프로그래머스 데이터 분석 과제
프로그래머스 채용공고를 보고 지원할 확률을 맞추어보자.
주어진 데이터.
[머신러닝] 채용 공고 추천
programmers 채용 공고 페이지를 방문한 개발자들의 방문/지원 기록을 바탕으로 추천 모델을 만들어야 한다.
구체적으로 개발자와 채용공고를 보고, 개발자가 해당 채용 공고에 지원할지 안 할지를 예측하는 Binary Classifier를 만들자.
data set은 다음과 같이 존재한다.
train.csv - 개발자 ID, 구인공고, 해당 구인공고를 보고 지원을 했는지
job_tags.csv - 잡의 키워드를 나타낸다.
user_tags.csv - 각 개발자가 등록한 키워드를 나타낸다.
tags.csv - 무슨 tag인지 기술한다.
job_companies.csv - 회사 id, 잡 id, 회사 규모
test.csv - userid, job id
*데이터의 저작권은 프로그래머스에 있습니다.
모델 설계.
0 1로 나뉘는 Binary classifier가 목적이므로, 가능한 분류모델이 로지스틱 회귀, Random Forest 정도를 사용할 수 있겠다.
모델을 정하기 전에 데이터를 살펴보자. 만약 데이터에서 지원한 직무에 관하여 알아본다면 지원자와 직무 그리고 회사간의 연관관계가 어떻게 구성되어 있는지 알 수 있을 것이다.
모듈 불러오기
numpy, sklearn, pandas,모듈을 사용한다
# 모듈 로드
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestClassifier
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as snsjob_companies = pd.read_csv('./data/job_companies.csv')
job_companies| tagID | keyword | |
|---|---|---|
| 0 | 602d1305678a8d5fdb372271e980da6a | Amazon Web Services(AWS) |
| 1 | e3251075554389fe91d17a794861d47b | Tensorflow |
| 2 | a1d50185e7426cbb0acad1e6ca74b9aa | Docker |
| 3 | 884d79963bd8bc0ae9b13a1aa71add73 | Git |
| 4 | 4122cb13c7a474c1976c9706ae36521d | Python |
| ... | ... | ... |
| 882 | 818f4654ed39a1c147d1e51a00ffb4cb | 활용 |
| 883 | 7cce53cf90577442771720a370c3c723 | mybais |
| 884 | c2aee86157b4a40b78132f1e71a9e6f1 | * |
| 885 | 1fb2a1c37b18aa4611c3949d6148d0f8 | Autodesk Maya |
| 886 | 5fa9e41bfec0725742cc9d15ef594120 | Apache Pig |
887 rows × 2 columns
train = pd.read_csv('./data/train.csv')
train| userID | tagID | |
|---|---|---|
| 0 | e576423831e043f7928d9ac113abbe6f | 82c2559140b95ccda9c6ca4a8b981f1e |
| 1 | e576423831e043f7928d9ac113abbe6f | 2ba8698b79439589fdd2b0f7218d8b07 |
| 2 | e576423831e043f7928d9ac113abbe6f | 351b33587c5fdd93bd42ef7ac9995a28 |
| 3 | e576423831e043f7928d9ac113abbe6f | 81e5f81db77c596492e6f1a5a792ed53 |
| 4 | e576423831e043f7928d9ac113abbe6f | 0e095e054ee94774d6a496099eb1cf6a |
| ... | ... | ... |
| 17189 | 3ab88dd28f749fe4ec90c0b6f9896eb5 | 801c14f07f9724229175b8ef8b4585a8 |
| 17190 | 3ab88dd28f749fe4ec90c0b6f9896eb5 | 95151403b0db4f75bfd8da0b393af853 |
| 17191 | 3ab88dd28f749fe4ec90c0b6f9896eb5 | f47330643ae134ca204bf6b2481fec47 |
| 17192 | 15d84e9a5eceb67bcb8fb0e8c839a903 | 285f89b802bcb2651801455c86d78f2a |
| 17193 | 3fb6224c45e07abd01a213f707d2219b | 7d771e0e8f3633ab54856925ecdefc5d |
17194 rows × 2 columns
test_job = pd.read_csv('./data/test_job.csv')
