[YOLO] YOLO 버전 - Yolo v1부터 Yolo v8까지 (23.03.기준)
Computer Vision
이번 글에서는 YOLO 시리즈별 구조 및 특징에 대해 정리해보겠습니다. 23년 3월 기준 YOLO는 버전 8까지 나와있습니다.
< YOLO 버전별 출시 시점 >
- YOLOv1 : 2016년에 발표된 최초 버전으로, 실시간 객체 검출을 위한 딥러닝 기반의 네트워크
- YOLOv2 : 2017년에 발표된 두 번째 버전으로, 성능을 개선하고 속도를 높인 것이 특징
- YOLOv3 : 2018년에 발표된 세 번째 버전으로, 네트워크 구조와 학습 방법을 개선하여 객체 검출의 정확도와 속도를 모두 개선
- YOLOv4 : 2020년 4월에 발표된 네 번째 버전으로, SPP와 PAN 등의 기술이 적용되어 더욱 정확한 객체 검출과 더 높은 속도를 제공
- YOLOv5 : 2020년 6월에 발표된 버전으로 YOLOv4와 비교하여 객체 검출 정확도에서 10% 이상 향상되었으며, 더 빠른 속도와 더 작은 모델 크기를 가짐
- YOLOv7 : 2022년 7월 발표된 버전으로, 훈련 과정의 최적화에 집중하여 훈련 cost를 강화화는 최적화된 모듈과 최적 기법인 trainable bag-of-freebies를 제안
- YOLOv6 : 2022년 9월 발표된 버전으로, 여러 방법을 이용하여 알고리즘의 효율을 높이고, 특히 시스템에 탑재하기 위한 Quantization과 distillation 방식도 일부 도입하여 성능 향상
- YOLOv8 : 2023년 1월 발표된 버전으로, YOLO 모델을 위한 완전히 새로운 리포지토리를 출시하여 개체 감지, 인스턴스 세분화 및 이미지 분류 모델을 train하기 위한 통합 프레임워크 로 구축됨
YOLOv1
-
First YOLO
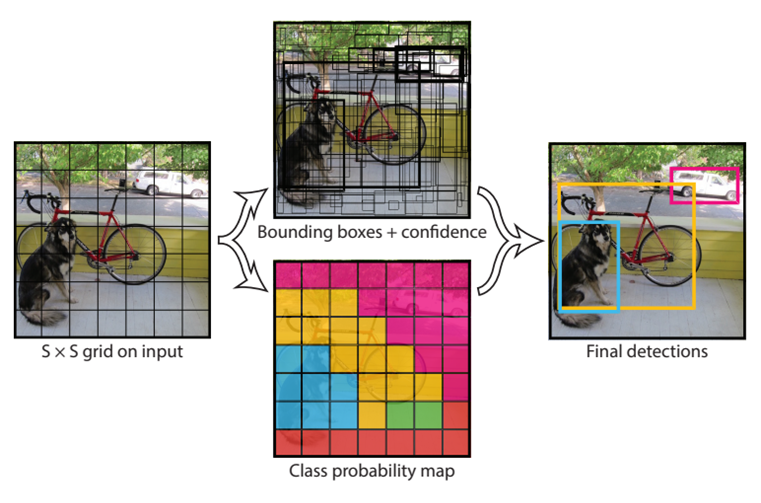
S x S 크기의 Grid Cell로 Input Image를 분리하고, Cell마다 B개의 Bounding boxes, confidence score, Class probabilities를 예측한다.
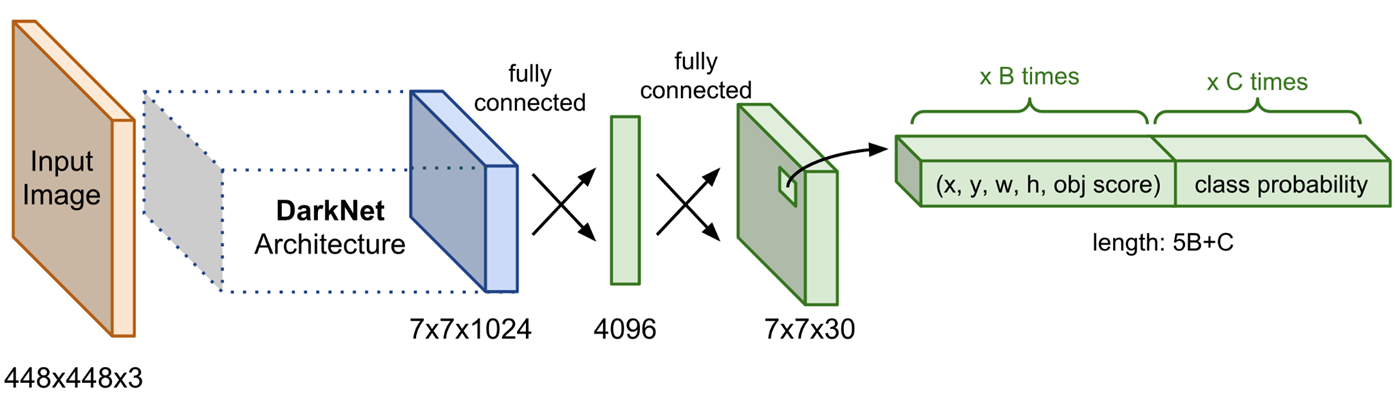
Final Output : S x S x ( B * 5 + C ) [ S : Num of Cell, B : Num of Bounding boxes, C : Num of Classes]
-
Overlap Problem과 NMS (None Maximum Suppression)
각각의 Grid Cell마다 B개의 Bounding Box가 생성되는데, 인접한 Cell이 같은 객체를 예측하는 Bounding Box를 생성하는 문제가 발생한다.
