SimpleNet: A Simple Network for Image Anomaly Detection and Localization (CVPR 2023)
연구 배경 및 문제
이미지 이상 탐지 (Image Anomaly Detection)는 입력 이미지가 정상인지 비정상인지 판별하는 분류 문제이며, 이상 위치 추정 (Anomaly Localization) 은 이미지 내에서 결함이 존재하는 구체적인 픽셀 단위의 영역을 찾아내는 문제이다.
그러나 실제 산업 현장에서 이상 탐지 방법론을 적용하는 데에는 데이터 불균형이라는 큰 장벽이 존재한다. 제조 공정의 특성상 정상 데이터는 풍부한 반면, 이상(불량) 데이터는 매우 희소하기 때문이다. 또한 이상 형태는 얇은 스크래치 같은 미세한 결함부터 부품 누락과 같은 구조적 결합까지 매우 다양하고 공통된 패턴이 부족하여, 지도 학습(Supervised Learning) 방식으로 모든 이상 케이스를 학습하는 것은 사실상 불가능하다.
따라서 최근 연구들은 정상 데이터만으로 정상 분포를 학습하고, 테스트 시 정상 분포에서 벗어난 패턴을 이상으로 간주하는 비지도 학습(Unsupervised Learning) 또는 One-Class Classification 설정을 주로 따르고 있다.
PaDiM, PatchCore와 같은 기존 SOTA 방법론들은 높은 정확도를 달성했으나, 실용성 측면에서 한계를 보인다. 현장 적용 시에는 정확도뿐만 아니라 추론 속도, 메모리 사용량, 구현 난이도가 중요한 요소이다. 하지만 기존 방법들은 고차원 특징의 처리를 위해 복잡한 통계 모델을 사용하거나, 대규모 메모리 뱅크를 구축해야 하므로 현장 적용에 대한 한계가 존재한다.
SimpleNet은 이러한 문제점을 해결하고자, 복잡한 알고리즘을 배제하고 특징 공간에서의 간단한 노이즈 주입만으로 높은 정확도와 빠른 추론 속도, 적은 메모리 사용량을 동시에 달성하는 것을 목표로 제안되었다.
기존 연구의 한계
기존 이상탐지 방법론은 크게 (1) 재구성 기반, (2) 합성 기반, (3) 임베딩 기반으로 구분할 수 있다.
1) 재구성 기반 (Reconstruction-based)
재구성 기반 방법은 정상 데이터만으로 학습된 모델은 이상 영역을 정확히 복원하지 못할 것이라는 가정에 의존하며, 입력 이미지와 복원된 이미지 간의 픽셀 단위 오차를 이상 점수로 사용한다.
대표적으로 MemAE (ICCV 2019), GAN (2014 NerIPS)와 같이 Auto-Encoder나 GAN을 활용하는 방식이 있으며, 이미지 일부를 가리고 복원하는 Inpainting 기법을 사용하는 RIAD (Pattern Recognition 2021), SSPCAB (CVPR 2022) 등이 제안되어 왔다.
그러나 이상 영역이 정상 데이터와 유사한 저수준 패턴(Local edge, texture 등)을 공유하거나 Decoder의 성능이 과도하게 뛰어난 경우, 이상 영역까지 정상처럼 잘 복원해버리는 '일반화(Generalization)' 문제로 인해 비정상 이미지가 그대로 비정상 이미지로 복원되는 문제점이 존재한다.
2) 합성 기반 (synthesizing-based)
합성 기반 방법은 정상 이미지에 인위적으로 이상 영역을 합성하여 정상과 이상 사이의 결정 경계를 학습하는 방식이다. 대표적으로 정상 이미지의 작은 패치를 잘라내어 무작위한 위치에 붙여넣어 비정상 이미지로 합성하고, 정상 이미지와 합성된 이미지(비정상 이미지)를 구별하도록 학습하는 CutPaste(CVPR 2021)가 있다.
그러나 합성된 이미지가 현실적이지 못하고, 실제 현장의 다양한 불량 이미지와 외관상 일치하지 않아 모델이 실제 이상을 놓치거나, 정상 분포의 경계를 느슨하게 학습하여 미세한 결함을 정상으로 오탐지하는 문제가 생길 수 있다.
3) 임베딩 기반 (embedding-based)
최근 SOTA 성능을 기록하고 있는 임베딩 기반 방법은 ImageNet으로 사전학습된 CNN으로 특징을 추출한 뒤 통계 알고리즘을 활용해 정상 특징 분포를 모델링하는 방식이다.
