이전 글 에 이어지는 글 입니다.
Data-intensive(데이터 집약적) 어플리케이션의 요구사항 중 신뢰성, 확장성, 유지보수성 중 저번 글에서 다룬 신뢰성에 이어서 Scalability(신뢰성), Maintainability(유지보수성) 을 다뤄보겠습니다.
Scalability(확장성)
확장성은 load 가 증가하여도 좋은 퍼포먼스를 유지할 수 있는 방안을 갖고 있음을 의미합니다. scalability를 논하기 위해서는 우선 load와 퍼포먼스를 어떻게 측정하고 산정할지 정해야합니다.
load
로드를 논하기 위해서는 어떤 수치를 기준으로 로드를 설명할 것인지 기준이 될 수치를 선택해야합니다. 해당 수치는 어떤 시스템 구조를 갖고 있냐에 따라 달라집니다.
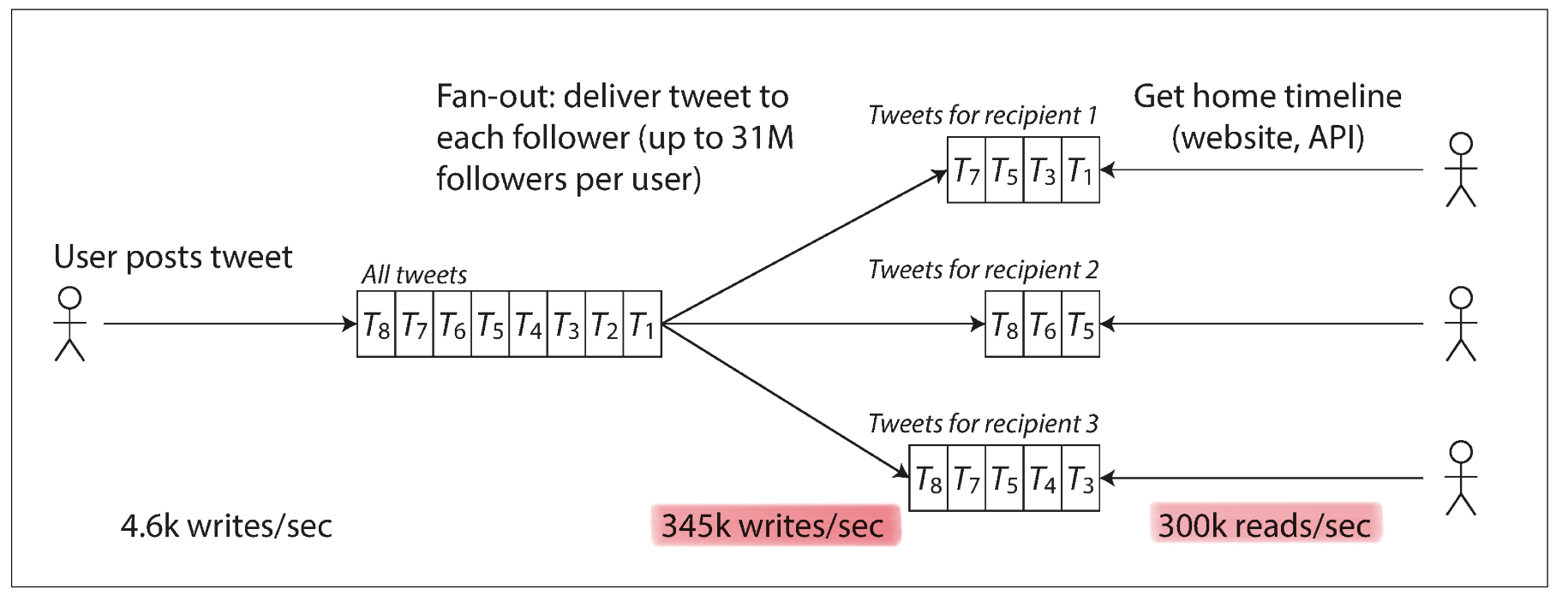
트위터를 예시로 보겠습니다. 트위터에서는 초당 4600여개의 트윗을 작성하는 request 가 발생하며, 유저가 타임라인 홈을 request하는 것이 초당 300,000 request가 발생합니다. 트위터는 두 개의 아키텍처 구조가 있었는데 이에 따른 load를 산정하는 수치도 달라집니다.
