모델의 성능을 높이기 위해 단순히 많은 feature를 사용하는 것이 항상 좋은 것은 아니다. 불필요한 feature가 많아질수록 모델은 학습 데이터에 과도하게 적합되는 overfitting 문제가 발생할 수 있다.
이를 방지하기 위해 feature selection(특성 선택) 이 필요하다.
feature selection의 핵심 목적은
Bias–Variance Trade-off에서 최적의 균형점을 찾는 것이다.
불필요한 feature를 제거하면 variance를 줄일 수 있지만, 너무 많은 feature를 제거하면 bias가 증가할 수 있으므로 신중한 선택이 요구된다.
Supervised Variable Selection — Exhaustive Search
Exhaustive Search(완전 탐색)는 가능한 모든 feature 조합을 평가하여 최적의 subset을 찾는 방법이다.
- 총 p개의 feature가 있을 때,
가능한 subset의 개수는 2ᵖ − 1 - 각 subset에 대해 모델을 학습하고 성능을 평가
- Training set이 아니라 Test set 성능 기준으로 최적 조합을 선택
이 방법은 이론적으로 최적해를 보장한다는 장점이 있다.
그러나 feature 수가 조금만 커져도 경우의 수가 기하급수적으로 증가하여
계산 시간이 현실적으로 감당 불가능해진다는 치명적인 단점이 있다.
Forward Selection
Forward Selection은 feature가 하나도 없는 상태에서 시작한다.
- 가장 성능 향상에 기여하는 feature를 하나씩 순차적으로 추가
- 한 번 선택된 feature는 절대 제거하지 않음
비교적 계산량이 적고 직관적이지만,
초기에 잘못 선택된 feature가 이후 단계에 영향을 미칠 수 있다는 한계가 있다.
Backward Elimination
Backward Elimination은 Forward Selection과 반대 방식이다.
- 모든 feature를 포함한 상태에서 시작
- 성능에 거의 영향을 주지 않는 feature를 순차적으로 제거
- 한 번 제거된 feature는 다시 선택되지 않음
초기 모델이 복잡해 계산 비용이 크며,
역시 전역 최적해를 보장하지는 않는다.
Stepwise Selection
Stepwise Selection은 Forward와 Backward를 번갈아 수행하는 방식이다.
- feature를 추가했다가, 필요 없으면 다시 제거
- 더 유연하게 subset을 탐색 가능
계산 시간은 증가하지만,
Forward/Backward 단독 방법보다 더 나은 subset을 찾을 가능성이 높다.
전통적인 Feature Selection 방법의 한계
이러한 Exhaustive, Forward, Backward, Stepwise 방법들은 공통적인 단점을 가진다.
- feature 수가 커질수록 계산 시간이 급격히 증가
- 탐색 공간이 제한되어 최적 subset을 놓칠 가능성
- 시간 대비 성능 개선 효과가 낮은 경우도 많음
→ 즉, 가성비가 떨어진다
그렇다면 이런 질문이 자연스럽게 생긴다.
모델이 error를 최소화하는 과정 자체에서
feature selection을 자동으로 수행할 수는 없을까?
Feature Selection 방법의 분류
이 질문에 대한 해답으로 feature selection 방법은 크게 세 가지로 나뉜다.
Filter Method
- 모델과 무관하게 feature 자체의 통계적 특성을 기준으로 선택
- 예: Correlation, ANOVA 등
- 빠르지만 feature 간 상호작용을 고려하지 못함
Wrapper Method
- 특정 모델을 사용해 feature subset의 성능을 직접 평가
- 예: Forward, Backward, Stepwise
- 성능은 좋지만 계산 비용이 큼
Embedded Method
- 모델 학습 과정에 feature selection을 내재화
- 대표적으로 Regularization(정규화) 기반 방법
Embedded Method의 장점
Embedded Method는 Wrapper Method의 장점을 일부 유지하면서 단점을 보완한다.
