Logistic Regression (로지스틱 회귀)
Logistic Regression (로지스틱 회귀)란 Binary Classification (이진 분류) 문제를 해결하기 위한 모델이다.
ex) 스팸 메일, 질병 양성/음성 분류 등
Sigmoid Function을 이용하여 특정 입력 데이터가 양성 class에 속할 확률을 계산한다.
Sigmoid Function
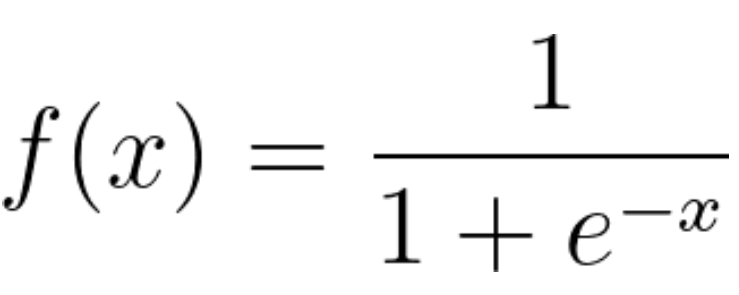
s자형 곡선을 갖는 함수
-
x값이 무한하게 커질 경우 함수는 점점 1에 수렴하고, x값이 무한하게 작아질 경우 함수는 점점 0에 수렴한다.
-
x가 어떤 값이 되더라도 함수의 값은 0 ~ 1 사이의 범위 내에 있으며, 0 ~ 1 사이의 값을 확률로 해석 가능하다.
-
미분 결과를 아웃풋의 함수로 표현 가능