1번 방안.
follew table, user table, tweets table 을 구성하여 유저가 홈에 들어왔을 때 해당 유저아이디가 팔로워로 등록되어 있는 테이블을 다 조회한 다음, 해당 테이블에 연결된 유저들을 유저 테이블을 다 찾은 뒤 트윗 테이블에서 해당 유저의 트윗들을 가져가서 홈으로 접속한 유저의 타임라인에 제공한다.
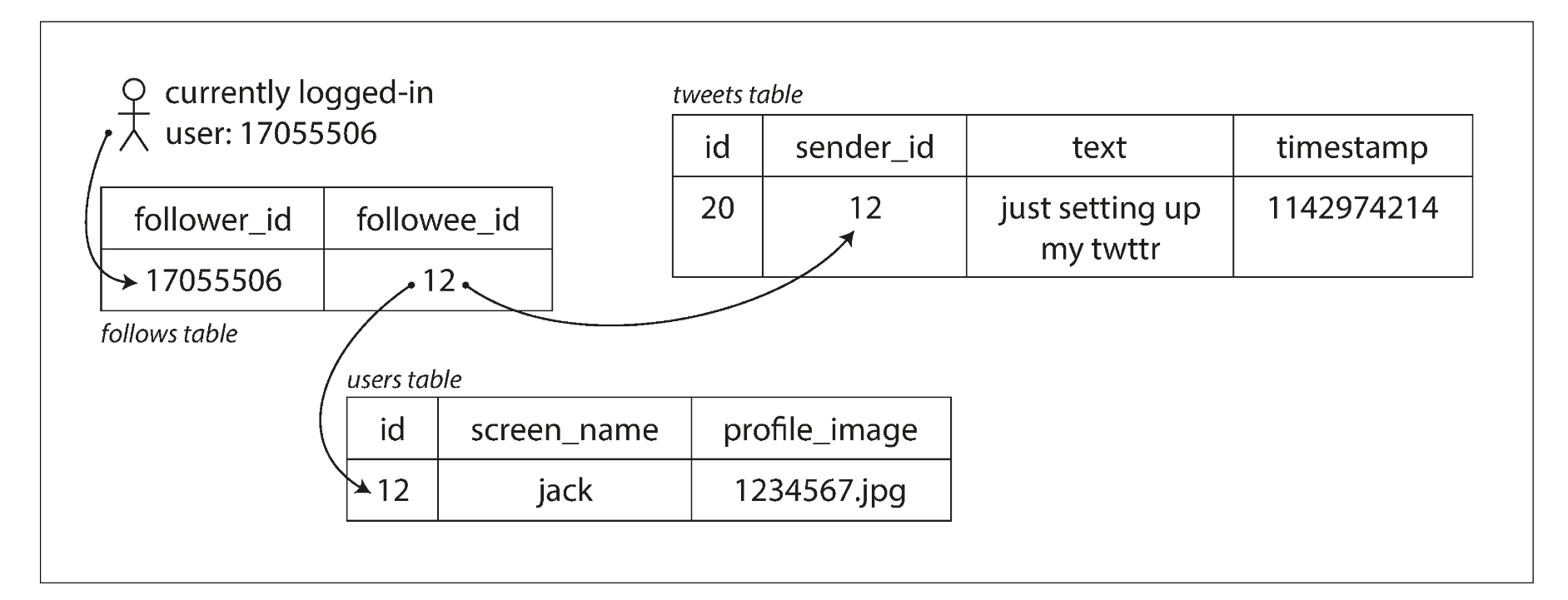
SELECT tweets.*, users.* FROM tweets
JOIN users ON tweets.sender_id = users.id JOIN follows ON follows.followee_id = users.id
WHERE follows.follower_id = current_user초당 30만의 reqeust 를 감당하면서 request 마다 table 세개를 순회하는 load 를 감당하기 위해 트위터는 2번 방안을 도입힌다.
