LLM
1.원-핫 인코딩(One-Hot Encoding)

원-핫 인코딩은 범주형(카테고리) 변수를 머신러닝 알고리즘이 처리할 수 있는 숫자 형식으로 변환하는 기법입니다. 각 범주를 하나의 “1”과 나머지 “0”으로 이루어진 이진 벡터로 표현하여, 범주 간의 순서를 암시하지 않습니다.머신러닝 모델은 일반적으로 숫자 입력을 필요
2.NLP vs LLM
NLP와 LLM의 차이점을 설명해드리겠습니다.NLP (Natural Language Processing, 자연어 처리)개념: 컴퓨터가 인간의 언어를 이해하고 처리할 수 있게 하는 인공지능의 한 분야범위: 언어학, 컴퓨터 과학, 머신러닝을 아우르는 광범위한 학문 분야역사
3.Bag of Words (BoW)
정의: 텍스트를 단어들의 집합(가방)으로 표현하는 자연어 처리 기법핵심 특징:단어 순서 무시: 문장의 구조나 단어 순서를 고려하지 않음빈도 기반: 각 단어가 문서에서 몇 번 나타나는지만 중요벡터 표현: 문서를 숫자 벡터로 변환예시:장점:구현이 간단하고 직관적계산 비용이
4.RNN
RNN(Recurrent Neural Network, 순환 신경망)은 시계열, 자연어, 음성 등 순차 데이터(Sequence Data)를 처리하기 위한 딥러닝의 기본적 시퀀스 모델입니다17. 기존 피드포워드 신경망과 다르게, RNN은 이전 입력의 정보를 메모리로 저장해
5.Transformer (Basic)
Transformer 모델은 자연어 처리(NLP)를 비롯한 다양한 시퀀스 처리의 판을 바꾼 딥러닝 아키텍처로, 2017년 구글의 논문 “Attention is All You Need”에서 처음 소개되었습니다1. 이 모델의 핵심 개념은 셀프 어텐션(Self-attenti
6.Transfomer (Advanced)
핵심 포인트구글이 2017년에 발표한 “Attention Is All You Need” 논문은 RNN 계열을 완전히 대체할 수 있는 병렬 처리 기반 시퀀스 모델을 제시하며, 이후 모든 NLP·AI 연구의 패러다임을 바꿨습니다. 이 해설에서는 논문의 주요 구성 요소를 코
7.자연어 처리에서 NLG vs NLU
자연어 처리(NLP)에서 NLG(Natural Language Generation)와 NLU(Natural Language Understanding)는 서로 다른 역할을 하는 핵심 구성 요소입니다. 이 두 기술은 인간과 기계 간의 자연스러운 언어 소통을 가능하게 하는
8.음절(syllable)과 형태소(morpheme)
자연어 처리와 언어학에서 음절(syllable)과 형태소(morpheme)는 언어를 분석하는 두 가지 중요한 단위입니다. 이 둘은 완전히 다른 관점에서 언어를 다루며, 각각 고유한 역할과 특성을 가지고 있습니다.음절은 소리의 덩어리 단위로, 한 번에 낼 수 있는 소리의
9.자연어 처리에서 의미론(Semantics)이란?
핵심 요약:의미론은 자연어 처리(NLP)에서 언어가 담고 있는 의미를 분석하고 이해하는 분야로, 단어·문장·텍스트 수준에서 의미를 표현하고 추론하는 다양한 기법을 다룹니다. 의미론을 적용하면 기계가 텍스트의 숨은 의도, 개체 관계, 맥락적 뉘앙스까지 이해할 수 있어 고
10.자연어 처리(NLP)에서 화용론 활용법
핵심 요약:자연어 처리 시스템에 화용론을 도입하면 사용자의 의도 파악, 맥락 기반 대화 관리, 함축 추론, 정중도·스타일 제어 등을 통해 더욱 자연스럽고 정확한 상호작용이 가능해진다.화용론적 정보(대화 맥락, 발화 상황, 전발화 내용 등)를 활용하여 사용자의 진정한 의