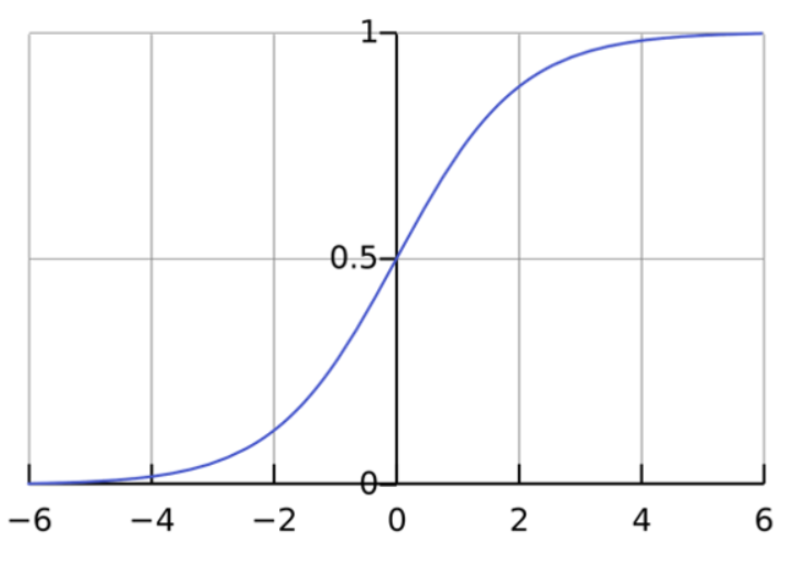
Cross Entropy
성능 지표로 분류를 위한 Cross-entropy를 활용
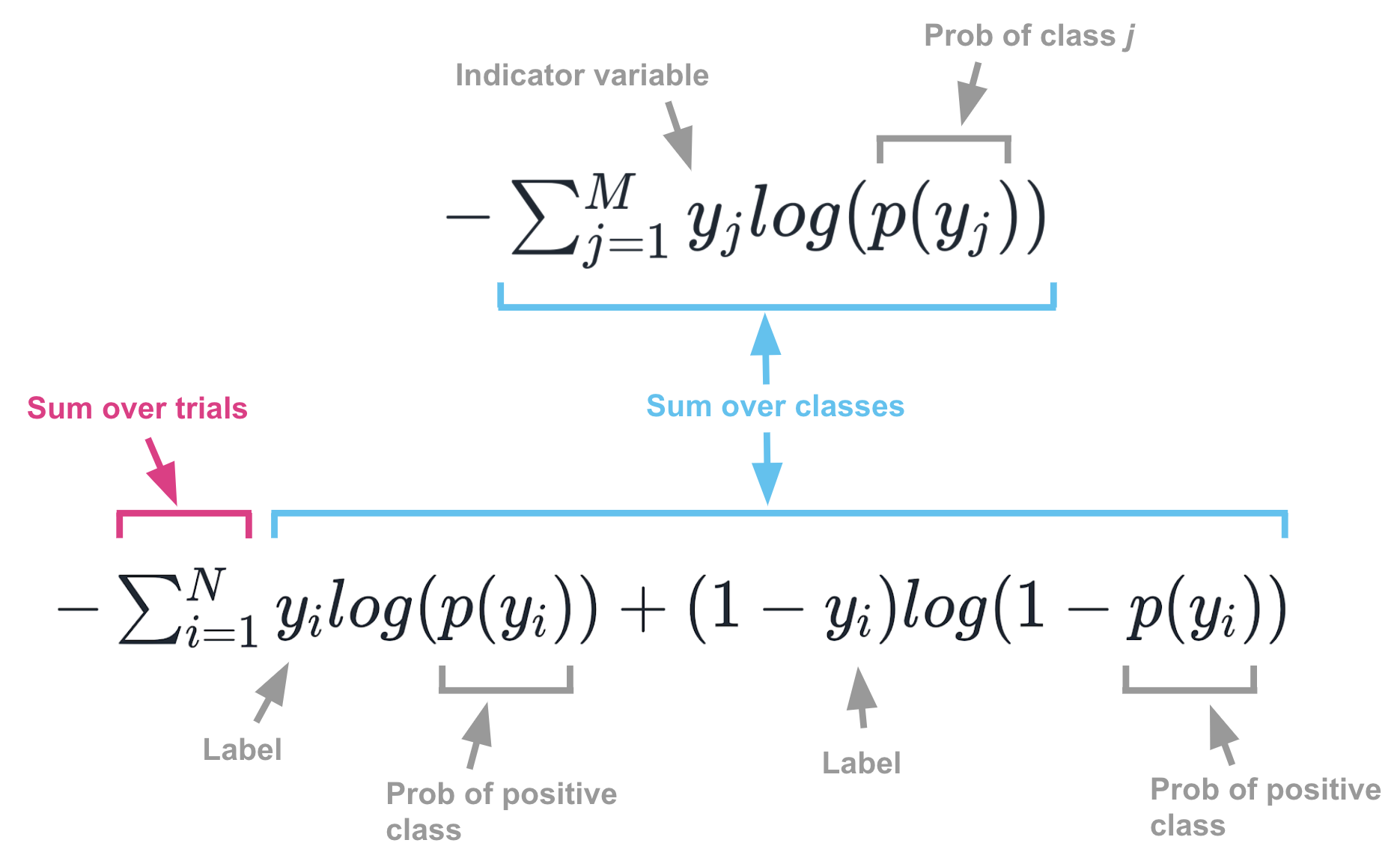
Odds
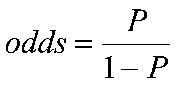
Odds란 성공 확률을 p로 정의할 때, 실패 대비 성공 확률 비율로,
성공 확률을 실패 확률로 나눈 것이다.
로지스틱 회귀의 관점으로는, 범주 0에 속할 확률 대비 범주 1에 속할 확률을 의미한다.
Odds vs Probability
Odds와 Probability(확률)은 다른 개념이다.
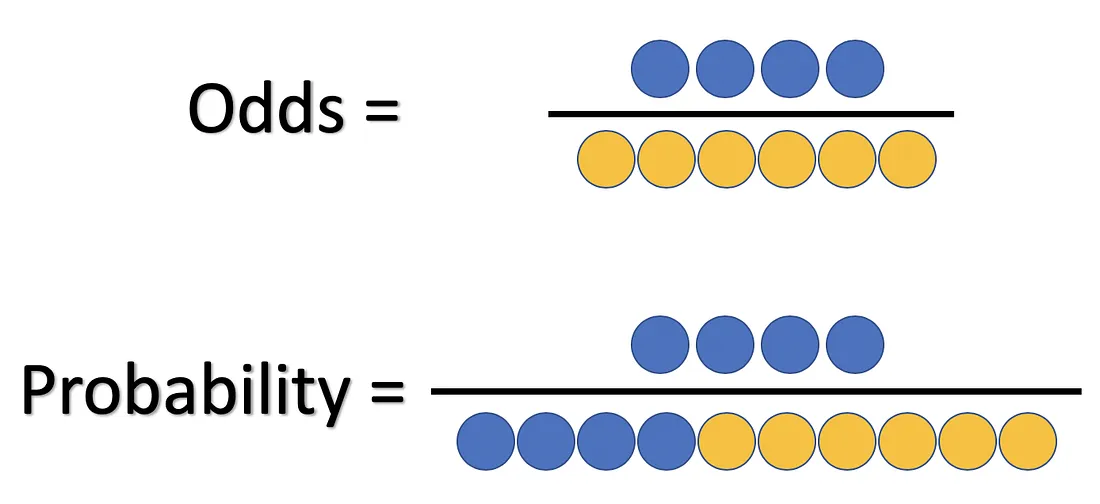
- Odds는 사건이 발생할 확률 / 발생하지 않을 확률
- Probability는 사건이 일어날 경우의 수 / 전체 경우의 수로 표현된다.
