | 테이블 당 N개 |
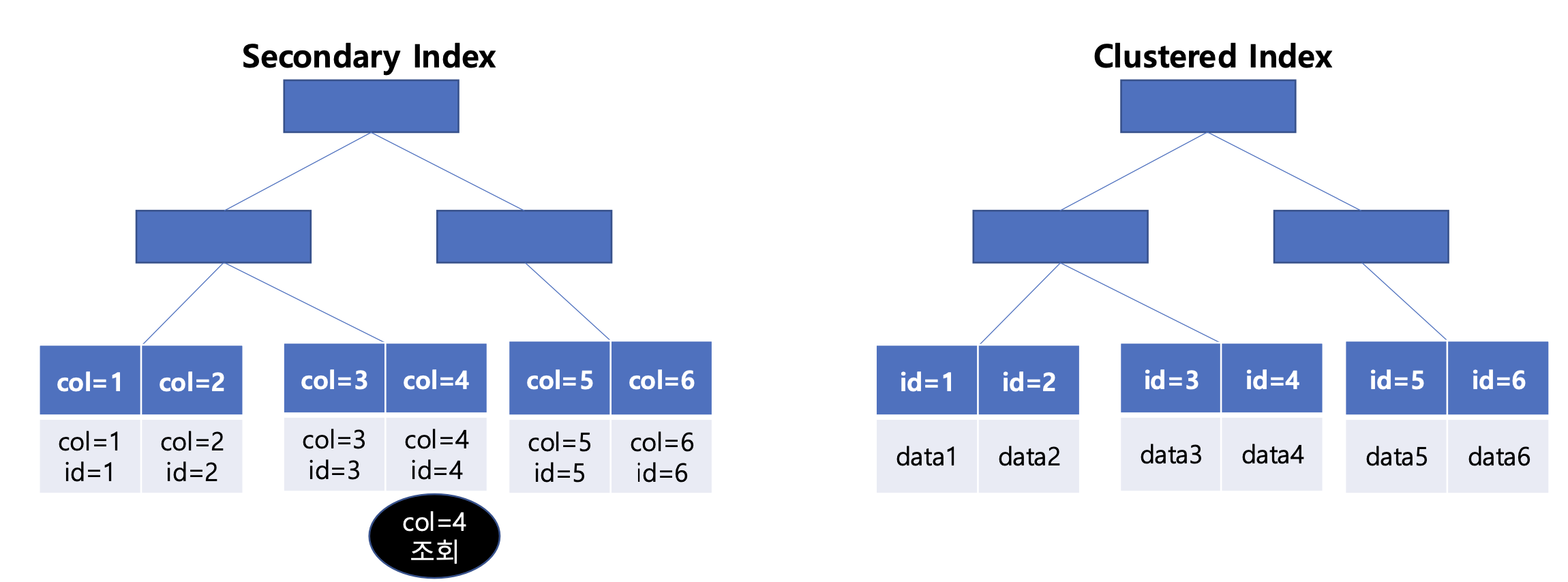
현재 우리의 Article 테이블에서는
PK인 {article_id}로 Clustered Index가 생성되어있고,
{board_id, article_id} 로 Secondary Index를 생성한 상태이다.
실행 쿼리
select * from article
where board_id = 1
order by article_id desc
limit 30 offset 1499970예상 동작
1) 세컨더리 인덱스의 리프 노드 시작점에서 1499970의 offset이 될 때까지 곧장 skip한다.
2) 30개의 포인터가 참조하는 클러스터드 인덱스의 데이터를 조회한다.
실제 동작
1) 세컨더리 인덱스의 리프 노드 시작점에서 클러스터드 인덱스의 데이터를
전부 조회하면서 1499970의 offset이 될 때까지 skip한다.
2) 30개의 포인터가 참조하는 클러스터드 인덱스의 데이터를 조회한다.