11.자연어 처리(NLP)에서 담화론 활용법
핵심 요약:담화론은 문장 간의 연결성, 구조, 글 흐름을 분석하여 텍스트 전체의 일관성과 응집성을 파악하는 분야입니다. NLP 시스템에 담화론을 적용하면 텍스트 요약, 문맥적 핵심어 추출, 대화 자연성 개선, 코헤런스 유지 등이 가능해집니다.텍스트를 발화문(uttera
12.자연어 처리(NLP)에서 언어학 적용 연구
핵심 요약:자연어 처리 분야는 전통적 언어학의 주요 이론과 기법을 다각도로 통합하여 언어 이해·생성의 정확성과 자연성을 획기적으로 향상시켜 왔다. 형태론·통사론·의미론·화용론·담화론 등 각 언어학 분과의 통찰을 기반으로 한 모델 설계, 어노테이션, 멀티태스크 학습, 지
13.자연어 처리에서 형태론 활용법
핵심 요약:형태론(Morphology)은 단어 내부의 의미 단위(형태소)와 그 결합 규칙을 다룹니다. NLP 시스템에 형태론 지식을 통합하면 어휘 희소성 감소, 정확한 형태소 분석, 품사 태깅 고도화, 저자원 언어 처리 등에서 성능을 크게 향상시킬 수 있습니다.언어별
14.자연어 처리(NLP)에서 의미론 활용법
핵심 요약:의미론을 NLP에 적용하면 단어 중의성 해소, 문장 의미 역할 태깅, 지식 융합 및 추론 등으로 텍스트 이해와 생성의 정밀도를 높일 수 있습니다. 주요 기법으로는 단어 의미 중의성 해소(WSD), 의미 역할 표지(SRL), 지식 그래프 통합 등이 있으며, 이
15.자연어 처리(NLP)에서 통사론 활용법
핵심 요약:통사론(Syntax)을 NLP 파이프라인에 적용하면 문장 구조 이해, 의존 관계 파싱, 문법적 제약 적용, 구조적 특징 활용 등을 통해 텍스트 분석과 생성의 품질을 크게 향상시킬 수 있습니다.의존 구문 분석은 단어 간 직접적 관계를 식별하여 문장의 의미 구조
16.RefinedWeb
RefinedWeb은 대규모 웹 크롤링 데이터만으로 고성능 대형언어모델(LLM)을 학습할 수 있음을 실험적으로 입증한 데이터 파이프라인 및 데이터셋이다. 기존의 The Pile 같은 큐레이션 코퍼스를 능가하는 성능을 보이면서, 5조(token) 규모로 확장 가능한 웹
17.KoNLPy
KoNLPy는 한국어 형태소 분석기(POS Tagger)들을 파이썬에서 쓸 수 있도록 만든 라이브러리예요.⸻📌 주요 특징 • 여러 형태소 분석기 지원 • Hannanum (KAIST 한나눔 형태소 분석기) • Kkma (서울대 꼬꼬마 형태소 분석기) • Komoran
18.NLTK
NLTK는 Natural Language Toolkit의 약자로,파이썬에서 자연어 처리(NLP, Natural Language Processing)를 배우고 실습할 때 가장 널리 쓰이는 라이브러리 중 하나예요.주요 특징을 정리하면: • 토큰화 (Tokenization)
19.자연어처리 텍스트 전처리 개요
텍스트 전처리(Text Preprocessing)는 원시 텍스트 데이터를 자연어처리 모델이 효과적으로 학습하고 처리할 수 있는 형태로 변환하는 과정입니다. 실제 텍스트 데이터는 노이즈, 불규칙한 형식, 다양한 언어적 변이를 포함하고 있어 그대로 사용하기 어렵습니다. 따
20.transformer-explainer
https://poloclub.github.io/transformer-explainer/
21.언어학에서 화용론 이란?
