Linear Regression (선형 회귀)
데이터를 가장 잘 설명하는 모델을 찾아 입력값에 따른 결과값을 예측하는 알고리즘
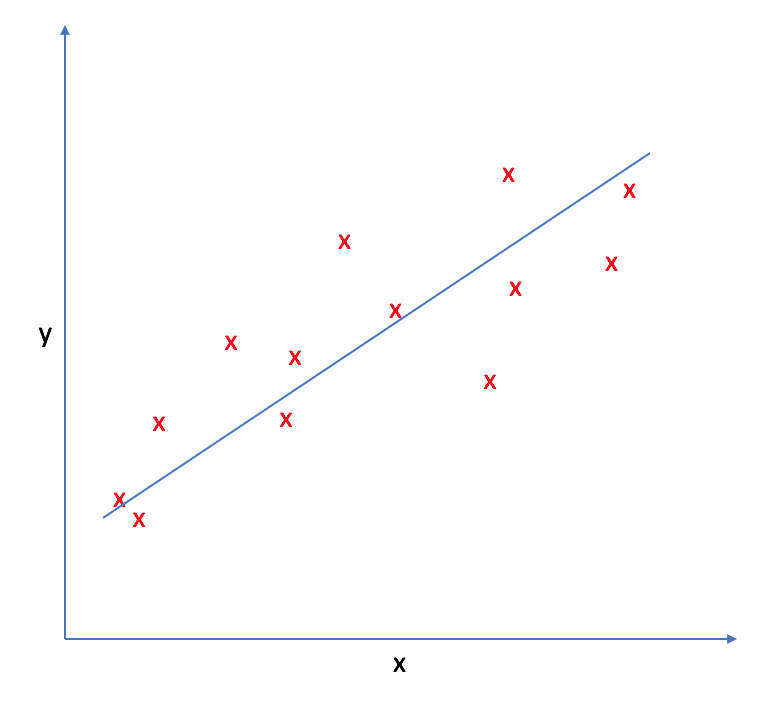
완벽한 예측은 불가능하기 때문에, 데이터의 실제값과 예측값의 차이를 최소한으로 하는 선을 찾아야한다.
선형 회귀는 크게 두 가지 종류로 나눌 수 있다.
- Simple Linear Regression (단순 선형 회귀)
- Multi Linear Regression (다중 선형 회귀)
Simple Linear Regression (단순 선형 회귀)
데이터를 설명하는 모델을 직선형태로 가정하며, 독립변수와 종속변수가 1개
데이터를 가장 잘 설명하는 모델이란 ?
실제값과 예측값과의 차이가 가장 작은 것
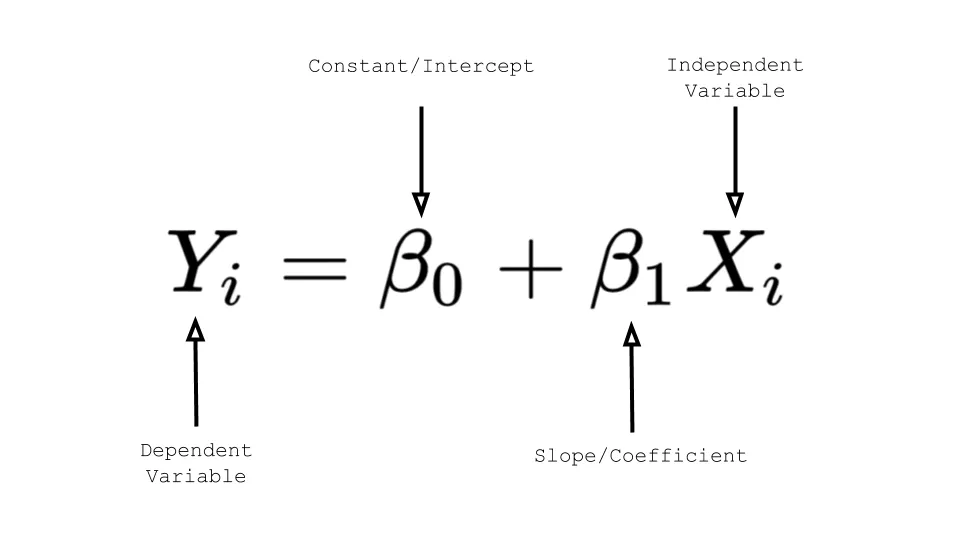
Yi (Dependent Variable)
- 종속 변수로, 예측하고자 하는 값
Constant/Intercept
- y 절편으로, 독립 변수 X 가 0일 때의 종속 변수 Y 값
Slope/Coefficient
- 기울기, 독립 변수X가 1 단위 증가할 때 종속 변수 Y가 얼마나 변하는지를 나타냄
Independent Variable
- 독립 변수 또는 입력 값으로, 종속 변수에 영향을 미치는 요인
목표 : 데이터를 가장 잘 설명하는 직선을 찾는 것
- 직선을 구성하는 y절편과 기울기가 찾아야 할 파라미터이며, 결국 선형 회귀는 최적의 파라미터를 찾는 문제라고 할 수 있다.