이를 해결하기 위해 confidence score와 IOU를 계산하여 가장 높은 confidence score의 Bounding Box를 선택하고 선택한 Bounding Box와 IOU가 큰 나머지 Bounding Box를 삭제하는 개념이다.
 NMS에 관해서는 여기서 더 자세히 설명해놓았다.
NMS에 관해서는 여기서 더 자세히 설명해놓았다. -
Architecture
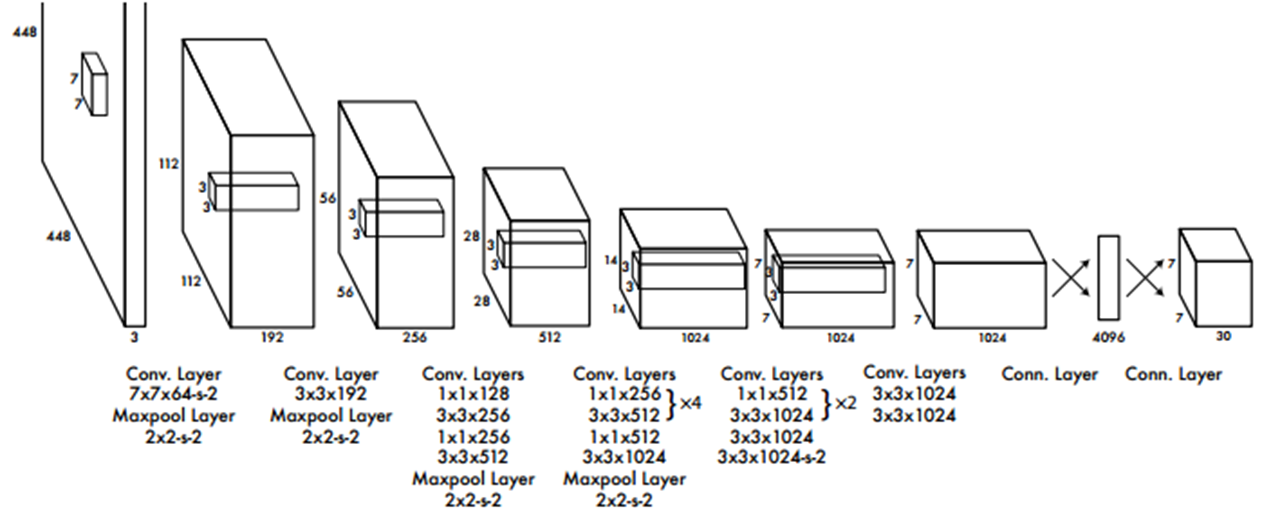
24개의 Conv layer와 2개의 FC layer로 구성되어 있다. Darknet network라고 부르며 ImageNet dataset으로 Pre-trained된 network를 사용한다.
1x1 Conv layer와 3x3 Conv layer의 교차를 통해 Parameter 감소시킨다.
-
특징
- 각 Grid cell은 하나의 Class만을 예측한다.
- 인접한 Cell들이 동일한 객체에 대한 Bounding Box를 생성할 수 있다.
- Background Error가 낮다.
- 당시 SOTA들에 비해 Real-Time 부분에서 가장 좋은 성능을 보였다.
