YOLO 알고리즘 개요
YOLO 알고리즘의 탄생은 컴퓨터 비전과 객체 탐지 분야에서 중요한 변화를 가져왔습니다.
이 알고리즘이 개발된 시기는 대략 2015년으로, 당시의 기술적 동향과 배경을 이해하면 YOLO의 혁신적인 접근 방식과 그 중요성을 더 잘 파악할 수 있습니다.
YOLO 모델 개발 이전 전통적인 객체 탐지 시스템은 여러 단계로 구성되어 있었습니다. 초기 모델들은 먼저 이미지 내에서 잠재적인 개체가 존재할 만한 위치를 선별하는 ‘Region Proposal’ 단계를 거쳤고, 이후 실제 객체 탐지를 위해 각 제안된 영역을 더 자세히 분석했습니다. 이 방식은 상당히 정확할 수 있지만, 처리 속도가 느리고 계산 비용이 매우 높다는 단점이 있었습니다.
2012년에 AlexNet이라는 딥러닝 기반의 아키텍처가 ImageNet 경쟁에서 큰 성공을 거두면서, 컴퓨터 비전 분야에 딥러닝의 활용이 급격히 증가하기 시작했습니다. 이후 R-CNN, Fast R-CNN, Faster R-CNN과 같은 모델들이 등장하며 정확도는 향상되었지만, 여전히 실시간 처리에는 한계가 있었습니다.
YOLO는 이러한 기존 접근 방식을 단순화 시키고, 한 번의 추론으로 전체 이미지에서 객체를 탐지하고 분류할 수 있는 방법을 제안했습니다. 이는 다음과 같은 혁신적인 점을 포함합니다 :
통합 아키텍처 : 이미지를 한 번만 처리하여 객체의 위치와 분류 정보를 동시에 예측합니다.
속도의 혁신 : 실시간 처리가 가능할 정도로 빠른 속도를 제공하며, 이는 실시간 애플리케이션에서 더욱 중요도가 대두됩니다.
일반화 성능 향상 : 다른 모델들에 비해 배경 오류가 적고, 새로운 상황이나 적은 데이터에서도 비교적 잘 작동합니다.
이러한 YOLO의 개발은 객체 탐지 분야에서 ‘속도와 정확도’의 균형을 다시 생각하게 만들었고, 이후 등장한 많은 연구와 모델에 영향을 미쳤습니다. 이러한 접근 방식은 특히 자율 주행 차량, 보안 감시 시스템 등 실시간 반응이 중요한 분야에서 큰 잠재력을 보여주고 있습니다.
1. Introduction
기존의 검출(dectection) 모델은 분류기(classifier)를 재정의 하여 검출기(detector)로 사용하고 있습니다.
객체 검출 : 하나의 이미지 내에서 각각의 객체의 위치를 판단하는 것.
어떠한 이미지를 검출 하는 작업은 위치 정보를 판단하는 것 뿐만 아니라, 분류 작업도 추가로 수행되어야 합니다.
이러한 객체검출 방식을 수행하는 대표적인 모델에는 R-CNN이 있습니다.
R-CNN은 이미지 안에서 bounding box를 생성하기 위해 'Region Proposal' 방식을 사용합니다.
Region Proposal의 작동 방식
1. 생성된 bounding box에 blassifer을 적용하여 분류
2. 분류 한 뒤 bounding box를 조정
3. 중복된 검출을 제거
4. 객체에 따라 box의 점수를 재산정하기 위해 후처리
이러한 복잡한 과정 때문에 R-CNN은 속도가 느리고 비용부담이 크고 각 절차를 독립적으로 훈련하기 때문에 최적화도 힘들다는 단점이 존재합니다.
이러한 문제를 해결하기 위해 YOLO 알고리즘의 연구진은 객체 검출을 하나의 회귀 문제로 보고 절차를 개선하였습니다.
이미지의 픽셀로부터 bounding box의 위치, 클래스 확률을 구하기 까지의 절차를 하나의 회귀 문제로 재정의 하였습니다. 이러한 시스템을 통해 YOLO 알고리즘은 이미지 내의 객체 검출을 하나의 파이프라인을 통해 수행합니다.