화용론은 언어 사용에서 발화의 의미와 맥락 간의 관계를 연구하는 언어학의 한 분야입니다. 화용론은 단순히 문법적·구조적 의미(의미론, semantics)를 넘어, 실제 의사소통 상황에서 화자가 의도하는 의미와 청자가 해석하는 과정을 중점적으로 다룹니다.화용론이 다루는
22.자연어처리에서 화용론 활용법
핵심 요약:자연어처리(NLP) 시스템에 화용론적 요소를 통합하면 대화 이해도와 응답 적합도가 크게 향상됩니다. 핵심 활용법은 맥락 모델링, 발화 의도 식별, 대화 전략 설계, 간접화법·함축 처리, 대화 정책(언어적·비언어적 맥락) 통합 등입니다.자연어의 의미는 발화가
23.표제어(Lemma)
표제어(Lemma)는 사전에서 대표 형태로 사용되는 단어의 기본형입니다.표제어는 한 단어의 여러 변형들을 대표하는 기준이 되는 형태로, 사전을 찾을 때 찾아보는 그 단어입니다.영어:동사: go, goes, going, went, gone → go (부정사형)명사: ca
24.HMM(Hidden Markov Model, 은닉 마르코프 모델)
LLM(대형 언어 모델)에서 HMM(Hidden Markov Model, 은닉 마르코프 모델)은 과거에 자연어 처리(NLP)에서 많이 사용된 시퀀스(순차) 데이터 모델링 기법을 의미한다1. HMM은 상태(state)들이 직접 관찰되지 않고 숨겨져 있으며, 관찰 가능한
25.CRF(Conditional Random Field; 조건부 랜덤 필드)
CRF(Conditional Random Field; 조건부 랜덤 필드)CRF는 "연속된 데이터를 순서대로 분류할 때" 사용하는 머신러닝 모델이다. 예를 들어, 문장 속 단어들이 각각 어떤 품사인지, 혹은 사람 이름인지 아닌지 구분하려고 할 때 쓰인다.“Donald J
26.Character-Level Bidirectional LSTM-CRF 모델
Character-Level Bidirectional LSTM-CRF 모델은 자연어 처리에서 시퀀스 라벨링 문제를 효과적으로 해결하기 위한 심층 신경망 모델이다. 쉽게 말해, 단어를 글자 단위로 쪼개서(캐릭터 수준) 양방향 LSTM으로 앞뒤 문맥을 모두 이해하고, 최종
27.개체명 인식(Named Entity Recognition, NER)에서 태깅 시스템
개체명 인식(Named Entity Recognition, NER)에서 태깅 시스템이란 문장 내에서 이름을 가진 개체명(사람, 장소, 조직 등)을 단어별로 분리하여 각 단어에 특정 태그를 붙이는 체계를 말한다. 이 태그들은 개체명의 시작, 내부, 또는 비개체명임을 구분
28.자연어처리(NLP)에서 정보 추출(Information Extraction, IE)
자연어처리(NLP)에서 정보 추출(Information Extraction, IE)은 비정형 텍스트나 문서에서 의미 있는 구조화된 정보를 자동으로 식별하고 추출하는 과정을 말한다. 쉽게 말해, 글이나 문장에서 중요한 사람 이름, 장소, 날짜, 사건, 관계 등의 정보를
29.BlenderBot
BlenderBot은 Meta(구 Facebook) AI Research에서 개발한 고급 대화형 인공지능 챗봇이다. BlenderBot은 오픈 도메인 대화에 강점을 가지고, 다양한 주제에 대해 인간과 자연스럽고 일관된 대화를 이어가는 것이 특징이다.멀티턴 대화 능력:
30.추출요약 (Extractive Summarization) / 추상적 요약 (Abstractive Summarization)
추출요약과 추상적 요약은 자연어처리에서 텍스트를 요약하는 두 가지 주요 방식으로, 각각 특징과 사용 목적이 다르다.원문에서 중요한 문장이나 구절을 직접 뽑아서 조합해 요약문을 만드는 방법 요약문에 포함된 문장이나 단어는 모두 원문에 그대로 존재 간단하고 빠르며, 원