test_job| userID | jobID | |
|---|---|---|
| 0 | ebaee1af0c501f22ddfe242fc16dae53 | 352407221afb776e3143e8a1a0577885 |
| 1 | 9ab05403ac7808cbfba3da26665f7a9c | 96b9bff013acedfb1d140579e2fbeb63 |
| 2 | 33349e909eba71677299d2fc97e158b7 | 58d4d1e7b1e97b258c9ed0b37e02d087 |
| 3 | ac985a9db5faeb44c94a334430ccc241 | ccb0989662211f61edae2e26d58ea92f |
| 4 | d41e0e6f6f1e29098d9d152511503ab2 | 4a213d37242bdcad8e7300e202e7caa4 |
| ... | ... | ... |
| 2430 | 01ed443356f762e9132b58f8c80e131d | 26e359e83860db1d11b6acca57d8ea88 |
| 2431 | 946aa0c612952da8d67dd338a43d5929 | c0f168ce8900fa56e57789e2a2f2c9d0 |
| 2432 | ce840aa9583592e71f3db26ee6e41703 | 8065d07da4a77621450aa84fee5656d9 |
| 2433 | 946aa0c612952da8d67dd338a43d5929 | a0160709701140704575d499c997b6ca |
| 2434 | 33349e909eba71677299d2fc97e158b7 | 192fc044e74dffea144f9ac5dc9f3395 |
2435 rows × 2 columns
# train에서 지원한 사람만 보자.
train[train['applied'] == 1]| userID | jobID | applied | |
|---|---|---|---|
| 2 | 8ec0888a5b04139be0dfe942c7eb4199 | 0fcbc61acd0479dc77e3cccc0f5ffca7 | 1 |
| 23 | b052e2e0c0ad1b2d5036bd56e27d061c | 4a213d37242bdcad8e7300e202e7caa4 | 1 |
| 24 | a35af76a1c0bb174a3cfc66592804848 | e820a45f1dfc7b95282d10b6087e11c0 | 1 |
| 29 | cb08b2c94dbb772324444bb4ed7cc1a4 | 9b70e8fe62e40c570a322f1b0b659098 | 1 |
| 35 | 688da39dcb1131d0d91b348653850d08 | b534ba68236ba543ae44b22bd110a1d6 | 1 |
| ... | ... | ... | ... |
| 5976 | e3979074cac4d9393ebbd4c2a534a851 | 58d4d1e7b1e97b258c9ed0b37e02d087 | 1 |
| 5981 | 6da6479250104018131de61655f1f385 | 851ddf5058cf22df63d3344ad89919cf | 1 |
| 5983 | 6bd22a86b1f7a3a11de928d301f86d67 | 758874998f5bd0c393da094e1967a72b | 1 |
| 5985 | 2eeb9064f7f5b2569912cbb772a96438 | 24b16fede9a67c9251d3e7c7161c83ac | 1 |
| 5993 | 5585082ed1ea25eaf73052029f2161ce | 9cc138f8dc04cbf16240daa92d8d50e2 | 1 |
857 rows × 3 columns
다음의 데이터는 쉽게 말하자면 이렇게 구성되어 있다.
유저(ID) <- tag(id) <-(keyword)
회사(ID , size) <- 일(ID) <- tag(id)
만약, user의 tag와 일의 id tag가 일치한다면, 지원 가능성을 높이고, 아니면 낮춘다.
순서, - 정량화 할 수 있는 변수를 찾는다.
- userID 1번, jobID 1번을 읽는다.
- userID의 태그를 읽는다.(모두),
- jobID의 태그를 읽는다. (모두)
- jobID중에 userID가 몇개 있는지 판단한다.(비율)
def find_tag_ratio(train_data, tag_data):
print(train_data.iloc[0])find_tag_ratio(train, tags)userID fe292163d06253b716e9a0099b42031d
jobID 15de21c670ae7c3f6f3f1f37029303c9
applied 0
Name: 0, dtype: object태그별로 지원율이 다르지 않을까?
train 데이터를 조금 더 수정하자.
지원자 ID, 잡 ID, 지원자 tags, job tags, 일치비율, 기업사이즈(NULL 가능), 지원 여부
# 잡 태그 종류는 345개이다.
user_tags['tagID'].value_counts()
f47330643ae134ca204bf6b2481fec47 820
0e095e054ee94774d6a496099eb1cf6a 796
c8ba76c279269b1c6bc8a07e38e78fa4 701
2ba8698b79439589fdd2b0f7218d8b07 564
3948ead63a9f2944218de038d8934305 516
...