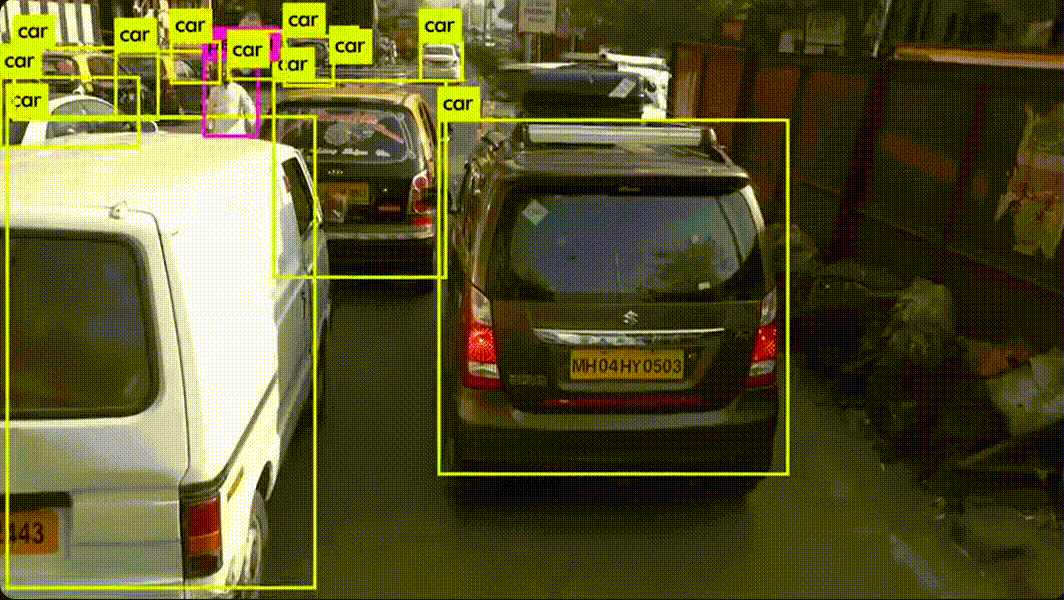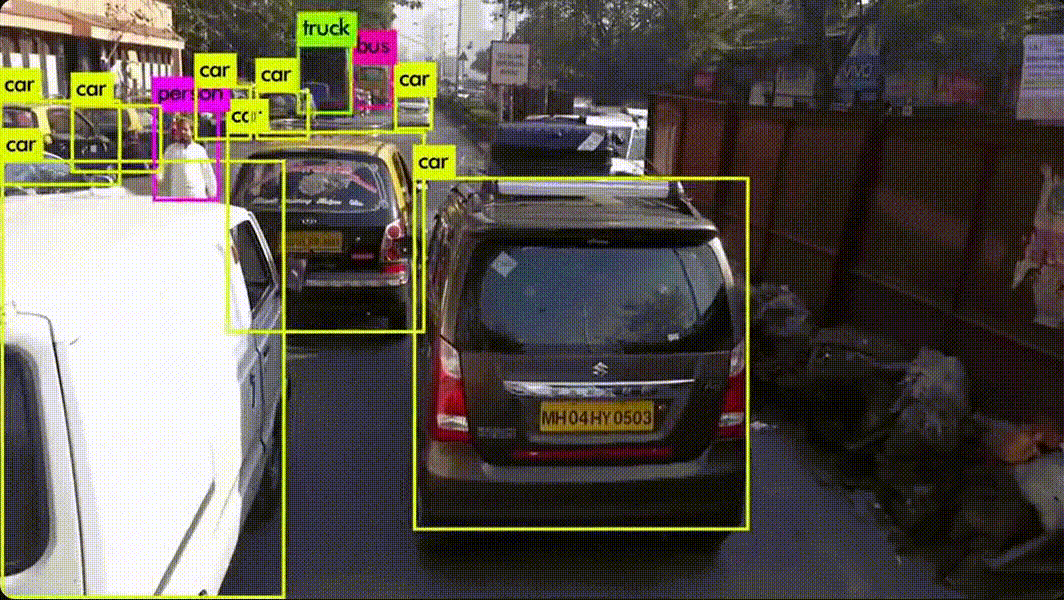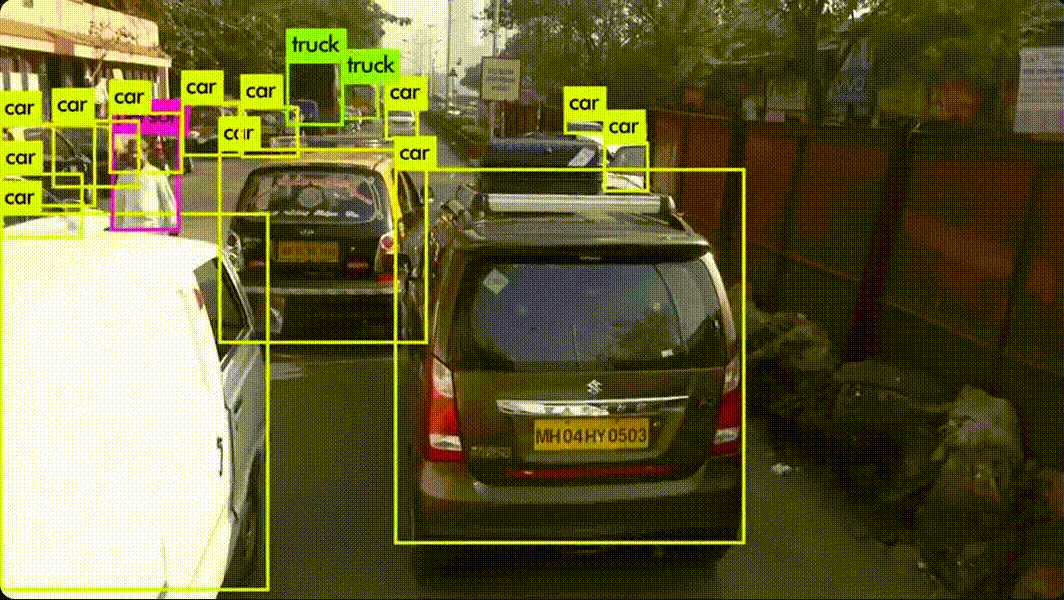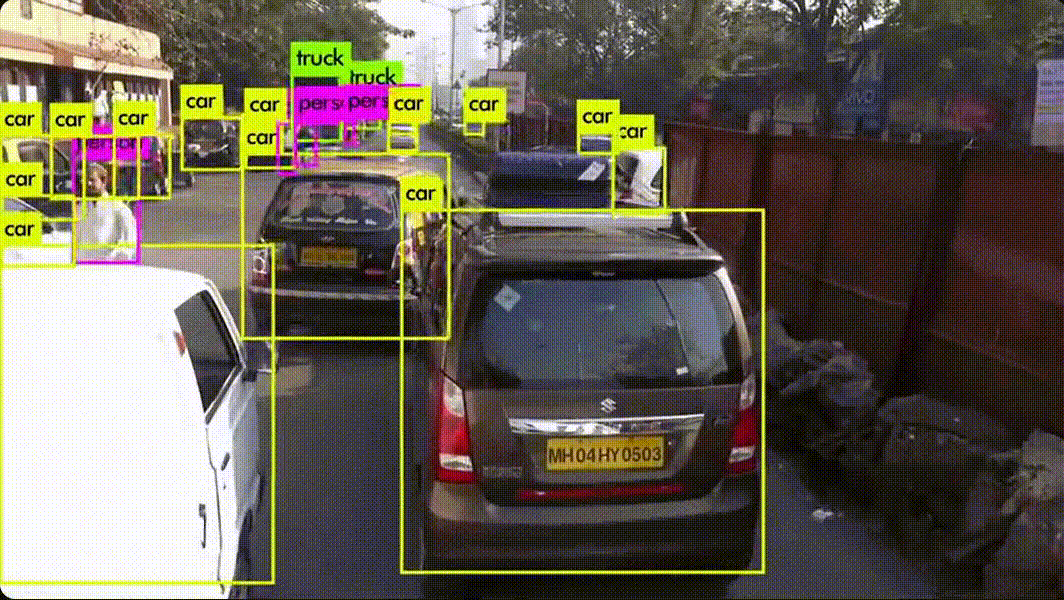

Figure 1의 하나의 convolutional network가 여러 bounding box와 클래스 확률을 동시에 계산합니다.
