
Kafka 소개에 대한 짧은 영상을 보시면 카프카를 보다 더 쉽게 이해하실 수 있습니다. 본 시리즈는 Kafka 공식문서와 인프런 무료강의, Apache Kafka 101을 참고하여 한 내용입니다.
앞선 포스트에서 Kafka의 서버와 클라이언트, 토픽에 대해 알아보았습니다. Kafka의 구조(구성)에는 Producer, Broker, Consumer가 있고 특징을 간단히 서술합니다. 실습 내용을 차근차근 업로드 하겠습니다.
0. 들어가기에 앞서...
🔊 카프카의 데이터 구조를 이해하기 위해서는 카프카를 구성하는 요소에 대한 이해가 필요합니다. 구조가 어떻게 이루어져있는지를 떠올릴 수 있으면 좋을 것 같습니다.
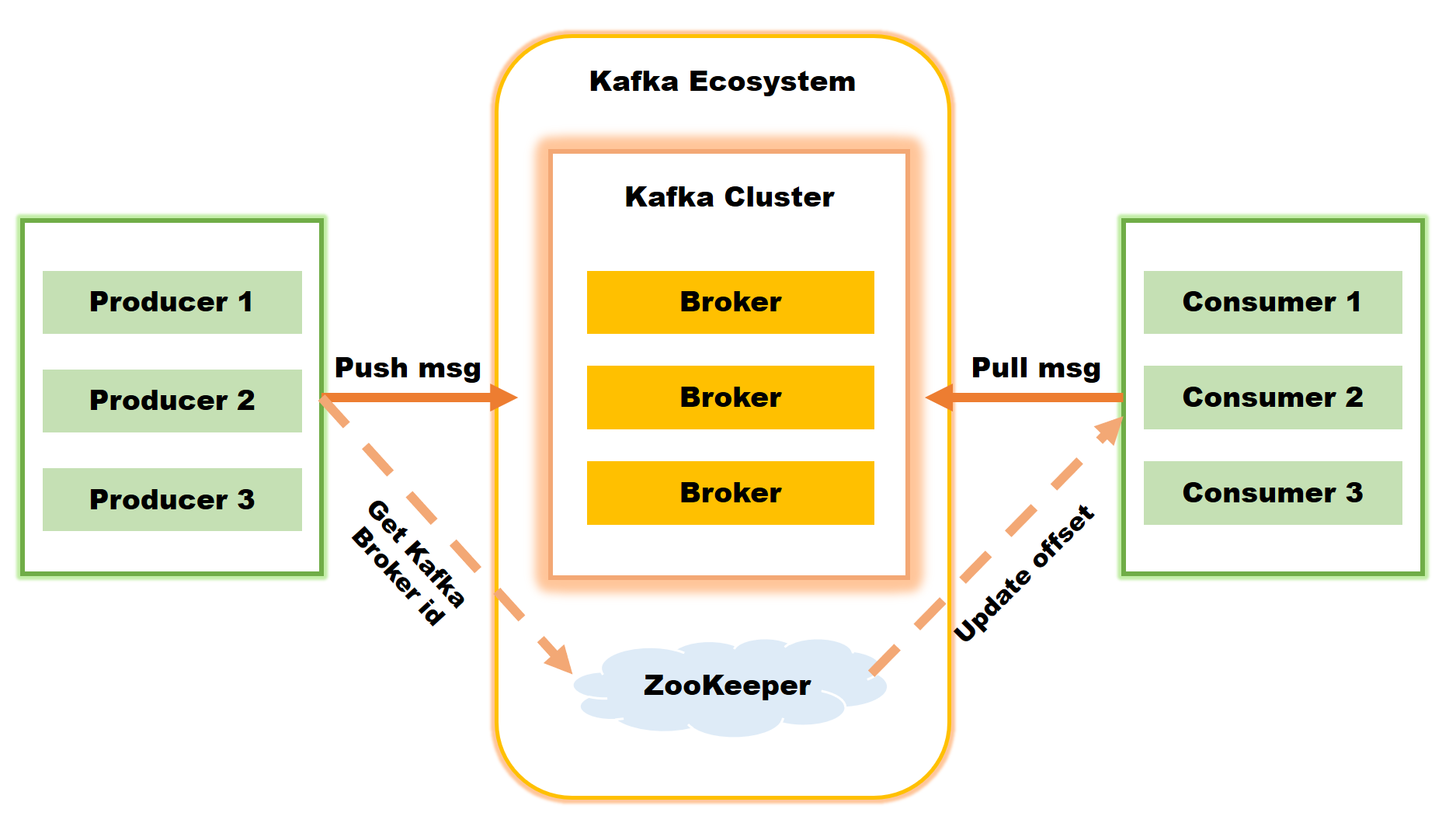
- 프로듀서: 데이터를 수집
- 브로커: 데이터를 저장
- 컨슈머: 데이터를 가져감
- 커밋을 통해서 어떤 데이터를 가져갔는지를 기록한다.
