💡10장 목표
- Demand paging
- Page replacement
- FIFO, optimal, LRU
- Working set of process
- OS별 Virtual memory
physical memory 공간(메인 메모리 공간)은 시스템 별로 존재
virtual memory 공간(논리 메모리 공간)은 프로세스마다 존재
→ 즉, 물리 메모리 공간은 부족하다. 그래서 각 프로세스마다 가상 메모리 공간을 가지고, 필요할 때만 물리 메모리 공간을 사용한다.
Partially-loaded program
프로그램이 실행되기 위해서는 메모리에 코드가 로드되어야하는데, 전체 프로그램이 동시에 사용되는 경우가 드물다. 왜냐하면 프로그램 내에서 항상 필요하지 않은 코드들이 존재하기 때문이다.
- 프로그램은 일부만 로딩해도 수행할 수 있다(locality).
- 메모리 절약 가능
- CPU 사용률 증가
- I/O감소(프로그램을 메모리에 로드하거나 스와핑하는데 필요한 I/O 줄어듦)
Virtual Memory
- 프로세스마다 존재하는 가상 메모리 공간
- 이걸 한 개의 물리 메모리 공간에 매핑하는 것
- 프로그램의 일부만 메모리에 로드할 수 있게 해줌
- 물리 메모리 공간보다 훨씬 더 큼
- 여러 프로세스 간 주소 공간 공유 가능 (아래 설명)
- 프로세스 생성 쉬움
- 더 많은 프로그램 동시 실행 가능
- 프로세스 로드 및 스와핑이 줄어들어 해당 I/O 감소
추가적인 메모리가 필요할 때 virtual memory 구현 방법
- Demand Paging: 필요한 페이지만 메모리에 로드 (아래 설명)
- Demand Segmentation: 필요한 세그먼트만 로드
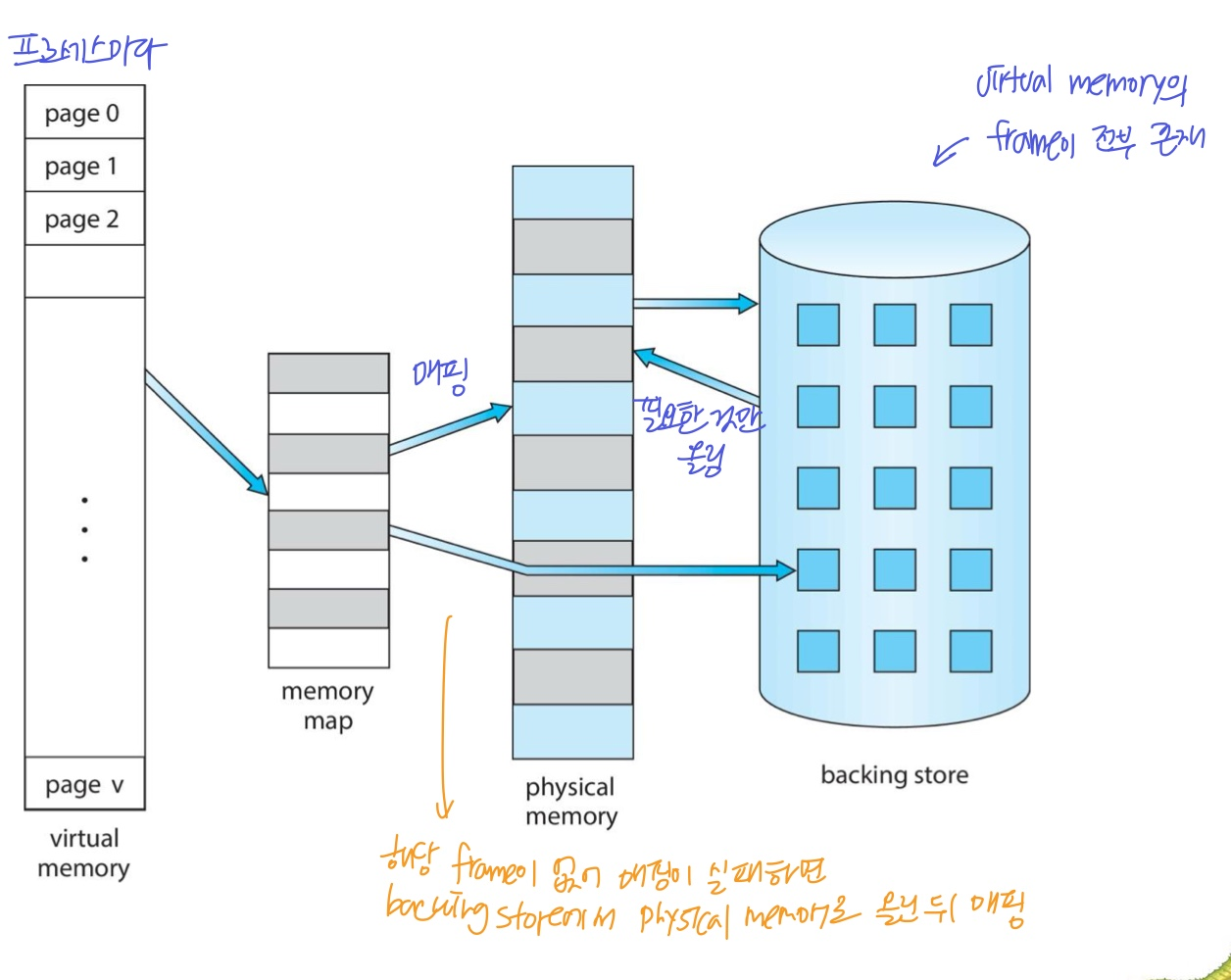
Virtual address space
- 프로세스가 메모리에 저장되는 logical view (논리 주소, 상대 주소)
- 프로세스의 입장에서는 연속적인 공간을 가진다고 생각한다.
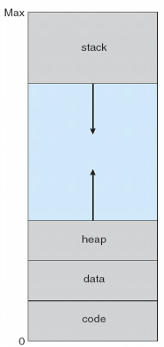
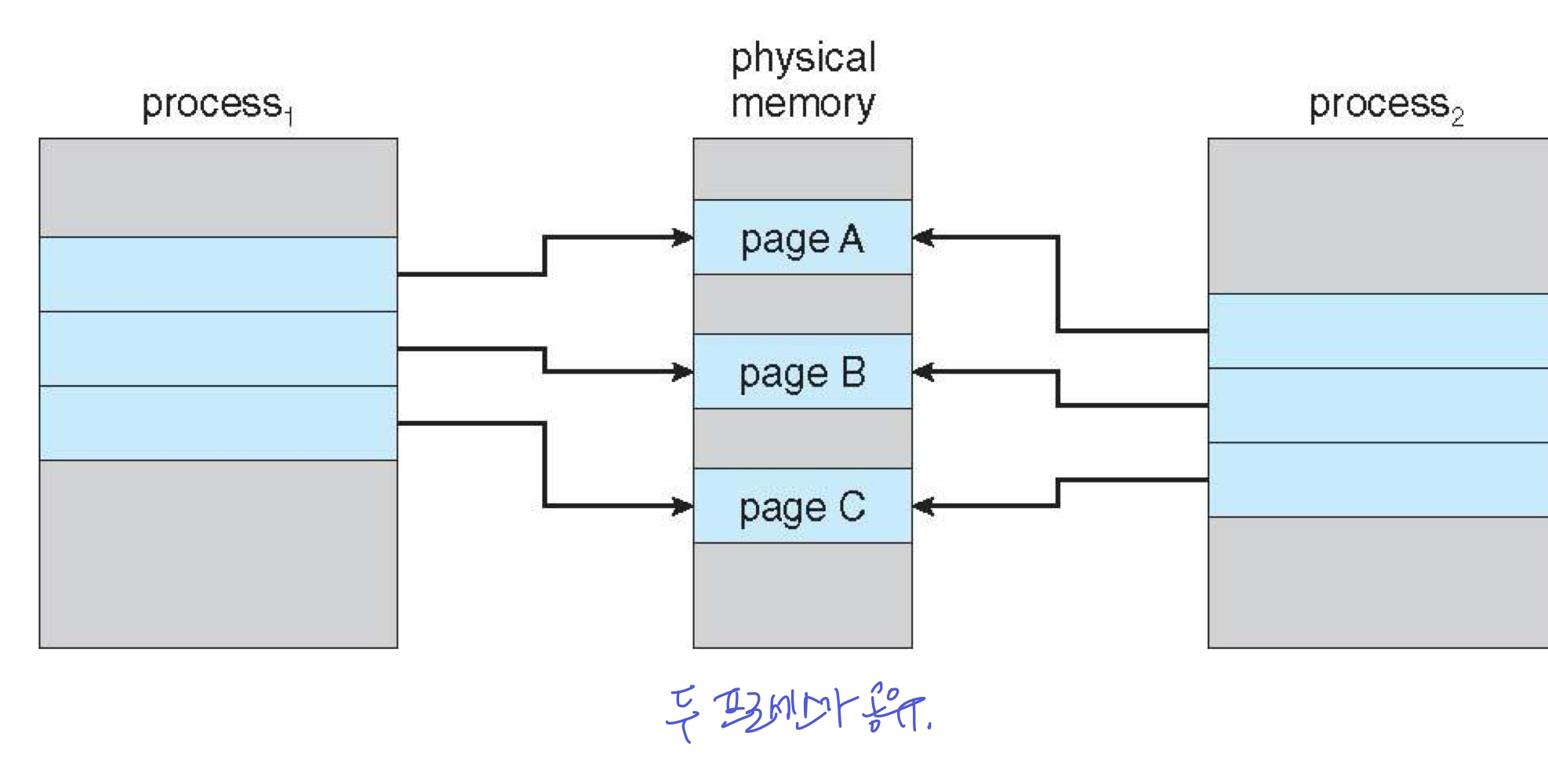
Shared Library
virtual memory를 사용하여 프로세스 간 주소 공간을 공유
- 여러 프로세스가 같은 라이브러리를 사용할 때, 가상 메모리는 공유할 수 있는 영역을 만들 수 있음
- 이 영역을 공유하는 프로세스들은 각자 자신의 논리 주소 상에 있는 것처럼 보이지만, 실제 물리 메모리에서는 같은 주소인 것이다. (같은 주소로 매핑)