- 모델이 학습 과정에서 자동으로 feature subset을 선택
- feature 간 상호작용을 고려
- 반복적인 subset 탐색 없이도 비교적 효율적인 계산
이때 핵심 역할을 하는 것이 바로 Penalty Term이다.
Penalty Term (정규화 항)
Penalty Term는 축구 경기에서 반칙 시 부과되는 벌 과 같은 개념이다.
모델에서는 불필요하거나 중요도가 낮은 feature에 대해
계수 값이 커지는 것을 억제하는 벌점을 부여한다.
즉, 모델은
- Error를 최소화하면서
- 동시에 불필요한 feature의 영향력을 줄이도록 학습된다.
이 과정에서 자연스럽게 중요한 feature만 살아남게 되며,
모델 스스로 feature selection을 수행하게 된다.
L2 Regularization (Ridge Regression)
Regularization에서
L1은 절댓값, L2는 제곱을 사용한다.
L2 Regularization은 회귀 계수 β의 제곱합(L2-norm) 에 penalty term을 부여하는 방식이다.
즉, 모델은 제곱 오차(MSE)를 최소화하면서 동시에 계수의 크기를 제한하도록 학습된다.
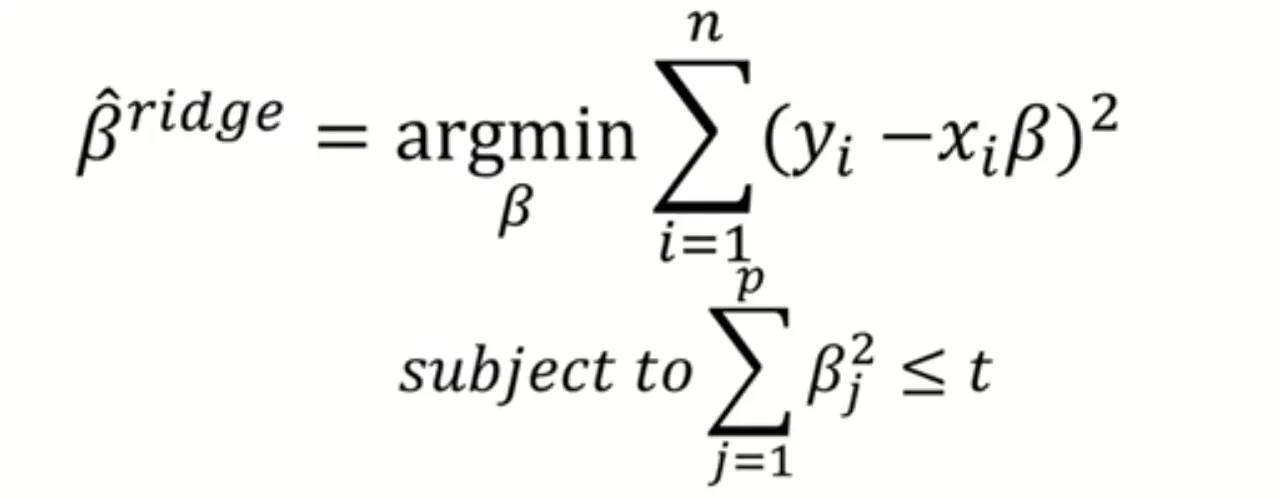
이때 penalty term이 포함된 모델에서는
feature 간 스케일 차이가 결과에 직접적인 영향을 미치므로 scaling이 필수이다.
기하학적 해석 (MSE Contour)
MSE contour는 타원 형태를 가지며,
중심에서 멀어질수록 error가 증가한다.
-
제약 조건이 없는 경우
→ MSE가 최소가 되는 지점은 LSE(Least Squares Estimator) -
제약 조건(L2-norm 제한)이 있는 경우
→ 타원(MSE contour) 과 원(L2 constraint) 이 만나는 지점이
제약을 만족하면서 error가 최소가 되는 해가 된다.