YOLO의 특징
- 속도
앞서 소개하였듯이, YOLO 알고리즘은 매우 빠릅니다.
기존의 객체 검출은 심층 신경망을 이용한 방식이였지만 YOLO 알고리즘은 이러한 방식을 하나의 파이프라인으로 해결합니다.
YOLO의 기본 네트워크는 Titan X GPU에서 1초에 45 프레임을 처리합니다. 더 나아가 Fast YOLO는 1초에 150 프레임을 처리합니다.
이는 Realtime이 중요한 실시간 어플리케이션에서 더욱 중요도가 대두됩니다. 다른 실시간 객체 검출 모델과 비교했을 때도 2배 이상의 mAP를 갖습니다.
- 학습 방법
YOLo는 예측을 할 때 이미지 전체를 봅니다. Region Proposal 방식과 달리, YOLO는 훈련과 테스트 단계에서 이미지 전체를 봅니다. 이러한 방식으로 클래스의 정보뿐만이 아닌 주변 정보까지 학습하여 처리합니다. 때문에 background error 가 Fast R-CNN 보다 월등히 적습니다.
- 일반적인 특징 학습
YOLO는 학습과정에서 일반적인 부분을 학습하기 때문에 다른 모델에 비해 새로운 이미지에 대해 검출 정확도가 훨씬 높습니다.
- 정확도
하지만 YOLO는 다른 모델에 비해 정확도 떨어진다는 단점이 있습니다. 물체를 빠르게 식별하지만 일부 물체, 특히 작은 물체를 정확하게 위치시키는데 어려움을 겪고 있습니다.
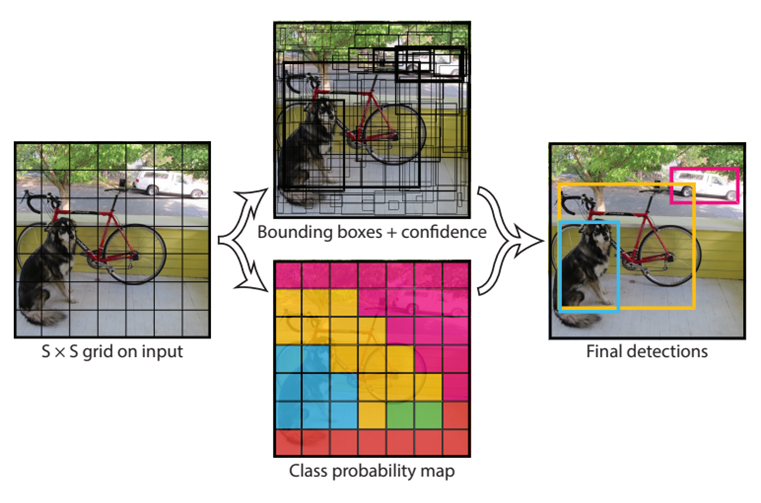
2. Unified Detection
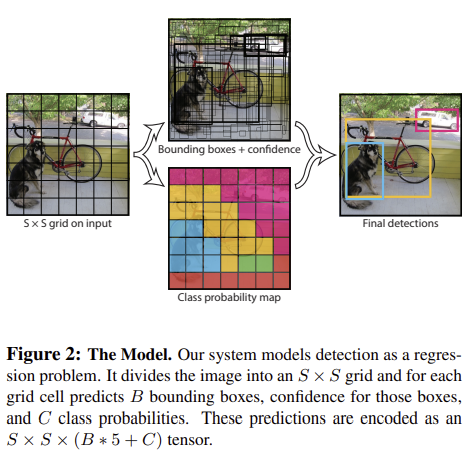
YOLO는 입력 이미지를 S x S 그리드로 나눕니다. 어떤 객체의 중심이 그리드 셀 안에 위치할 때, 그 그리드 셀이 해당 객체를 검출해야 합니다. 각각의 그리드 셀은 B개의 bounding box와 그 bounding box에 대한 confidence score를 예측합니다.
