CNN - Pooling
Feature map의 channel resolution을 줄여주는 용도로 Pooling이 사용된다
Resize the feature map & Reduce the resolution of feature map
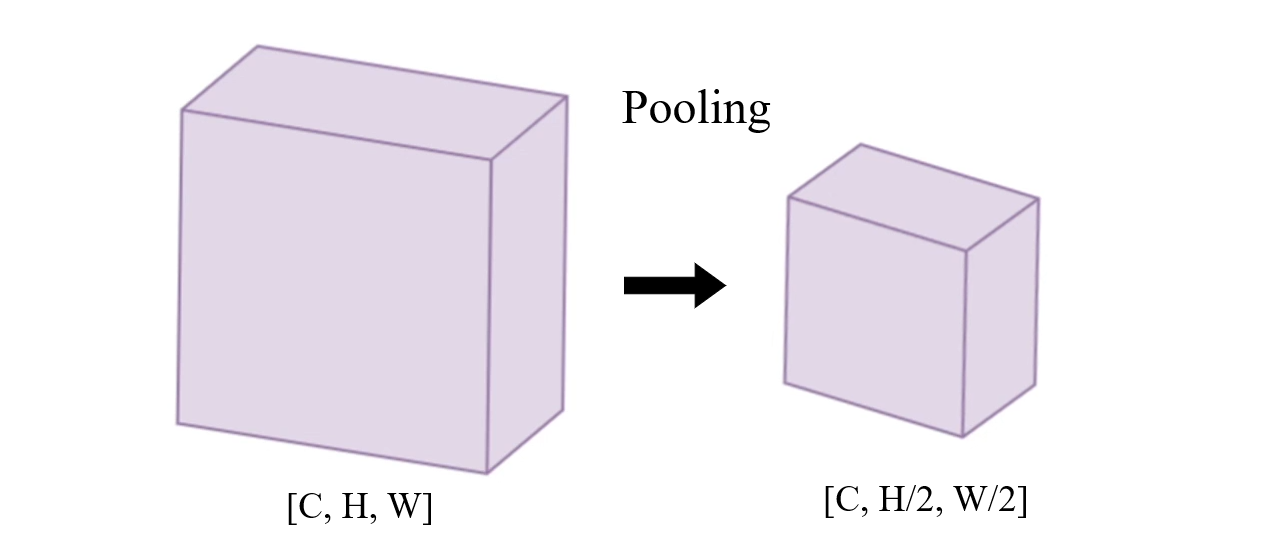
-
Max Pooling vs Average Pooiling
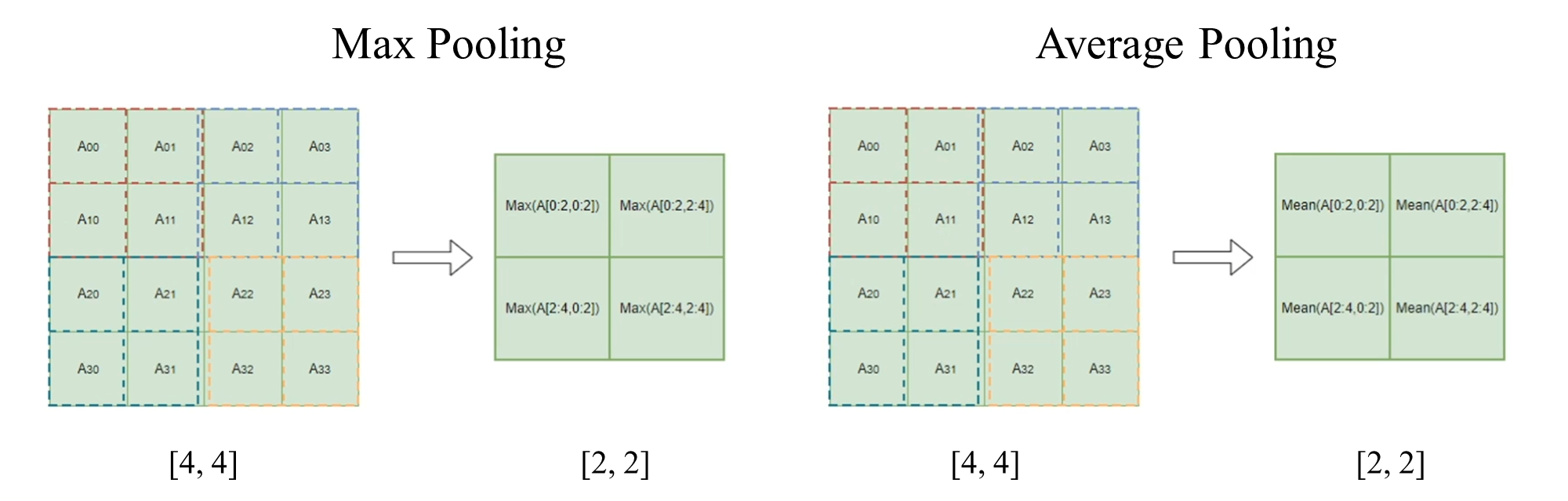
- Max -> 선명한 느낌, 각 픽셀의 특징이 보인다, 연속적이지 않다
- Ave -> 주변의 영향을 받아서 평균값으로 스무딩된 느낌이다

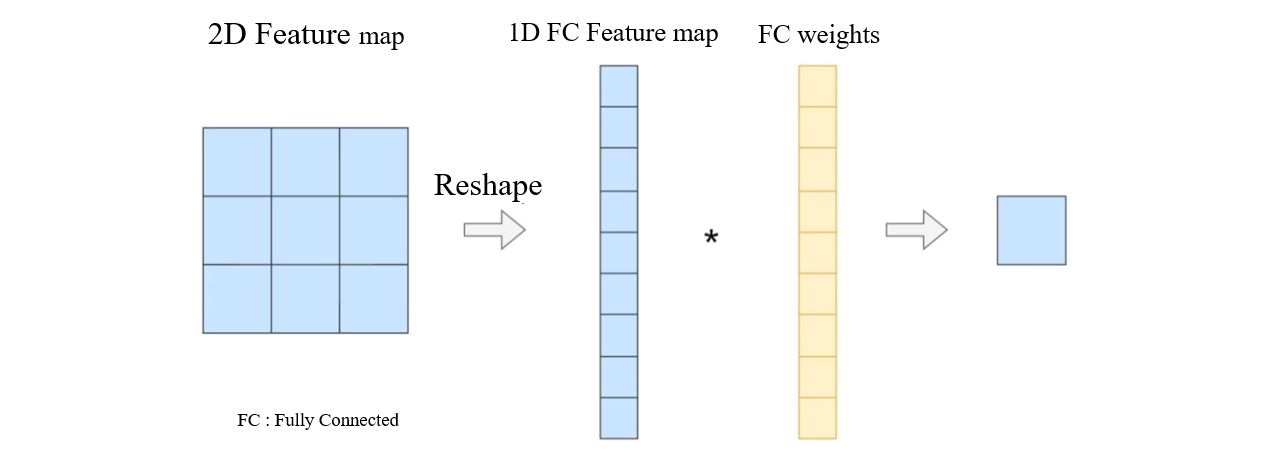
Fully Connected Layer
컨볼루션 연산과 다르게 2D의 기하학적인 정보를 가지고 있는 Feature map을 1D 벡터로 reshape을 시켜준다. 한 요소당 한 가중치와 매칭될 수 있게 FC weights를 만들어서 연산 후 합하여 결과를 도출한다
Reshape 2D feature maps from 2D to 1D
All weights are matching with each feature map pixel
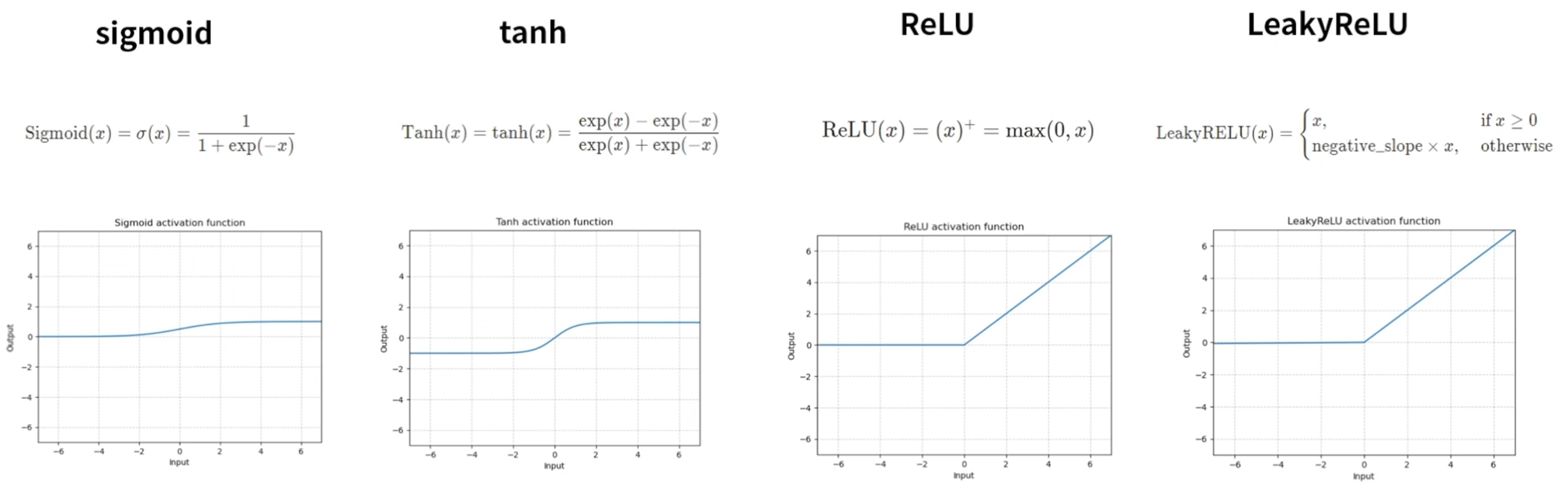
Activation
컨볼루션과 풀링을 통해 나온 결과 중 Feature map에서 유의미한 값을 더욱 도드라지게 만들어주며 유의미하지 않은 값을 0이나 음수의 값으로 치환하여 값에 차이를 주어 유의미한 값을 잘 나타내게 끔 활성화 함수가 사용된다
Activation 함수는 Non-linear function이다
실습
main.py (forward_net() -> Conv2d, Pooling, fully connected layer)