YOLOv2
YOLOv1에서 v2로 바뀐점
-
Architecture
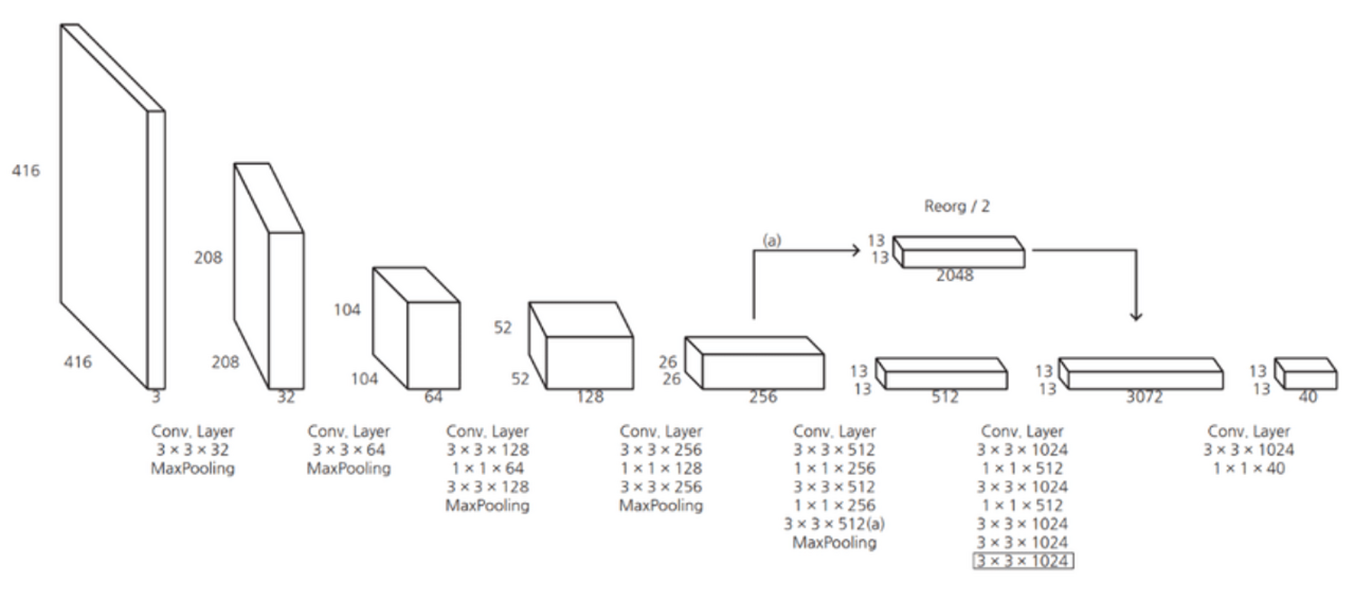
기존의 Darknet을 개선한 Darknet19을 제안하였다.
기존 network의 마지막 Fully Connected Layer를 삭제하여 1✕1 Convolution Layer로 대체했다.
Global Average Pooling을 사용해 파라미터를 줄여 속도 향상 -
Anchor Box 도입으로 인한 학습 안정화
YOLOv1에서는 Grid 당 2개의 B-Box 좌표를 예측하는 방식이었다면 YOLOv2에서는 Grid 당 5개의 Anchor Box를 찾는다.- Anchor Box
: 여러 개의 크기와 비율로 미리 정의된 형태를 가진 경계 박스(B-Box)로서 사용자가 개수와 형태를 임의로 지정 가능하다. YOLO B-box Regression은 B-box 좌표를 직접 예측하나, YOLO v2에서는 미리 지정된 Anchor box의 offset(size,ratio)을 예측하기 때문에 문제가 훨씬 간단해진다.
- Anchor Box
-
Fine-grained features 적용
중간 feature맵과 최종 feature맵을 합쳐 이용한다. 즉, 앞 Convolution Layer의 High Resolution Feature Map을 뒷 단의 Convolution Layer의 Low Resolution Feature Map에 추가한다.
👉🏻 중간 feature 맵은 지역적 특성을 잘 반영하기 때문
즉, High Resolution Feature는 작은 객체에 대한 정보를 함축하고 있기 때문에 작은 객체 검출에 강할 수 있도록 했다.
-
Batch Normalization
기존 모델에서 Dropout Layer를 제거하고 Batch Norm을 사용하여 mAP 점수를 2% 향상했다. -
High Resolution Classifier
기존 모델은 224x224 size로 Pre-train하고, 448x448 size를 input으로 사용하여 불안정한 학습이 이루어졌다면, 448x448 size로 Pre-train하는 것으로 변경하여 mAP가 4% 향상되었다. -
Dynamic Anchor box
- Faster R-CNN에서 Anchor Box의 사이즈와 비율을 미리 정하는 부분에 대한 문제가 제기되어 제안된 개념
- YOLOv2 에서는 k-means Clustering을 통해 GT와 가장 유사한 Optimal Anchor box를 탐색함으로써 데이터셋 특성에 적합한 Anchor Box를 생성
YOLOv3
v2 모델에 비해 탐지 속도는 약간 느려졌지만 탐지 성능을 또 대폭 개선한 v3 모델이 개발된다.
