Labeling and Test - 데이터 수집, 가공 및 pre-trained network 활용
- pre-trained networks (AlexNet, VGG, GoogleNet, Resnet)
- overfitting-underfitting
- roboflow - labeling
- COCO
- tensorboard
Pretrained networks
사전학습 모델을 사용하는 방법으로 torchvision에서 기본으로 제공한다 => torchvision.models
AlexNet
2012년 ILSVRC(ImageNet Large Scale Visual Recognition Challenge) 대회에서 우승한 컨볼루션 신경망 아키텍처입니다. 이 아키텍처는 딥러닝의 현대적인 변화를 주도한 모델 중 하나로 꼽히며, 컴퓨터 비전 분야에서 큰 돌파구를 만들었습니다.
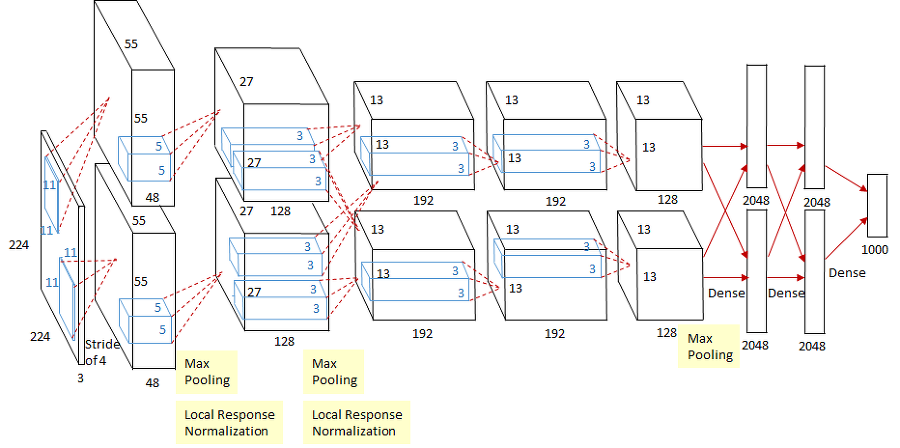
특성
2.1. 다층 컨볼루션 신경망
AlexNet은 8개의 계층(layer)로 구성된 컨볼루션 신경망으로, 이전 모델들과 비교해 훨씬 더 깊은 구조를 가졌습니다. 이 깊은 구조는 이미지 특징을 높은 수준에서 추출하고 학습하는 데 도움이 되었습니다.
2.2. ReLU 활성화 함수
AlexNet은 활성화 함수로 시그모이드 대신 ReLU(Rectified Linear Unit)를 사용했습니다. 이로 인해 학습 속도가 빨라지고 그레디언트 손실 문제가 완화되었습니다.
2.3. 드롭아웃(Dropout)
드롭아웃은 과적합(Overfitting)을 방지하기 위한 기술로, AlexNet에서도 사용되었습니다. 이를 통해 모델의 일반화 성능이 향상되었습니다.
2.4. GPU 가속
AlexNet은 당시에 비해 상당히 큰 모델이었기 때문에, 병렬 처리를 위해 GPU 가속을 활용했습니다. 이로 인해 학습 시간이 크게 단축되었습니다.
GoogLeNet
AlexNet이라고 불리는 이전 모델보다 더 깊고 효율적인 아키텍처를 가지고 있습니다.
특징:
Inception 모듈: 이 모델은 Inception 모듈이라고 불리는 특별한 구조를 사용합니다. Inception 모듈은 여러 크기의 필터(커널)를 한 번에 사용하여 이미지에서 다양한 유용한 정보를 추출합니다. 이것은 모델이 더 다양한 패턴과 특징을 학습할 수 있도록 돕습니다.
1x1 컨볼루션: Inception 모듈 내에서 1x1 크기의 필터를 사용하여 데이터의 크기를 줄입니다. 이것은 모델의 복잡성을 줄이고 계산량을 줄입니다.
Auxiliary Classifier: GoogLeNet은 중간 단계에서 별도의 보조 분류기를 사용합니다. 이 보조 분류기는 모델이 중간 단계에서 얼마나 잘 학습되고 있는지를 평가하는 데 도움을 줍니다.
Global Average Pooling: 마지막 분류 레이어에 대한 입력을 구할 때 Fully Connected 레이어 대신 평균 풀링을 사용합니다. 이것은 모델의 크기를 줄이고, 오버피팅을 방지하는 데 도움이 됩니다.
Batch Normalization: 이 모델은 Batch Normalization이라고 불리는 기술을 사용하여 학습 속도를 높이고 모델을 안정화시킵니다.
AlexNet과의 차이
GoogLeNet과 AlexNet의 가장 큰 차이점은 모델의 깊이와 구조입니다. GoogLeNet은 더 깊고 복잡한 모델로, Inception 모듈을 사용하여 이미지의 다양한 특징을 효과적으로 추출합니다. 반면 AlexNet은 덜 복잡하고 얕은 모델로, 단순한 컨볼루션 레이어를 사용합니다.
