Generalization (일반화)
학습에 사용된 데이터가 아닌 처음 보는 새로운 데이터에 대해 올바른 예측을 수행하는 능력
what is good model ?
머신러닝에서 좋은 모델이란 현재 데이터를 잘 설명하며, 미레 데이터에 대한 예측 성능이 좋은 모델이다.
현재 데이터를 잘 설명하는 모델은, 곧 training error를 최소화하는 모델이다.
Error는 다음과 같이 나타낼 수 있다.
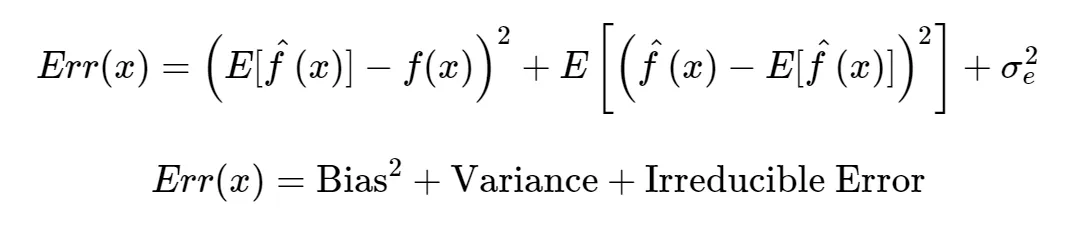
- Bias : 예측값의 평균과 실제값의 차이
- Variance : 예측 값들의 흩어진 정도
- Irreducible Error : 제거할 수 없는 오류
Error를 줄이기 위해서 Bias와 Variance를 줄여야 하는데,
Bias와 Variance는 Trade-Off 관계로 Bias와 Variance 사이의 균형을 맞추어야 오차를 최소화할 수 있다.
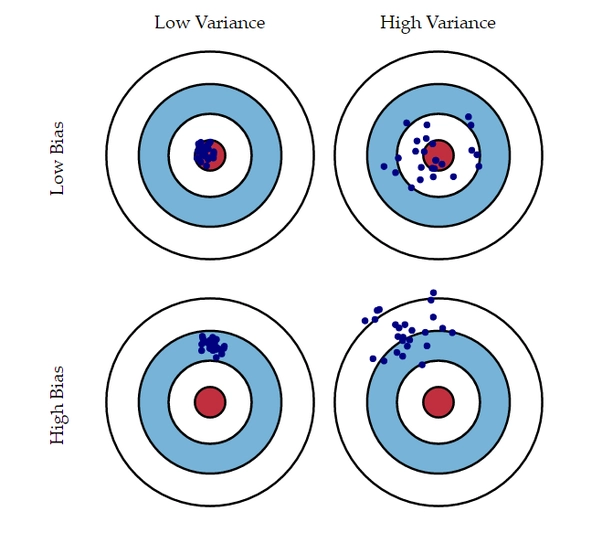
-
Variance가 높을수록 예측값들이 서로 흩어져있다.
-
Variance가 높으면 모델 학습이 과하게 학습된 것이다.
-
Bias가 높을 수록 예측값들이 실제값들과 떨어져 있다.
-
Bias 가 높으면 모델 학습이 제대로 되지 않았고, 모델 학습이 부족한 상태이기 때문에 더 학습을 해야한다.
그 중간 지점인 optimal capacity 를 찾아야하며, 이 부분이 훈련 데이터셋과 평가 데이터셋 모두에서 준수한 예측을 낼 수 있다.
Overfitting (과대적합)
High variance -> overfitting
모델이 주어진 훈련 데이터에 과도하게 맞춰져 새로운 데이터가 입력 되었을 때 잘 예측하지 못하는 현상
즉, 모델이 과도하게 복잡해져 일반성이 떨어진 경우를 의미함
과적합 - unstable, variance 증가 ( 모델의 복잡성이 올라가면 증가)
학습 데이터를 많이 모으면 variance가 줄어든다..
Underfitting (과소적합)
모델이 너무 단순하여 훈련 데이터에 적절히 훈련되지 않은 경우
훈련 데이터보다 테스트 데이터의 점수가 높거나, 두 점수가 모두 낮은 경우
지금까지의 내용을 종합한 그림
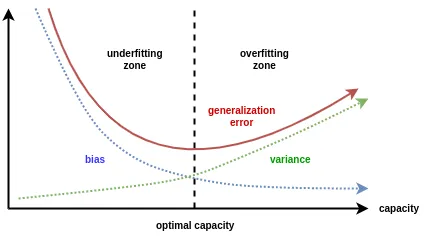
-
Capacity : 모델의 복잡도
-
Underfitting Zone : 과소적합 발생
-
Overfitting Zone : 과대적합 발생 -> 일반화 성능이 떨어진다.
-
Variance (초록색 곡선) : High variance -> overfitting
-
Bias (파란색 곡선) : High bias -> underfitting
-
Generalization Error (빨간색 곡선) : Bias와 Variance를 합한 총 오류, Optimal Capacity 지점(적절한 Bias와 Variance의 지점) 에서 Generalization Error가 최소화