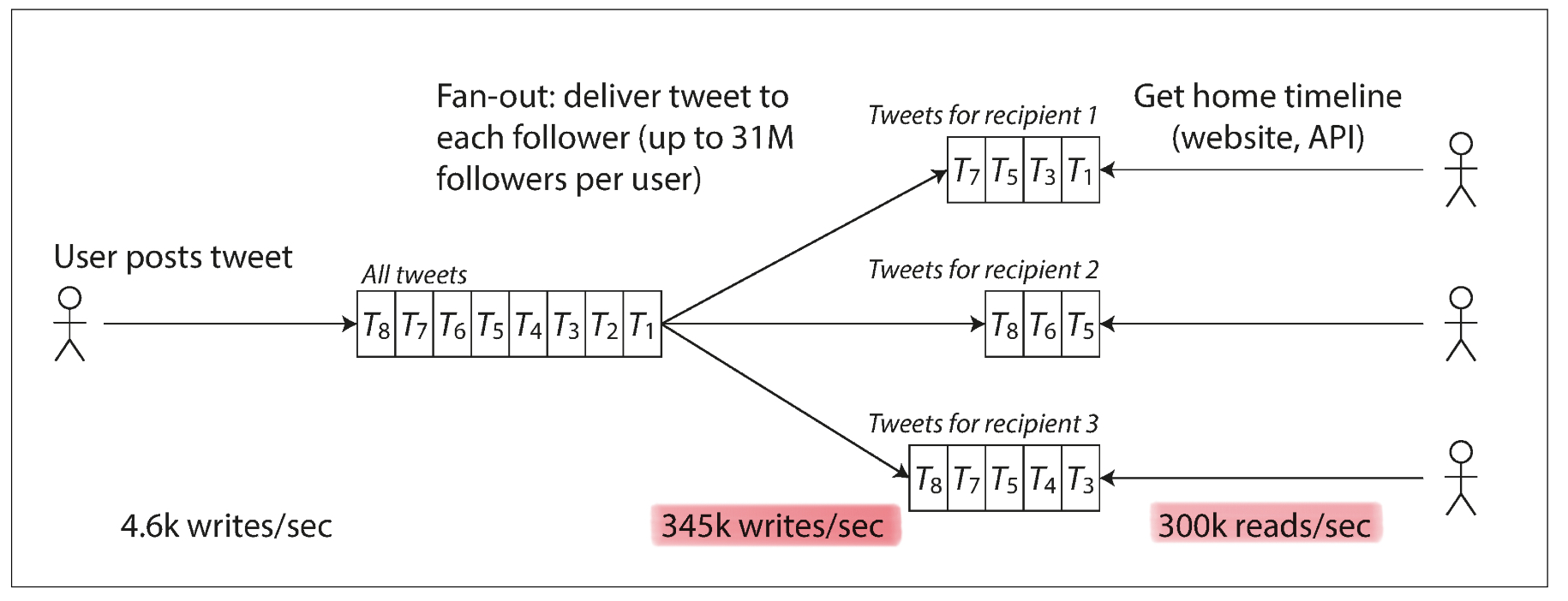
2번 방안. 두 번째 방식은 유저가 tweet 을 작성하는 경우 해당 tweet을 팔로우하고 잇는 유저의 타임라인에 넣어주는 것 입니다. 첫 번째 방식과의 차이는 write를 할 때 첫 번째와는 달리 각 팔로우하고 있는 유저의 타임라인에 작성한 트윗을 다 write 작업을 해줌으로서 write 작업에 있어서 더 많은 부담을 지게 됩니다. 그럼에도 불구하고 2번 방식으로 전환한 이유는 트위터 입장에서 가장 부담스러운 것은 초당 발생하는 타임라인 홈으로 접속하여 request 이기 때문입니다. 1번 방식으로 인한 load가 심하기 때문에 2번방식으로 write에 부담은 더 생기지만 가장 부담스러웠던 timeline request의 부담을 덜어주는 방식입니다. 1번방식처럼 테이블 세개를 순회하며 데이터를 다 search할 필요 없이 작성시에 각 유저의 타임라인에 이미 write을 해주었기에 read에서의 load을 줄일 수 있었죠. 허나 이 방식 또한 문제가 존재합니다.