0a09c8844ba8f0936c20bd791130d6b6 1
5fa9e41bfec0725742cc9d15ef594120 1
07042ac7d03d3b9911a00da43ce0079a 1
6d3a1e06d6a06349436bc054313b648c 1
d82118376df344b0010f53909b961db3 1
Name: tagID, Length: 345, dtype: int64# 유저 정보는 총 196명으로 이루어져 있음을 확인하는 코드
user_tags['userID'].value_counts()f69054686ba46877b6397ccdb8f51762 572
eeedf6d4d717eba333e1b53f1b5375c8 447
0cc8f7bf8a8d56980414a6e4bc69cdc6 358
87c0a904d6f959e5ecbd0bdaa29d8be9 336
5585082ed1ea25eaf73052029f2161ce 325
...
68a61f9415f07a4040f7afe82a058608 5
37b96469b46dfd9919cd984b788ceb17 5
15d84e9a5eceb67bcb8fb0e8c839a903 5
4611b8ff403bea67637c3f1911940668 5
4802630177809fcf861411501a443abb 4
Name: userID, Length: 196, dtype: int64# f69054686ba46877b6397ccdb8f51762 의 잡태그 목록.
test_list1 = user_tags[user_tags['userID'] =='f69054686ba46877b6397ccdb8f51762']['tagID'].value_counts()
test_list1c8ba76c279269b1c6bc8a07e38e78fa4 26
2ba8698b79439589fdd2b0f7218d8b07 26
aace49c7d80767cffec0e513ae886df0 26
a8c88a0055f636e4a163a5e3d16adab7 26
20d135f0f28185b84a4cf7aa51f29500 26
9996535e07258a7bbfd8b132435c5962 26
f47330643ae134ca204bf6b2481fec47 26
4122cb13c7a474c1976c9706ae36521d 26
81dc9bdb52d04dc20036dbd8313ed055 26
7bccfde7714a1ebadf06c5f4cea752c1 26
4c27cea8526af8cfee3be5e183ac9605 21
c9f95a0a5af052bffce5c89917335f67 21
1e6e0a04d20f50967c64dac2d639a577 21
9bf31c7ff062936a96d3c8bd1f8f2ff3 21
4e2545f819e67f0615003dd7e04a6087 21
db2b4182156b2f1f817860ac9f409ad7 21
e034fb6b66aacc1d48f445ddfb08da98 21
26588e932c7ccfa1df309280702fe1b5 21
c20ad4d76fe97759aa27a0c99bff6710 21
66808e327dc79d135ba18e051673d906 21
dd77279f7d325eec933f05b1672f6a1f 21
82c2559140b95ccda9c6ca4a8b981f1e 21
351b33587c5fdd93bd42ef7ac9995a28 5
c88d8d0a6097754525e02c2246d8d27f 5
6766aa2750c19aad2fa1b32f36ed4aee 5
7810ccd41bf26faaa2c4e1f20db70a71 5
81e5f81db77c596492e6f1a5a792ed53 5
42d6c7d61481d1c21bd1635f59edae05 5
e702e51da2c0f5be4dd354bb3e295d37 5
9adeb82fffb5444e81fa0ce8ad8afe7a 5
aff0a6a4521232970b2c1cf539ad0a19 5
8a3363abe792db2d8761d6403605aeb7 5
f91e24dfe80012e2a7984afa4480a6d6 5
2b6d65b9a9445c4271ab9076ead5605a 5
Name: tagID, dtype: int64user 'f69054686ba46877b6397ccdb8f51762'의 경우 34개의 잡태그를 가지고 있다.
X축을 - user가 가지고 있는 tags의 개수라고 하고,
y축을 - user tag 와 job tag 일치하는 개수 / job tag의 수라고 하자.
그렇다면 데이터는 다음과 같이 변환할 수 있다.