-
Architecture
backbone 네트워크를 Darknet-19에서 Darknet-53로 변경
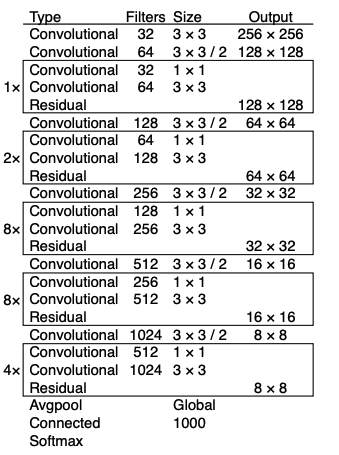
이전 Darknet-19에 ResNet에서 제안된 skip connection 개념을 적용
Pooling layer를 삭제
SSD 모델의 Multi-Scale Feature Layer와 Retinanet의 FPN(Feature Pyramid Network)과 유사한 기법을 적용
(SSD의 Multi-Scale Feature Layer는 서로 다른 크기의 Feature Map에 각 포인트마다 Object Detection을 수행해주는 기법이다.) -
Multilabel Classification
실제 어떤 물체가 사람이면서 동시에 여성일수도 있다. 즉, 한 물체에 대해 multi classlabel을 가질 수 있다. 그러나 softmax는 한 박스 안에서 여러 객체가 존재할 경우 적절하게 포착할 수 없었다. 따라서 version3에서는 이것이 가능하도록 마지막에 Loss function을 softmax가 아닌 모든 class에 대해 sigmoid를 취해 각 class별로 binary classification을 하도록 바꾸었다(Binary cross entropy)
YOLOv4
YOLOv4는 기존 YOLO시리즈의 작은 객체 검출 문제를 해결하고자 한 것이 특징이다.
-
다양한 작은 object들을 잘 검출하기 위해 input 해상도를 크게 사용하였다. 기존에는 224, 256 등의 해상도을 이용하여 학습을 시켰다면, YOLOv4에서는 512을 사용하였다.
-
또한 receptive field를 물리적으로 키워 주기 위해 layer 수를 늘렸으며, 하나의 image에서 다양한 종류, 다양한 크기의 object들을 동시에 검출하려면 높은 표현력이 필요하기 때문에 parameter 수를 키워주었다.
-
Architecture
정확도를 높이는 반면에 있어서의 속도문제는 아키텍처의 변경을 통해 해결하였다.- FPN(Feature Pyramid Network)과 PAN(Path Aggregation Network) 기술을 도입
- 또한, CSP (Cross Stage Partial connections) 기반의 backbone 연결과 SPP (Spatial Pyramid Pooling) 등의 새로운 네트워크 구조를 도입하여 성능을 향상
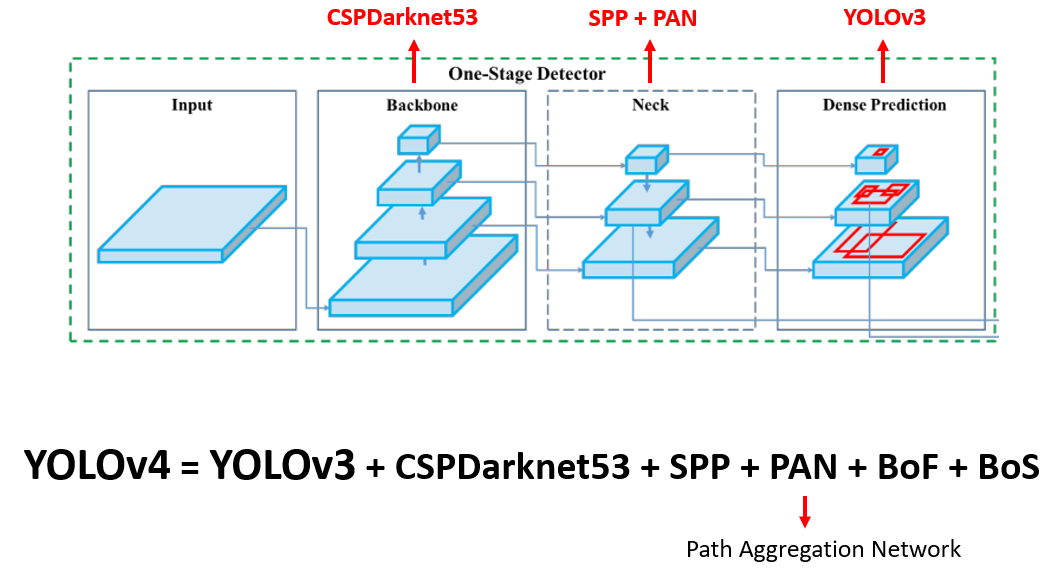
이러한 기술들을 도입함으로써 YOLOv4는 COCO 데이터셋에서 mAP(mean Average Precision) 43.5%와 65.7 FPS의 성능을 보여주었다.
또한, YOLOv4는 다양한 데이터셋을 이용한 데이터 증강 기술과 quantization 기술도 함께 도입하여 더 높은 성능과 더 낮은 모델 크기를 가지게 되었다.
YOLOv5
v5는 v4 발표 이후 2개월 만에 paper 없이 코드만 공개되었다.
Yolo v5는 Yolo v4와 마찬가지로 이러한 장점을 가진 CSPNet을 이용하는데, BottleneckCSP를 사용하여 각 계층의 연산량을 균등하게 분배해서 연산 bottleneck을 없애고 CNN layer의 연산 활용을 업그레이드 시켰다.