from function.convolution import Conv
from function.pool import Pool
from function.fc import FC
import numpy as np
import time
def forward_net():
"""_summary_
'Conv - Pooling - FC' model inference code
"""
#define
batch = 1
in_c = 3
in_w = 6
in_h = 6
k_h = 3
k_w = 3
out_c = 1
X = np.arange(batch*in_c*in_w*in_h, dtype=np.float32).reshape([batch,in_c,in_w,in_h])
W1 = np.array(np.random.standard_normal([out_c,in_c,k_h,k_w]), dtype=np.float32)
Convolution = Conv(batch = batch,
in_c = in_c,
out_c = out_c,
in_h = in_h,
in_w = in_w,
k_h = k_h,
k_w = k_w,
dilation = 1,
stride = 1,
pad = 0)
L1 = Convolution.gemm(X,W1)
print("L1 shape : ", L1.shape)
print(L1)
Pooling = Pool(batch=batch,
in_c = 1,
out_c = 1,
in_h = 4,
in_w = 4,
kernel=2,
dilation=1,
stride=2,
pad = 0)
L1_MAX = Pooling.pool(L1)
print("L1_MAX shape : ", L1_MAX.shape)
print(L1_MAX)
#fully connected layer
W2 = np.array(np.random.standard_normal([1, L1_MAX.shape[1] * L1_MAX.shape[2] * L1_MAX.shape[3]]), dtype=np.float32)