VGGNet
VGGNet은 주로 이미지 분류 및 객체 검출과 같은 컴퓨터 비전 작업에서 사용됩니다. 사전 훈련된 VGG 모델을 가져와서 원하는 작업에 맞게 파인 튜닝하여 사용할 수 있습니다. 또한, VGGNet은 학습 된 특징 추출기로서 중간 레이어의 출력을 활용하여 다른 작업에도 활용할 수 있습니다.
VGGNet은 그 당시에는 매우 깊은 신경망 아키텍처였으며, 이후의 딥 러닝 모델에도 영향을 미쳤습니다. 그러나 더 깊고 효율적인 아키텍처가 등장하면서 VGGNet은 일부 분야에서는 대체되기도 했습니다.
특징
깊은 신경망 아키텍처: VGGNet은 깊은 신경망 아키텍처로 유명합니다. 이 아키텍처는 16개 또는 19개의 가중치 층으로 구성되어 있으며, 각 층은 작은 3x3 크기의 컨볼루션 필터와 2x2 크기의 최대 풀링 레이어로 구성됩니다.
동일한 크기의 필터 사용: VGGNet의 중요한 특징 중 하나는 모든 컨볼루션 층에서 3x3 크기의 필터를 사용한다는 것입니다. 이러한 작은 필터 크기를 사용함으로써 신경망이 더 깊어질 수 있고, 많은 비선형성을 학습할 수 있습니다.
최대 풀링 레이어: VGGNet은 최대 풀링 레이어를 사용하여 공간 차원을 줄입니다. 이것은 공간적인 계층 구조를 생성하고, 특징의 크기를 절반으로 줄여 계산 효율성을 높입니다.
Fully Connected 레이어: VGGNet 아키텍처의 최상위에는 하나 이상의 완전 연결 (fully connected) 레이어가 있으며, 이 레이어는 최종 분류를 수행합니다.
다양한 버전: VGGNet은 다양한 버전이 있으며, 가중치의 개수와 깊이에 따라 VGG16과 VGG19 등으로 불립니다. VGG16은 16개의 가중치 층을 갖고 있으며, VGG19는 19개의 가중치 층을 갖고 있습니다.
사전 훈련된 모델: VGGNet은 ImageNet 데이터셋에서 사전 훈련된 모델이 공개되어 있어, 전이 학습을 통해 다양한 컴퓨터 비전 작업에 활용할 수 있습니다.
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torchvision.models as models
from torch.autograd import Variable
# VGG16 모델을 불러오기
vgg16 = models.vgg16(pretrained=True)
# 이미지를 불러와서 VGGNet 모델에 입력할 수 있도록 전처리
transform = transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])
# 이미지 분류를 위한 예시 이미지 불러오기
image = Image.open('example.jpg')
image = transform(image)
image = Variable(image.unsqueeze(0))
# 모델에 이미지 전달
vgg16.eval()
output = vgg16(image)
# 결과 출력
_, predicted = torch.max(output.data, 1)
print(predicted)ResNet
물체를 인식하는 컴퓨터 비전 모델은 여러 층으로 이루어진 신경망입니다. 각 층은 이미지의 다른 특징을 감지하려고 노력하며, 더 깊은 층으로 갈수록 더 고수준의 특징을 찾으려고 합니다.
ResNet은 이런 깊은 신경망을 더 효과적으로 학습시키기 위한 아이디어를 가지고 있습니다. 기존의 딥 네트워크에서는 층이 깊어질수록 학습이 어려워지고, 심지어 그레이디언트 소실 문제 때문에 학습이 멈출 수 있습니다.
ResNet은 이 문제를 해결하기 위해 각 층 사이에 "스킵" 연결을 추가했습니다. 이 스킵 연결은 이전 층의 출력값을 현재 층의 출력값에 직접 더해줍니다. 이것은 마치 이전 단계에서 학습한 내용을 그대로 유지하면서 새로운 특징을 더 배울 수 있게 해줍니다.
예를 들어, 얼굴을 인식하는 모델에서 눈을 감지하는 층에서 학습한 내용을 그대로 다음 층에서 활용할 수 있습니다. 그렇게 하면 네트워크가 깊어져도 더욱 정확한 특징을 학습할 수 있게 되죠.
ResNet은 이런 스킵 연결을 여러 개 쌓아서 깊은 네트워크를 만들며, 이를 통해 높은 성능을 달성합니다. 이렇게 하면 깊은 네트워크에서도 이미지 인식과 관련된 다양한 작업을 수행할 수 있게 됩니다.
roboflow - labeling
COCO - pycocotools
Roboflow와 COCO 데이터셋을 사용하여 얼굴 감지 (Face Detection) 작업을 수행하는 과정을 요약한 것입니다.
-
!pip install roboflow: Roboflow 패키지를 설치합니다.