다른 Yolo 모델들과 다른 점은 backbone을 depth multiple과 width multiple를 기준으로 하여 크기별로 yolo v5 s, yolo v5 m yolo v5 l, yolo v5 x로 나눈다는 것이다. 이는 small, medium,large, xlarge라고 생각하면 구분하기 쉽다. 따라서 아래 그림과 같이 yolo v5 s가 가장 빠르지만 정확도가 비교적 떨어지며 yolo v5 x는 가장 느리지만 정확도는 향상된다.
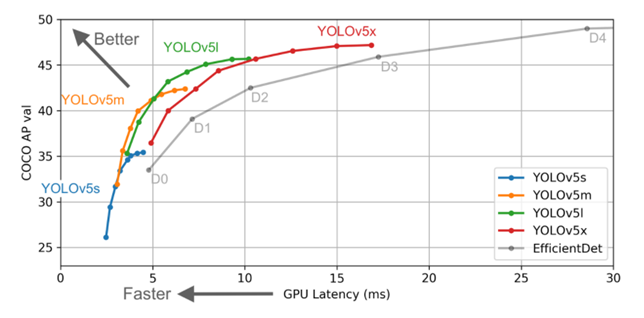
정확도와 속도는 상충관계이기 때문에 모두 잡을 순 없어 s 가 가장 빠른 대신 정확도는 떨어지고 x가 가장 느린 대신 정확도는 향상된다.
YOLOv7
real-time object detection 이면서 inference cost를 증가시키지 않고도 정확도를 향상시킬 수 있는 trainable bag-of-freebies 방법을 제안하는데, 해당 방법들이 적용된 모델이 v7이다.
특징
- Model reparameterization
학습시 여러개의 레이어들을 학습하고 inference시에는 해당 레이어들을 하나의 레이어로 fusing함- Label assignment
Ground truth를 그냥 사용하는 것이 아니라 모델의 prediction, ground truth의 distribution을 고려하여 새로운 soft label 생성
기존 label assignment방법들이 다른 branch에서 도출되는 다른 output에 대해 dynamic label assignment strategy 방법을 제안- extend and compound scaling
방법을 통해 계산에 효율적으로 사용
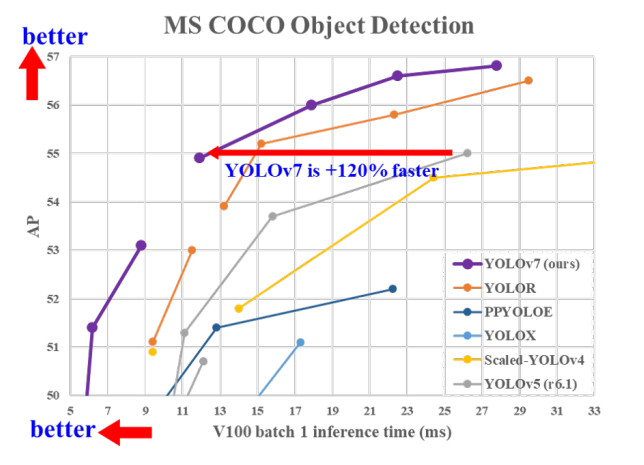
제안한 방법은 당시 SOTA 방법 보다 parameter 수를 40%, 계산량을 50% 감소시키고 더 빠른 inference time과 더 높은 accurcy를 달성하였다.