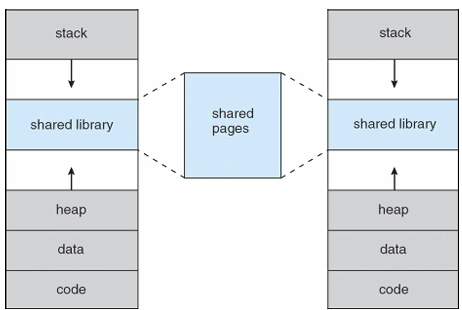
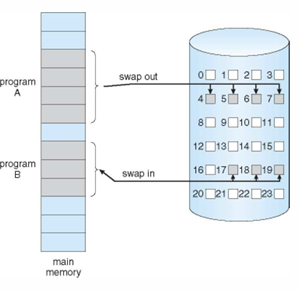
🔹Demand Paging
- 프로그램 B의 페이지가 물리 메모리에 없다면, 해당 페이지를 swap in
- swap in을 하기 위한 공간을 마련하기 위해서 프로그램 A는 swap out
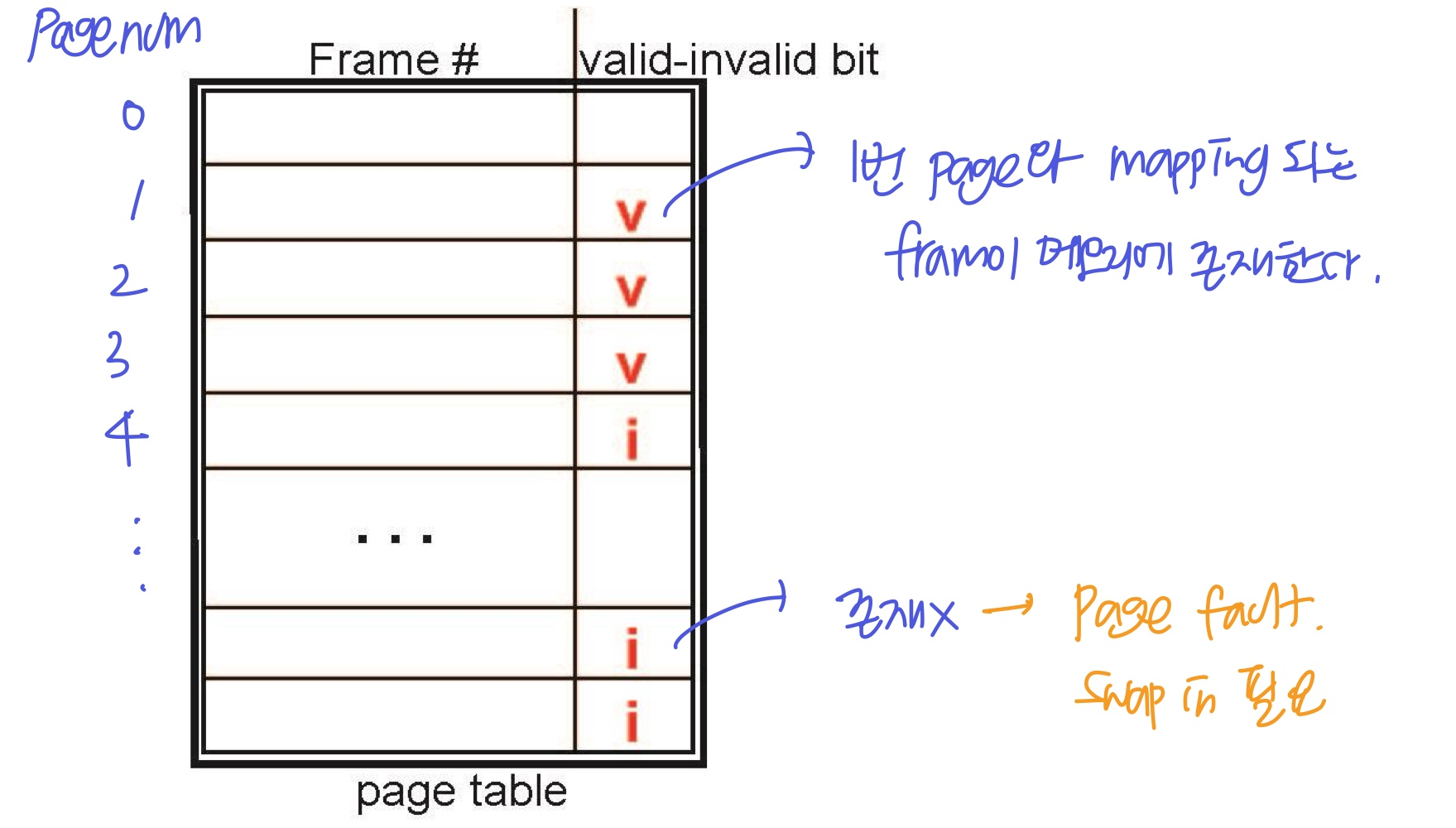
Page table의 Valid-Invalid Bit
demanding paging을 위해 MMU는 페이지가 유효한지 무효한지를 확인해야한다. 그래서 page table에 매핑될 frame 번호 뿐만 아니라, valid-Invalid bit도 가진다.
- Valid: 페이지가 이미 메모리에 있는 경우 (memory resident)
- Invalid: 페이지가 필요한데 메모리에 없는 경우 (Page fault) → 해당 페이지를 저장소에서 메모리로 로드(swap in)해야됨
- 또는, 자신의 영역이 아닌 페이지에 접근하는 경우 → 종료(abort)
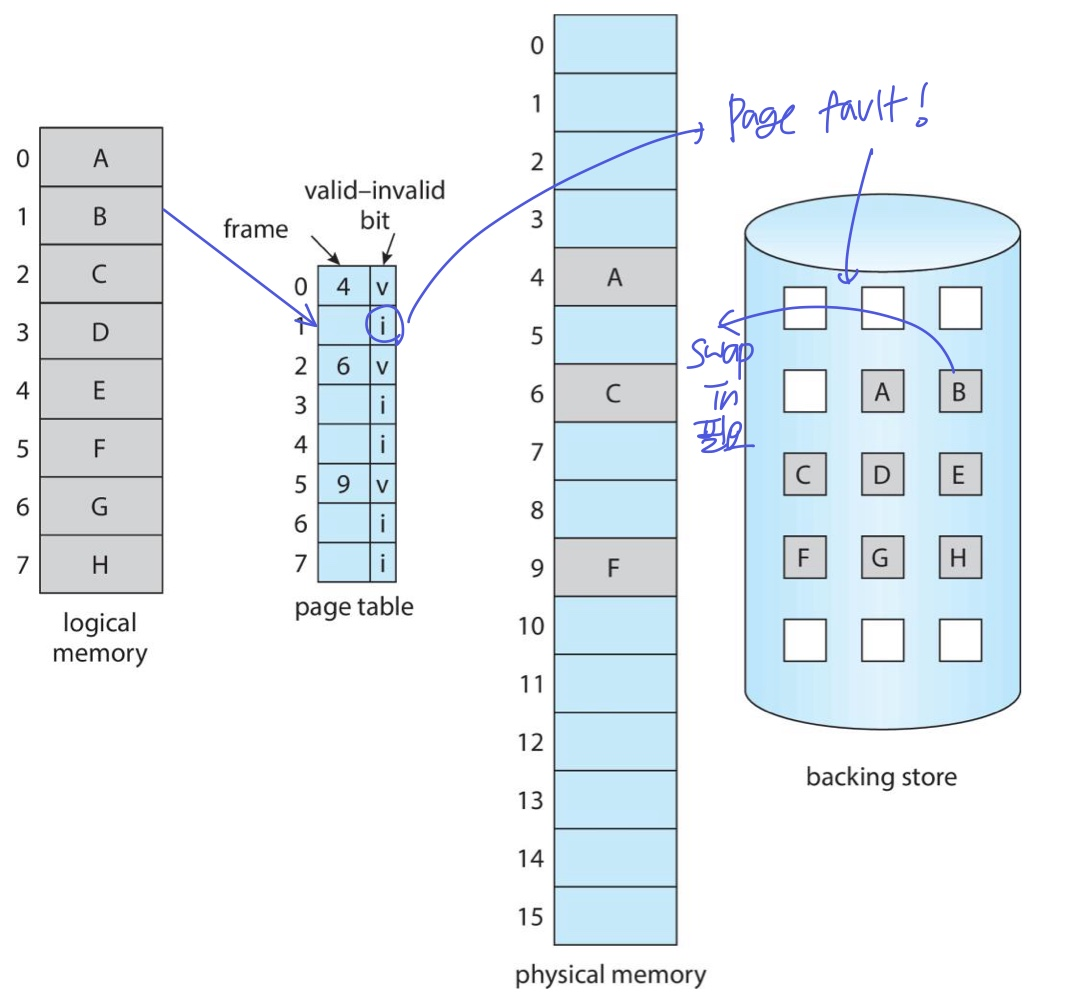
- 또는, 자신의 영역이 아닌 페이지에 접근하는 경우 → 종료(abort)
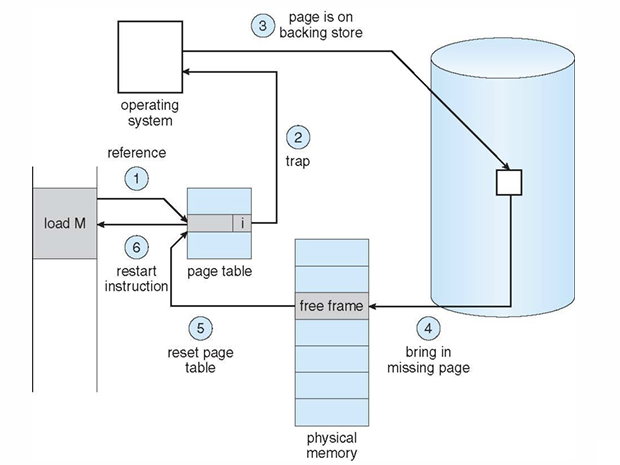
Handling Page fault
- Invalid하면 운영체제에 trap (일종의 Interrupt으로 page fault 발생시킴)
- 운영체제는 Context Save를 하고,
잘못된 영역으로 인한 Invalid면 종료
메모리에 없어 발생한 Invalid면 아래 과정 진행 - 물리 메모리 공간의 free frame을 찾기 (OS가 관리 중인 free frame List)
- 저장소에서 해당 페이지를 free frame으로 swap in
- 테이블 업데이트 (유효비트를 v로)
- Context Resume
그래서.. Page demanding은 메모리를 효율적으로 사용할 수 있지만 fault가 발생하면 꽤 큰 딜레이가 발생한다. page fault를 줄이는게 핵심
- 하지만 Locality 경향에 의해 page fault가 발생할 경우가 많지 않다. 웬만하면 hit (hit ratio가 높다)
- Locality: 사용한 부분을 집중적으로 사용하는 경향(재사용), 특정 부분에 오래 있는 경향
만약 한 Instruction이 여러 page에 걸쳐있다면? → 물리 메모리 상에서 다른 위치에 존재
- 여러 페이지 모두 로딩이 필요하다.