-
Roboflow API를 사용하여 데이터셋을 다운로드합니다. 아래 코드에서 api_key와 프로젝트 및 데이터셋 정보가 제공되어야 합니다.
from roboflow import Roboflow
rf = Roboflow(api_key="S0hGdSeEoTy0N8fdlyVb")
project = rf.workspace("mohamed-traore-2ekkp").project("face-detection-mik1i")
dataset = project.version(24).download("coco")
3.이미지 파일을 불러와 시각화합니다.
import skimage.io as io
import matplotlib.pyplot as plt
I = io.imread('./train/' + img['file_name'])
plt.imshow(I)
plt.axis('off')
- COCO 데이터셋에서 얼굴 감지 정보를 로드하고 시각화합니다.
catIds = coco.getCatIds(catNms=nms)
annIds = coco.getAnnIds(imgIds=img['id'], catIds=catIds, iscrowd=None)
anns = coco.loadAnns(annIds)
coco.showAnns(anns, draw_bbox=True)
나의 데이터셋을 pytorch에 올려 사용해보자
from torch.utils.data.dataset import Dataset
import torchvision.transforms as transforms
from pycocotools.coco import COCO
from PIL import Image
import os
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
class MyCocoDataset(Dataset):
def __init__(self, root):
super().__init__()
self.root = root
# COCO 데이터셋 로드
self.coco = COCO(os.path.join(self.root, '_annotations.coco.json'))
# 카테고리 정보 추출
cats = self.coco.loadCats(self.coco.getCatIds())
nms = [cat['name'] for cat in cats]
self.catIds = self.coco.getCatIds(catNms=nms)
# 이미지 ID 추출
whole_image_ids = self.coco.getImgIds()
self.imgIds = []
# 어노테이션이 있는 이미지만 선택
for idx in whole_image_ids:
annotations_ids = self.coco.getAnnIds(imgIds=idx, iscrowd=False)
if not len(annotations_ids) == 0:
self.imgIds.append(idx)
# 추가: 이미지 전처리 파이프라인 정의
self.preprocess = transforms.Compose([
transforms.Resize((256, 256)), # 이미지 크기 조절 25
transforms.ToTensor(), # 이미지를 텐서로 변환
transforms.Normalize(mean=[0.5, 0.5, 0.5],
std=[0.1, 0.1, 0.1]), # 이미지 정규화
])
# 추가: 최대 바운딩 박스 개수 설정
self.max_num_boxes = 20
def __getitem__(self, index): # 인덱스에 접근할 때 호출
imageId = self.imgIds[index]
# ----------------------
annIds = self.coco.getAnnIds(imgIds = imageId, catIds=self.catIds)
anns = self.coco.loadAnns(annIds)
bboxes = []
for ann in anns:
bbox = np.array(ann['bbox'])
bboxes.append(bbox)
bboxes = np.array(bboxes)
# 추가: 모든 바운딩 박스를 동일한 크기로 조정 (예: [8, 4] -> [8, 4])
padded_bboxes = np.zeros((self.max_num_boxes, 4), dtype=np.float32)
padded_bboxes[:bboxes.shape[0], :] = bboxes
# ----------------------
imageId = self.imgIds[index]
imageInfo = self.coco.loadImgs(imageId)[0]
with open(os.path.join(self.root, imageInfo['file_name']), 'rb') as f:
img = Image.open(f).convert('RGB')
# 추가: 전처리를 적용하여 이미지 크기 통일
img = self.preprocess(img)
return img, padded_bboxes
def __len__(self):
return len(self.imgIds)Dataloader 정의
import torch
batch_size = 4
cocotrainset = MyCocoDataset('./train')
cocotrainloader = torch.utils.data.DataLoader(cocotrainset, batch_size=batch_size,shuffle="True")
overfitting-underfitting
먼저, CIFAR-10 데이터셋을 로드하고 간단한 CNN 모델을 정의한 다음, 이 모델이 overfitting되도록 설정하겠습니다. 다음은 overfitting을 유발하는 주요 요인입니다:
1) 모델 복잡성을 높입니다.
2) 훈련 데이터를 적게 사용합니다.
3) 과도한 에포크로 훈련합니다.
아래는 이러한 요소들을 활용하여 overfitting이 발생하는 코드 예제입니다:
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.optim as optim
# 데이터 전처리 및 로드
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
batch_size = 4
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size,
shuffle=True, num_workers=2)
# 모델 정의 (복잡한 모델)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 5)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = x.view(-1, 32 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
# 손실 함수 및 옵티마이저 설정
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# 모델 훈련
for epoch in range(100): # 과도한 에포크 설정
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch {epoch + 1}, Loss: {running_loss / len(trainloader)}')
print('Finished Training')
위 코드는 모델을 복잡하게 만들고, 데이터셋의 일부만 사용하고, 과도한 에포크로 훈련하여 overfitting을 유발하는 예제입니다. Overfitting을 감지하려면 검증 데이터셋과 early stopping과 같은 정규화 기법을 활용해야 합니다.