대표적으로 사전 학습된 네트워크에서 추출된 패치별 특징을 다변량 가우시안 분포로 임베딩하여 정상 분포를 추정하는 PaDiM(ICPR 2021), 대표성 있는 특징들만 선별(Coreset sampling)하여 저장하여 메모리 뱅크(Memory Bank)를 구축하고, 테스트 시 저장된 특징들과의 최근접 이웃 거리를 계산하여 이상을 탐지하는 PatchCore(CVPR 2022), Normalizing Flow를 활용하여 복잡한 정상 특징의 분포를 가우시안 분포로 변환하여 모델링하는 CS-Flow(WACV 2022) 등이 있다.
그러나 산업 도메인과 ImageNet 간 도메인 차이(편향)로 인한 Mismatch 문제가 발생할 수 있으며, 공분산 역행렬/최근접 탐색/flow 등에서 오는 높은 계산 및 메모리는 실시간 탐지 적용에 제약이 된다.
이 외에도 Teacher 네트워크와 이를 모방하도록 정상 데이터로만 학습된 Student 네트워크를 활용하는 지식 증류 기반 방식이 있으며, 대표적으로 Student-Teacher AD (CVPR 2020)와, 이를 역방향으로 구조화하여 성능을 높인 Reverse Distillation (CVPR 2022) 등이 있다. 그러나 입력 이미지가 Teacher, Student 네트워크를 모두 통과해야 하므로, 단일 네트워크 모델에 비해 계산 복잡도가 높고 연산량이 많다는 단점이 있다.
제안 방법론
SimpleNet은 합성 기반 (synthesizing-based)과 임베딩 기반 (embedding-based) 방식의 장점을 활용하면서 해당 방법론들의 한계점에 대응되는 전략들을 제시한다.
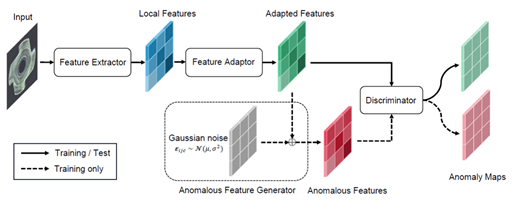
-
Pre-trained feature를 그대로 사용하지 않고 Feature Adaptor를 통해 Target-Oriented Feature를 만들어 Domain Bias을 줄이고 타깃 도메인에 맞게 변환한다.
-
이미지에 직접 이상 영역을 합성하는 대신, 특징 공간에서 정상 특징에 노이즈를 주입해 이상 특징을 생성한다.
-
복잡한 통계 알고리즘 대신 단순한 MLP Layer로 구성된 Discriminator가 정상/이상 특징을 구분하도록 학습해 계산 효율을 높인다.
Feature Extractor
사전학습된 백본 네트워크 로부터 다중 계층 Feature를 추출하고, 각 특징 맵의 위치 (h, w)에 대해, 패치 크기 p를 갖는 이웃 를 다음과 같이 정의한다.
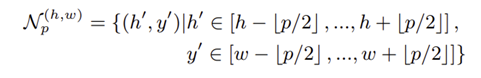
이웃 안의 Feature들을 집계함수로 계산하며, Adaptive Average Pooling을 사용하여 Local Pacth Feature를 획득한다.
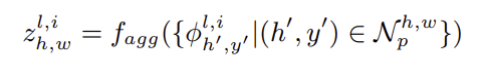
서로 다른 계층에서 얻은 Local Feature Map 들을 가장 큰 해상도 로 resize한 뒤, 채널 방향으로 이어붙여(Channel-wise concat) 최종 Feature Map 를 만든다. 이를 하나의 Feature Extractor로 정의한다.
Feature Adaptor
산업 이미지의 분포는 사전 학습에 사용된 ImageNet과 상이하므로, 단순히 사전 학습 Feature를 그대로 사용하는 경우 도메인 불일치 문제가 발생할 수 있다. 이를 완화하기 위해 SimpleNet 은 Feature Adaptor 𝐺𝜃를 도입하여, 사전 학습된 특징을 타겟 도메인에 적합한 특징 공간으로 전이시킨다.
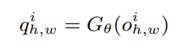
Feature Adaptor는 FC layer나 MLP와 같은 간단한 신경망으로 구성될 수 있으며, 실험 결과 단일 FC Layer를 사용하는 경우에도 충분한 표현력을 확보할 수 있었고, 오히려 복잡한 구조보다 더 우수한 성능을 보였다.