31.Hate Speech Detection(증오 발언 감지)
Hate Speech Detection(증오 발언 감지)은 온라인이나 소셜 미디어 등에서 특정 개인이나 집단에 대해 차별, 혐오, 폭력, 적대감 등을 조장하는 부적절한 발언을 자동으로 식별하고 분류하는 자연어처리 기반 기술이다. 혐오 표현, 인종차별적 발언, 성차별,
32.혐오발언의 주요 정의
혐오발언 탐지(Hate Speech Detection)는 자연어처리(NLP)와 머신러닝 기술을 활용해 온라인 텍스트(소셜 미디어, 댓글 등)에서 특정 개인이나 집단에 대한 차별, 적대감, 폭력, 혐오를 조장하는 발언을 자동으로 식별하고 분류하는 시스템이다. 이는 사회적
33.Fake News Detection: A Comprehensive Analysis of Methods, Challenges, and Future Directions
The proliferation of misinformation in the digital age has emerged as one of the most pressing challenges of our interconnected world. With the rise o
34.가짜뉴스 탐지: 방법론, 도전과제 및 미래 방향에 대한 종합적 분석
디지털 시대의 잘못된 정보 확산은 우리의 상호연결된 세계에서 가장 시급한 도전 과제 중 하나로 부상했다. 소셜 미디어 플랫폼의 부상과 콘텐츠 제작의 민주화로 인해 진실한 정보와 조작된 콘텐츠를 구별하는 것이 점점 더 복잡해지고 있다. 가짜뉴스 탐지는 거짓되거나 오해의
35.Persona-Grounded Dialogue: Advancing Conversational AI Through Personality and Context Integration
Persona-grounded dialogue represents a fundamental paradigm shift in conversational AI, moving beyond generic responses to create dialogue systems tha
36.페르소나 기반 대화: 개성과 맥락 통합을 통한 대화형 AI 발전
페르소나 기반 대화는 대화형 AI의 근본적인 패러다임 전환을 나타내며, 일반적인 응답을 넘어서 확장된 상호작용 전반에 걸쳐 일관된 성격과 캐릭터 특성을 유지하는 대화 시스템을 만드는 것이다. 이 접근법은 대화 시스템의 가장 지속적인 도전 과제 중 하나인 일관성 문제를
37.Neural Symbolic Based NLP: 신경망과 기호 AI의 융합
신경-기호(Neural-Symbolic) 기반 자연어처리(NLP)는 딥러닝의 패턴 인식 능력과 기호 AI의 논리적 추론 능력을 결합한 혁신적인 접근 방식이다1. 이 하이브리드 방법론은 전통적인 신경망 모델의 한계인 논리적 일관성 부족과 설명 가능성 문제를 해결하면서,
38.BART 모델: 양방향 자기회귀 트랜스포머의 혁신
BART(Bidirectional and Auto-Regressive Transformers)는 2019년 Facebook AI Research(현 Meta AI)에서 개발한 혁신적인 트랜스포머 기반 언어 모델이다1. BART는 노이즈 제거 오토인코더(denoising
39.YAML 형식: 사람이 읽기 쉬운 데이터 직렬화 표준
YAML은 "YAML Ain't Markup Language"의 재귀적 약어로, 사람이 쉽게 읽고 쓸 수 있도록 설계된 데이터 직렬화 형식입니다13. 원래는 "Yet Another Markup Language"였으나, 마크업 언어가 아닌 데이터 직렬화에 중점을 둔다는
40.Attention VS Self Attention