Odds Ratio
어떤 사건이 발생활 확률
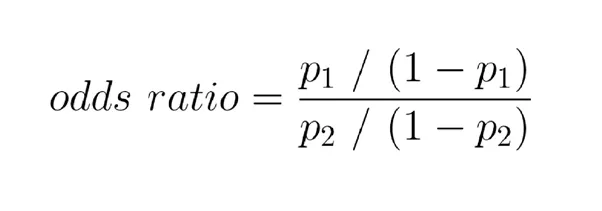
Odds Ratio가 Logistic Regression과 어떻게 관련이 있을까?
로지스틱 회귀 분석에서 독립 변수의 오즈비는 다른 모든 변수가 일정하게 유지될 때 단위당 오즈 변화가 해당 변수를 어떻게 증가시키는지를 나타낸다.
범주 0에 속할 확률 대비 범주 1에 속할 확률
Logit Transform (로짓 변환)
-> Odds에 log를 취해 선형결합으로 변환 가능
예측값이 0 ~ 1 사이의 값을 가져야 하는데, 로짓 변환을 통해 이를 해결함
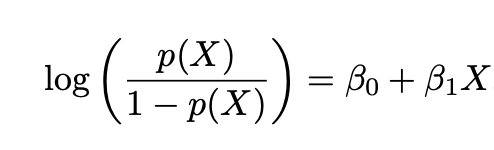
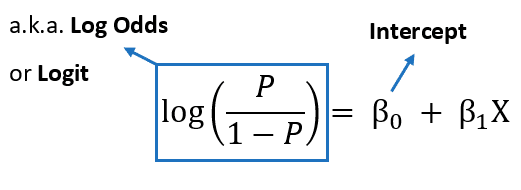
Log-Odds
Odds에 log를 취한 것
베타1 : x가 한 단위 증가했을 때 log(Odds)의 증가량
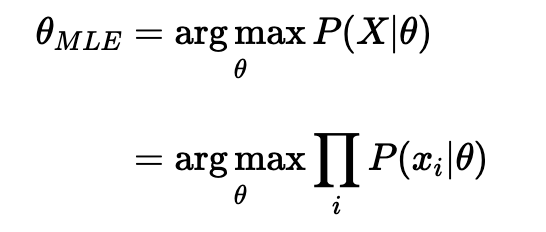
파라미터 추정 - Maximum Likelihood Estimation (최대 우도 추정법)
최대 우도법은 주어진 데이터에서 모델의 파라미터를 최적화하는 방법이다. 로지스틱 회귀에서는 우도를 최대화하는 방법을 사용한다.
◦ 데이터를 관찰함으로써 이 데이터가 추출되었을 것으로 생각되는 최적의 분포를 찾는 것
log likelihood function이 최대가 되는 파라미터 결정
로그 - 우도함수는 명시적인 해가 존재하지 않는다. (No closed-form solution exists)
수치 최적화 알고리즘을 이용하여 해를 구해야함
Cross entropy : 두 확률분포의 차이
Cross entropy : 음의 log likelihood function의 기대값
Log likelihood function을 최대 = Cross entropy를 최소
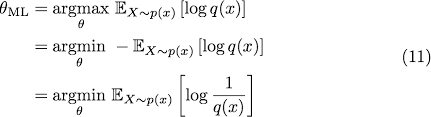
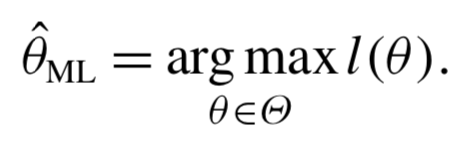
Threshold
이진 분류를 위한 임계값 (threshold) 설정
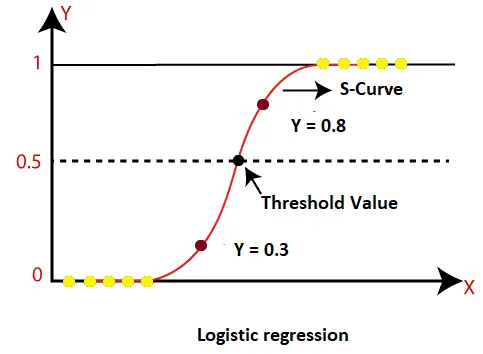
로지스틱 회귀의 결과 값은 분류 확률이므로, 임계값을 통해 특정 클래스에 속할 지 말지 결정한다.
대부분의 임계값은 0.5이며, 값이 0.5를 초과하면 대상에 1이 할당되고 그렇지 않으면 0이 된다.