- 여러 페이지의 page fault가 발생할 수 있다.
Worse Case
만약 빈 공간이 없다면? … 쫓아내고(swap out), 가져오는(swap in) 과정에서 disk I/O가 2번… → demand paging에서 이런 최악의 경우는 아래와 같다.
- 한 프로세스에서 page fault 발생, OS trap
- 해당 프로세스 Context save
- interrupt가 page fault임을 확인
- disk의 페이지 유효성 확인 및 위치 결정
- free frame 요청
- 디스크 장치에 disk I/O 요청, 큐 기다림
- 디스크 장치가 free frame을 탐색하는 것 기다림
- 페이지를 free frame으로 전송
그리고 대기하는 동안 CPU가 놀지 않도록 다른 프로세스에게 할당해주려고 기다림
- disk I/O 작업이 완료되면 interrupt 받음
- 아까 놀지 않도록 다른 사용자에게 할당해줬다면 그것 또한 Context Save
- interrupt가 disk I/O 완료임을 확인
- 페이지 테이블 수정
- 다시 이 프로세스가 CPU할당 받기를 기다림
- 할당 받으면 Context resume
이처럼 page fault는 메모리, I/O, CPU scheduling 등 여러가지를 발생시킨다.
Performance
- Page fault rate 0≤p≤1
- p=0 → page fault 없음
- p=1 → 항상 page fault
- 보통 p=0.1, 0.01 정도
- EAT = (1-p) x memorry access + p x (page fault over head + swap page out + swap page in)
- 앞에 항은 fault 없을 때, 뒤에 항은 fault 있을 때
- 뒤에 항에서는 page fault interrupt와 table update 등의 시간과 빈 공간이 없는 경우의 swap out/in을 포함
- example
- 메모리 접근 시간: 200ns, 평균 page fault 서비스 시간: 8ms
- ETA = (1-p)200 + p8000000
Optimization
- Large chunks: swap 공간이 page단위로 흩어져 있으면 관리가 힘드므로, 모여있는 넓은 공간 제공
- 페이지를 디스크의 프로그램 binary에서 요구
- binary는 read only instruction으로, 프로그램 코드가 실행 중에 변경되지 않는다.
- read only는 swap공간에 저장되지 않는다. swaping의 대상이 아니다.
- 필요한 페이지가 메모리에 없으면 swap공간이 아닌 디스크에서 excutable 파일을 직접 가져옴
모바일 시스템은 swap 지원X, 부족하면 종료, 애플리케이션의 진행 상태의 일부 저장
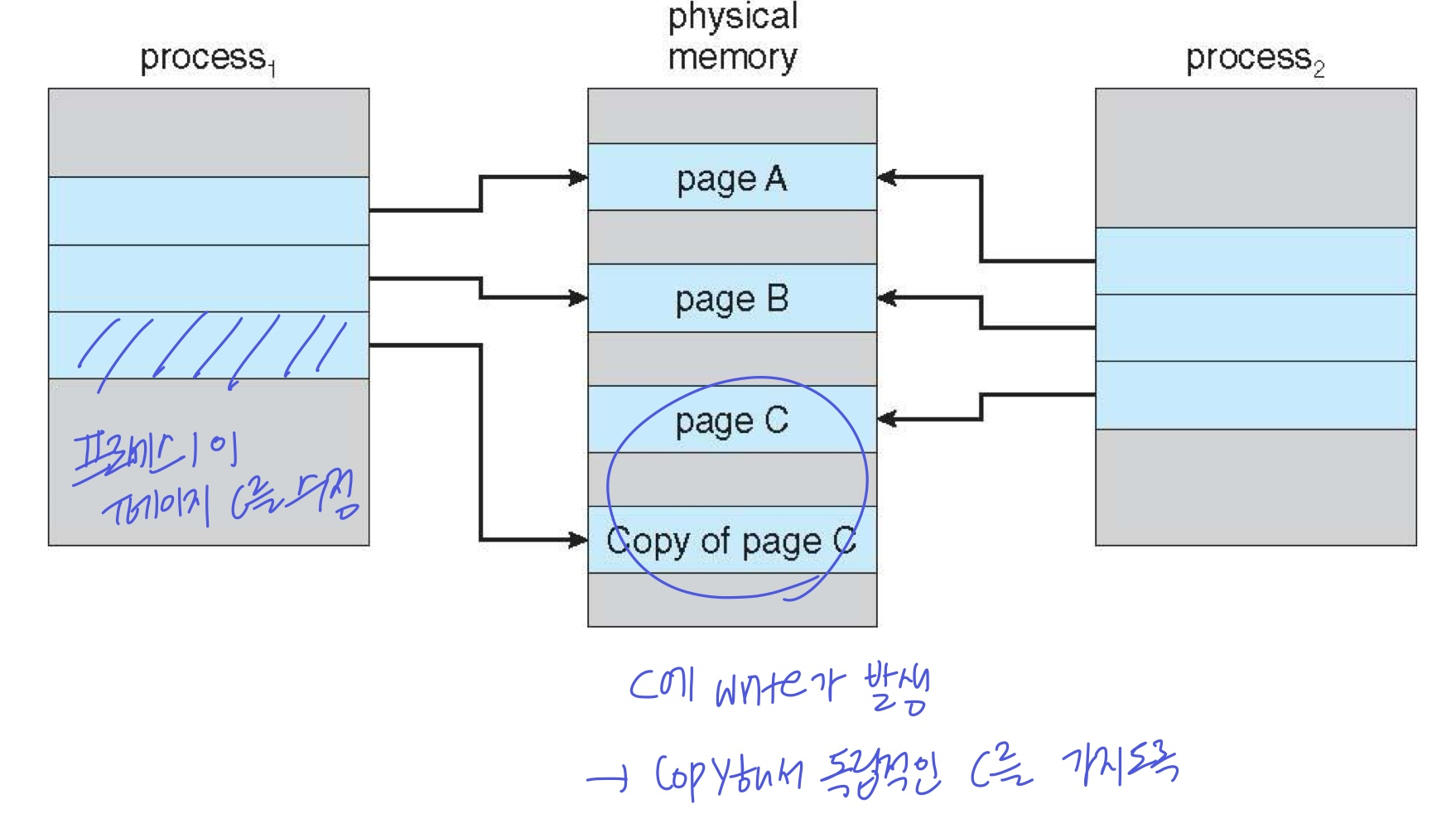
🔹Copy-on-Write
부모 프로세스가 fork하여 자식 프로세스를 만들 때, copy가 일어난다. 하지만 copy는 느리다!
- copy하기 전에 먼저 공유하고, 두 프로세스가 달라지는 부분이 생기면(write operation이 생기면) 그 때 해당 부분만 copy한다.
- 공유해서 자식 만드는게
vfork() - 이를 통해 copy delay 시간을 줄인다.
🔹Page Replacement
메모리 공간에 빈 공간이 없을 때 페이지 단위로 교체(swapping)하는 방안
- 한 프로세스에게 너무 많은 page를 할당(over-allocation)하지 않도록 해야된다
- Modify(dirty) bit: 메모리에 있는 프레임이 수정됐는지 안됐는지를 나타내는 비트
- 만약 수정되지 않았다면, swap out할 필요 없이 새로운 페이지를 해당 프레임에 swap in해서 덮어씌우면 됨
- 수정되었다면, swap out해서 저장해둔 뒤 새로운 페이지를 해당 프레임 자리에 swap in
- text는 수정되지 않고, 메모리나 stack 등은 수정된다.