train| userID | jobID | applied | |
|---|---|---|---|
| 0 | fe292163d06253b716e9a0099b42031d | 15de21c670ae7c3f6f3f1f37029303c9 | 0 |
| 1 | 6377fa90618fae77571e8dc90d98d409 | 55b37c5c270e5d84c793e486d798c01d | 0 |
| 2 | 8ec0888a5b04139be0dfe942c7eb4199 | 0fcbc61acd0479dc77e3cccc0f5ffca7 | 1 |
| 3 | f862b39f767d3a1991bdeb2ea1401c9c | 3b5dca501ee1e6d8cd7b905f4e1bf723 | 0 |
| 4 | cac14930c65d72c16efac2c51a6b7f71 | 287e03db1d99e0ec2edb90d079e142f3 | 0 |
| ... | ... | ... | ... |
| 5995 | 68cb94b97d00979f4e8127915885b641 | b9228e0962a78b84f3d5d92f4faa000b | 0 |
| 5996 | c0b199d73bdf390c2f4c3150b6ee1574 | e3796ae838835da0b6f6ea37bcf8bcb7 | 0 |
| 5997 | 3ab88dd28f749fe4ec90c0b6f9896eb5 | e2a2dcc36a08a345332c751b2f2e476c | 0 |
| 5998 | 75b4af0dacbc119eadf4eeb096738405 | 3b712de48137572f3849aabd5666a4e3 | 0 |
| 5999 | 67adefb430df142b099bed89bd491524 | 65cc2c8205a05d7379fa3a6386f710e1 | 0 |
6000 rows × 3 columns
#train - user ID, jobID, user-tag counts, coincide with job & user tags/ job-tag counts / apply
#user-tag counts
train['user_tags_counts'] = 0
for i in range(len(train)):
train['user_tags_counts'].iloc[i] =len( user_tags[user_tags['userID'] == train['userID'].iloc[i]])
/Users/junhyeoungson/opt/anaconda3/lib/python3.7/site-packages/pandas/core/indexing.py:670: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
iloc._setitem_with_indexer(indexer, value)#job tag counts
train['job_tags_counts'] = 0
for i in range(len(train)):
train['job_tags_counts'].iloc[i] =len( job_tags[job_tags['jobID'] == train['jobID'].iloc[i]])
/Users/junhyeoungson/opt/anaconda3/lib/python3.7/site-packages/pandas/core/indexing.py:670: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
iloc._setitem_with_indexer(indexer, value)job_tags[job_tags['jobID'] =='15de21c670ae7c3f6f3f1f37029303c9']| jobID | tagID | |
|---|---|---|
| 948 | 15de21c670ae7c3f6f3f1f37029303c9 | a9078e8653368c9c291ae2f8b74012e7 |
| 2687 | 15de21c670ae7c3f6f3f1f37029303c9 | d38901788c533e8286cb6400b40b386d |
user_tags[user_tags['userID'] == '8ec0888a5b04139be0dfe942c7eb4199' ]['tagID']7531 f91e24dfe80012e2a7984afa4480a6d6
7897 aace49c7d80767cffec0e513ae886df0
7898 d2ed45a52bc0edfa11c2064e9edee8bf
8613 58ae749f25eded36f486bc85feb3f0ab
8614 3948ead63a9f2944218de038d8934305
8615 4e2545f819e67f0615003dd7e04a6087
8616 26588e932c7ccfa1df309280702fe1b5
8685 4e2545f819e67f0615003dd7e04a6087
8686 26588e932c7ccfa1df309280702fe1b5
9195 58ae749f25eded36f486bc85feb3f0ab
9196 3948ead63a9f2944218de038d8934305
9359 4e2545f819e67f0615003dd7e04a6087
9360 26588e932c7ccfa1df309280702fe1b5
9361 f91e24dfe80012e2a7984afa4480a6d6
9432 58ae749f25eded36f486bc85feb3f0ab
9433 3948ead63a9f2944218de038d8934305
9563 4e2545f819e67f0615003dd7e04a6087
9564 26588e932c7ccfa1df309280702fe1b5
10279 f91e24dfe80012e2a7984afa4480a6d6
10280 aace49c7d80767cffec0e513ae886df0
10281 d2ed45a52bc0edfa11c2064e9edee8bf
10350 aace49c7d80767cffec0e513ae886df0
10351 d2ed45a52bc0edfa11c2064e9edee8bf
11023 aace49c7d80767cffec0e513ae886df0
11024 d2ed45a52bc0edfa11c2064e9edee8bf
11025 58ae749f25eded36f486bc85feb3f0ab
11026 3948ead63a9f2944218de038d8934305
11097 f91e24dfe80012e2a7984afa4480a6d6
Name: tagID, dtype: object#비율을 계산하는 함수를 만든다.