- confidence score : bounding box의 신뢰도
각각의 bounding box는 X, y, w, h, confidence 5개의 정보로 구성되어 있습니다.
- X & Y : 좌표 쌍으로 bounding box 중심의 그리드 셀 내 상대 위치
- W & H : bounding box의 상대 너비와 상대 높이
각각의 그리드 셀은 Conditional class probability를 예측합니다.
- Conditional class probability : 그리드 셀 안에 객체가 있다는 조건 하에 그 객체가 어떤 클래스 인지에 대한 조건부 확률
테스트 단계에서는 conditional class probability와 개별 bounding box의 confidence score를 곱해주는데, 이를 class specific confidence score 라 부릅니다.
- Class specific confidence score : bounding box에 특정 클래스 객체가 나타날 확률과 예측된 bounding box가 그 클래스에 얼마나 fit 한지 나타내는 수치
2.1 Network Design
앞서 얘기했듯이 YOLO 모델은 하나의 CNN 구조로 이루어져 있습니다.

이러한 아키텍쳐는 Google의 GoogLeNet 모델의 이미지 분류 방식에 영감을 받았으며, 24개의 Convolutional layers와 2개의 fully connected layer로 이루어져 있습니다. 앞의 Convolutional Layers 는 이미지의 특징을 추출하고, fully connected layer는 클래스 확률과 좌표를 예측합니다.
GoogLeNet 모델의 인셉션 모듈과는 다르게 YOLO 모델은 1 x 1 축소 계층(reduction layer) 와 3 x 3 합성곱 계층(convolutional layer)로 이루어져 있습니다.
더 빠른 버전인 Fast YOLO 모델은 9개의 convolutional layers 를 사용하여 더 빠른 객체 인식을 가능케 합니다. 최종 출력은 7 x 7 x 30 의 예측 텐서 모델(tensor of predictions)입니다.
2.2 Training
YOLO는 ImageNet 데이터셋을 사용하여 사전 학습된 분류 모델을 객체 검출 모델로 전환하는 접근 방식을 취합니다. 이 모델은 약 1주일 동안 학습되었으며, ImageNet 2012 검증 데이터셋에서 88%의 single crop top-5 정확도를 기록했습니다. 학습 과정에서는 20개의 Convolutional Layers와 2개의 Fully Connected Layers를 사용하며, 추가적으로 4개의 Convolutional Layers와 2개의 Fully Connected Layers가 추가되어 성능을 향상시켰습니다.
YOLO 신경망의 마지막 계층은 선형 활성화 함수를 사용하며, 다른 계층에는 leaky ReLU를 적용합니다. 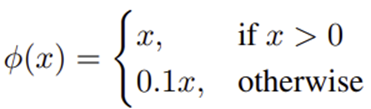
모델의 Loss 함수는 SSE(sum-squared error)를 사용합니다.
SSE는 동일한 가중치를 두고 학습시켜 최적화가 굉장히 쉽다는 장점이 있습니다. 하지만 이것이 최적의 선택 (mAp를 올리기 위한 선택)은 아닙니다. YOLO의 Localization Loss와 Classification Loss는 동일한 가중치를 갖는데, 이는 SSE의 단점 중 하나로 지적되었습니다.
- Localization Loss : Bounding Box의 위치를 얼마나 잘 예측했는지에 대한 Loss
- Classification Loss : 클래스를 얼마나 잘 예측했는지에 대한 Loss
모델의 그리드 셀에는 대부분 객체가 존재하지 않아 학습이 불균형적으로 이루어질 수 있습니다. 이를 보완하기 위해 객체가 존재하는 Bounding Box는 Loss를 증가시키고, 객체가 없는 경우 Loss를 감소시켜 Localization Loss를 개선하는 전략을 사용합니다.
또한, 작은 Bounding Box보다 큰 Bounding Box가 위치 변화에 대한 민감도가 낮기 때문에, Bounding Box의 Width와 Height에 Square Root를 적용해 Loss 가중치를 감소시킵니다. Bounding Box 선택 시, 여러 후보 중에서 가장 높은 IOU를 가진 것을 선택하여 객체를 잘 감싸도록 학습됩니다. 이를 통해 모델은 다양한 크기(size), 종횡비(aspect ratios), 객체 클래스(classes of object)를 예측하는 능력을 갖추게 됩니다.
YOLO v1
- 2016년에 발표된 최초 버전
YOLO v1의 한계
-
물체가 작을수록 정확도가 감소합니다.
-
여러 물체가 겹쳐있을 경우 제대로된 예측이 어렵습니다.
-
Bounding Box 형태가 data를 통해 학습되므로 새로운 형태의 Bounding Box의 경우 정확히 예측하기 어렵습니다.
YOLO v2
- 2017년에 발표된 두번째 버전 - 성능 개선(mAP: 30.2%), 속도 감소
YOLO v1에서 v2로 바뀐점
Architecture 부분
-
기존의 Darknet을 개선한 Darknet19 신경망을 사용하였습니다. 덕분에 파라미터가 감소하여 훨씬 빠른 속도로 detection이 가능하게 되었습니다.
-
YOLOv1에서는 Grid 당 2개의 Bounding Box 좌표를 예측하는 방식이었다면 YOLOv2에서는 Grid 당 5개의 Anchor Box를 찾는 Anchor Box 도입으로 학습이 안정화되었습니다.
그 대신 mAP(mean Average Precision)는 소폭 감소하였습니다.