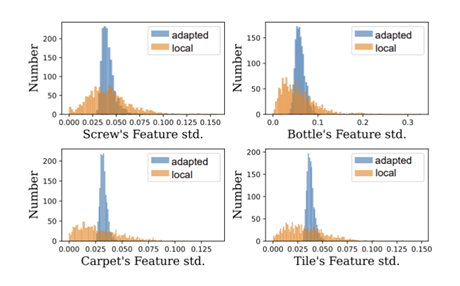
Feature Adaptor를 거친 adapted feature는 각 차원별 표준편차가 보다 일정한 분포를 형성하는 경향을 보이며, 이는 정상 특징과 이상 특징을 구분하는 과정에서 특징 공간이 더욱 조밀하고 안정적으로 형성되었음을 의미한다. 결과적으로, 이러한 특징 공간의 특성은 이상 특징과 정상 특징 간의 분리를 보다 용이하게 만들고, 이렇게 Feature Adaptor를 통해 생성된 특징은 이후 특징 공간에서 합성된 이상 특징과 함께 Discriminator에 입력된다.
Anomalous Feature Generator
직접적으로 이상 영역을 합성하기에는 실제 산업 환경에서의 이상 데이터가 극히 제한적이고 다양하므로, 이를 보완하기 위해 논문에서는 이미지 공간에서 결함을 조작하여 생성하는 기존 방식과 달리, 특징 공간에서 정상 특징에 간단한 노이즈를 추가하는 방법을 제안한다.
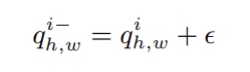
이상 특은 정상 특징 (Feature Adaptor를 통해 변환된 정상 특징)에 가우시안 노이즈 ε를 더하여 생성되며, 이러한 방식으로 생성된 이상 특징은 정상 특징과 함께 판별기(Discriminator)의 학습에 사용되며, 이를 통해 정상 특징 공간의 경계를 보다 명확하게 학습할 수 있다.
Discriminator
Discriminator는 각 위치 (h, w)에서 정상성을 직접 추정하는 점수 측정기로 작동한다.
학습 단계에서는 Feature Adaptor를 거친 정상 특징과, 가우시안 노이즈를 통해 생성된 이상 특징이 모두 입력된다. Discriminator는 정상 특징에 대해서는 높은 값, 이상 특징에 대해서는 낮은 값(음수 값)을 출력하도록 학습된다.
Discriminator는 일반적인 분류기와 유사하게 2- layer MLP 구조로 구성되며, 복잡한 통계 모델 대신 단순한 구조를 사용함으로써 계산 효율을 확보한다.
Loss function and Training
정상 특징과 이상 특징을 효과적으로 구분하기 위해, 본 논문에서는 Truncated L1 loss를 사용한다. 각 위치 (ℎ, w) 에서의 손실 함수는 다음과 같이 정의된다.
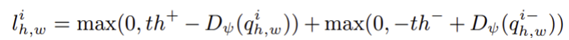
th+와 th-은 truncation 항으로 Discriminator의 출력이 일정 범위를 넘어서더라도 추가적인 Loss 증가를 제한함으로써 과도한 출력 값으로 인한 과적합을 방지하는 역할을 한다. 본 논문에서는 기본적으로 0.5, -0.5 로 설정된다.
이 손실 함수는 정상 특징에 대해서는 출력이 0.5 이상이 되도록 유도하고, 이상 특징에 대해서는 출력이 -0.5 이하가 되도록 유도한다. 이를 통해 정상과 이상 특징 간의 명확하지만 과도하지 않은 결정 경계를 설정할 수 있으며, 이는 다양한 형태의 결함에 대해 일반화 성능을 높이는 데 기여한다.
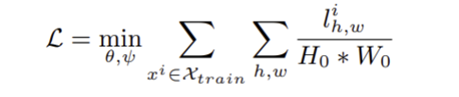
전체 학습 목적 함수는 모든 학습 샘플과 위치에 대해 평균 손실을 최소화하는 방식으로 정의된다. 학습 과정에서 Feature Extractor는 사전 학습된 가중치를 유지한 채 고정되며, Feature Adaptor와 Discriminator만이 역전파를 통해 업데이트된다. 이를 통해 일반적인 시각적 특징 표현은 유지하면서도, 타겟 도메인에 특화된 이상 판별 기준을 효율적으로 학습할 수 있다.
Inference and Scoring function
추론 단계에서는 Anomalous Feature Generator를 제거하고, Feature Extractor와 Feature Adaptor, Discriminator로만 구성된 단일 스트림 구조를 사용한다. 입력 이미지는 Feature Extractor와 Feature Adaptor를 순차적으로 통과하여 특징을 얻는다.
이상 점수는 Discriminator의 출력에 음수를 취한 값으로 정의된다.
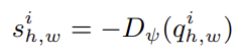
이를 이용해 이상 영역을 나타내는 이상 map은 다음과 같이 정의된다.