- 데이터를 가져가더라도 브로커에 저장된 데이터는 삭제되지 않는다.
1. Broker
- Kafka는 분산 시스템이다.
- Broker는 Kafka의 프로세스를 운영하는 컨테이너 또는 인스턴스, 컴퓨터이다.
- 독립된 machine(기기)로 브로커 process(=partitions)를 운영한다.
- Partition을 관리하고 Partition의 복제를 관리한다.
- 간단한 디자인을 가지고 있기 때문에 Scalable에 유용하다.
- 3 대 이상의 브로커 서버를 하나의 클러스터로 묶어서 운영한다.
Broker의 역할에 대해 알아봅시다.
1) 컨트롤러, 데이터 삭제
- 클러스터에는 다수의 Broker가 존재한다.
- 하나의 Broker에는 다수의 Partiton이 존재한다.
- 이 때, 클러스터의 하나의 Broker는 자신이 속한 클러스터를 관리하는 컨트롤러 역할을 한다.
- 컨트롤러 역할을 하는 브로커에 장애가 생기면 다른 브로커가 그 역할을 대신한다.
- 카프카는 파일 시스템에 데이터를 저장하기 때문에 컨슈머가 데이터를 소비하더라도 데이터를 삭제하지 않는다는 특징이 있다.
- 오직 브로커만이 데이터를 삭제할 수 있고, 데이터 삭제는 파일단위로 이루어지며 이 단위를
Log segment라고 한다.
- 특정 데이터를 선별해서 삭제하는 것은 불가능하다. (= 로그 세그먼트 안에는 다수의 데이터가 하나의 파일 단위로 묶여져 있기 때문에 선택하여 데이터를 삭제하는 것이 불가능하다)
2) 컨슈머 오프셋 저장, 코디네이터
- 컨슈머는 데이터를 어디까지 가져갔는지를 확인하기 위한 용도로
offset을 사용한다.
- 커밋한
offset은__consumer_offsets라는 토픽에 저장되어 관리된다.토픽은 브로커의 파티션들의 집합이라고 볼 수 있습니다..
consumer commit을 관리하는 브로커가 따로 존재한다는 뜻입니다.
3) 그룹 코디네이터
- 컨슈머 그룹의 상태를 체크하고 파티션을 컨슈머와 매칭되도록 분배
- Rebalance: 일대일 매핑이 되지 않으면 매칭되지 않은 파티션을 정상 동작하는 컨슈머와 매핑하여 끊임없이 데이터 처리가 가능하도록 도와준다.
4) 데이터의 저장
- 카프카의 브로커에는 데이터가 실제적으로 저장된다.
- 데이터는 파일시스템에 저장되지만, 빠른 처리를 위해 한 번 읽혀진 데이터를 캐시메모리에 저장하여 빠른 접근을 허용한다./
2. Replication
- fault tolerance를 위한 데이터 복사본이다.
- 하나의 lead partition과 N-1개의 followers이 있다.
- 모든 Partition은 하나의 리더를 가지고 있으며 다른 클러스터로 복사된다.
- 데이터를 쓰거나 읽을 때마다, 리더가 생겨난다.
- 리더가 생기고, 팔로워가 생기는 것은 개발자가 알지 않아도 되는 invisible process 이다. (자동화된 과정)
- Producer 내에서 Replication을 설정할 수도 있다.
3. ZooKeeper
- 카프카 클러스터 실행을 담당하며 관리한다.
root znode에 각 클러스터별znode를 생성하고 클러스터 실행시root가 아닌znode로 설정한다.
- 카프카 3.0 부터는 ZooKeeper 없이도 클러스터 동작이 가능하다.
여기서부터는 Client 단계입니다. Client는 Producer, Consumer 가 있으며 실제 프로그래밍을 작성하는 부분입니다. Producer, Consumer 중 하나가 두 개의 역할을 할 수도 있지만, 두 개로 구분하여 각 역할에 대해 서술하겠습니다.
4. Producer
Kafka에서는 Producer API를 이용하여 Producer 코딩이 가능하다.
- Client Application
- Java에서
KafkaProducer라는 클래스에서 클러스터를 연결할 수 있다.
- 메시지를 토픽에 넣고, 토픽의 어떤 파티션에 저장할지에 관해 설정할 수 있다.
ProducerRecord는 브로커에 저장되는Key,Value쌍을 어떻게 저장할지에 관해 설정할 수 있다.
- 네트워크 버퍼링을 어떤식으로 대처할 수 있을지에 관한 설정이 가능하다.
정리) Producer에서는 어떤 클러스터의, 어떤 토픽, 어떤 파티션에 데이터를 저장할지를 정할 수 있다. 또한, 네트워크 관련된 사항도 관리할 수 있다.
5. Consumer
Kafka에서는 Consumer API를 이용하여 Consumer 코딩이 가능하다.
- 클라이언트 애플리케이션이다.
- 토픽으로부터 메시지를 읽는다.
- Scale out이 가능하다.
- 파티션의 순서를 보장한다.