Anchor Box
: 여러 개의 크기와 비율로 미리 정의된 형태를 가진 경계 박스(B-Box)로서 사용자가 개수와 형태를 임의로 지정 가능합니다. YOLO B-box Regression은 B-box 좌표를 직접 예측하나, YOLO v2에서는 미리 지정된 Anchor box의 offset(size,ratio)을 예측하기 때문에 문제가 훨씬 간단해집니다.
Training 부분
- High Resolution Classifier : 기존 모델은 VGG16 모델을 기반으로 224 x 224 size로 Pre-train하고, 448 x 448 size를 input으로 사용하여 불안정한 학습이 이루어졌다면, 448x448 size로 Pre-train하는 것으로 변경하여 mAP가 약 4% 향상되었습니다.
mAp
mAP(mean Average Precision)는 객체 탐지와 같은 컴퓨터 비전 분야에서 모델의 성능을 평가하는 중요한 지표 중 하나입니다. 이 지표는 모델이 객체를 얼마나 정확하게 탐지하고 분류하는지를 종합적으로 나타내며, 특히 다양한 클래스가 있는 경우에 모델의 효과를 평가하는 데 유용합니다.
이 본문에서 mAP는 COCO(Common Objects in Context) 데이터셋에서 평가된 기준입니다.
YOLO v3
- 2018년에 발표된 세 번째 버전 - 성능 개선(mAP: 57.9%), 탐지속도 소폭 증가, 작은 물체를 잘 못 찾는다는 문제 해결
YOLO v2에서 v3로 바뀐점
Architecture 부분
-
backbone 네트워크를 Darknet-19에서 Darknet-53로 변경했습니다.
-
Loss Function을 Softmax가 아닌 Binary cross entropy로 변경하여 box에서 각 class의 존재 여부를 확인하여 적절한 포착을 가능하게 변경했습니다. (Multi-Label Classification)

YOLO v4
- 2020년 4월에 발표된 네 번째 버전 - 성능(mAP: 60.0%), 정확도 향상, 속도 감소, 더 정확한 객체 검출
YOLO v3에서 v4로 바뀐점
Architecture 부분
-
기존의 모델들은 Backbone과 Head로 구성되어 있었는데 서로 다른 scale의 Feature map을 수집하는 Neck layer를 추가하였습니다.
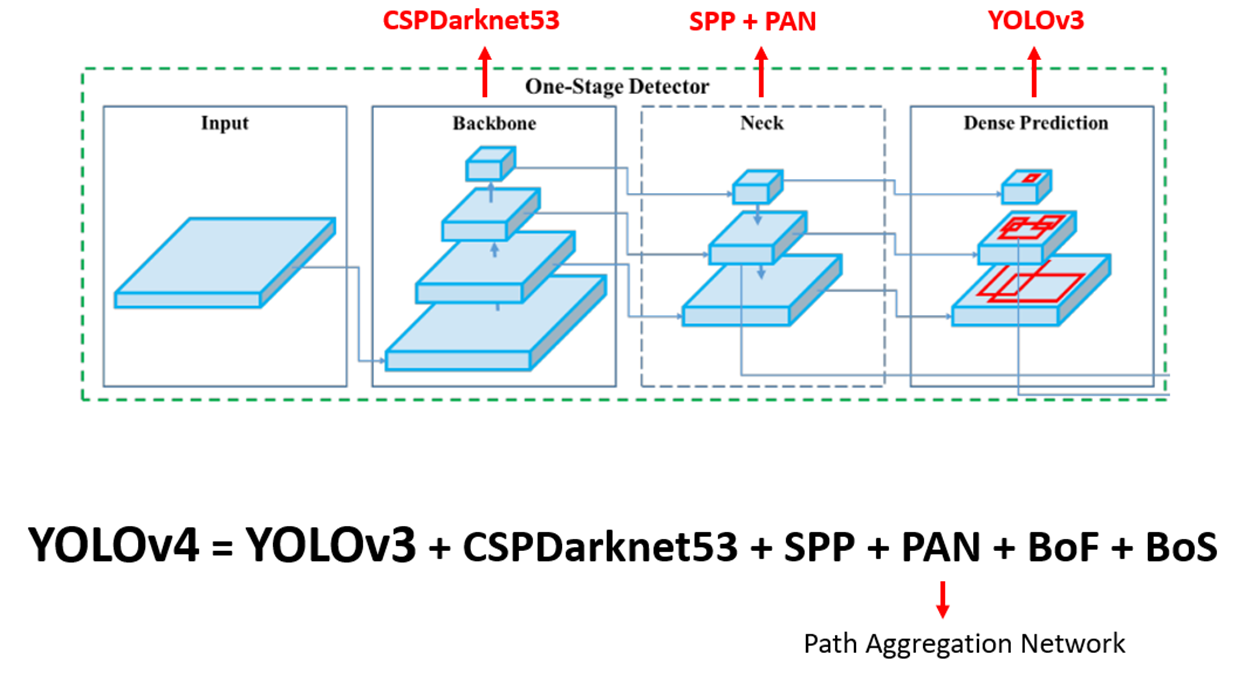
-
FPN(Feature Pyramid Network)과 PAN(Path Aggregation Network), SPP (Spatial Pyramid Pooling) 등의 새로운 네트워크 구조를 도입하여 성능을 향상하였습니다.
-
backbone 네트워크를 Darknet-53에서 CSP (Cross Stage Partial connections)로 변경했습니다.