def calculate_tags_ratio(userID, jobID):
user_tag_list = []
job_tag_list = []
val = []
user_tag_list = user_tags[user_tags['userID'] == userID ]['tagID'].tolist()
job_tag_list = job_tags[job_tags['jobID'] == jobID ]['tagID'].tolist()
for i in job_tag_list:
if i in user_tag_list:
val.append(1)
return len(val)/len(job_tag_list)
calculate_tags_ratio('8ec0888a5b04139be0dfe942c7eb4199', '0fcbc61acd0479dc77e3cccc0f5ffca7')0.3333333333333333train['coincide_tags'] = 0
train
for i in range(len(train)):
train['coincide_tags'].iloc[i] = calculate_tags_ratio(train['userID'].iloc[i], train['jobID'].iloc[i])
/Users/junhyeoungson/opt/anaconda3/lib/python3.7/site-packages/pandas/core/indexing.py:670: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
iloc._setitem_with_indexer(indexer, value)train| userID | jobID | user_tags_counts | coincide_tags | applied | |
|---|---|---|---|---|---|
| 0 | fe292163d06253b716e9a0099b42031d | 15de21c670ae7c3f6f3f1f37029303c9 | 151 | 0.000000 | 0 |
| 1 | 6377fa90618fae77571e8dc90d98d409 | 55b37c5c270e5d84c793e486d798c01d | 125 | 0.333333 | 0 |
| 2 | 8ec0888a5b04139be0dfe942c7eb4199 | 0fcbc61acd0479dc77e3cccc0f5ffca7 | 28 | 0.333333 | 1 |
| 3 | f862b39f767d3a1991bdeb2ea1401c9c | 3b5dca501ee1e6d8cd7b905f4e1bf723 | 85 | 0.600000 | 0 |
| 4 | cac14930c65d72c16efac2c51a6b7f71 | 287e03db1d99e0ec2edb90d079e142f3 | 100 | 0.250000 | 0 |
| ... | ... | ... | ... | ... | ... |
| 5995 | 68cb94b97d00979f4e8127915885b641 | b9228e0962a78b84f3d5d92f4faa000b | 145 | 1.000000 | 0 |
| 5996 | c0b199d73bdf390c2f4c3150b6ee1574 | e3796ae838835da0b6f6ea37bcf8bcb7 | 76 | 0.500000 | 0 |
| 5997 | 3ab88dd28f749fe4ec90c0b6f9896eb5 | e2a2dcc36a08a345332c751b2f2e476c | 122 | 0.166667 | 0 |
| 5998 | 75b4af0dacbc119eadf4eeb096738405 | 3b712de48137572f3849aabd5666a4e3 | 35 | 0.250000 | 0 |
| 5999 | 67adefb430df142b099bed89bd491524 | 65cc2c8205a05d7379fa3a6386f710e1 | 126 | 0.250000 | 0 |
6000 rows × 5 columns
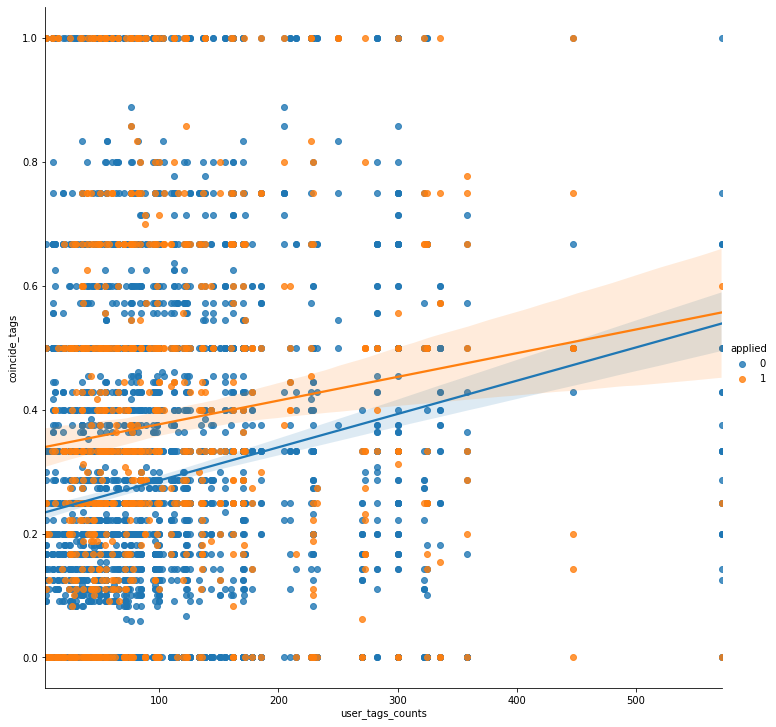
sns.lmplot(x="user_tags_counts", y="coincide_tags", hue="applied", height=10, data=train)
plt.show()
#test csv 변형
test_job
def set_df(df,user_tags,job_tags):
df['user_tags_counts'] = 0
for i in range(len(df)):
df['user_tags_counts'].iloc[i] =len( user_tags[user_tags['userID'] == df['userID'].iloc[i]])
#job tag counts
df['job_tags_counts'] = 0
for i in range(len(df)):
df['job_tags_counts'].iloc[i] =len( job_tags[job_tags['jobID'] == df['jobID'].iloc[i]])
df['coincide_tags'] = 0
for i in range(len(df)):
