
Kafka 소개에 대한 짧은 영상을 보시면 카프카를 보다 더 쉽게 이해하실 수 있습니다. 본 시리즈는 Kafka 공식문서와 인프런 무료강의, Apache Kafka 101을 참고하여 한 내용입니다.
앞선 포스트에서 Kafka가 Event Streamig Data를 타겟으로 삼는다고 서술했습니다. 이제부터는 Kafka의 용어를 설명하며 시리즈를 이어갑니다. 본 포스팅에서는 Kafka의 서버와 클라이언트, 토픽에 대해 알아봅니다.
한국어로 바꾸는 것보다 영어 단어로 아는 것이 나을 경우, 번역하지 않고 용어 그대로 이용하겠습니다.
1. 서버와 클라이언트
in a nutshell : 간단히
- Kafka는 서버와 클라이언트 사이 TCP network protocol 을 이용해서 빠른 커뮤니케이션이 이루어진다.
- 실제 기기에서 이루어질 수도 있고, 가상 머신에서도 이루어질 수 있으며, 클라우드 환경에서도 이루어질 수 있다.
1) 서버 (Broker)
- Kafka는 하나 이상의 클러스터로 이루어져 수십 개의 데이터 센터와 클라우드를 이을 수 있다.
- Storage layer의 서버들은 "Broker"라고 불린다.
- Kafka는 여러 데이터 서버들이 이어질 수 있게끔 Scalable한 구조를 지원한다.
- 한 서버가 기능을 제대로 수행하지 못할 경우, 혹은 데이터가 손실될 경우 다른 서버가 그 역할을 맡는다.
2) 클라이언트 (Producer, Consumer)
- 데이터를 수집, 소비하는 대상
- 병행(Parallel)으로, 그리고 확장(scalable)하여, 네트워크 실패나 기기의 결함과 같은 fault를 tolerant할 수 있다.
- 자바, 스칼라, 카프카 스트림 라이브러리, 고 등의 언어를 지원한다.
3) Kafka의 데이터 구조
- Kafka의 데이터는 Key와 Value로 이루어져 있다.
- Kafka는 Serialized, Deserealized 한 데이터를 다룬다.
- 보통 JSON 형태로 데이터를 받아들여 나눈다.
- Kafka는 Key의 값이 unique하다기 보다는, 병렬화와 데이터의 위치 등을 결정하는 요소로 사용된다.
2. Kafka Topic
1) Topic
- 비슷한 이벤트로 부터 발생한 Named Container
- 시스템들은 많은 Topic들을 가지고 있다.
- Topic들 간의 데이터는 중복될 수 있다.
- 토픽이 파일시스템 안의 폴더라면, 이벤트는 폴더 안의 파일이다.
- 이벤트에서 지속보관가능한 로그들
- Topic을 큐라고 부르는 경우도 있으나. 토픽은 쌓이는 모양이 큐와 비슷하다고 하더라도, 큐보다는 지속보관가능한 로그라고 생각해야한다.
- 로그는 이해할 수 있는 의미있는 데이터(semantic data)로 구성되어있다.
- 로그는 인덱스화되는 것이 아니라 offset으로 찾는다.
- Event는 한 번 발생하면 발생을 무를 수 없다. (immutable)
- Event는 한 번 발생하면 발생을 무를 수는 없다고 해서 중복 가능하다.
- Durable: 로그를 얼마나 보관할 수 있을지(유지기간)에 관해 설정할 수 있다.
큐는 데이터가 output되면 사라지지만, kafka는 로그들의 집합으로서 output되어도 보존기간 내에서는 사라지지 않는다.
- 각 파일들은 Disk에 저장된다.
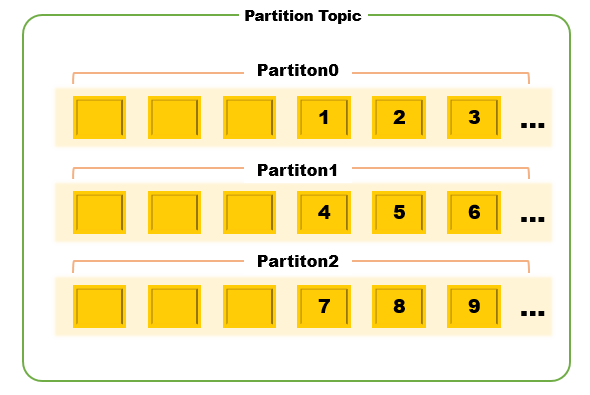
2) Kafka의 Topic은 어떻게 Partitioning을 하는가.
- Kafka는 분산 시스템을 기반으로 한다.
- Kafka에서 Partitioning은 하나의 Topic을 여러 개의 Topic으로 나누는 것을 의미한다. (Bucket)
- 메시지가 주어졌을 때 어떤 Partition으로 보내야할지에 관해 결정이 필요하다
- 키를 가지고 있는 메시지라면? 보통 Key를 기반으로 나누지만, Key가 빈(null) 경우 라운드 로빈 방식으로 각 Partition에 배정된다
- 키를 가지고 있지않은 메시지라면? 해쉬를 이용하여 키를 임의로 만들어 Partitioning 한다.
Partition 개수를 가지고
mod를 써주어 Partitioning 해준다.
- Kafka의 강점은 메시지가 같은 키를 가지게 하여 순서를 보장할 수 있게 만들 수 있다는 것이다
- 예를 들어 key를 Customer ID로 결정한다고 한다면, Customer ID별로 Partition에 같이 보관할 수 있다.
- Key는 Partitioning의 기준이 되기 때문에 메시지의 Key를 어떻게 정하는지도 Kafka의 중요 고려요소다.
- Kafka는 Fault-tolerant를 위해서 토픽을 중복하여 복사한다.

담대하게 도전하고 기꺼이 실패를 받아들이는 개발자