- Bag of Freebies (BOF)
BOF는 inference cost의 변화 없이 (공짜로) 성능 향상(better accuracy)을 꾀할 수 있는 딥러닝 기법입니다. 대표적으로 데이터 증강(CutMix, Mosaic 등)과 BBox(Bounding Box) Regression의 loss 함수(IOU loss, CIOU loss 등)이 있습니다.
- Bag of Specials (BOS)
BOS는 BOF의 반대로, inference cost가 조금 상승하지만, 성능 향상이 되는 딥러닝 기법입니다.
- Feature Pyramid Network (FPN)
이 방법은 각 레벨에서 독립적으로 특징을 추출하여 객체를 탐지하는 방법입니다.
- Path Aggregation Network (PAN)
하위 계층 정보를 상위로 더 쉽게 전파할 수 있도록 하는 방법입니다.
- Cross-Stage Partial connections (CSP)
기존의 CNN 네트워크의 연산량을 줄이는 기법으로, 학습할 때 중복으로 사용되는 기울기 정보를 없앰으로써 연산량을 줄이면서도 성능을 높입니다.
YOLO v5
-
2020년 6월에 발표된 버전 - 성능 개선(mAP: 83.5%), 속도 감소, 더 작은 모델 크기를 가짐
-
Paper와 Tech Report 없이 코드만 공개
YOLO v4에서 v5로 바뀐점
Architecture 부분
- YOLO v4까지는 Darknet기반 backbone을 사용했으나 v5부터 Pytorch를 사용했습니다.
모델 부분
-
다른 Yolo 모델들과 다르게 크기별로 yolo v5 s, yolo v5 m, yolo v5 l, yolo v5 x로 나눈다는 것입니다.
-
small, medium, large, xlarge로 모델을 나누었습니다.
-
yolo v5 s가 가장 빠르지만 정확도가 비교적 떨어지고 yolo v5 x는 가장 느리지만 정확도는 향상되었습니다.
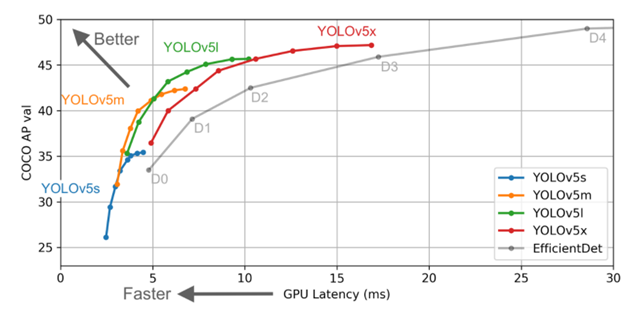
YOLO v7
- 2022년 7월 발표된 버전 - 성능 개선(mAP: 85.4%), 속도 감소, 효율 증가
YOLO v7의 특징
-
trainable bag-of-freebies 방법을 사용했습니다.
-
이 방법은 Real-time object detection 이면서 inference cost를 증가시키지 않고도 정확도를 향상시켰습니다.
-
이 방법은 당시 SOTA 방법보다 파라미터 수를 40%, 계산량을 50% 감소시키고 더 빠른 inference time과 더 높은 정확도를 달성하였습니다.
-
데이터를 마음껏 쌓아도 학습이 잘되도록 하기 위해 E-ELAN을 사용하였습니다.
- SOTA
SOTA (State of the Art)는 특정 기술이나 분야에서 최고의 성능을 나타내는 현재의 최고 수준을 의미합니다. 연구나 기술 개발에서 SOTA는 주어진 문제에 대해 가장 효과적인 해결책을 제시하는 기법, 모델, 또는 접근 방식을 뜻합니다. SOTA를 통해 해당 분야의 기술적 진보의 경계를 파악하고, 현재의 기술이나 방법론이 어느 정도까지 발전했는지를 이해할 수 있습니다.
YOLO v6
- 2022년 9월 발표된 버전 - 성능 개선(mAP: 84.4%), 속도 감소, 알고리즘의 효율 증가
YOLO v6의 특징
-
여러 방법을 이용하여 알고리즘의 효율을 향상시켰습니다.
-
시스템에 탑재하기 위한 Quantization과 distillation 방식을 도입하여 성능을 높혔습니다.
-
Backbone: 이전 YOLO 버전 Backbone보다 higher Parallelism을 가진 EfficientRep을 사용했습니다.
-
Neck: 기존 YOLO v4, v5 에서 사용된 PAN이 v6의 base가 되었고 여기에 RepBlocks으로 강화하여 사용했습니다. (RepPAN)
-
Head: Efficient Decoupled Head을 사용했습니다.
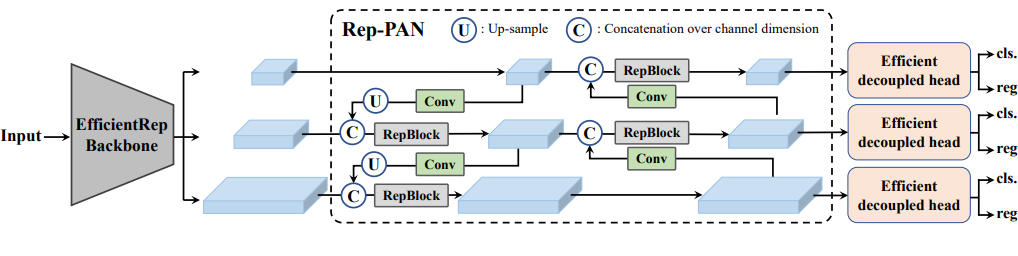
YOLO v8
-
2023년 1월 발표된 버전 - 성능 개선(mAP: 86.4%)
-
YOLO 모델을 위한 완전히 새로운 리포지토리를 출시하여 개체 감지, 인스턴스 세분화 및 이미지 분류 모델을 train하기 위한 통합 프레임워크로 구축하였습니다.