만일 저스틴 비버가 트윗을 한 번 작성하게 될 경우, 팔로워가 1억명을 넘어가기에 1억명이 넘는 타임라인에 해당 트윗을 넣어줘야합니다.. 그렇기에 트위터에서는 두개를 결합한 하이브리드 방식으로 접근한다고 합니다.
1번 방식에서는 timeline request가 주요한 load를 산정하는 기준이며, 2번 방식에서는 write reqeust가 load의 기준이 되는 수치입니다.
Scalability , 즉 확장성을 논하는 방식은 "load 가 증가할 때 어떻게 좋은 퍼포먼스를 유지할 수 있을까?"였습니다.
트위터에 이를 적용해보자면, 1번 방식에서는 timeline read request가 증가해도 어떻게 좋은 퍼포먼스를 유지할 수 있을까? 이며 2번 방식에서는 write request가 증가해도 어떻게 좋은 퍼포먼스를 유지할 수 있을까가 트위터에서 확장성을 논의할 때 논의되는 주제인 것 이죠.
Performance
퍼포먼스 또한 수치로 산정됩니다. 퍼포먼스 또한 어떤 프로그램이냐에 따라 그 기준치가 달라지죠. 온라인 웹이라면 client가 request를 보낸 후 response 를 받게 되는 response time 이 퍼포먼스의 기준이 될 것 이며 특정 작업들을 처리하는 서버 프로그램이라면 throughput 이 중요할 것 입니다.
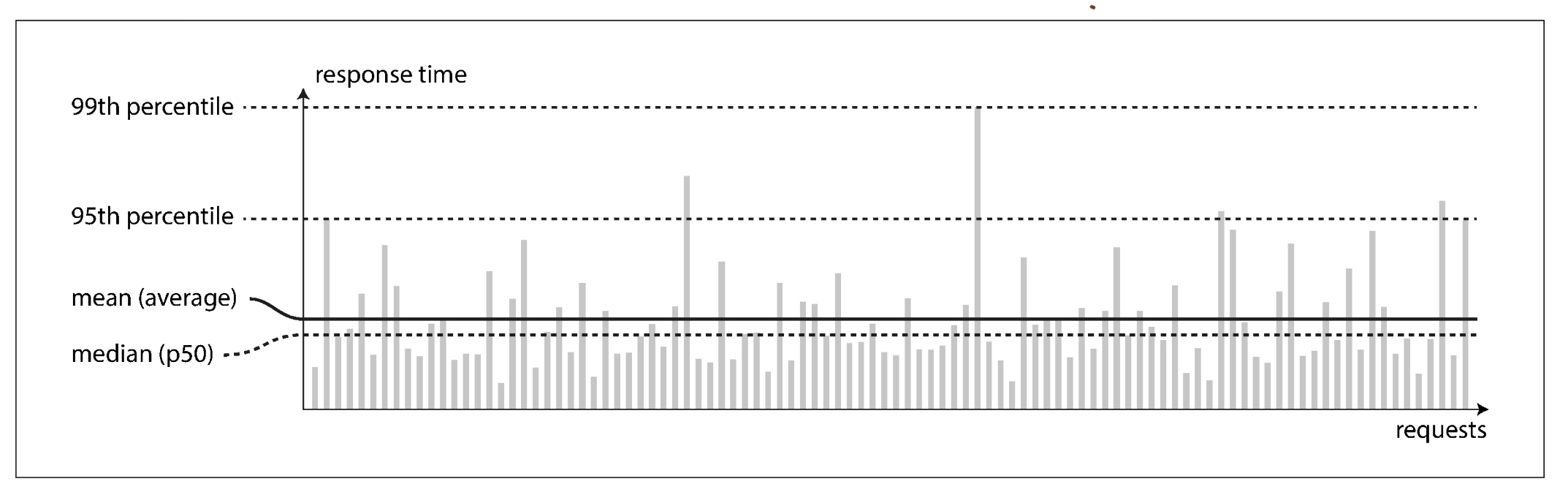
허나 이 수치는 실행할 때마다 차이가 발생합니다. 네트워크 패킷 손실과 TCP 재전송, 가비지 컬렉터로 인해서, 페이지 폴트 등등 매번 차이가 발생하기에 어떤걸 기준으로 잡을지 문제가 생기는거죠. request에 따른 response time을 측정할 때 보통 response time을 정렬해서 상위 95퍼센트, 99퍼센트를 기준으로 언제 response가 도착하는지를 측정합니다. 50퍼센트를 기준으로 한 시간은 절반은 그보다 짧지만 절반은 그보다 오랜 시간이 걸린다는 것이기에 의미있는 수치라고 볼 수 없습니다. 해당 시간보다 얼마나 오래 걸릴지도 모르는 response들이 절반이나 된다는 것이기 때문이죠. 아마존에서는 response time이 100ms 지연될 때 sales 1% 줄어들고 소비자 만족도는 16%가 감소한다고 합니다. 세일즈의 1퍼센트의 기준 단위가 무엇인지는 모르겠지만 아마존의 규모를 생각하면 100ms 가 엄청난 차이를 발생시키는걸 알 수 있습니다.