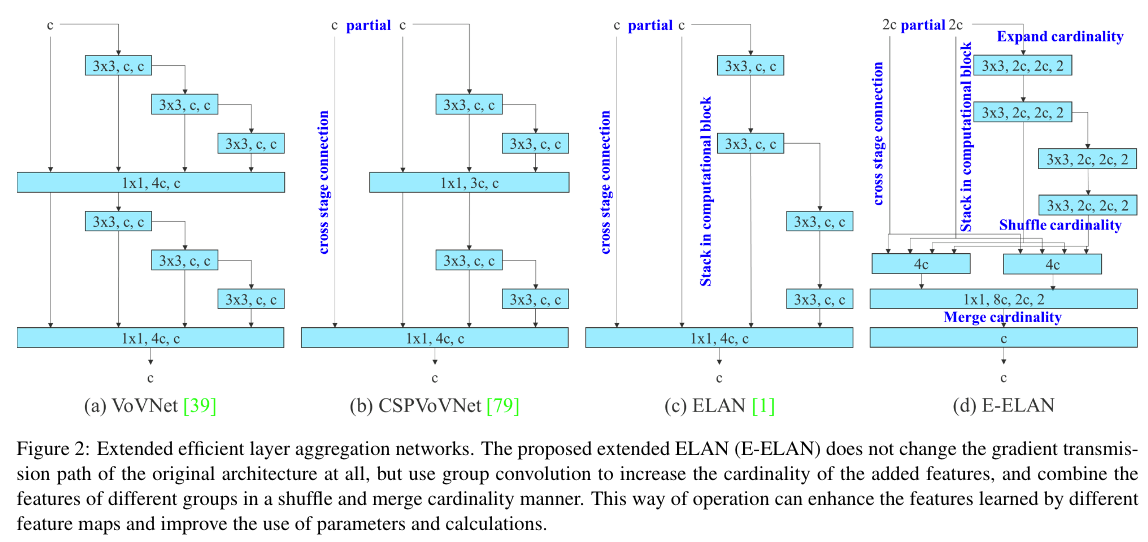
기존 연구들에서 제안된 ELAN은 Computation block을 어느정도 많이 쌓아도 잘 학습되지만 무한대 가까이로 쌓을경우 parameter utilization이 낮아지는 문제가 있었음
따라서 YOLOv7에서는 마음껏 쌓아도 학습이 잘되도록 하기 위해 E-ELAN을 제안함
- Architecture
- Expand, shuffle, merge cardinality를 통해 computational block을 많이 쌓아도 학습능력이 뛰어남
- 아키텍쳐 측면에서 E-ELAN은 computational block의 아키텍쳐만 변경하는 반면 transition layer의 아키텍쳐는 변경되지 않음
- 이러한 전략은 grup conv를 사용하여 computational block의 channel과 cardinality를 확장
- computational layer의 모든 block에 동일한 group parameter와 channel multiplier를 적용하고, 각 computational block에서 계산된 feature map은 설정된 parameter에 따라 group으로 섞인 다음 함께 연결된다. 이 때 각 feature map group의 channel 수는 원래 아키텍쳐 수와 동일
- 마지막으로 merge cardinality를 수행하기 위해 g개의 feature map group을 추가
YOLOv6
Yolov6는 특이하게도 Yolov7보다 늦게 출시되었다.
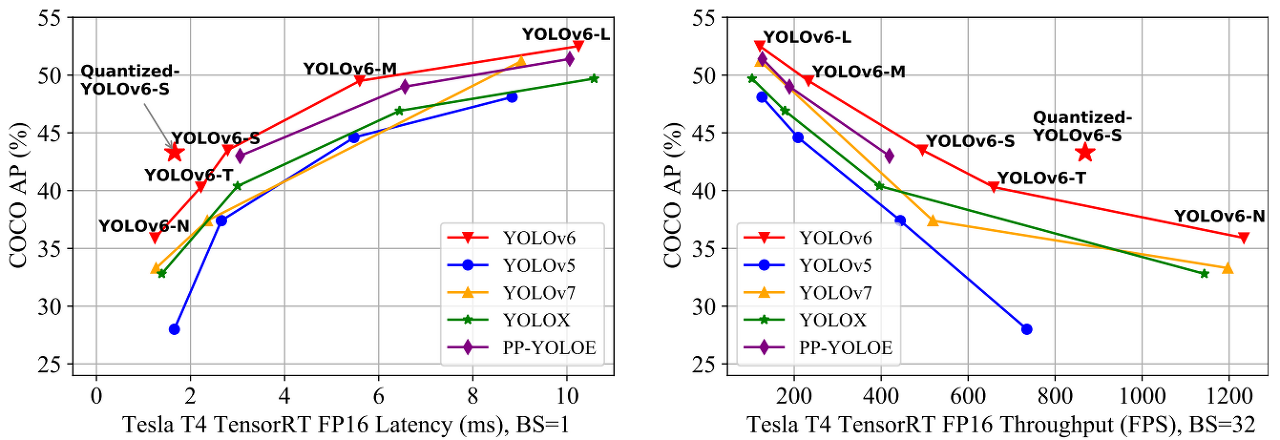
Yolov6는 여러 방법을 이용하여 알고리즘의 효율을 높이고, 특히 시스템에 탑재하기 위한 Quantization과 distillation 방식도 일부 도입하여 성능을 높혔다.
-
Architecture
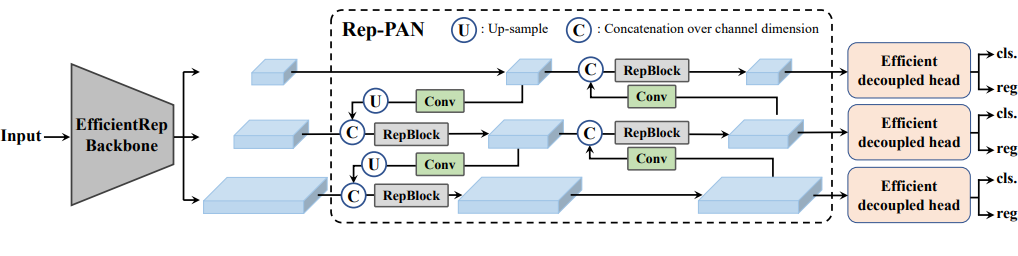
-
백본은 EfficientRep Backbone이 사용되었다. Neck 부분은 Rep-PAN이 사용되었다. head는 Efficient decoupled head가 사용되었다.