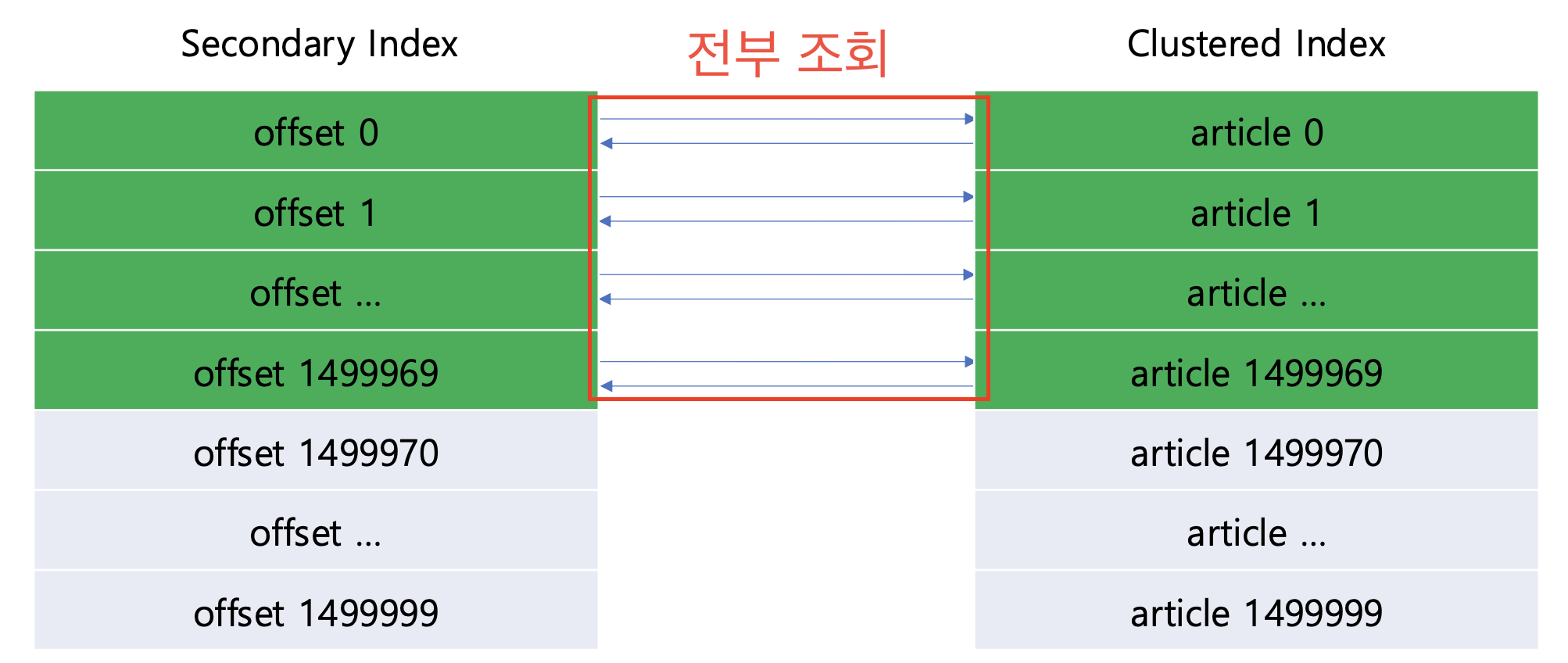
offset이 될 때까지 전부 조회하면서, offset이 클 경우 성능 문제가 발생하는 것이다.
예상대로 동작하지 않는 이유? (추정)
현재 실행하는 쿼리는select *로 최종적으로 세컨더리 인덱스만으로는 확인할 수 없는 값을 조회한다.
InnoDB 스토리지 엔진은 이런 경우 where 조건에 부합하는지 여부를 확인하기 위해 실제 데이터를 전부 조회하는 과정을 거친다.
물론 현재 쿼리는 세컨더리 인덱스에서 확인할 수 있는 컬럼인board_id만으로 where 조건문이 구성되어있지만, 이는 특수한 경우이다.
쿼리 옵티마이저가 특수한 경우를 모두 캐치해서 최적화하지는 않는 것으로 추정된다.
쿼리 튜닝
Covering Index
세컨더리 인덱스만으로 필요한 데이터 컬럼을 모두 가져올 수 있으면,
이를 커버링 인덱스라고 부르고 성능이 매우 우수해진다.
select * from (
select article_id from article //세컨더리 인덱스만으로 확인 가능
where board_id = 1
order by article_id desc
limit 30 offset 144970
) t left join article on t.article_id = article.article_id;기존 인덱스 사용이 필요한 부분을 내부쿼리로 변경하고,
커버링 인덱스가 되도록 article_id만 조회하였다.