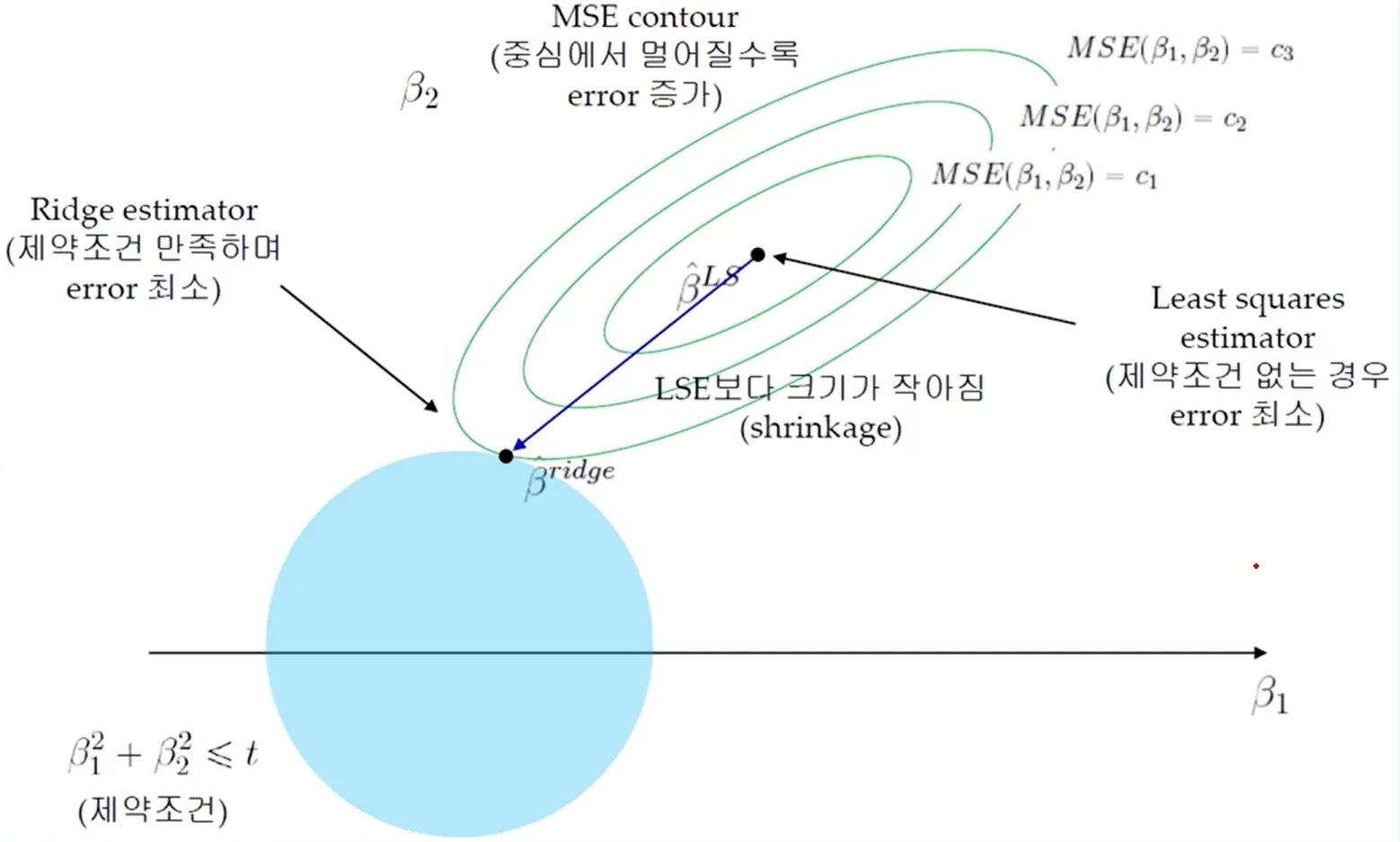
이 과정은
train error를 약간 증가시키는 대신 variance를 줄이는 과정으로 볼 수 있으며,
overfitting을 방지하는 효과를 가진다.