- 이 비트는 demand paging 뿐만 아니라 캐시 과정에서도 사용
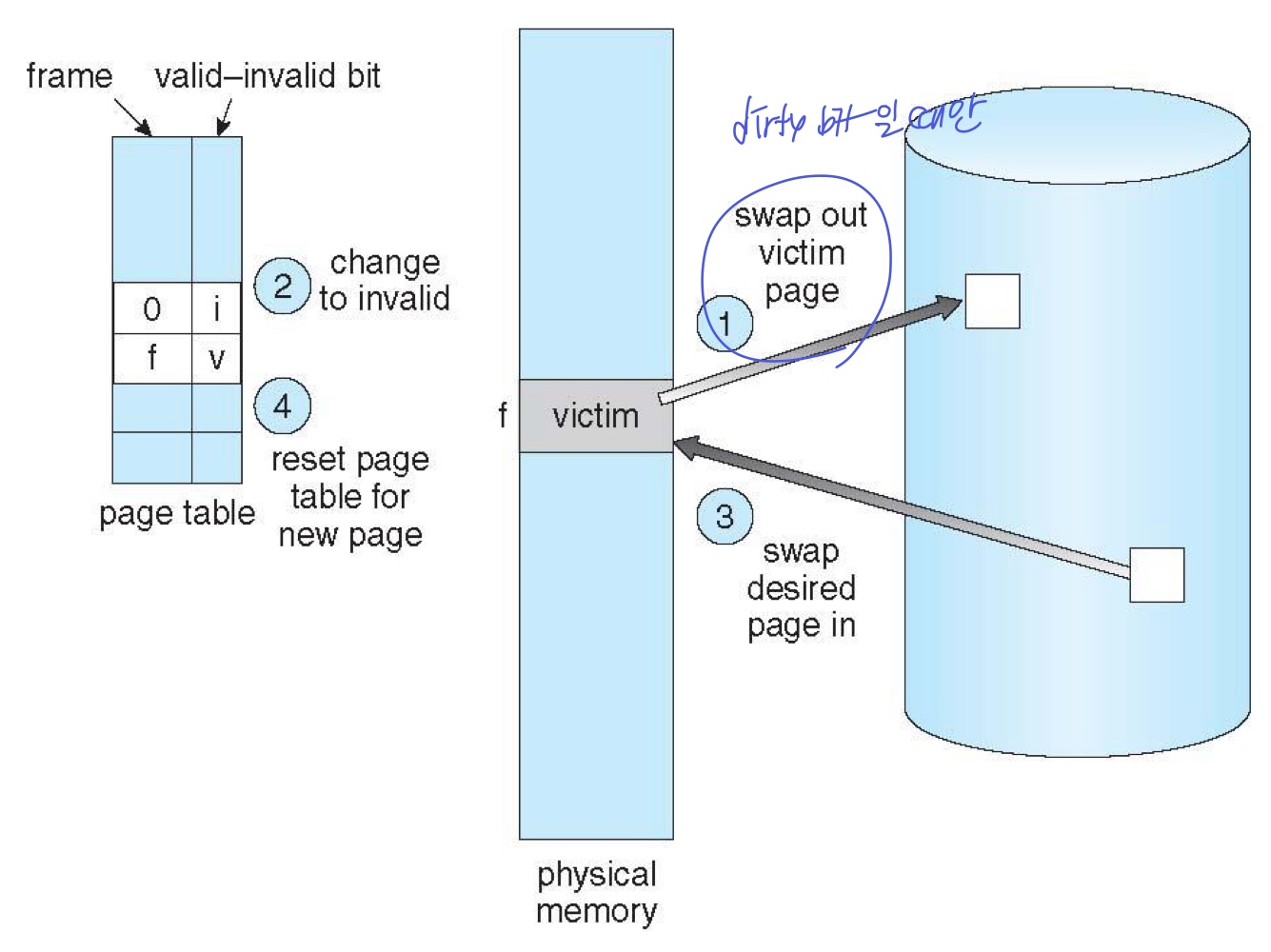
Page Replacement 과정
- 디스크에서 페이지 위치 찾기
- free frame 찾기
- 있으면 그대로 진행
- 없으면 victim frame 선정(알고리즘을 통해) 및 dirty bit 확인
- replacement하고 페이지 및 pagetable 업데이트
Algorithm
- 프로세스에 프레임을 얼마나 할당할건지 → Frame-allocation algorithm
- victim page 누구로 할건지 → Page-replacement algorithm (아래 설명)
일반적으로 프로세스에 프레임을 많이 할당할수록 page fault의 발생 비율이 낮아진다. algorithm의 성능은 Page fault가 얼마나 적은지로 나타낸다.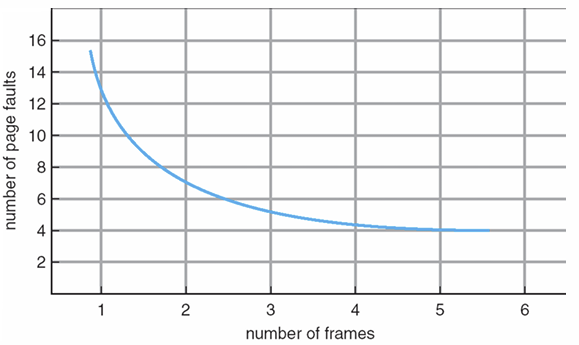
아래는 page-replacement alhorithm의 세가지 종류에 대한 설명이다.
1. FIFO
- 먼저 frame에 들어온 페이지가 victim
ex) 프로세스마다 3개의 프레임, 아래와 같은 순서로 페이지가 사용될 때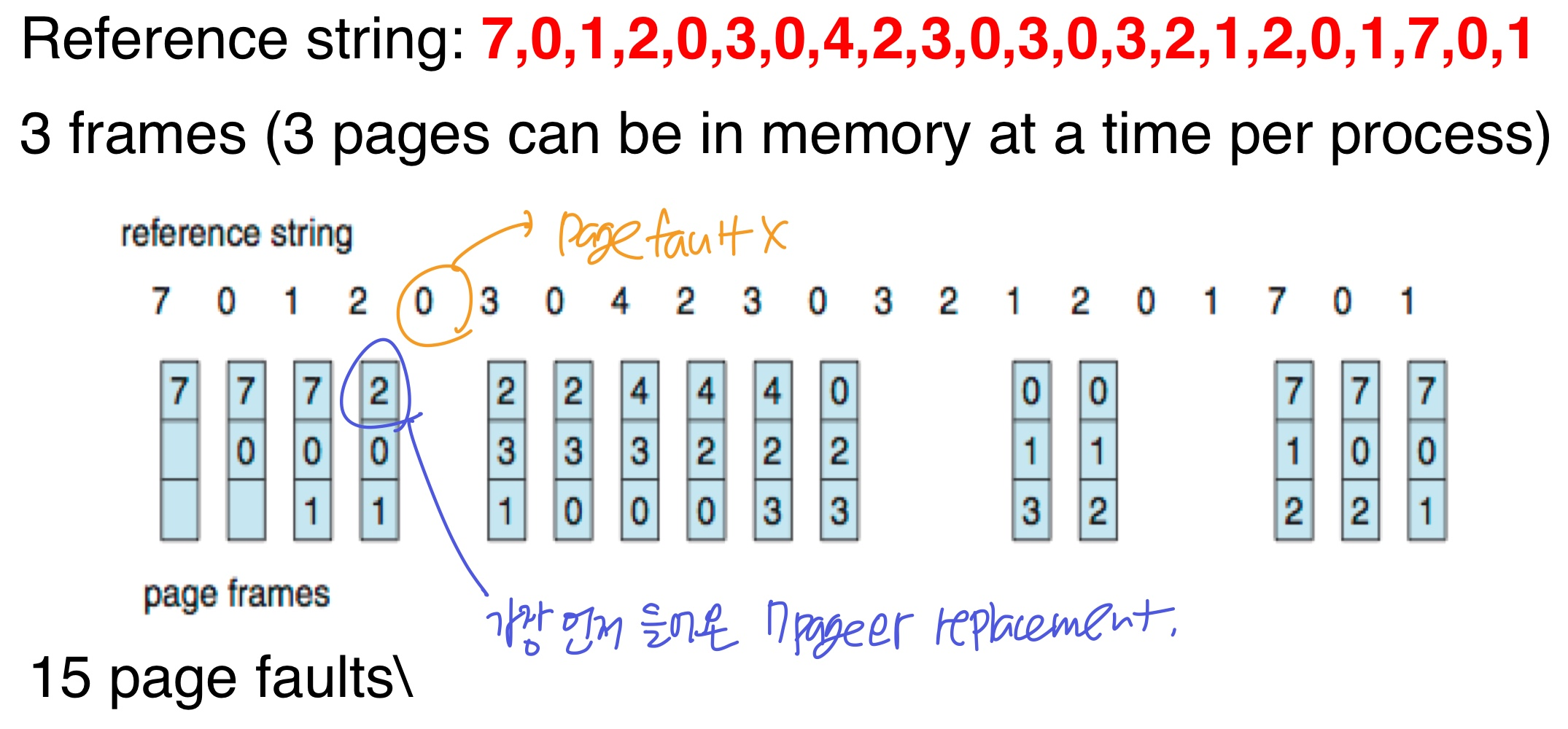 15번의 page faults (12번의 replacement) → 성능 별로 안좋음
15번의 page faults (12번의 replacement) → 성능 별로 안좋음