df['coincide_tags'].iloc[i] = calculate_tags_ratio(df['userID'].iloc[i], df['jobID'].iloc[i])
return df
a = set_df(test_job,user_tags,job_tags)
a
/Users/junhyeoungson/opt/anaconda3/lib/python3.7/site-packages/pandas/core/indexing.py:670: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
iloc._setitem_with_indexer(indexer, value)| userID | jobID | user_tags_counts | job_tags_counts | coincide_tags | |
|---|---|---|---|---|---|
| 0 | ebaee1af0c501f22ddfe242fc16dae53 | 352407221afb776e3143e8a1a0577885 | 143 | 7 | 0.428571 |
| 1 | 9ab05403ac7808cbfba3da26665f7a9c | 96b9bff013acedfb1d140579e2fbeb63 | 48 | 7 | 0.142857 |
| 2 | 33349e909eba71677299d2fc97e158b7 | 58d4d1e7b1e97b258c9ed0b37e02d087 | 78 | 7 | 0.142857 |
| 3 | ac985a9db5faeb44c94a334430ccc241 | ccb0989662211f61edae2e26d58ea92f | 15 | 4 | 0.000000 |
| 4 | d41e0e6f6f1e29098d9d152511503ab2 | 4a213d37242bdcad8e7300e202e7caa4 | 100 | 6 | 0.000000 |
| ... | ... | ... | ... | ... | ... |
| 2430 | 01ed443356f762e9132b58f8c80e131d | 26e359e83860db1d11b6acca57d8ea88 | 82 | 4 | 0.000000 |
| 2431 | 946aa0c612952da8d67dd338a43d5929 | c0f168ce8900fa56e57789e2a2f2c9d0 | 30 | 3 | 0.666667 |
| 2432 | ce840aa9583592e71f3db26ee6e41703 | 8065d07da4a77621450aa84fee5656d9 | 170 | 4 | 0.500000 |
| 2433 | 946aa0c612952da8d67dd338a43d5929 | a0160709701140704575d499c997b6ca | 30 | 3 | 0.333333 |
| 2434 | 33349e909eba71677299d2fc97e158b7 | 192fc044e74dffea144f9ac5dc9f3395 | 78 | 3 | 0.000000 |
2435 rows × 5 columns
train| userID | jobID | user_tags_counts | coincide_tags | applied | |
|---|---|---|---|---|---|
| 0 | fe292163d06253b716e9a0099b42031d | 15de21c670ae7c3f6f3f1f37029303c9 | 151 | 0.000000 | 0 |
| 1 | 6377fa90618fae77571e8dc90d98d409 | 55b37c5c270e5d84c793e486d798c01d | 125 | 0.333333 | 0 |
| 2 | 8ec0888a5b04139be0dfe942c7eb4199 | 0fcbc61acd0479dc77e3cccc0f5ffca7 | 28 | 0.333333 | 1 |
| 3 | f862b39f767d3a1991bdeb2ea1401c9c | 3b5dca501ee1e6d8cd7b905f4e1bf723 | 85 | 0.600000 | 0 |
| 4 | cac14930c65d72c16efac2c51a6b7f71 | 287e03db1d99e0ec2edb90d079e142f3 | 100 | 0.250000 | 0 |
| ... | ... | ... | ... | ... | ... |
| 5995 | 68cb94b97d00979f4e8127915885b641 | b9228e0962a78b84f3d5d92f4faa000b | 145 | 1.000000 | 0 |
| 5996 | c0b199d73bdf390c2f4c3150b6ee1574 | e3796ae838835da0b6f6ea37bcf8bcb7 | 76 | 0.500000 | 0 |
| 5997 | 3ab88dd28f749fe4ec90c0b6f9896eb5 | e2a2dcc36a08a345332c751b2f2e476c | 122 | 0.166667 | 0 |
| 5998 | 75b4af0dacbc119eadf4eeb096738405 | 3b712de48137572f3849aabd5666a4e3 | 35 | 0.250000 | 0 |