계수의 크기를 줄이는 특성 때문에
Ridge Regression은 shrinkage method라고도 불린다.
Ridge Regression의 특징
- Feature selection은 수행되지 않음
- 불필요한 feature라도 계수는 0에 매우 가깝게만 수렴
- feature 스케일에 민감 → 정규화 필수
- Multicollinearity(다중공선성) 문제 완화에 효과적
릿지 회귀는 선형 회귀와 구조는 같지만,
각 feature가 출력에 미치는 영향을 전반적으로 줄이도록 규제를 거는 모델이다.
다중공선성 문제는 두 개 이상의 feature가 강한 상관관계를 가질 때 발생하며, Ridge Regression은 이를 완화하여 모델의 안정성을 높여준다.
Lasso Regression
L1 Regularization
Lasso는 회귀 계수의 절댓값 합(L1-norm) 에 penalty term을 부여한다.
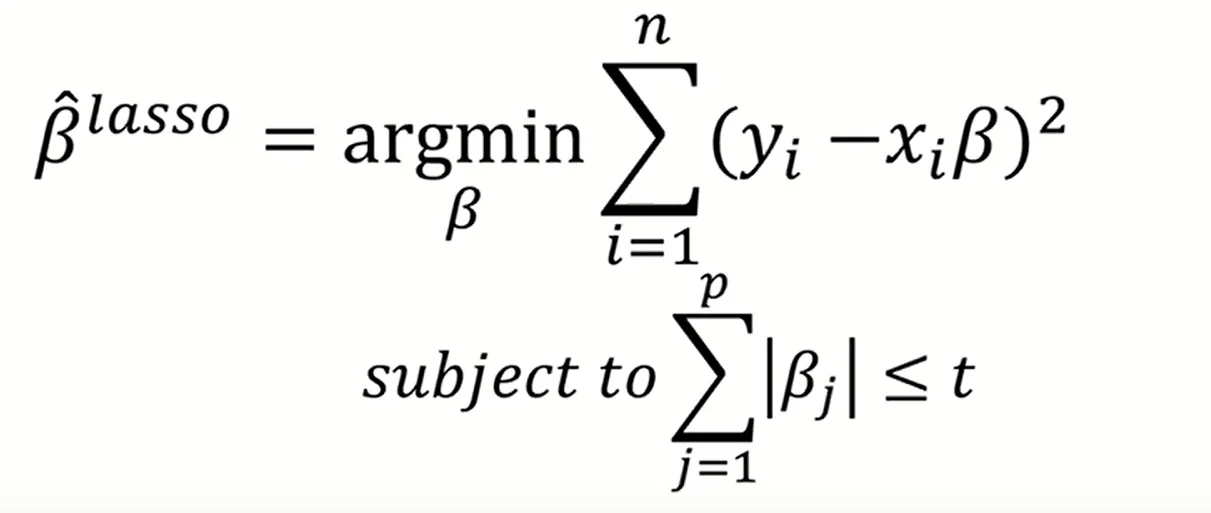
기하학적으로 보면,
- Ridge (L2) → 원 형태의 제약 조건
- Lasso (L1) → 마름모 형태의 제약 조건
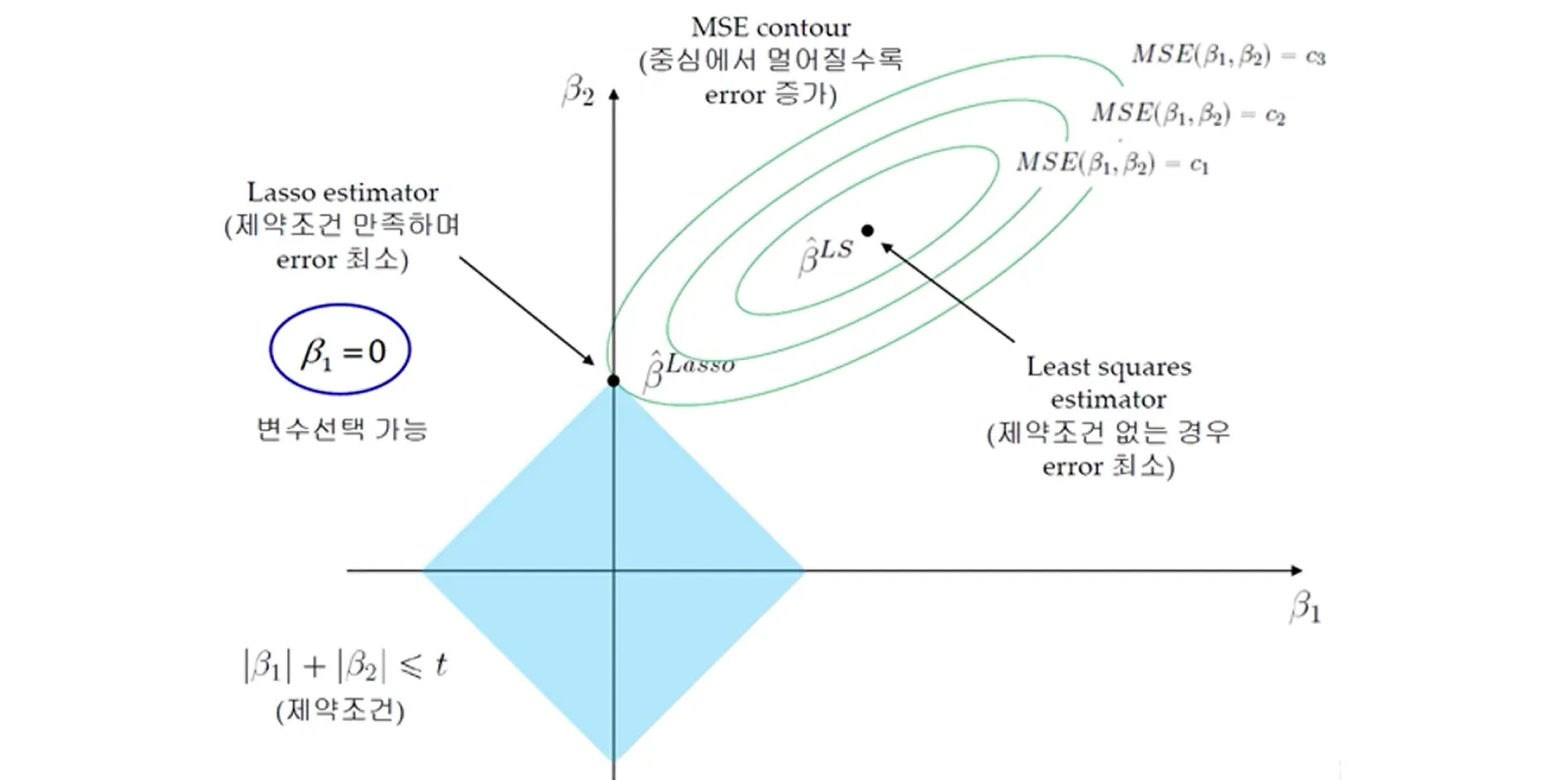
이 차이 때문에
Lasso는 최적해가 좌표축과 만나는 경우가 많아지고,
그 결과 일부 계수가 정확히 0이 된다.

→ 해당 feature는 모델에서 완전히 제외됨
즉, Lasso는
Regularization + Feature Selection을 동시에 수행한다.
Lasso의 최적화 특성
Lasso는 절댓값을 사용하기 때문에
미분이 불가능하며,
Ridge와 달리 closed-form solution이 존재하지 않는다.
따라서 실제 학습에서는
Numerical optimization 방법을 사용한다.
