머신러닝 면접 준비
1. 지도학습 vs 비지도학습 vs 강화학습
지도 학습
- 정답을 알려주고 학습시키는 것
- 입력값 X를 주고, Y라고 알려준다.
- 크게 분류(classification)과 회귀(regression)가 있다.
1) 분류(classification)
주어진 데이터를 정해진 카테고리(라벨)에 따라 분류. (T/F 이진분류 , 다중분류)
2) 회귀(Regression)
데이터들의 Feature(특징)를 기준으로, 연속된 값을 예측하는 문제. (패턴이나 트렌드, 경향 예측)
ex) 30평대 아파트 가격 예측
비지도학습
- 정답을 알려주지 않고, 비슷한 데이터들을 군집화 하는것. (그룹핑)
- 지도 학습에 적절한 Feature를 찾아내기 위한 전처리 방법으로 이용되기도 한다.
- 대표적으로 클러스터링, GAN이 있다.
ex) 과일 사진이 있을때, 모양과 색깔로 구분하여 군집화 한다.
1) 군집화 (Clustering): 서로 비슷해 보이는 데이터를 그룹으로 생성. E.g. 새 사진 모음으로 종을 구분
2) 이상 탐지 (Anomaly Detection): 특이한 패턴을 감지하는 것. E.g. 고객의 구매 행동에서 특이한 패턴을 감지해 사기거래를 탐지
3) 연성 (Association): 데이터 샘플의 특징을 다른 특징과 연관짓는 것. E.g. 쇼핑카트에 옷을 넣으면 다른 연관되는 옷들을 추천
4) 오토인코더 (Autoencoder): 입력 데이터를 요약한 뒤 요약된 코드로부터 입력 데이터를 재생성하는 방법. E.g. 이미지의 더러운 버전, 깔끔한 버전을 오토인코딩 함으로써 노이즈를 제거 및 이미지의 품질 개선
강화학습
- 자신이 한 행동에 대한 보상을 받으며 학습한다.
- 규칙을 따로 입력하지 않고 스스로 행동하고 학습하면서 가장 높은 보상을 받도록 학습.
- 알고리즘 종류는 DQN, A3C 등등
ex) 알파고
2. 대표 알고리즘 종류와 특징
3. 생성적 적대학습(GAN) 이란?
- GAN(Generative Adversarial Network)로 생성자와 식별자가 서로 경쟁하면서 데이터를 생성하는 모델이다.
- 예를 들어, 사진을 만들어내는 생성자(Generator)와 만든 사진을 평가하는 구분자(Discriminator)가 서로 대립하면서 성능을 점차 개선해 나가는 학습이다.
- 실제 데이터와 가짜로 만든 데이터를 구별하도록 학습하면서 실제 데이터의 분포에 가까운 데이터를 생성하는것이 궁극적인 목표이다.
- 비지도 학습에 해당된다.
- 다만, 시간이 지날수록 발생기의 성능이 좋아지지만 판별 성능은 나빠지게 된다. (차이점을 더이상 쉽게 구별하지 못함) 결국, 분류 오류를 만들어 낼 수 있다.
4. 딥러닝과 머신러닝의 차이
머신러닝
- 알고리즘을 사용하여 데이터를 분석하고 학습하며, 학습된 내용에 따라 정보에 근거한 결정을 내린다.
딥러닝
- 인공 신경망이라는 계층화된 알고리즘 구조 사용.
- 머신 러닝의 하위 개념
- 데이터의 양이 많을수록 성능이 좋아진다.
5. RNN - 자연어 처리 NLP
RNN
- RNN(Recurrent Neural Network)로 순환 신경망으로 불리며 입력과 출력을 시퀀스 단위로 처리하는 모델.
- 과거의 데이터의 영향을 판단하여 새로운 예측
*시퀀스 테이터는 연관된 연속의 데이터를 지칭.(소리,문자열,주가). 순서가 매우 중요하며 과거의 정보 맥락을 고려하는 RNN에서 사용된다.
6. 데이터 전처리 BPE, Subword, Tokenization
- 아무리 많은 단어를 학습시켜도 세상의 모든 단어를 알려줄 수 없다. 모르는 단어가 등장하면 단어 집합에 없는 단어이기에 OOV(Out-Of-Vocabulary) UNK(Unkown Token)같은 OOV 문제가 발생한다. 이를 해결하기 위해 Subword 분리 작업을 하게 되는데 하나의 단어를 더 작은 단위의 의미있는 여러 subword로 나누는 작업이다.
=> 이를 통해 OOV , 신조어, 희귀 단어 문제를 완화시킬 수 있다.