| 5999 | 67adefb430df142b099bed89bd491524 | 65cc2c8205a05d7379fa3a6386f710e1 | 126 | 0.250000 | 0 |
6000 rows × 5 columns
# 로지스틱 회귀 모델train[['applied']]| applied | |
|---|---|
| 0 | 0 |
| 1 | 0 |
| 2 | 1 |
| 3 | 0 |
| 4 | 0 |
| ... | ... |
| 5995 | 0 |
| 5996 | 0 |
| 5997 | 0 |
| 5998 | 0 |
| 5999 | 0 |
6000 rows × 1 columns
X = train[['user_tags_counts','coincide_tags']]
y = train[['applied']]
test_df_X = test_job[['user_tags_counts','coincide_tags']]X_train, X_test, y_train, y_test = train_test_split(X , y , test_size = 0.2, random_state = 5)model = LogisticRegression()model.fit(X_train, y_train)/Users/junhyeoungson/opt/anaconda3/lib/python3.7/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
LogisticRegression()model.score(X_test,y_test)0.8441666666666666model.predict(X_test)array([0, 0, 0, ..., 0, 0, 0])test_df_y = model.predict(X_test)result = pd.DataFrame(test_df_y)result| 0 | |
|---|---|
| 0 | 0 |
| 1 | 0 |
| 2 | 0 |
| 3 | 0 |
| 4 | 0 |
| ... | ... |
| 2430 | 0 |
| 2431 | 0 |
| 2432 | 0 |
| 2433 | 0 |
| 2434 | 0 |
2435 rows × 1 columns
모두 0으로 예측하는 불상사가 일어나 버렸다..
model = LinearRegression()model.fit(X_train, y_train)LinearRegression()model.score(X_test, y_test)0.023744821590652054선형 모델은 성공률이 굉장히 낮았다.
model = RandomForestClassifier()model.fit(X_train, y_train)/Users/junhyeoungson/opt/anaconda3/lib/python3.7/site-packages/ipykernel_launcher.py:1: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples,), for example using ravel().
"""Entry point for launching an IPython kernel.
RandomForestClassifier()model.score(X_test, y_test)0.8266666666666667test_df_y = model.predict(test_df_X)
result = pd.DataFrame(test_df_y)
result| 0 | |
|---|---|
| 0 | 1 |
| 1 | 0 |
| 2 | 1 |
| 3 | 0 |
| 4 | 0 |
| ... | ... |
| 2430 | 0 |
| 2431 | 0 |
| 2432 | 0 |
| 2433 | 0 |
| 2434 | 0 |
2435 rows × 1 columns
result[result[0] == 1]| 0 | |
|---|---|
| 0 | 1 |
| 2 | 1 |
| 51 | 1 |
| 64 | 1 |
| 69 | 1 |
| ... | ... |
| 2379 | 1 |
| 2380 | 1 |
| 2385 | 1 |
| 2413 | 1 |
| 2426 | 1 |
127 rows × 1 columns
앙상블을 사용한 결과의 정확도는 83% 정도 되었다. 프로그래머스 고득점자를 보니 94%의 정확도를 보여 주었다. 그 사람들은 어떤 모델을 사용한 것일까?
나는 아직 하이퍼 파라미터 튜닝같은 것을 하지 않고 단순하게 앙상블-랜덤포레스트 모델만 만들어서 돌렸다. 어떤 요소가 정확도를 올릴 수 있는 하이퍼 파라밍터인지 고민해보고 튜닝해보아야 겠다.
결론,
생각보다 머신러닝 과제가 재미있었다. 시간가는줄 모르고 진행했다. 우선, 카테고리로 되어있는 문제를 수로 표현하려고 노력했고, 태그를 이용하여 지원자의 역량을 정량화 하였으며, 공고당 요구하는 자격조건 대비 조건을 만족하는 유저의 태그 수를 계산하여 지표로 사용하였다.
물론 이보다 더 나은 지표도 많겠지만, 아직 머신러닝 초보자로서 3시간만에 재미있는 결과와 분석을 할 수 있어서 좋았고, 많이 배워갔다.