-
먼저 네트워크 구조에서 가장 핵심이 되는 기여는 CSPstackRep Block이다. CSPstackRep Block은 CSP(cross stage partial) + RepVGG 방식이다. 이 방식은 backbone에 사용된다.
-
소형 모델은 일반 단일 경로 백본을 특징으로 하고 대형 모델은 효율적인 다중 분기 블록을 기반으로 구축
-
주요 특징
- 자기 증류 기법 수행시 모든 학습 단계에서 학생 모델이 지식을 보다 효율적으로 학습할 수 있도록 교사와 레이블의 지식을 동적으로 조정 가능
- RepOptimizer 및 채널별 증류로 객체탐지를 위한 양자화 체계를 개선하여 43.3% COCO AP와 32개의 배치 크기에서 869 FPS 성능을 가짐
- Loss Function
- 메인스트림 앵커가 없는 객체 탐지 모델의 손실 함수에는 classification loss, box regression loss, object loss이 포함된다.
- classification loss로는 VFL(VariFocal Loss)을 사용했다.
*VariFocalLoss
VariFocalLoss는 객체 검출에서 주로 사용되는 손실 함수 중 하나로 YOLOv4에서 처음 소개되었다.
기존의 객체 검출에서 사용되던 Cross-Entropy 손실 함수는 모든 예측 박스에 대해 동일한 가중치를 부여하는 데 비해, VariFocalLoss는 예측 박스의 어려운 예제에 더 높은 가중치를 부여한다. 즉, VariFocalLoss는 예측 오류가 큰 예제에 더 많은 비중을 둬서 모델 학습을 개선하려는 목적을 가지고 있다. - VariFocalLoss를 분류 손실로, SIoU/GIoU 손실을 회귀 손실로 선택한다. box regression loss는 큰 모델에는 GIoU, 작은 모델에는 SIoU를 사용했다.
- Probability Loss로 DFL (Distribution Focal Loss)를 M/L 모델을 위해 사용했다.
- Object Loss는 FCOS를 사용했다.
- Re-parameterizing Optimizer for PTQ
- Re-parameterizing Optimizer를 이용하여 PTQ를 진행
- Re-parameterizing Optimizer는 기존의 SGD 같은 범용적optimizer와 다르게 특정 reparameterization based model의 구조에 특화된 optimizer이기 때문에 가장 영향이 많이 미치는 layer를 뽑아낼 수 있다.
- RepOptimizer를 이용하여 PTA를 적용했을 때 성능이 약간 밖에 줄지 않아 QAT channel wise self-distillation를 활용하여 개선
결과적으로 Quantization의 양대 산맥인 PTQ, QAT를 모두 활용하여 거의 손해 없이 Quantization을 이루어냈다.
YOLOv8
23년 3월 기준 가장 최근에 나온 YOLO 버전이며 2023 년 1월 Ultralytics 에서 개발되었다. YOLO 모델을 위한 완전히 새로운 리포지토리를 출시하여 개체 감지, 인스턴스 세분화 및 이미지 분류 모델을 train하기 위한 통합 프레임워크로 구축되었다.
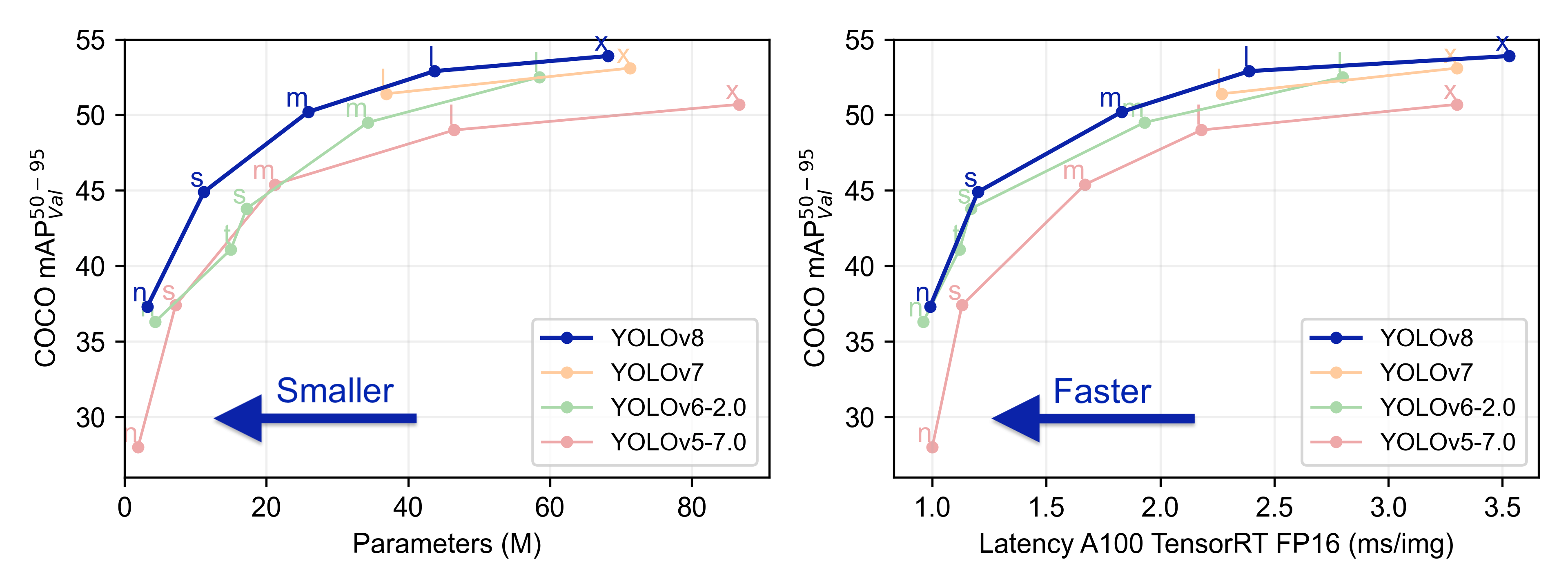
YOLOv8은 YOLOv8n, YOLOv8x, YOLOv8m 등 다양한 버전이 존재하는 데 그중 하나인 YOLOv8m (medium) 은 COCO에서 50.2의 mAP를 달성하였고 다양한 작업별 domain들에서 YOLOv8은 YOLOv5보다 높은 성능을 보임