- 가끔 frame 수가 늘어났는데 page fault가 늘어나는 시나리오가 발생하기도 한다. → Belady’s Anomaly
2. Optimal Algorithm
- 가장 오래 사용되지 않을 페이지를 victim으로
- page fault를 가장 최소화하는 알고리즘(이상적, 최적)
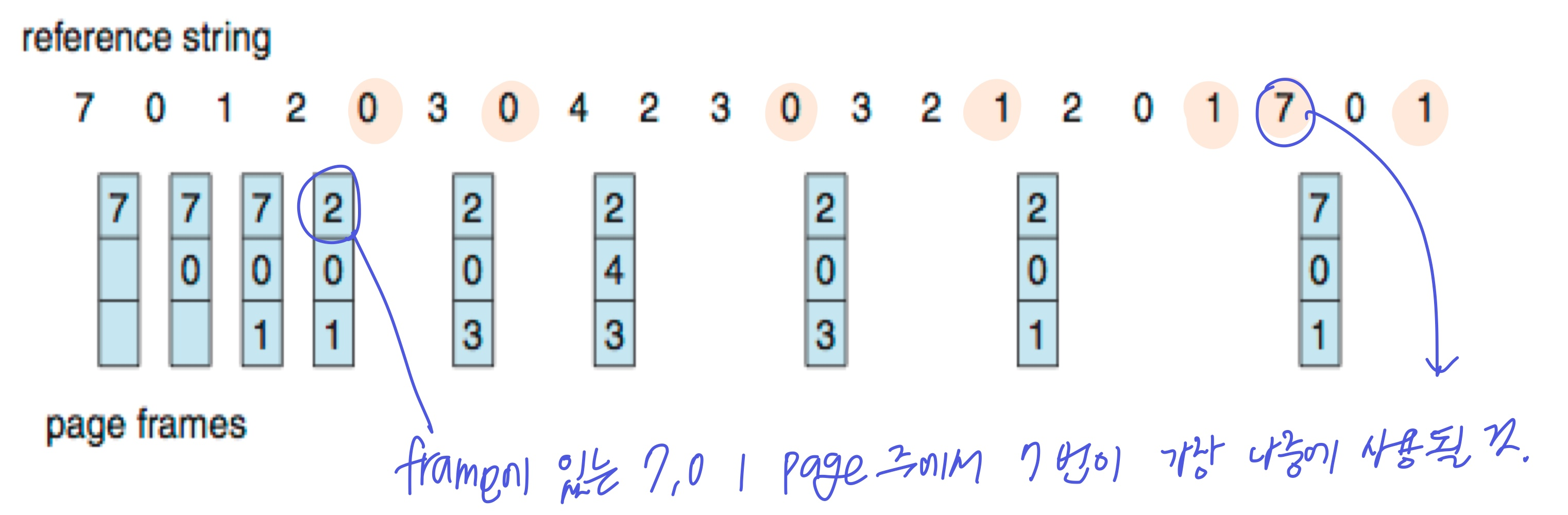 9번의 page fault
9번의 page fault
- 하지만 미리 예측이 어렵다는 단점
3. LRU(Least Recently Used) Algorithm
- 가장 오랫동안 사용되지 않은 페이지를 victim으로 (과거를 보고 미래 예측)
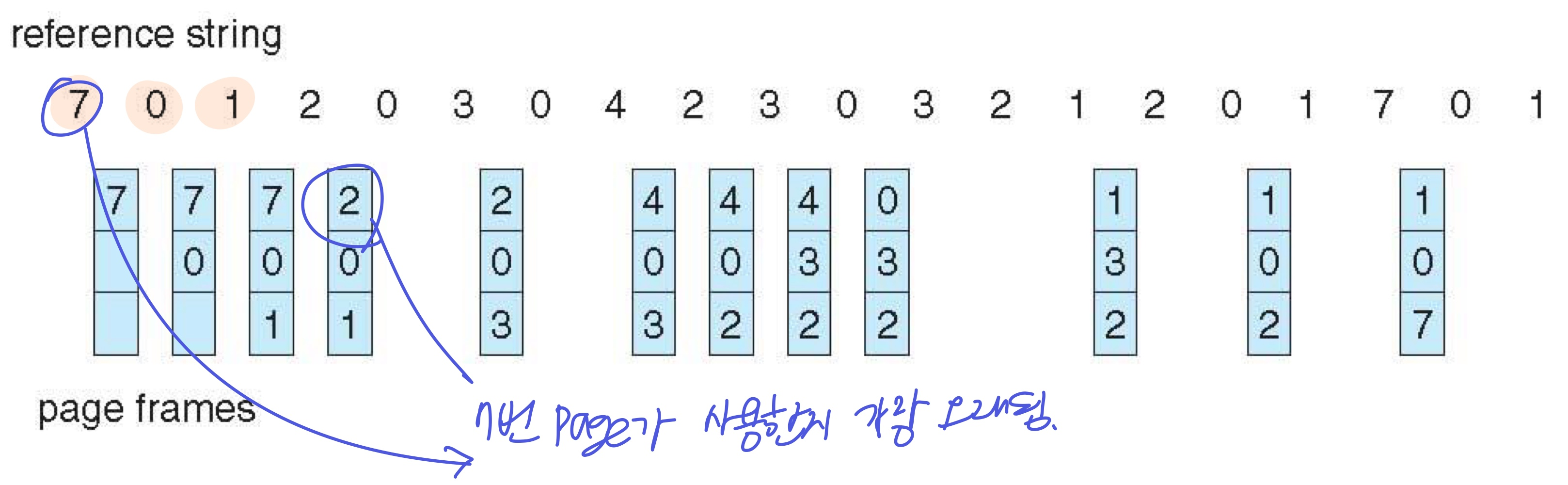 12번의 page fault (Optimal보단 안좋지만, FIFO보단 좋음)
12번의 page fault (Optimal보단 안좋지만, FIFO보단 좋음)
Implementation
1. Counter: page 사용할 때마다 카운터 증가
2. Time stamp: page 사용할때마다 time 기록
위의 두 방법은 page table에 저장되는데, overhead 발생
3.Stack: 사용한 순서대로 stack에 push, 아래에 있을 수록 사용한지 가장 오래됨 → victim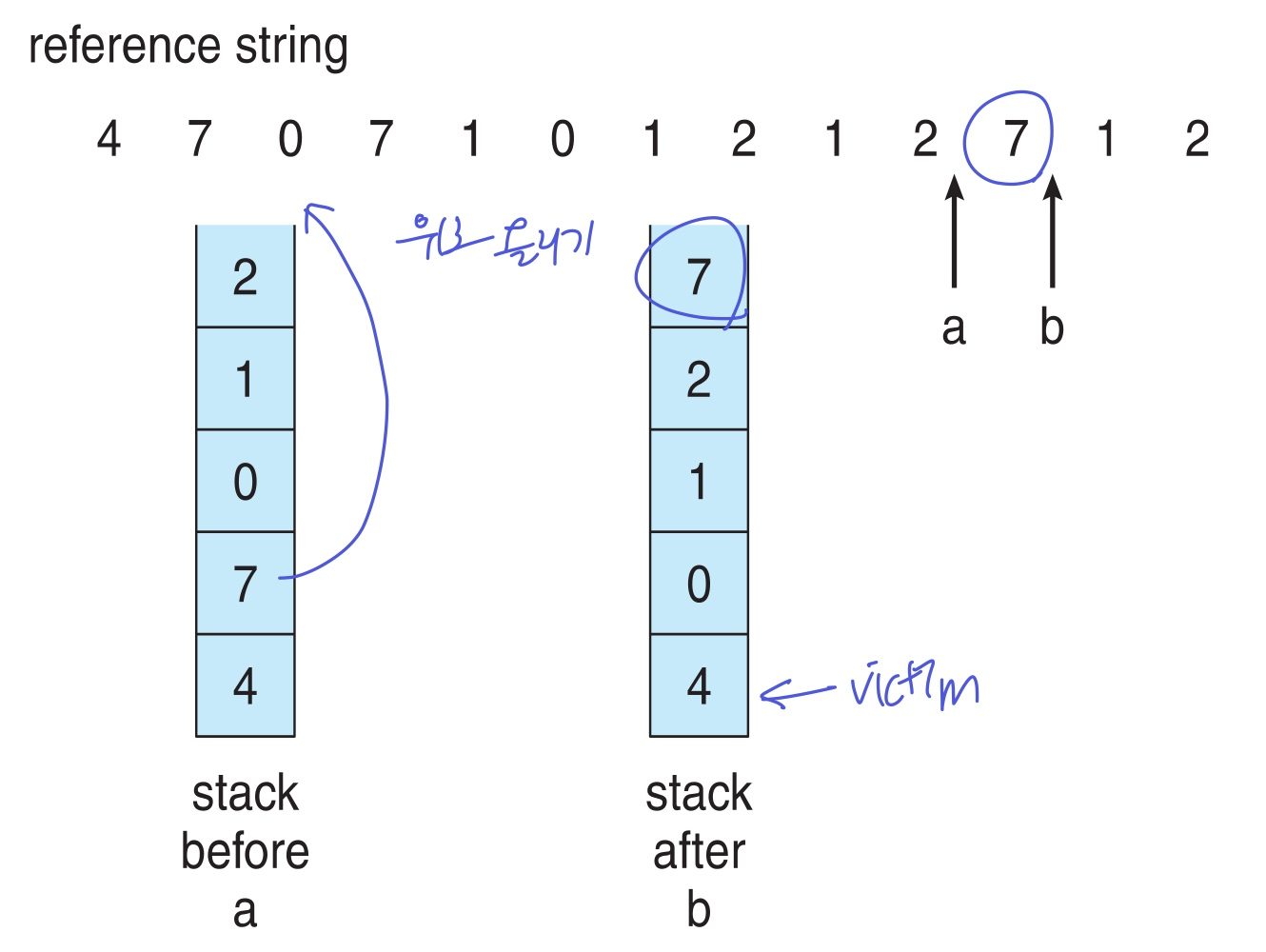 하지만 stack도 1, 2번보단 덜하지만 overhead..
