[논문 리뷰] PatchCore: Towards Total Recall in Industrial Anomaly Detection (Roth et al., CVPR 2022)
PatchCore: Towards Total Recall in Industrial Anomaly Detection (Roth et al., CVPR 2022)
Unsupervised Anomaly Detection
- Density-based : 정상 데이터의 분포를 통해 비정상 데이터 탐지
- Classification-based : one- class classification 적용하여 비정상 데이터 탐지
- Reconstruction-based : 정상 데이터만을 복원하도록 학습하여 비정상 데이터 추론 시 재구축된 결과와의 차이로 비정상 데이터 탐지
Density-based
- 사전 학습된 모델 사용
- 추가적인 학습 필요 X
Related Work
-
SPADE
- 사전 학습된 네트워크로 추출한 feature를 그대로 사용
- kNN 기반 anomaly score 측정
-
PaDiM
- 각 patch 위치별로 정상 분포의 mean, covariance를 추정 → Mahalanobis distance로 anomaly score 계산 (같은 위치의 패치들끼리만 score 측정, 가장 먼 거리로 anomaly score 측정)
- 한계 : input 이미지 크기 고정, patch alignment에 의존 (동일 위치의 patch feature끼리 비교)
- 각 patch 위치별로 정상 분포의 mean, covariance를 추정 → Mahalanobis distance로 anomaly score 계산 (같은 위치의 패치들끼리만 score 측정, 가장 먼 거리로 anomaly score 측정)
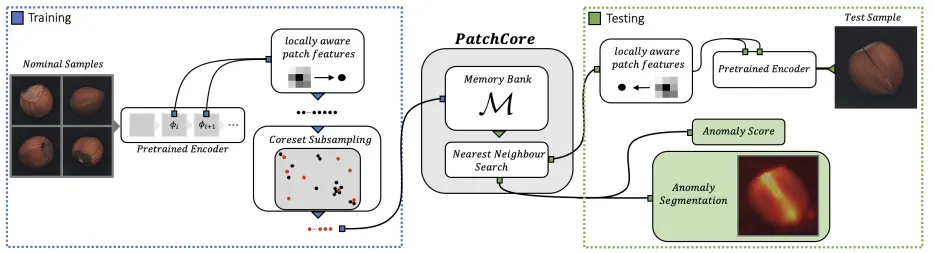
PatchCore
-
locally aware한 patch feature 만들기
-
coreset subsampling → 계산 시간 줄이기
-
PatchCore: 패치들이 공유 메모리 뱅크를 사용 → 다양한 정상 패턴을 전역적으로 저장
이미지 정렬 요구가 줄어들고, 더 큰 범위의 정상 문맥을 활용 가능
-
다양한 크기/비율의 이미지를 처리할 수 있다는 점도 장점
Method
- Locally Aware Patch Features
- Coreset-Reduced Memory Bank
- Anomaly Detection & Localization