공식적 논문은 아직 발표되지 않아서 가장 잘 나타낸 차트를 가져왔다.
YOLOv8 Architecture, visualisation made by GitHub user RangeKing
YOLOv5와 비교했을 때 변경된 사항
- C3 모듈을 C2f 모듈로 교체
- Backbone에서 첫 번째 6x6 Conv를 3x3 Conv으로 교체
- 두 개의 컨볼루션 레이어 삭제
- ConvBottleneck에서 첫 번째 1x1 Conv를 3x3 Conv로 교체
- 분리된 head 사용 및 objectness 분기 삭제
YOLOv8은 앵커박스의 offset 대신에 객체의 중심을 직접 예측하는 앵커프리모델이며 이로 인해 NMS의 속도를 높였다.
버전별로 개선점과 아키텍처를 간단히 정리하려고 했는데 생각보다 간단하지도 않았고 용어를 정리하느라 조금 오래걸리기도 했고 애매한 리뷰가 된게 아닌가 싶습니다. v8은 아무래도 올해 출시되어 공식적인 paper가 없고 리뷰들도 적다보니 아키텍처를 이해하기 어려워 추후 다시 공부하여 따로 업데이트 하겠습니다.

5개의 댓글

YOLO 원작자는 V3까지 개발 후 중단하였고, 이에 뒤어 YOLO라는 이름을 붙인 work들이 수많이 등장하였습니다. 개발하는 팀도 다르구요. 따라서 v4부터는 번호를 따지는 것은 어찌보면 무의미합니다. YOLOv4/Scaled-YOLOv4/YOLO-R/YOLOv7 을 개발한 팀이 그나마 YOLO의 원작자 연구를 이어나가는 연구팀에 가깝습니다. YOLOv5/YOLOv8을 개발한 Ultralytics는 연구논문 없이 소프트웨어를 개발하는 개발팀이며, 대중들에게 좋은 소프트웨어를 무료로 제공해주는 것은 고맙지만, v4/v7이 개발된 후 버전숫자를 빼앗으려고 하는 의도가 너무 뻔히 보여 얌체 같다는 느낌이 들기도 합니다.


https://zybuluo.com/bothbest/note/2620977
https://medibulletin.com/author/chinabamboo/
https://thefwa.com/profiles/chinabamboo
https://www.politforums.net/profile.php?showuser=chinabamboo
https://tutorialslink.com/member/ChinaBamboo/68662
https://schoolido.lu/user/chinabamboo/
https://backloggery.com/chinabamboo
https://www.catapulta.me/users/chinabamboo
https://party.biz/profile/327933
https://wearedevs.net/profile?uid=202610
https://my.usaflag.org/members/chinabamboo/profile/
https://malt-orden.info/userinfo.php?uid=414587
https://womenindata.mn.co/members/35670855
https://givestar.io/profile/26482d73-cc4c-4e15-8a36-31a21bcbd467
https://aisalon.mn.co/members/35670809
https://pathwaycitychurch.mn.co/members/35670788
https://www.yourquote.in/china-bamboo-bfc-d1dpf/quotes
https://noti.st/chinabamboo
https://www.tkaraoke.com/forums/profile/chinabamboo/
너무 유익합니다.