이후 기존 테이블과 left join을 한다.
튜닝 결과
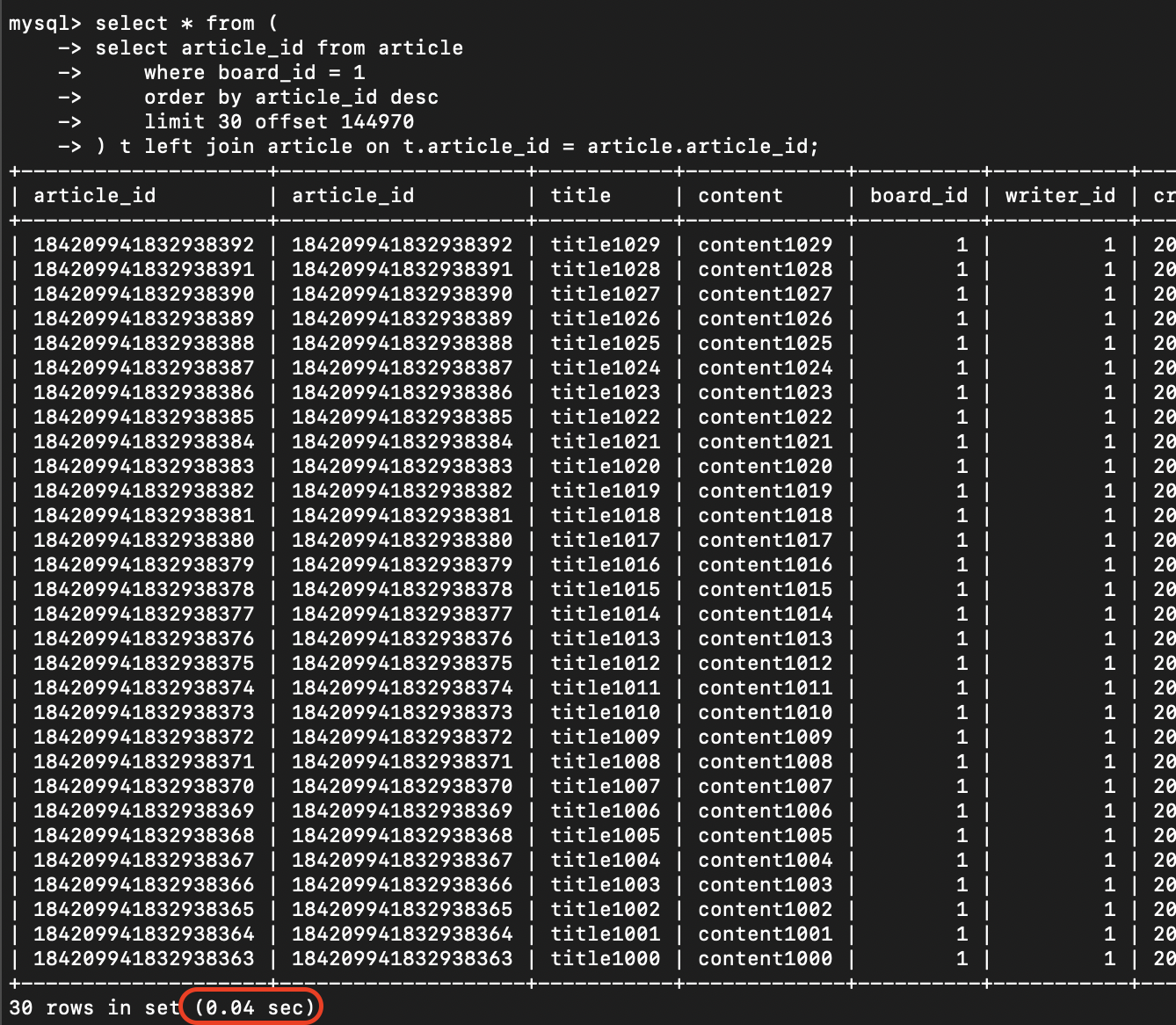
같은 결과를 출력하는데 1.83 -> 0.04초로 속도가 상당히 개선되었다.