BPE
- BPE(Byte pair encoding)은 데이터 압축 알고리즘이다. 자연어 처리의 subword 분리 알고리즘으로 응용됨.
ex) 딕셔너리에 단어 집합이 (low, est...)가 있는데 lowest라는 단어가 들어오면 low와 est로 잘라서 OOV 문제를 해결한다.
Tokenization
-
크롤링 등으로 얻어낸 데이터는 정제되지 않았기 때문에 토큰화, cleaning, 정규화(normalization) 하는 과정이 필요하다. 의미있는 단위로 토큰을 정의.
=> ex) 구두점, 특수문자 제거(?, ; ! . ) 띄어쓰기.. -
단, 한국어는 토큰화 작업하기 힘들다. 교착어이기 때문에 다양한 조사가 띄어쓰기 없이 붙게 되어 의미있는 단어로 나누기 힘들다.. (띄어쓰기가 잘 지켜지지 않는 데이터가 많다.) NLTK, KoNLpy가 있지만 그래도 어려움.
Cleaning, Normalization
- (Cleaning)갖고 있는 코퍼스로부터 노이즈 데이터 제거, (Normalization)표현 방법이 다른 단어들을 통합시켜 같은 단어로 만들어준다.
- 대소문자 통합, 불필요한 단어 제거 , 등장 빈도가 현저히 적거나 길이가 짧은 단어 제거
7. LSTM, Transformer 모델
LSTM
- 기존 RNN은 오랜 기간 정보를 기억하지 못해서 오랜 기간 정보를 기억하기 위해 사용.
- 기존 RNN은 입력 순서가 가까울수록 영향을 많이 받는 문제가 발생함.
- 새로운 입력값뿐 아니라 이전의 출력값의 정도를 고려하는 gate를 추가하여 멀리있는 단어도 영향을 받도록. 단, 학습속도가 너무 느리다.
- cell state, hidden state, sigmoid 사용
- 기존 RNN의 한계점인 역전파 문제는 이전 단계의 cell state에 필요한 정보를 곱셈이 아닌 덧셈으로 업데이트 해줌으로 해결.
GRU
- LSTM 간소화된 버전.
- Cell state와 Hidden State를 h로 합침
Transformer
- 입력값에 대한 보다 유연한 처리를 위해 사용.
- 인코더, 디코더가 N개 존재하며 (논문에서는 각각 6개 사용) RNN은 사용되지 않음.
- 인코더-디코더 어텐션 레이어 사용. 디코더의 모든 위치가 입력 시퀀스의 모든 위치를 attend할 수 있다.
- 인코더에는 self-attention 레이어 포함. 인코더의 각 위치는 인코더의 이전 레이어에 있는 모든 위치에 attend할 수 있다.
8. 혼동 행렬
- 모델의 성능을 평가할 때 사용되는 지표이다.
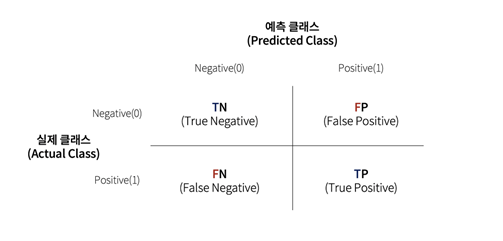
1) TP(True Positive) - 맞는 것을 올바르게 맞다고 예측한 것
2) TN(True Negative) - 아닌 것을 올바르게 틀리다고 예측한 것
3) FP(False Positive) - 아닌 것을 올바르지 않게 맞다고 예측한 것
4) FN(False Negative) - 맞는 것을 올바르지 않게 틀리다고 예측한 것
9. 과대적합, 과소적합
-
과대적합(Overfitting)은 필요 이상의 특징으로 학습을 계속 진행하는 경우.
-
과소적합(Underfitting)은 데이터가 적어서 충분히 특징을 찾아내지 못할때.
10. K-폴드 교차검증
- 보편적으로 전체 데이터셋 20%를 테스트, 나머지의 데이터의 90%를 학습 데이터(Training)로 10%는 검증 데이터(Valid)로 사용.

11. 개인 프로젝트 느낀점
-
데이터의 전처리가 그 무엇보다 중요함을 깨닫게 되었다. 데이터를 더 잘 가공할수록 결과가 확연히 달라짐을 느꼈고 데이터 전처리하는 여러 방법들을 익힐 수 있었다. (Subword.. BPE..)
-
사용했던 데이터 전처리 방법
1) BPE Subword
2) Tokenizer
3) Cleaning , Normalization
4) 딕셔너리 (고유명사 사전, Training-Valid 사전)