하지만 stack도 1, 2번보단 덜하지만 overhead..
4. LRU Approximation Algorithms
- page 사용을 나타내는 reference bit로 LRU를 짐작
- reference bit: 해당 페이지 사용 했으면 1, 아니면 0 (page table에 기록)
Second-chance(Clock) algorithm 적용
- page순서대로 circular queue를 돌아다니는 포인터(시계의 침)이 존재
- 포인터가 가리키는 page의 reference bit가
- 0이면 → victim으로 설정
- 1이면 → 0으로 바꾸고 기회를 한 번 더준다
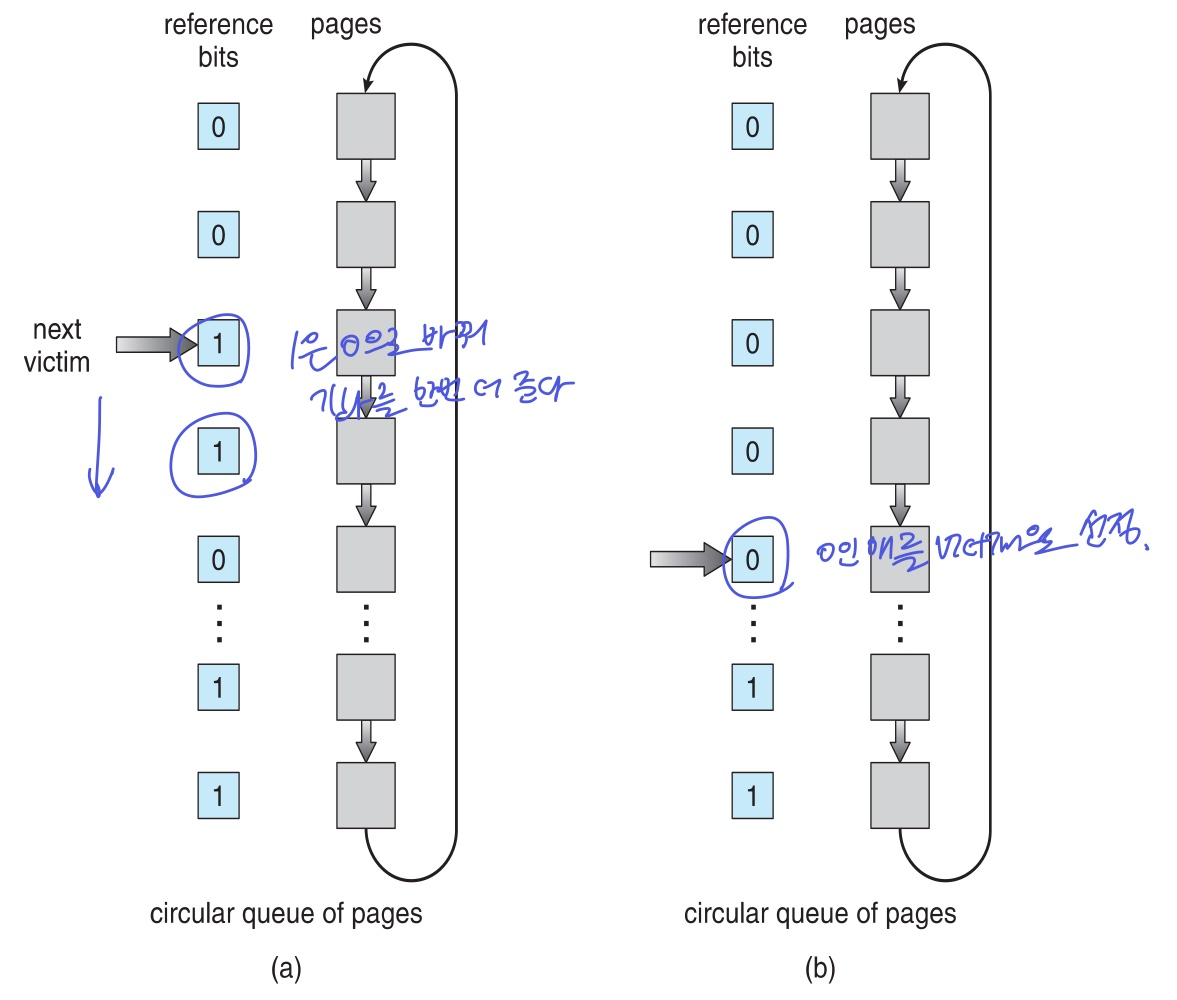
- cycle이 돌아오는 도중에 1로 다시 바뀌었다는 것은 자주 사용되는 거고, 0은 cycle이 돌아오는 동안 사용이 여전히 안됐다는걸 나타내므로
Enhanced Second-Chance Algorithm
- reference bit 뿐만 아니라 modify bit도 같이 고려한다.
- modify된 것보다 안된걸 쓰는게 더 나으니까
| (reference, modify) | victim |
|---|---|
| (0, 0) | 가장 좋음 |
| (0, 1) | 나쁘지 않음. page out 필수 |
| (1, 0) | 아마 금방 다시 사용될 페이지, 적합하지 않음 |
| (1, 1) | 적합하지도 않고 page out도 해줘야해서 최악 |
* Counting Algorithm
페이지 접근 횟수를 카운트해서 victim 정할 때 두 가지 기준이 있다.
- LFU(Lease Frequently Used): 사용 빈도 적은 것이 victim (적으니까 계속 사용 안될거다)
- MFU(Most Frequently Used): 사용 빈도 큰 것이 victim (많이 사용했으니까 이제 사용 안될거다)
* Page-Buffering Algorithms
OS는 freee frame을 항상 유지하여 page fault가 발생했을 때 지연이 발생하지 않도록 한다.
- free frame을 찾는게 아닌, 미리 준비된 free frame을 사용할 수 있도록 victim들 설정
- dirty(수정된) 페이지도 free frame pool에 들어갈 수 있고, 수정된걸 유지할 수 있다
* Application
일반적으로 OS가 page replacement를 관리하지만, 특정 Application은 일반적인 page replacement가 아닌 자신에게 잘 맞는 특정 알고리즘을 사용할 수 있다. (애플리케이션 개발자가 설정 가능)
- Raw disk mode: 하위 계층(디스크)에 계층적이 아닌 직접 접근을 할 수 있음
이런거 할 수 있다~
🔹Allocation of Frames
프로세스에게 프레임 할당을 어떻게 할까
- 각 프로세스는 최소/최대 프레임 수를 가진다.
프레임 할당 개수는
- Equal allocation: 모든 프로세스에게 같은 개수의 frame 할당 (1/n)
- Proportional allocation: 프로세스 크기에 따라 frame 할당 (ex.프로세스 크기의 2배)
page fault로 replacement가 필요할 때,
- Global replacement: 전체 프로세스를 다 따져 victim 정함
- Local replacement: 자신 프로세스 내 영역에서의 frame 중 victim 정함
Reclaiming pages
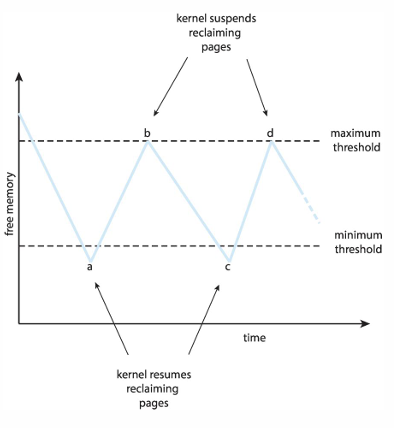
페이지 회수: global replacement를 구현하기 위한 방법으로, free frame을 확보하는 과정이다.
- OS는 일정 수의 free frame을 유지해야한다고 했다.
- free frame의 최대/최소 개수 (threadhold)가 존재한다.
- 최대보다 많아지면 free frame을 확보하려고 노력할 필요가 없음, replacement가 진행되며 free frame수가 줄어든다
- 최소보다 적어지면 커널은 free frame을 확보하려고 노력한다.
with NUMA
CPU에 가까운 메모리를 할당하는 것이 좋다. 가까워야 delay가 적고 성능 향상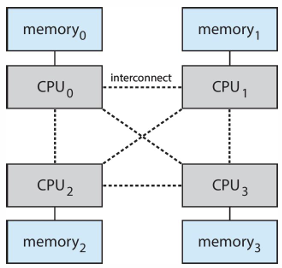
- Solaris는 Igroups를 생성해서 NUMA문제를 해결했다.
🔹Thrashing
프로세스에 할당된 page 수가 적어서 page fault가 너무 많이 발생하는 현상, page fault를 처리하기 위해 swapping하는 시간이 더 오래걸리는 경우
→ CPU 사용률 저하
프로세스의 수가 많아지면(멀티프로그래밍 증가) CPU 사용률은 증가하지만, 너무 많아지면 각 프로세스에 할당되는 page 수가 줄어든다. 어느정도를 넘으면 page 수가 부족해 page fault가 발생하여 CPU 사용률이 저하되는 것이다. (CPU가 놀고있음)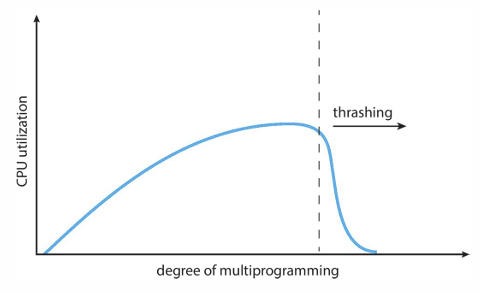
with Demanding page, Locality model
Locality Model에 따라, 프로세스의 loaclity size(=그 영역의 페이지 수)가 존재한다. 프로세스마다 적당한 locality size를 가진다.