Fc = FC(batch = L1_MAX.shape[0],
in_c = L1_MAX.shape[1],
out_c = 1,
in_h = L1_MAX.shape[2],
in_w = L1_MAX.shape[3])
L2 = Fc.fc(L1_MAX, W2)
print("L2 shape : ", L2.shape)
print(L2)
if __name__ == "__main__":
forward_net()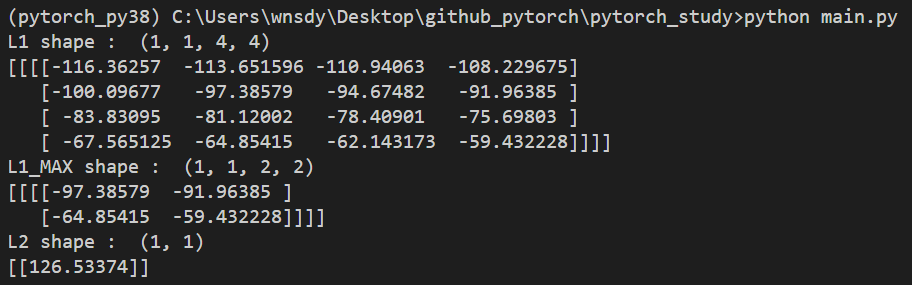
pool.py
import numpy as np
# 2D Pooling
class Pool:
def __init__(self, batch, in_c, out_c, in_h, in_w, kernel, dilation, stride, pad):
self.batch = batch
self.in_c = in_c
self.out_c = out_c
self.in_h = in_h
self.in_w = in_w
self.kernel = kernel
self.dilation = dilation
self.stride = stride
self.pad = pad
self.out_w = (in_w - kernel + 2 * pad) // stride + 1
self.out_h = (in_h - kernel + 2 * pad) // stride + 1
def pool(self, A):
C = np.zeros([self.batch, self.out_c, self.out_h, self.out_w], dtype=np.float32)
for b in range(self.batch):
for c in range(self.in_c):
for oh in range(self.out_h):