λ (lambda)의 역할
-
λ가 클수록
→ 선택되는 변수 수 감소
→ 단순한 모델
→ underfitting 위험 증가 -
λ가 작을수록
→ 많은 변수 사용
→ 복잡한 모델
→ overfitting 위험 증가
Ridge와 Lasso 모두
λ가 커질수록 계수의 크기는 줄어든다.
-
Ridge
→ 크기가 큰 계수부터 빠르게 감소 (제곱 penalty) -
Lasso
→ 중요하지 않은 계수가 먼저 0이 됨
→ 명확한 feature selection 효과
Ridge vs Lasso 정리
-
Ridge
- 계수를 전반적으로 줄임
- feature는 제거되지 않음
- 다중공선성 완화에 효과적
-
Lasso
- 중요하지 않은 feature를 0으로 만듦
- feature selection 가능
- 해석 가능성이 높은 모델 생성
Elastic Net Regularization
Elastic Net은 L1-norm과 L2-norm을 결합한 정규화 기법이다.
즉, Ridge와 Lasso의 장점을 동시에 활용하는 방식이다.
- L1-norm → feature selection
- L2-norm → 계수 안정화 및 다중공선성 완화
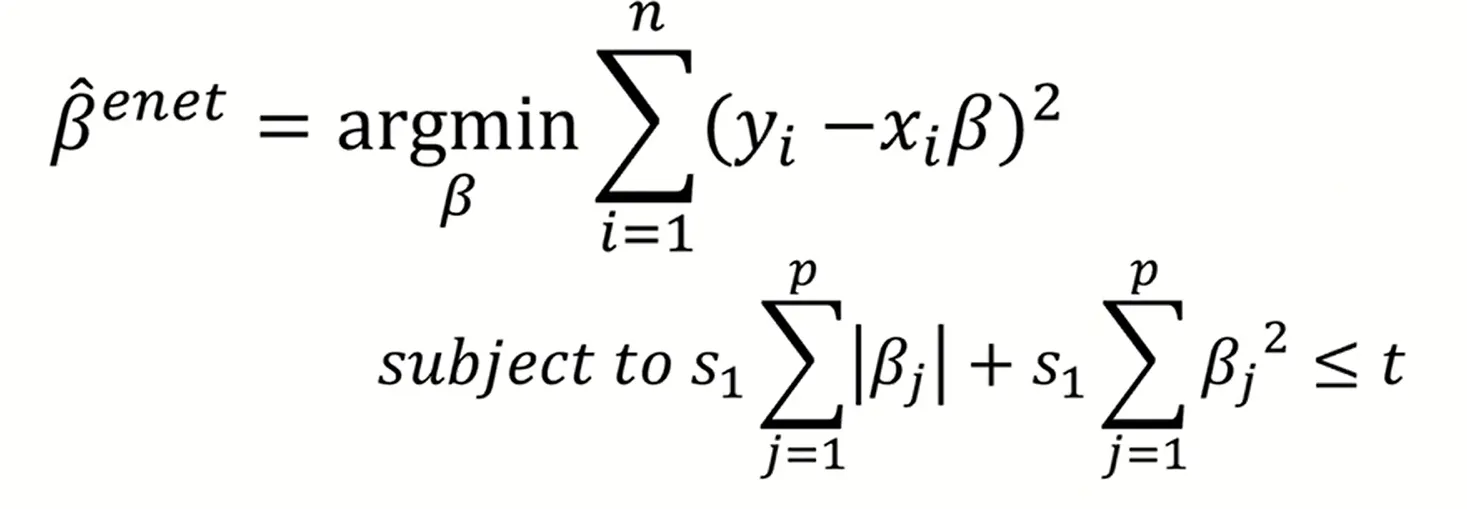
Elastic Net의 목적 함수는 오차를 최소화하면서,
L1과 L2 penalty를 동시에 제어하는 것이다.