YOLO v8의 특징
-
Anchor Free Detection : 앵커박스의 offset 대신에 객체의 중심을 직접 예측하는 앵커프리모델이며 이로 인해 NMS의 속도를 높였습니다.
-
YOLOv8-seg, YOLOv8-pose, YOLOv8-obb, YOLOv8-cls 의 모델들이 있어 추론, 검증, 탐지, 분류 등 다양한 운영 모드와 호환됩니다.
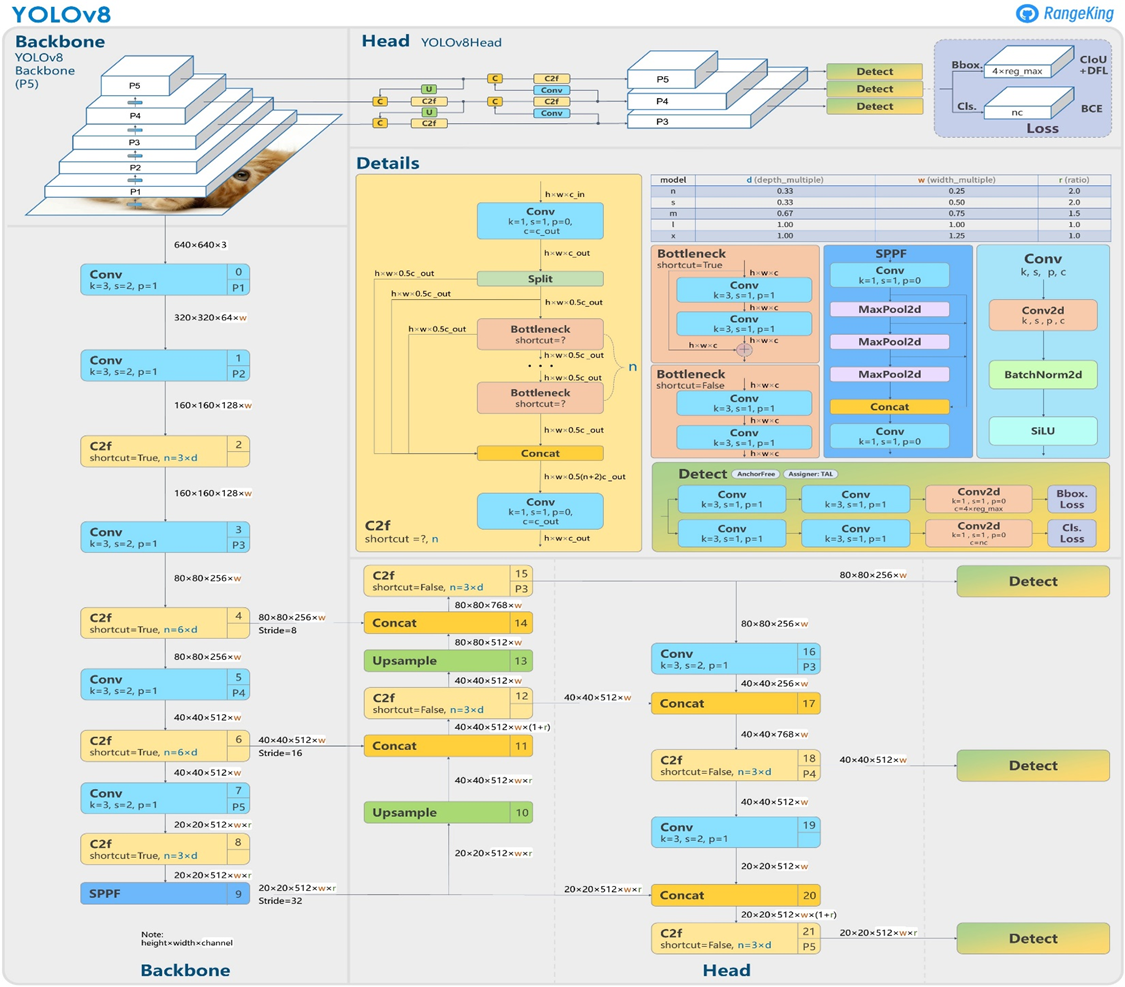
YOLO v9
-
2024년 2월 발표된 버전 - 성능 개선, 정보 병목 현상 완화
YOLO v9의 특징
-
v9-S, v9-M, v9-C 및 v9-E의 네 가지 모델로 출시되었습니다.
-
PGI(Programmable Gradient Information) 도입으로 정보 병목 현상을 완화시켰습니다.
- 정보 병목 현상 원리
정보 병목 현상은 데이터가 네트워크의 연속적인 계층을 통과할수록 정보 손실 가능성이 증가한다는 딥 러닝의 근본적인 문제를 드러내는 원리입니다.