a_j = oh * self.stride - self.pad
for ow in range(self.out_w):
a_i = ow * self.stride - self.pad
max_value = np.amax(A[:, c, a_j:a_j+self.kernel, a_i:a_i+self.kernel])
C[b, c, oh, ow] = max_value
return Cfc.py
import numpy as np
class FC:
def __init__(self, batch, in_c, out_c, in_h, in_w):
self.batch = batch
self.out_c = out_c
self.in_c = in_c
self.in_h = in_h
self.in_w = in_w
def fc(self, A, W):
#A shape : [b,in_c, in_h, in_w]
a_mat = A.reshape([self.batch, -1])
B = np.dot(a_mat, np.transpose(W, (1,0)))
return Bmain.py (activation)
import matplotlib.pyplot as plt
import numpy as np
from function.activation import *
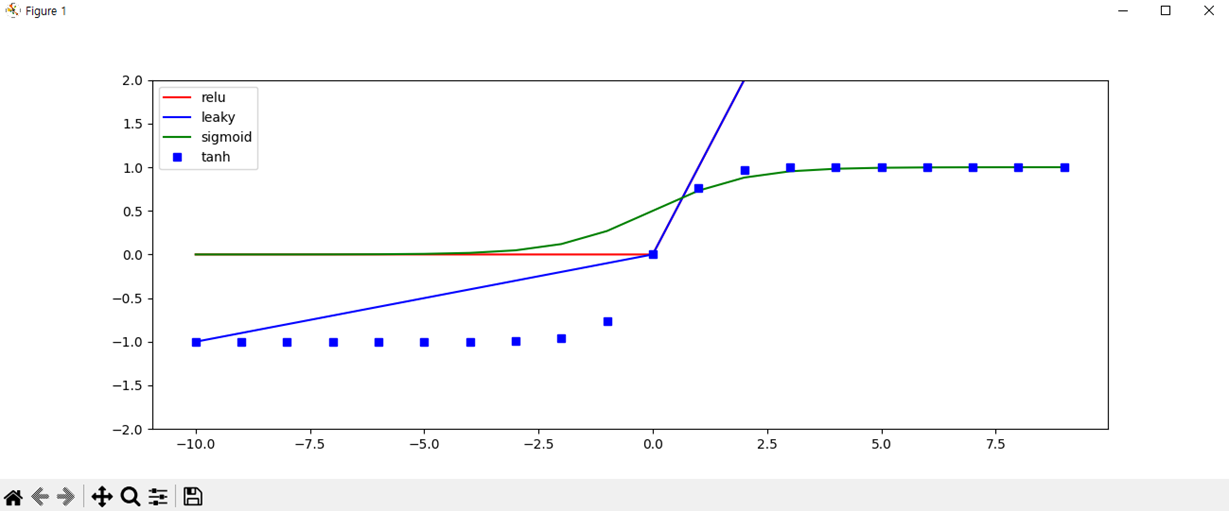
def plot_activation():
"""_summary_
Plot the activation output of [-10,10] inputs
activations : relu, leaky_relu, sigmoid, tanh
"""
x = np.arange(-10,10,1)
out_relu = relu(x)
out_leaky = leaky_relu(x)
out_sigmoid = sigmoid(x)
out_tanh = tanh(x)