Locally Aware Patch Features
사전 학습 네트워크(ResNet-50, WideResNet-50-2)에서 feature를 추출
High level feature은 공간적 정보가 많이 사라짐 + 분류 작업에 최적화 되어있음
→ mid-level의 feature를 사용
-
예: ResNet block 2, 3의 feature 사용 (WideResNet-50-2의 2/3 블록)
Local Neighbourhood 집계
추출한 feature map의 주변 patch들을 함께 사용
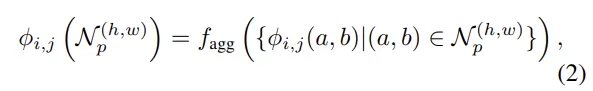
- feature map의 patch 중심 (h, w)를 기준으로 p × p 크기의 패치 영역
주변 이웃의 feature들을 모아 adaptive average pooling으로 하나의 벡터로 합침 (aggregation)
→ Locally Aware Patch Feature
Patchcore는 여러 계층 feature를 결합해 사용
- 계층 j, j+1 두 레벨에서 feature map를 뽑고
- 상위 계층 feature를 bilinear upsampling해서 해상도를 맞춤 (다음 계층 feature는 해상도가 낮으므로)
최종적으로 patch feature set 구축
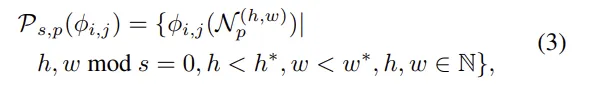
- s : stride
- p : local neighbourhood window 크기
Memory Bank 구축
- 모든 정상 이미지를 대상으로 위 과정을 수행하고 합쳐 메모리 뱅크 생성
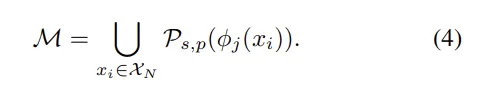
Coreset-Reduced Memory Bank
만든 메모리 뱅크는 정상 이미지의 모든 패치를 포함 → 크기가 매우 크고 연산 비용이 높음
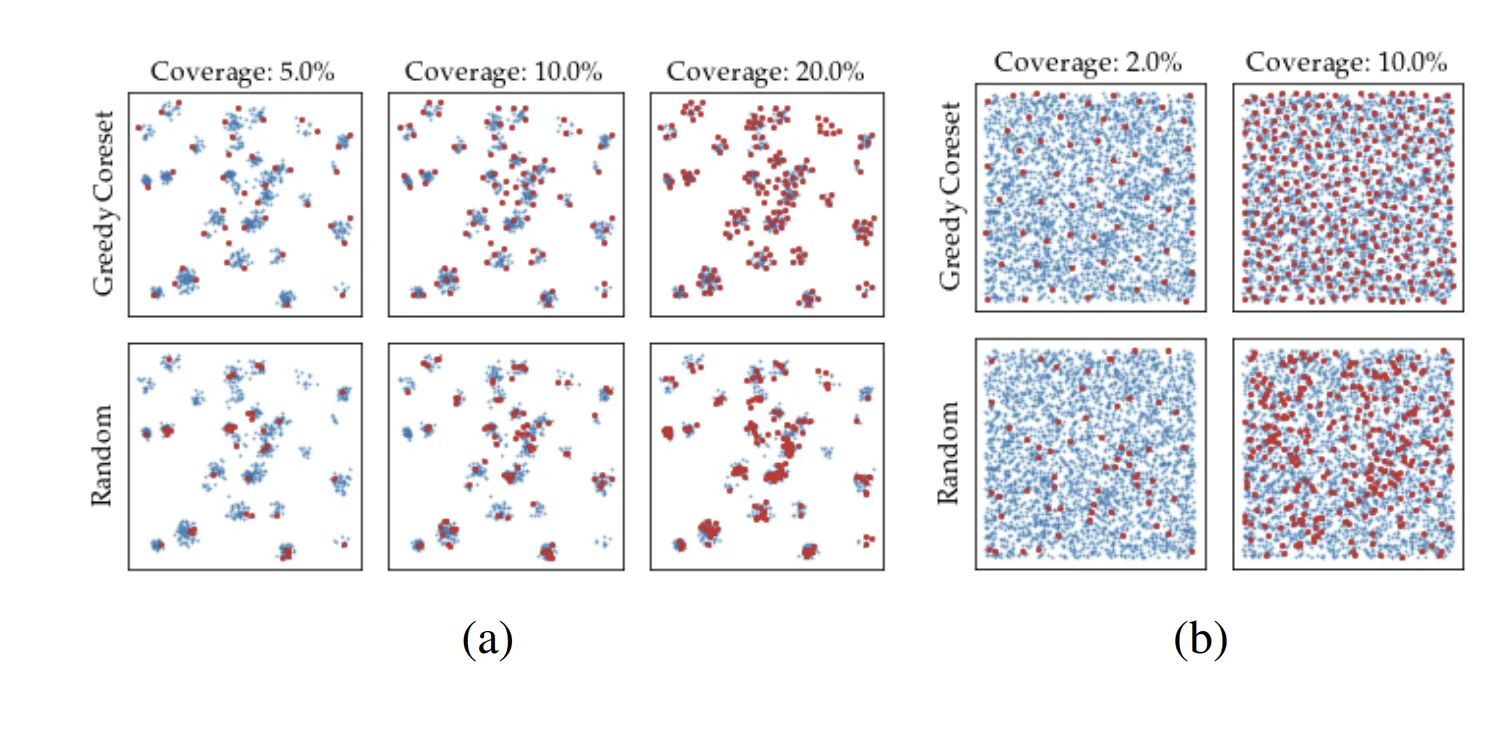
Coreset 기반 서브샘플링
- 정상 분포를 충분히 대표하면서도 크기를 줄인 subset
- 단순 random subsampling에 비해 효율적

1. 처음 임의의 포인트를 선택
2. 매 단계마다 현재 선택된 집합에서 가장 멀리 떨어진 포인트를 추가
3. 원하는 개수가 될때까지 반복
- feature 차원이 크기 때문에 거리 계산이 느릴 수 있어, Johnson–Lindenstrauss으로 random linear projection 후 거리 계산 (feature를 저차원으로 임베딩 후 거리 계산)