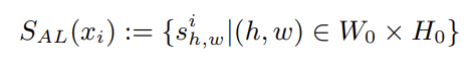
이상 map은 입력 이미지 크기로 보간된 후, 경계의 부드러운 표현을 위해 가우시안 필터링이 적용되며, 최종적으로 이미지 단위의 이상 점수는 이상 map의 최대값으로 정의된다.
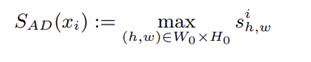

해당 과정들을 요약하면, 학습 단계에서는 정상 이미지 𝑥를 입력으로 하여, 사전 학습된 Feature Extractor 𝐹를 통해 정상 특징을 추출하고, Feature Adaptor 𝐺를 통해 타겟 도메인에 적응된 특징을 생성한다.
이후 적응된 특징에 가우시안 노이즈를 추가하여 이상 특징을 생성하고, 정상 특징과 이상 특징에 대해 Discriminator 𝐷를 학습한다.
이 과정에서 Feature Extractor는 고정되어 업데이트되지 않으며, Feature Adaptor와 Discriminator만 역전파를 통해 학습된다. 이를 통해 사전 학습 특징의 일반성을 유지하면서도, 타겟 도메인에 특화된 이상 판별 경계를 효율적으로 학습할 수 있다.
결과
실험 환경
논문에서는 모든 입력 이미지를 데이터 증강 없이 256×256으로 리사이징한 후, 224×224 크기로 center crop하여 실험을 수행하였다. 또한, 산업 이상 탐지뿐만 아니라 일반적인 원-클래스 이상 탐지 성능을 평가하기 위해 CIFAR-10 데이터셋을 활용한 One-Class Novelty Detection 실험도 함께 수행하였다.
평가 지표
이상 탐지 성능 평가는 이미지 단위 이상 탐지 성능을 측정하는 I-AUROC와, 픽셀 단위 이상 위치 추정 성능을 평가하는 P-AUROC를 기준으로 수행되었다.
구현 세부사항
모든 실험에서는 ImageNet으로 사전 학습된 백본 네트워크를 사용하였으며, 기본 설정으로 WideResNet50을 채택하였다. Feature Extractor에는 백본의 layer 2와 3에서 추출한 특징을 활용하였고, 이상 특징 생성을 위해 가우시안 노이즈의 표준편차 σ를 0.015로 설정하였다. Discriminator는 Linear–Batch Normalization–Leaky ReLU–Linear 구조로 구성되었으며, 모델은 총 160 epoch 동안 학습되었다.
실험 결과
실험 결과, SimpleNet은 전체 15개 클래스 중 9개 클래스에서 가장 높은 이상 탐지 성능을 기록하였다. Texture 클래스와 Object 클래스에 대해 I-AUROC는 각각 99.8%, 99.5%, 전체 평균 I-AUROC는 99.6%을 달성하였다. 이상 위치 추정 성능 측면에서도 평균 98.1%의 P-AUROC를 기록하여 비교 대상 방법들 중 가장 우수한 성능을 보였다. 또한 추론 속도 측면에서 Nvidia RTX 3080Ti GPU 기준 약 77 FPS를 기록하여, PatchCore(약 10 FPS 수준) 대비 약 8배 빠른 속도를 보여주었다.
Ablation Study
Ablation study에서는 (1) 특징 추출 설정, (2) Feature Adaptor 구조, (3) 노이즈 스케일 σ, (4) 손실 함수 및 백본 의존성을 중심으로 성능 변화를 분석하였다.
그 결과, 이웃 크기 p=3 및 Layer 2+3 조합이 가장 우수한 성능을 보였다. Feature Adaptor 구성에서는 편향이 없는 단일 FC Layer가 가장 안정적이고 높은 성능을 보였으며, 복잡한 Adaptor 구조는 과적합으로 인해 성능이 저하되는 경향이 관찰되었다.
또한 노이즈 스케일 σ는 성능에 큰 영향을 주었으며, σ가 너무 크면 경계가 느슨해지고 너무 작으면 학습이 불안정해지는 경향이 나타났다. 논문에서는 σ=0.015에서 최적의 성능을 보고하였다.
손실 함수 측면에서는 제안된 Truncated L1 loss가 Cross-Entropy loss 대비 약 0.2%의 I-AUROC 성능 향상을 보였고, 백본 의존성 실험에서는 ResNet18, ResNet50, ResNet101, WideResNet50 전반에서 비교적 안정적인 성능이 유지됨을 확인하였다. 추가로 CIFAR-10 기반 One-Class Novelty Detection 실험에서도 86.5%의 AUROC를 기록하여 비교 방법론들보다 우수한 성능을 보였으며, 이를 통해 산업 이상 탐지뿐만 아니라 일반적인 one-class 이상 탐지 문제에서도 효과적임을 확인하였다.