I(X, X) >= I(X, f_theta(X)) >= I(X, g_phi(f_theta(X)))
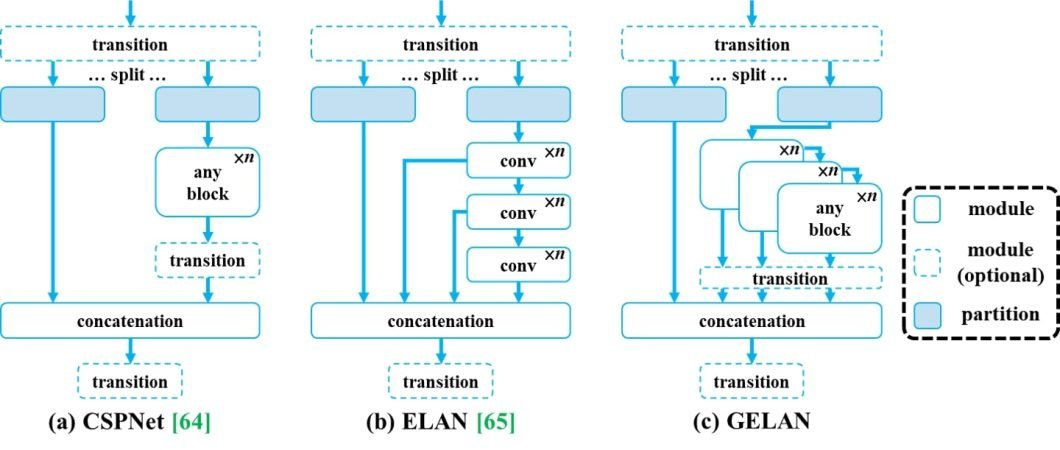
-
PGI(Programmable Gradient Information) 사용 : PGI는 정보 병목 문제를 해결하기 위해 YOLOv9에 도입된 새로운 개념으로, 심층 네트워크 계층에서 필수 데이터를 보존할 수 있도록 합니다. 이를 통해 신뢰할 수 있는 그라데이션을 생성하여 정확한 모델 업데이트를 촉진하고 전반적인 탐지 성능을 개선할 수 있습니다.
-
GELAN(Generalized Efficient Layer Aggregation Network) 사용 : GELAN은 전략적으로 아키텍처를 발전시켜 YOLOv9이 뛰어난 파라미터 활용도와 계산 효율성을 달성할 수 있게 해줍니다. 다양한 계산 블록을 유연하게 통합할 수 있도록 설계되어 속도나 정확도를 저하시키지 않습니다.

Reference
- Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. (2016). You Only Look Once: Unified, Real-Time Object Detection. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 779-788. (참조: pp. 1-4). doi:10.1109/CVPR.2016.91
- Joon-Yong Kim. 2023.7. A comparative study on the characteristics of each version of object detection model YOLO. https://www.dbpia.co.kr/pdf/pdfView.do?nodeId=NODE11528162
- 김선영, 강창호. 실시간 객체 인식 및 분할 기술: YOLO 알고리즘 분석. https://www.dbpia.co.kr/pdf/pdfView.do?nodeId=NODE11534777
- ultralytics. Ultralytics YOLOv8 문서. https://docs.ultralytics.com/ko/models/yolov8/
- ultralytics. Ultralytics YOLOv9 문서. https://docs.ultralytics.com/ko/models/yolov9/
- Gaudenz Boesch. YOLOv9: Advancements in Real-time Object Detection (2024). https://viso.ai/computer-vision/yolov9/
- Chien-Yao Wang. 2024/2. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. https://arxiv.org/abs/2402.13616
- 한준호. 2023/8. Object Detection (2) - YOLO 모델 비교. https://velog.io/@jjun-ho/Object-Detection-2-YOLO-%EB%AA%A8%EB%8D%B8-%EB%B9%84%EA%B5%90#yolov8-202301
- ByeongHun Kim. 2023/9. [YOLOv8] 빠르고 정확한 객체 인식의 새로운 기준. https://blog.deeplink.kr/?p=1469
- Jomii. 2023/3. [YOLO] YOLO 버전 - Yolo v1부터 Yolo v8까지 (23.03.기준). https://velog.io/@qtly_u/n4ptcz54#yolov8

https://pumpyoursound.com/u/user/1519313
https://sfx.thelazy.net/users/u/chinabamboo/
https://www.fantasyplanet.cz/diskuzni-fora/users/chinabamboo/
https://www.gta5-mods.com/users/chinabamboo
https://www.pintradingdb.com/forum/member.php?action=profile&uid=108220
https://www.wvhired.com/profiles/7038403-china-bamboo
https://all4.vip/p/page/view-persons-profile?id=87767
https://careers.gita.org/profiles/7038388-china-bamboo
https://www.fundable.com/china-bamboo
https://varecha.pravda.sk/profil/chinabamboo/o-mne/
https://www.forum-joyingauto.com/member.php?action=profile&uid=48040
https://www.mikocon.com/home.php?mod=space&uid=256736
https://scrapbox.io/chinabamboo/chinabamboo
https://slatestarcodex.com/author/chinabamboo/
https://hanson.net/users/chinabamboo
http://www.fanart-central.net/user/chinabamboo/
https://www.rwaq.org/users/bothbest-20250813145515
https://www.zubersoft.com/mobilesheets/forum/user-89124.html
https://www.niftygateway.com/@chinabamboo/
https://protospielsouth.com/user/77682
https://whyp.it/users/100591/chinabamboo
https://bulkwp.com/support-forums/users/chinabamboo/
https://spinninrecords.com/profile/chinabamboo
https://fyers.in/community/member/MAGfDcP7tF
https://velog.io/@chinabamboo/posts
https://robertsspaceindustries.com/en/citizens/chinabamboo
https://unityroom.com/users/chinabamboo
https://www.aseeralkotb.com/ar/profiles/china-bamboo-bfc-116365576188419692513-1755394900
https://mathlog.info/users/Y7CG8ma0cAeikQnPJW0IDMbf8EW2
https://mathlog.info/articles/RW0eKy1Cls8auLMkkODN