Reduced memory Bank
- PatchCore-25% : M의 25%만 사용
- PatchCore-10% : 10%
- PatchCore-1% : 1%
메모리 뱅크의 1%만 사용해도 성능 거의 유지 + 속도 크게 향상
Anomaly Detection & Localization
Coreset으로 압축된 메모리 테스트 이미지의 각 패치가 정상 패치 공간으로부터 얼마나 떨어져 있는지를 계산하여 이상 여부를 판단
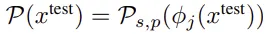
테스트 이미지의 모든 위치에 대한 patch-level feature
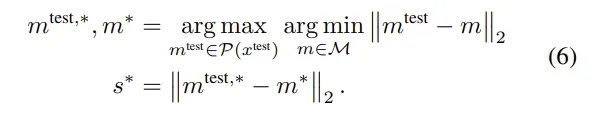
arg min : m test와 가장 가까운 정상 패치를 찾는 kNN
arg max : 모든 패치중에 가장 멀리 떨어져있는 이상치 패치 선택
→ 테스트 이미지에서 정상 분포와의 최소 거리가 가장 큰 패치를 선택
s∗이 anomaly score가 됨
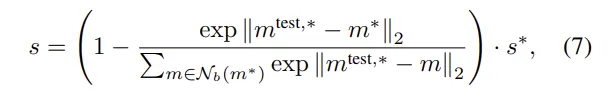
보정식
정상 패치의 국소 밀도(local density) 기반 weight를 곱해
희귀(normality가 낮은) 영역에서의 anomaly를 더 강하게 반영하는 보정식
Experiments
MVTec AD
- 15 클래스, 총 5354장, test 1725장
- 클래스별로 정상 train 이미지 + 정상/불량 test 이미지 + pixel GT mask 제공
- 이미지 전처리: resize + center crop (256→224 등)
- 평가:
- Image-level AUROC
- Pixel-wise AUROC
- PRO (Per-Region Overlap) score: 다양한 anomaly 크기를 고려하는 segmentation 평가지표
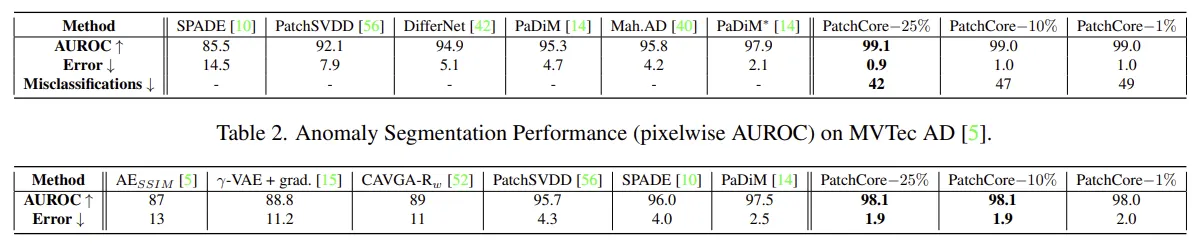
Ablation Study
Low-shot Anomaly Detection
- 정상 샘플 개수를 1, 2, 5, 10, 16, 20, 50으로 줄여 실험
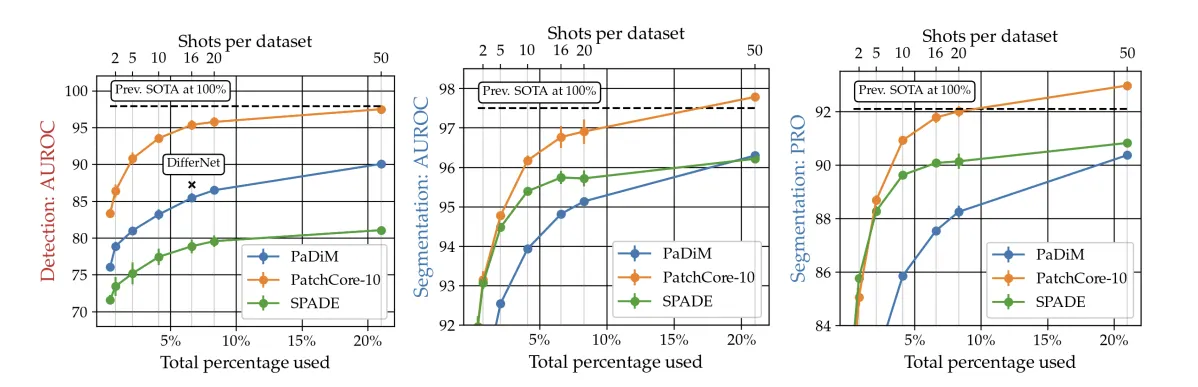
- 결과:
- 정상 이미지의 20% 이하만 써도 기존 SOTA와 거의 비슷한 성능
- 5-shot/10-shot에서도 SPADE/PaDiM보다 높은 이미지/픽셀 AUROC
정상 데이터가 많지 않은 상황에서도 성능이 잘 유지 → 실제 현장에서 유리