어텐션과 셀프 어텐션은 관련이 있지만 서로 다른 개념으로, 주로 신경망과 딥러닝 분야에서 사용됩니다.어텐션은 모델이 예측을 할 때 입력의 특정 부분에 집중할 수 있게 해주는 일반적인 기법입니다. 마치 문제를 풀 때 지문에서 중요한 단어들을 형광펜으로 표시하는 것과 같습
41. The Transformer - model architecture
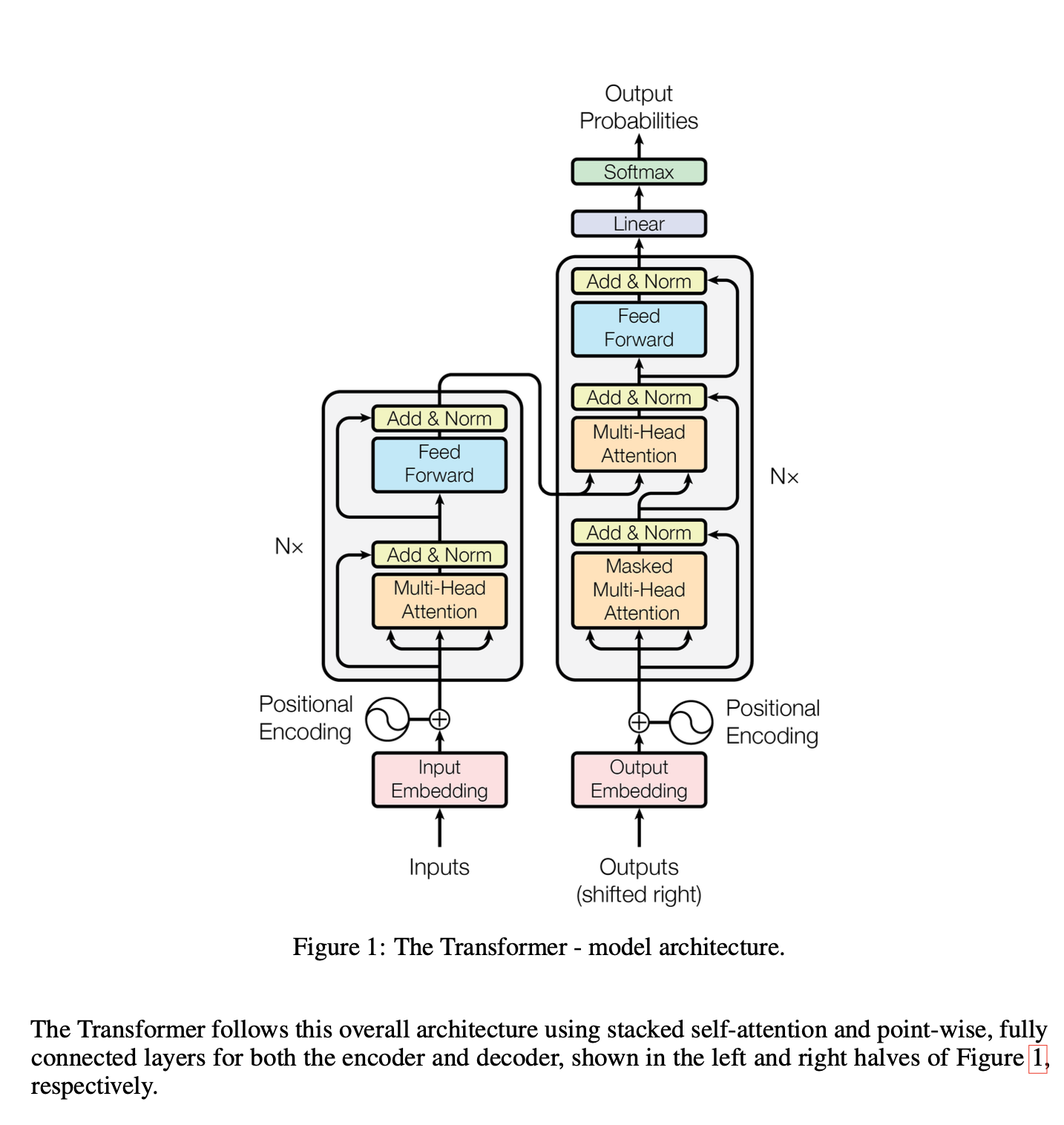
Embedding Encoding Posoitional Encoding AttentionSelf AttentionMulihead AttentionResidual ConnectionLayer Normalization
42.Confusion Matrix
Confusion의 뜻은 "혼동, 혼란"입니다.명명 이유:모델이 어떤 클래스들을 서로 혼동(confuse)하는지를 보여주는 표이기 때문입니다예를 들어:고양이를 개로 잘못 예측 → 고양이와 개를 혼동숫자 3을 8로 잘못 예측 → 3과 8을 혼동암 환자를 건강하다고 예측
43.Accuracy
Accuracy는 전체 예측 중에서 올바르게 예측한 비율입니다.공식:TP: 실제 Positive를 Positive로 예측 (맞음)TN: 실제 Negative를 Negative로 예측 (맞음)FP: 실제 Negative를 Positive로 예측 (틀림)FN: 실제 Pos
44.Precision
Precision은 모델이 Positive로 예측한 것들 중에서 실제로 Positive인 비율입니다.공식:TP (True Positive): 실제 Positive를 Positive로 예측FP (False Positive): 실제 Negative를 Positive로 예측
45.Recall
Confusion Matrix에서 Recall에 대해 설명드리겠습니다.Recall은 실제 Positive인 것들 중에서 모델이 Positive로 정확히 예측한 비율입니다.공식:TP (True Positive): 실제 Positive를 Positive로 예측FN (Fal
46.LoRA 파인튜닝 (Low-Rank Adaptation)
좋아요. 👌지금 말씀하신 “LoRA 파인튜닝 (Low-Rank Adaptation)”은 현대 AI, 특히 대형 언어 모델(LLM)이나 이미지 생성 모델을 가장 효율적으로 미세조정(fine-tuning) 하는 방법 중 하나예요.아래에서는 이론 → 직관적 비유 → 수학적
47.일반화 성능
“성능(performance)” 과 “일반화 성능(generalization performance)” 은 조금 다른 개념이에요.즉, “성능 향상”이 꼭 “일반화 성능 향상”을 의미하지는 않습니다.훈련 데이터의 품질이 나쁘면, 모델은 노이즈나 편향을 배우고 → 실제 환경
48.OCR vs Document Parsing
Perfect! Now I have all the research gathered and visualizations created. Let me compile the comprehensive report.OCR(광학 문자 인식)과 문서 파싱은 문서 자동화의 핵심 기술이
49.RRF (Reciprocal Rank Fusion)
RRF는 여러 개의 검색 결과 리스트를 하나의 통합된 순위로 융합하는 알고리즘입니다. 특히 서로 다른 검색 방식(예: 키워드 검색, 의미 기반 검색)의 결과를 결합할 때 매우 유용합니다.RRF의 기본 공식은 다음과 같습니다:여기서:d는 문서(document)rank_i
50.Query Decomposition
Query Decomposition은 복잡한 사용자 질문을 여러 개의 간단한 하위 질문(sub-queries)으로 분해하여 각각 검색한 후 결과를 통합하는 RAG(Retrieval-Augmented Generation) 기법입니다.원래 복잡한 질문:"2023년 Open