- locality size가 총 메모리 크기보다 크면 (가진 것보다 많이 필요하면) Thrashing이 발생 (locality size>total memory size)
아래 그림의 가로는 시간, 세로는 전체 프로세스의 page를 나타낸다. 시간별로 locality한 영역의 페이지들이 사용되는 모습이 보인다. 메모리에 locality 영역만 로딩하여 적은 공간의 frame들로만 수행할 수 있다.
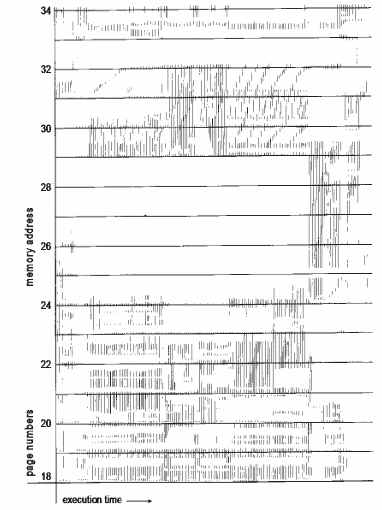
Working-set model (WSS)
특정 프로세스에서 최근에 사용한 page 집합을 의미한다.
모든 프로세스의 working set을 다 더하면, 현재 시스템에 필요한 총 frame 수를 알 수 있다.
- 만약 프로세스가 요구하는 page양이 시스템이 가진 물리메모리 공간보다 크면 (가진 것보다 더 많이 요구하면) Thrashing이 발생
- 그래서 working set을 메모리에 다 올려두는 것이 중요하고(올라가지 못하면 thrashing), 지속적으로 track해서 working set을 알아낸다.
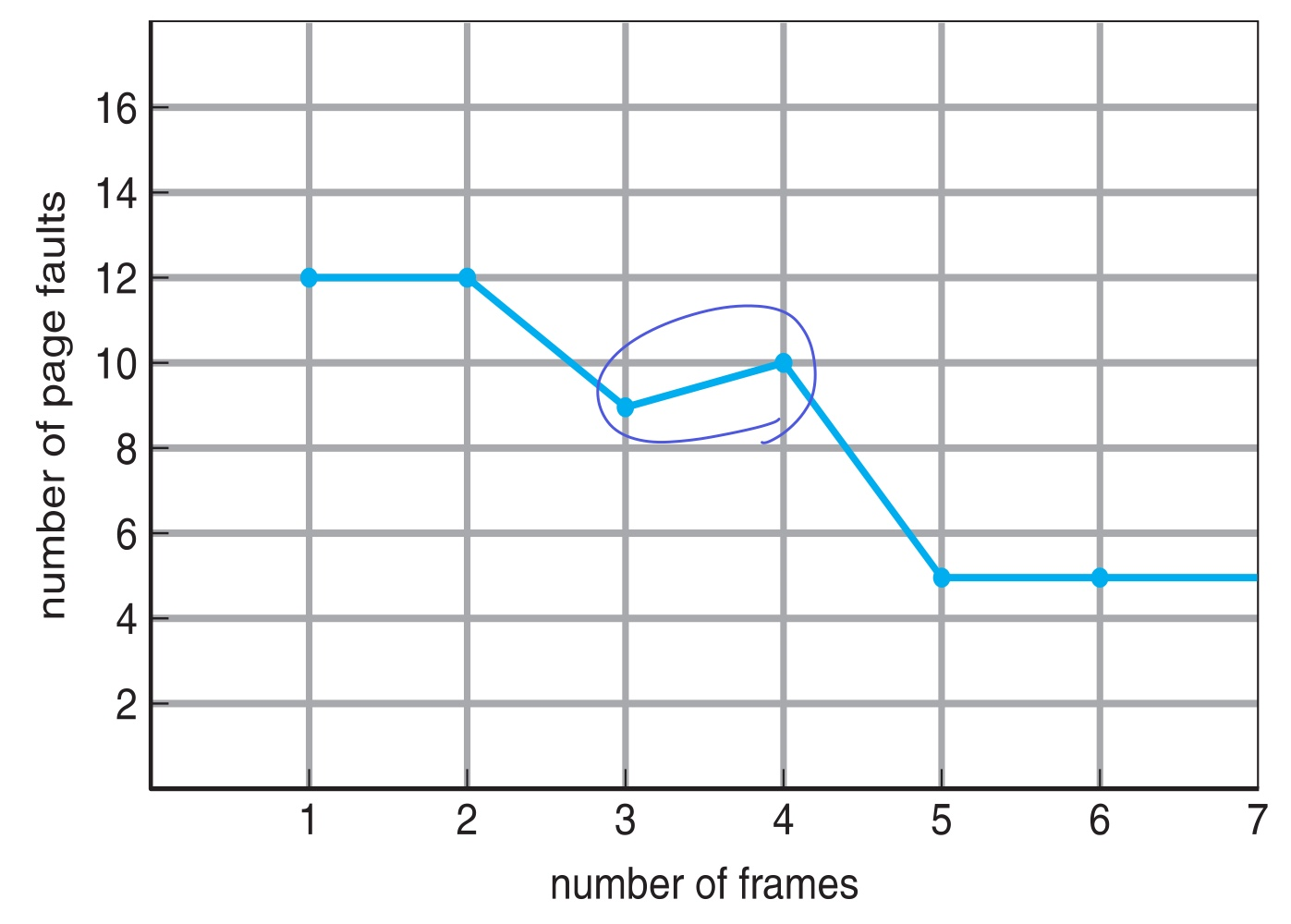
Page fault frequency
아래 그림은 한 프로세스에게 할당되는 프레임 수가 많아짐에 따라 page fault가 줄어드는 것이다.
- 프레임 수가 적으면 page fault가 너무 많아 부적절
- 프레임 수가 많으면 page fault 큰 차이도 없고, 한 프로세스에만 페이지가 몰빵된거라 멀티 프로그래밍 어려움
→ 그래서 적당히 프레임 수를 조절해가며 적당하게 유지해야한다.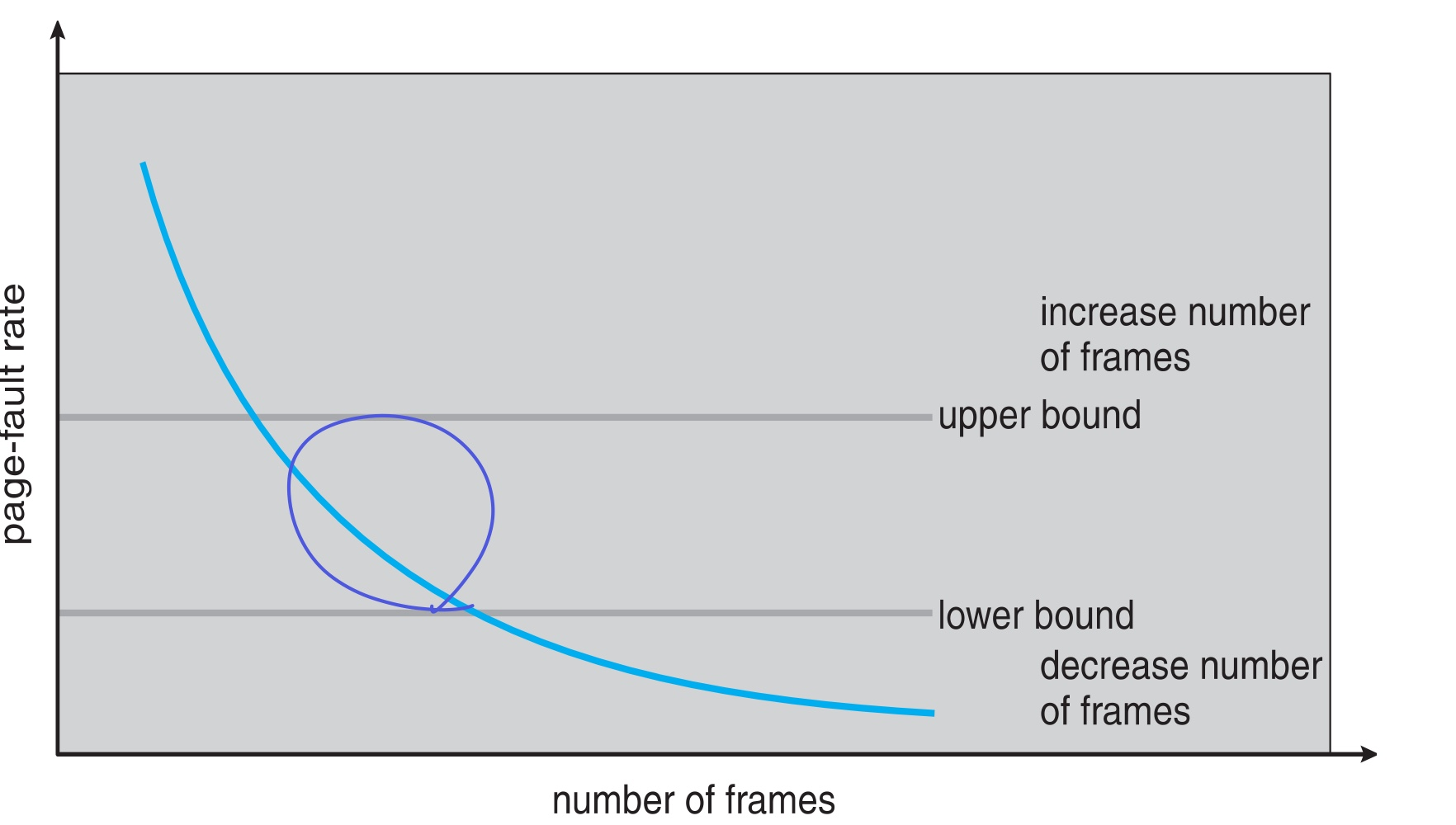
Page fault rate
시간에 따라 working set 변화 → 새로운 working set에 들어가면 메모리에 해당 페이지들이 없으니 page fault 발생 → local하게 계속 있으면 fault 줄어듦 → 시간이 지나 working set 또 변화 → …
page fault가 시간에 따라 일시적으로 발생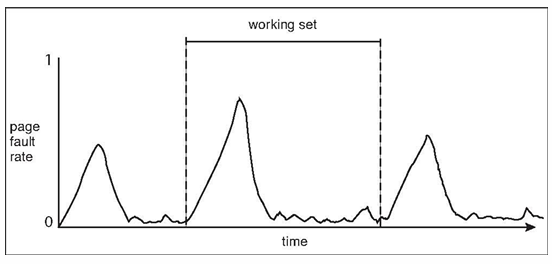
Memory Compression
페이징의 대안, 메모리 압축
- 수정된 프레임을 page out하지 않고, 여러 프레임을 하나의 프레임을 압축
- 이렇게 해서 시스템이 스와핑에 의존하지 않고 메모리 사용량 줄임(적은 오버헤드)
아래 그림은 15, 3, 35 3개의 프레임을 7이라는 하나의 프레임으로 압축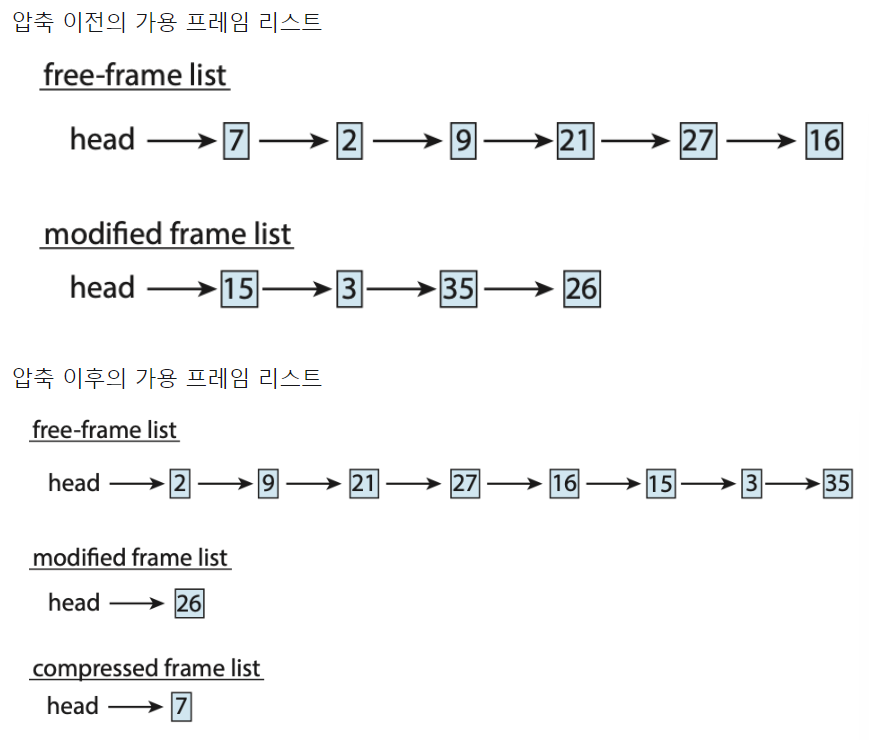
🔹Allocating Kernel Memory
커널에게 메모리를 할당해주기
- 커널은 우선순위가 높고, 관리 데이터 크기도 크다 → 요구 page 크기가 크다
- 그래서 커널에는 작은 page 여러개 할당해주는 것 보다, 연속적인 큰 page 하나를 할당해주는 것이 더 효율적이다. (할당 방법 여러개, 아래 설명)
1. Buddy System Allocator
물리적 연속 페이지를 쪼개가며 메모리를 할당
- 만약 커널이 32KB를 요청했고, 256KB의 청크가 있을 때
→ 32KB를 만족시키는 크기까지 2^n단위로 쪼개고 그 페이지를 할당해줌
→ 그 페이지가 해제되면 다시 합쳐지기도 함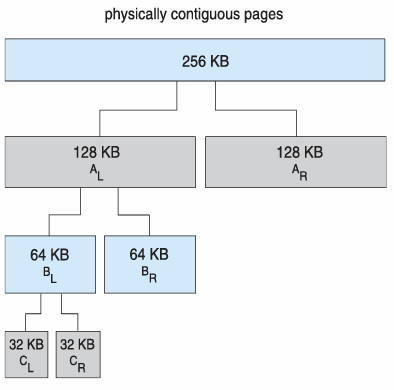
2. Slab Allocator
물리적 연속 페이지로 구성된 slab을 사용하여 메모리를 할당
- 연속된 페이지가 모여 slab → slab이 모여 캐시 → 캐시가 모여 오브젝트
- 오브젝트는 캐시를, 캐시는 슬랩을 할당받는다.