#print(out_relu, out_leaky, out_sigmoid, out_tanh)
plt.plot(x, out_relu, 'r', label='relu')
plt.plot(x, out_leaky, 'b', label='leaky')
plt.plot(x, out_sigmoid, 'g', label='sigmoid')
plt.plot(x, out_tanh, 'bs', label='tanh')
plt.ylim([-2,2])
plt.legend()
plt.show()activation.py
import numpy as np
def relu(x):
x_shape = x.shape
x = np.reshape(x,[-1])
x = [max(v,0) for v in x]
x = np.reshape(x, x_shape)
return x
def leaky_relu(x):
x_shape = x.shape
x = np.reshape(x, [-1])
x = [max(0.1*v,v) for v in x]
x = np.reshape(x, x_shape)
return x
def sigmoid(x):
x_shape = x.shape
x = np.reshape(x,[-1])
x = [ 1 / (1 + np.exp(-v)) for v in x]
x = np.reshape(x, x_shape)
return x
def tanh(x):
x_shape = x.shape
x = np.reshape(x, [-1])
x = [np.tanh(v) for v in x]
x = np.reshape(x,x_shape)
return x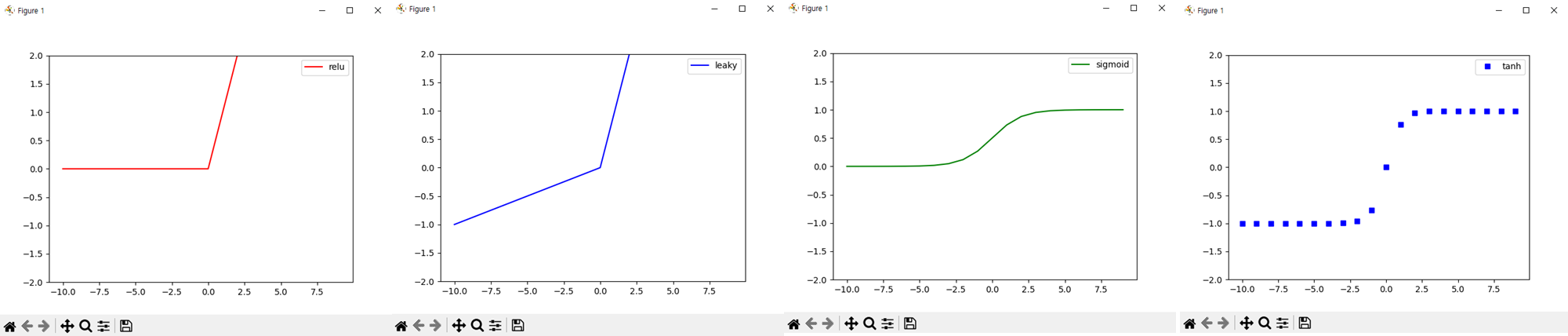
https://github.com/Jun-yong-lee/pytorch_study/tree/Convolution

도전하는 개발자 지망생