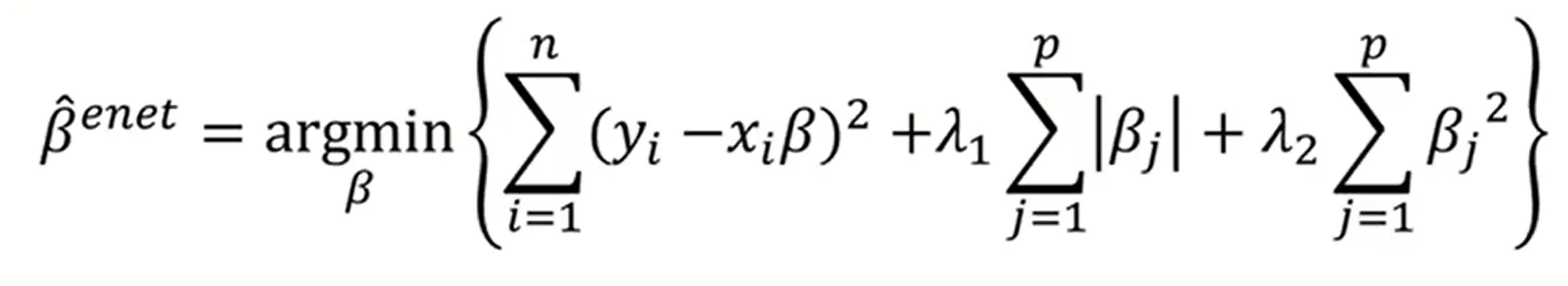
Elastic Net의 핵심 특징
Elastic Net은 상관관계가 강한 feature들을 함께 선택하거나 함께 제거하는 경향을 가진다.
- Lasso의 경우
→ 상관관계가 높은 변수 중 하나만 선택하는 경향 - Elastic Net의 경우
→ 상관관계가 높은 변수들을 그룹처럼 동시에 유지
이 특성 때문에 Elastic Net은
feature 간 상관관계가 강한 데이터셋에서 특히 유리하다.
λ₁, λ₂ (또는 α)의 역할
Elastic Net에서는 두 개의 penalty 강도를 조절한다.
- λ₁ (L1 penalty)
→ sparsity(희소성) 조절, feature selection 영향 - λ₂ (L2 penalty)
→ 계수 안정화, 다중공선성 완화
실제로는 일정 범위 내에서 λ₁, λ₂를 함께 조정하며 실험하고,
가장 좋은 예측 성능을 보이는 조합을 선택한다
Elastic Net의 단점
- Ridge나 Lasso에 비해
튜닝해야 할 하이퍼파라미터가 많음 - 더 많은 실험과 계산 비용 필요
현실 데이터에서의 안정성과 성능은 더 뛰어난 경우가 많다.
해 공간 관점에서의 이해
Elastic Net의 제약 조건은
L1과 L2 제약이 혼합된 형태의 해 공간을 만든다.