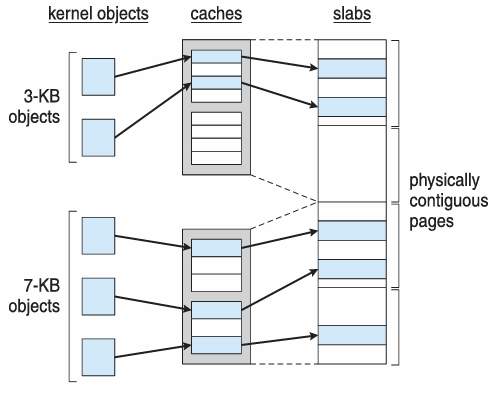
in Linux
- slab의 상태
- Full(꽉찬 슬랩), Empty(빈 슬랩), Partial(부분적으로 찬 슬랩)
- 커널의 요청이 들어오면 아래와 같은 우선순위로 슬랩 할당
- Partial → Empty → 새 empty slab 생성
변형된 슬랩
- SLOB: 제한된 메모리를 가진 모바일 시스템 등에서 사용, small, medium, large 오브젝트를 위한 3개의 리스트 관리 → 간단
- SLUB: 성능 최적화를 위해 발전된 형태, 메타데이터
🔹other Consideration
Paging할 때 고려사항들…
1. Prepaging
- demading page와 반대, 사용이 예상되는 페이지를 미리 올린다.
- page fault를 막을 수 있다는 장점
- s개 페이지를 미리 올리고, a비율로 페이지가 사용되면
→ prepaging 또는 save page fault 비용: sa
→ 낭비 비용: s(1-a)
2. Page size
- 상황에 따라 다른 페이지 크기를 설정할 수 있음 (보통 4KB~4MB)
- 고려할 점
- 페이지 테이블 크기를 작게 유지하려면 큰 페이지
- fragmentation은 작은 페이지에서 적음
- 페이지가 작을수록 높은 해상도(더 자세하게?정확하게?)
- I/O 오버헤드 줄이려면 작은 페이지
- 지역성이 강한 프로그램은 작은 페이지가 좋음
3. TLB reach
- 페이지 테이블의 크기 한계
- TLB reach = TLB 크기 * 페이지 크기
- Working set이 TLB에 저장되는게 효율적이다.
- 페이지 크기를 키우면 TLB reach를 키울 수 있지만, fragmentation으로 메모리 낭비 발생 가능
- 페이지 크기를 다양하게 제공하면 좋다
4. Inverted page table
5. Program structure
- ex) c에서 2차원 배열(128*128)이 있을 때
- c의 주소 체계?는 행 기준으로 쓰여지고 한 행이 꽉차면 다음 열로 넘어간다. → 각 열은 하나의 페이지에 저장
- 열 우선 방식으로 배열에 접근하면 한 열을 접근 할 때마다 page fault 발생

- 행 우선 방식으로 배열에 접근하면 각 행마다 1개의 페이지만 필요

6. I/O interlock and page locking
- CPU가 I/O디바이스에 직접 접근하면, CPU는 너무 빠르고 I/O는 너무 느려서 CPU가 쓸데없이 오래 기다리게 됨
- 그래서 I/O디바이스의 버퍼를 메인 메모리 공간에 배치하여 CPU가 이 버퍼를 접근하도록, 덜 기다리도록 함
- 이때, 해당 버퍼가 page replace당해버리면 문제가 발생하므로 interlock으로 보호
🔹OS example
Window
- Demand paging
- clustering → page fault 발생하면 근처 page도 메모리에 가져와서 page fault를 줄임
- working set의 min/max 동적 관리 가능(trimming)
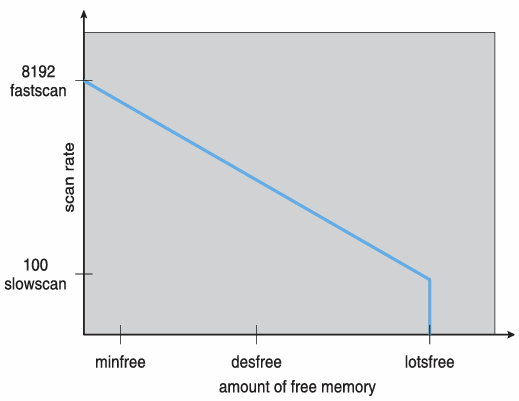
Solaris
- Demand paging
- scan
- Second-chance(Clock) algorithm에서 clock이 도는 것을 스캔한다고함
- scanrate: clock 속도
일정한 free memory를 유지하기 위해 min/max값을 가진다. free memory가 min보다 적으면 scan을 빠르게해서 free memory를 빠르게 얻고, max보다 크면 scan을 안한다. max와 가까워질수록 scan을 천천히한다.