확장성을 논의하기 위한 load와 performace의 개념을 알아보았으니 그럼 load가 증가할 때 performace을 유지하기 위해 어떻게 대응 할 수 있을까요?
Approaches for Coping with Load
1) Scaling-Up : 하드웨어 사양을 올려 해당 load를 감당할 수 있게 함
2) Scaling-Out : 여러 하드웨어를 사용하여 분산함으로서 해당 load를 처리함
두 가지 방법의 있는데 현실에서는 역시나..!! 둘 다 사용합니다. 첫 번째 하드웨어 사양을 높이는 방식은 직관적이고 간단해보이지만 특정 사양을 넘어서면 비용이 상당히 비싸지며 가장 좋은 하드웨어도 결국은 한계가 있기에 Scaling-out으로 병행하여 이용합니다.
Maintainability(유지보수성)
유지보수를 위한 세가지 운용성(Operability), 단순성(Simlicity), 발전성(Evolvability)이 있지만 유지보수성의 본질은 sw엔지니어링과 시스템 운영팀의 일을 개선시켜주는 것에 있습니다.
유지보수를 위한 설계 원칙 세 가지를 살펴보겠습니다.
-
Operability
시스템 운영을 쉽게 만들며 다음과 같은 경우에 좋은 Operability를 갖추었다고 말합니다.
- 좋은 모니터링 시스템과 bad state에 빠졌을 때 빠르게 회복이 가능한지
- 시스템에 장애를 이르키거나 성능을 저하하는 요인을 빠르게 파악할 수 있는지
- 각 시스템들이 주고 받는 영향을 추적하고 문제가 발생하기 전에 이를 파악 할 수 있는지
- 예측 가능한 동작 및 예상치 못한 상황 최소화
- 좋은 문서와 이해가능한 쉬운 운영 시스템
- 높은 가시성ㄴ 등등.. 주로 사람의 노동력의 투입을 줄이면서 시스템 운용력을 높이는지와 관련있다.
-
Simplicity(단순성)
시스템이 복잡하면 유지보수가 힘들어지고 시스템에 변화가 생길 때 버그가 발생할 리스크가 높아집니다. 단순성을 위해서는 추상화를 이용해서 깔끔하고 직관적인 구현을 해야합니다. 예시로는 프로그래밍 언어들 또한 머신레벨의 코드, 시스템콜, cpu 레지스터 등을 추상화해서 사용할 수 있게 해놓은 대표적인 케이스입니다. SQL 또한 디스크와 메모리 구조, 동시성 처리등을 추상화를 통해 잘 구현해놓은 사례입니다. -
발전성(Evolvability)
시스템은 끊임 없기 변하게 되는데 이럴 때 유연하게 변화하고 발전할 수 있어야함을 말합니다. 조직적으로는 변화에 유연하게 대처하기 위해 애자일 작업 패턴을 이용합니다.
결국 데이터 집약적인 서비스를 위해서는 Reliability(신뢰성), Scalability(확장성), Maintainability(유지보수성) 을 신경써야함!
이번 글에서는 확장성 다루는 방법, 그에 따른 load와 performance를 알아보았고 유지보수성에 대해 알아보았습니다.
다음 글의 주제는 Data Models and Query Language 입니다.