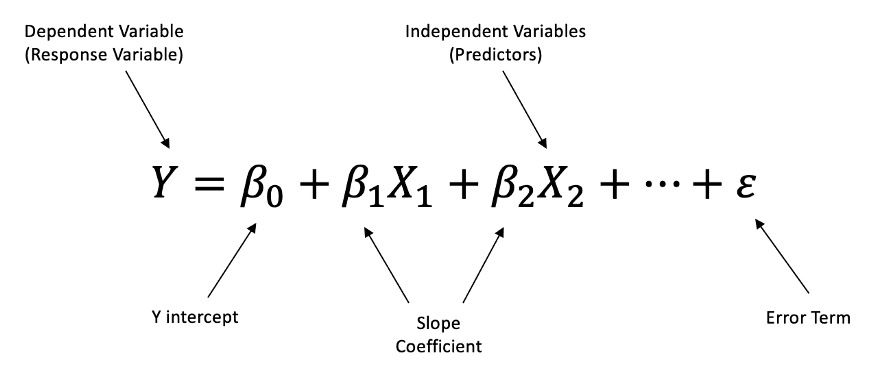
Multi Linear Regression (다중 선형 회귀)
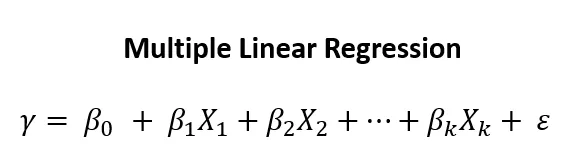
독립 변수 여러 개 (2개 이상), 종속 변수 1개
다중 선형 회귀는 입력값이 1개일 경우 적용하는 단순 선형 회귀 알고리즘과 달리 입력값 X가 여러 개일 때 사용할 수 있는 회귀 알고리즘이다.
LinearRegression 클래스를 다중 선형 회귀에서도 사용이 가능하다.
Polynomial Regression (다항 회귀)
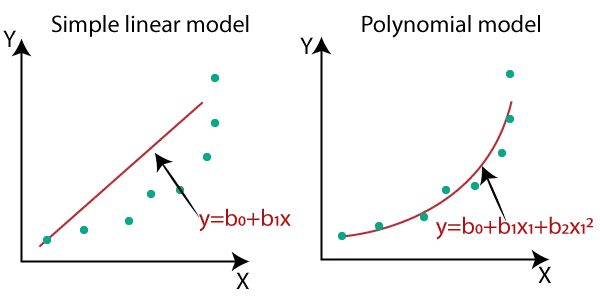
다항 회귀는 2차, 3차 방정식과 같은 다항식을 사용한 회귀
각 특성(feature)의 제곱을 새로운 특성으로 추가하여 선형 모델을 학습
fit()은 새롭게 만들 특성 조합을 찾고, transform()은 실제로 데이터를 변화한다.
from sklearn.preprocessing import PolynomialFeatures
np.random.seed(0)
X = 3 * np.random.rand(50, 1) + 1
y = X**2 + X + 2 + 5 * np.random.rand(50, 1)
poly = PolynomialFeatures(degree=2, include_bias=True)
poly_X = poly.fit_transform(X)poly = PolynomialFeatures(degree, include_bias): Polynomial 객체 poly를 생성한다.
degree: 다항식의 차수
include_bias : 편향 변수의 추가 여부 (True/False)
True로 설정하게 되면, 해당 다항식의 모든 거듭제곱이 0일 경우 편향 변수를 추가한다.
poly.fit_transform(X): 데이터 X와 X의 degree 제곱을 추가한 데이터를 반환
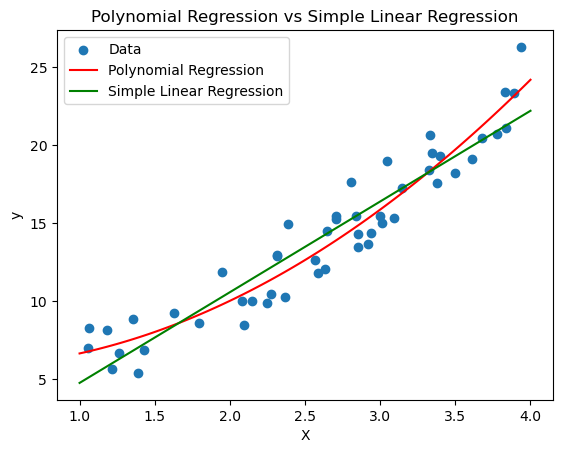
Polynomial이 더 잘 나타냄
Loss Function
그럼 어떻게? -> 실제 값과 예측 값 차이의 제곱의 합으로 비교하자
-
머신러닝이나 딥러닝 모델이 예측한 값과 실제 값 사이의 차이를 측정하는 함수
-
손실함수의 값을 최소화하는 것이 모델 학습의 목표
-
비용 함수(cost function) = 손실 함수(loss function) = 오차 함수(error function) = 목적 함수(objective function) 다 같은 말
References
Simple Linear Regression
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split'''
```python
np.random.seed(0)
X = 5 * np.random.rand(100, 1)
y = 2 * X + np.random.rand(100, 1)```
train_X, test_X, train_y ,test_y = train_test_split(X, y, test_size = 0.3)
model = LinearRegression()
model.fit(train_X, train_y)
predicted = model.predict(test_X)
print("학습 데이터 평가점수 : {}".format(model.score(train_X, train_y)))
print("학습 데이터 평가점수 : {}".format(model.score(test_X, test_y)))
beta_0 = model.intercept_
beta_1 = model.coef_
plt.figure(figsize = (12, 6))
plt.scatter(train_X, train_y)
plt.scatter(test_X, test_y)
plt.plot(test_X, predicted, color='b')
plt.show()```