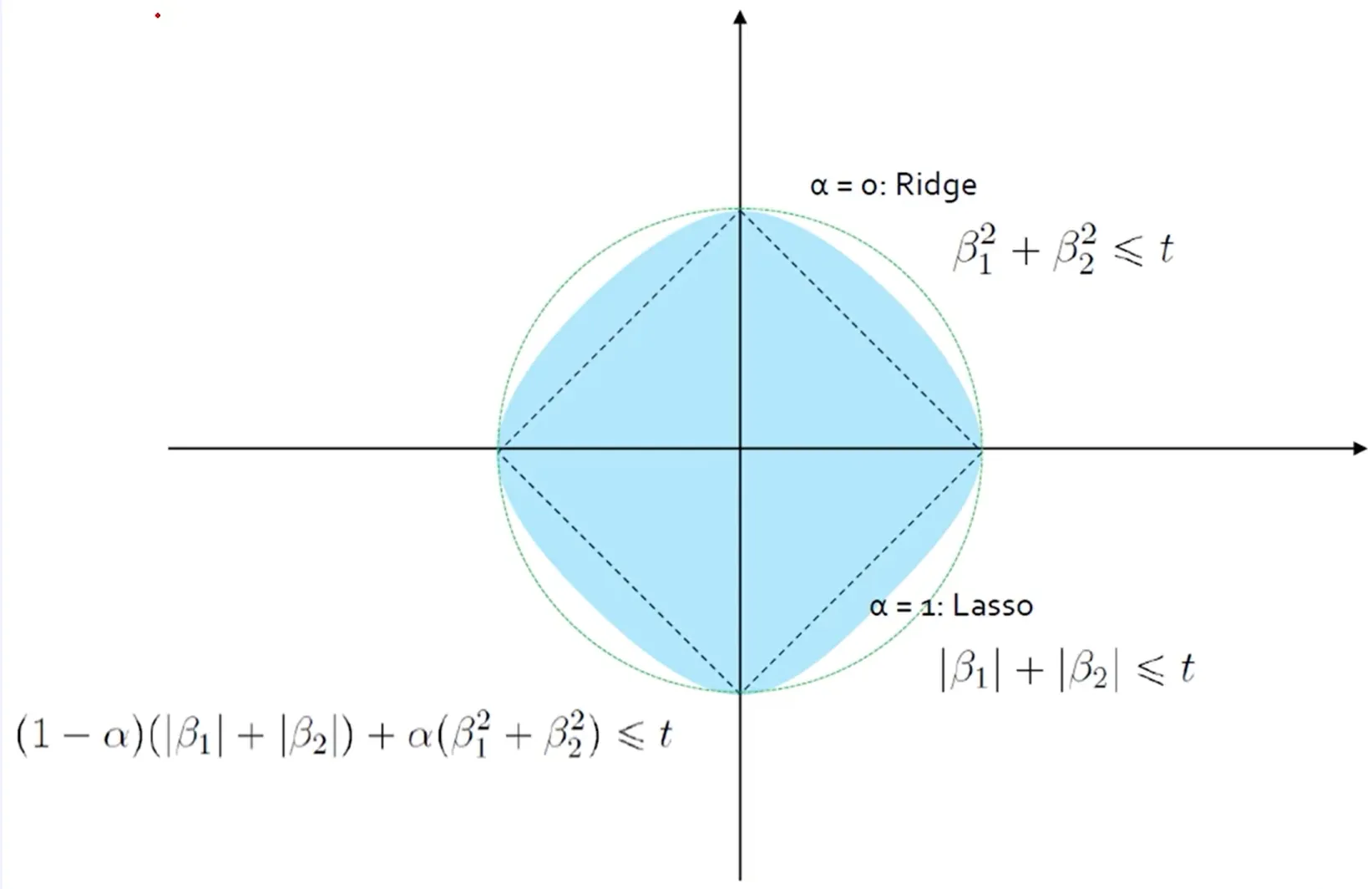
- Ridge → 원형 해 공간
- Lasso → 마름모 해 공간
- Elastic Net → 두 형태가 섞인 부드러운 제약 공간
이로 인해 계수가 0이 되기도 하고, 동시에 안정적으로 shrinkage 되는 특성
확장된 Regularization 기법들
Elastic Net을 확장한 다양한 정규화 기법들도 존재한다.
- Fused Lasso
→ 인접한 feature 간의 차이까지 함께 규제 - Group Lasso
→ feature를 그룹 단위로 선택/제거 - GRACE
→ feature 간의 그래프 구조를 반영한 정규화 - Non-convex Penalties
→ L0에 가까운 sparsity를 유도하기 위한 비볼록 정규화
구조적 특성을 가진 데이터에서 특히 유용하게 사용된다.
정리
- Ridge
→ 계수 안정화, 다중공선성 완화 - Lasso
→ 명확한 feature selection - Elastic Net
→ 두 장점을 결합한 실전형 정규화 기법
특히 고차원 데이터 + 강한 feature 상관관계 환경에서는
Elastic Net이 가장 현실적인 선택이 되는 경우가 많다.
