
ch 11. Mass-Storage Systems
대용량 저장 장치
💡11장 목표
- 구조
- HDD, NVM
- Storage Device Management
- Scheduling
- RAID
🔹Structure
대용량 저장 장치는 HDD와 NVM(SSD)로 구성되어있다. HDD가 가장 낮고, 그 위에 SSD, 그 위에 메모리의 계층 구조를 가진다.
(Magnetic tape → HDD → SSD → RAM(주기억장치))
1. HDD
하드 디스크 드라이브
- 디스크 형태, 초당 60-250회 회전
- 디스크 암이 가리키는 곳으로 데이터를 접근한다.
- 데이터를 전송하는 속도 Transfer rate를 가진다. 이는 드라이브와 컴퓨터 간의 데이타 흐름 속도를 나타낸다.
- Positioning Time 즉, 위치를 지정하는 시간은 아래 두 시간을 합친 것이다.
- seek time: 디스크 암이 움직이며(디스크 안/바깥 수평 이동) 원하는 sector가 위치한 track을 찾는 것
- Rotational latency: 디스크 자체가 회전하며 (트랙 회전) 원하는 sector를 찾는 것 ****
- latency = 1/(RPM/60) = 60/RPM
- 평균 latency = 1/2latency (운이 좋으면 바로 찾고, 운이 안좋으면 한바퀴 돌아서)
Positioning Time은 데이터 접근 속도에 큰 영향, HDD 성능 평가 지표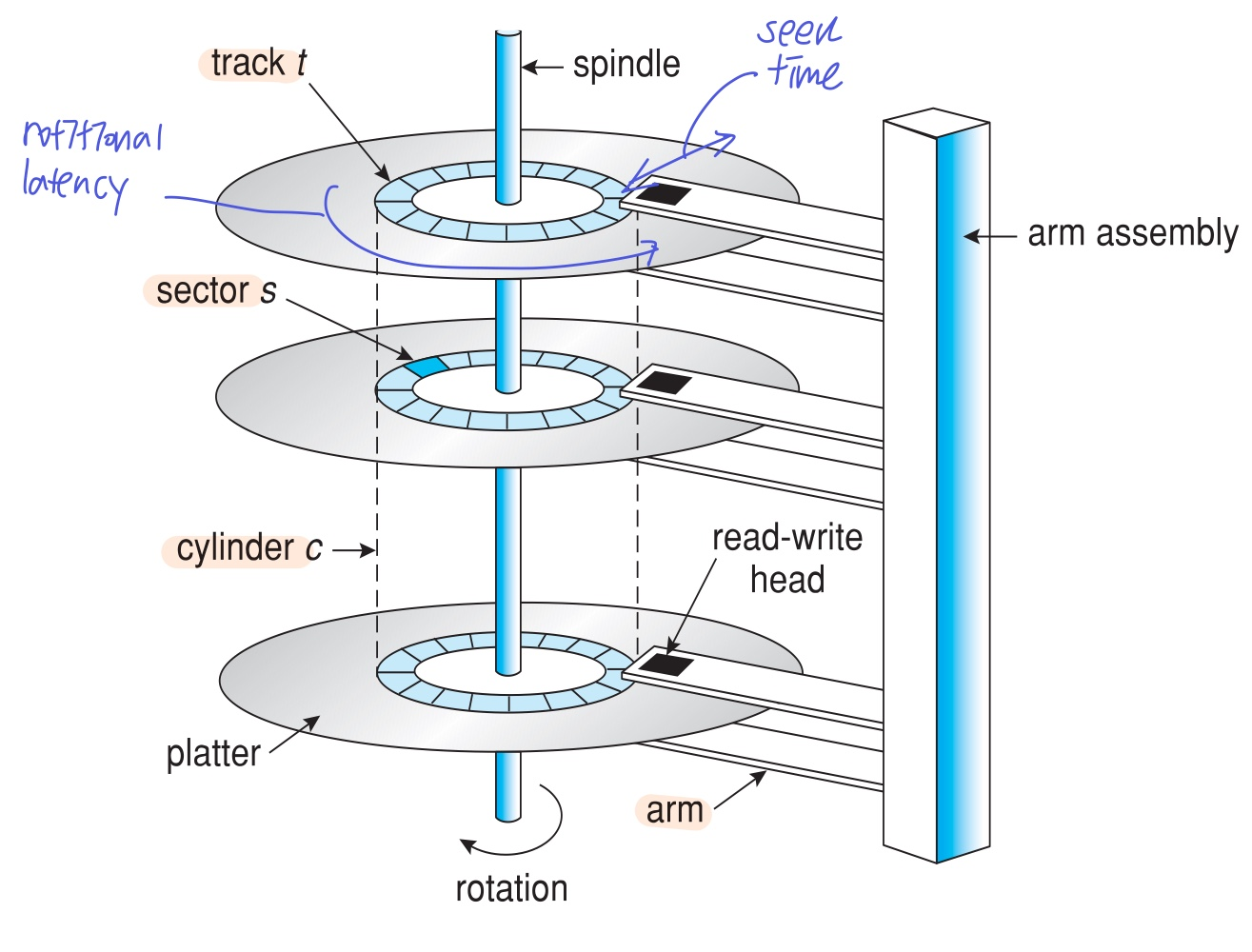
Average I/O time
= average accress time + (amout to transfer/transfer rate) + controller overhead
- 첫째 항: 물리적인 지연 시간, average seek time + average latency
- 둘째 항: 데이터 이동 시간 (전송 데이터 크기/전송 속도)
- 셋째 항: CPU(controller) 계산 시간
example: 4KB블록을 7200RPM 디스크에서 전송하는 경우
- 전송 데이터 크기: 4KB블록
- 7200RPM
- average seek time: 5ms
- transfer rate: 1GB/s
- controller overhead = 0.1ms
가 주어졌을 때,
- average latency: 4.17ms = (60s/7200)/2
- transfer time = 0.031ms
를 계산할 수 있다. 결론적으로
Average I/O time = 9.17ms + 0.031ms + 0.1ms = 9.031ms
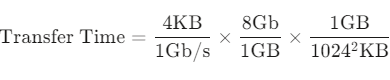
2. NVM
비휘발성 메모리(Nonvolatile Memory), SSD(solid-stae disks)
- 전윈이 꺼져도 내용 유지
- HDD보다 용량이 적고, 전력이 덜 들고, 속도가 빠름, 단지 더 비쌈
- HDD의 캐시 용도로 자주 사용
- 읽기/쓰기 시간이 다르다.
- 쓰기 시 기존 데이터를 덮어 쓸 수 없으므로 지운 뒤 써야하기 때문
- 그리고 지우는 횟수가 제한되어 있음, 만약 하루에 5번 write해서 1년 쓸 수 있다면 5DWPD라고 함 (드라이브 수명)
NAND Flash controller algorithms
- 비휘발성 메모리 장치는 블록들로 관리를 하는데, 각 블록들은 여러 페이지로 구성되어있다.
- 각 페이지는 유효한지/유효하지 않은 데이터를 가지고 있다.
- 유효한 데이터 → 사용 중
- 뮤효한 데이터 → 사용 완료, 이 공간을 쓰려면 기존 데이터 지워야 함
- 근데 지우려면 페이지 단위로 지울 수 없고, 블록 단위로 지워야한다.
- 그래서 유효한 데이터를 다른 블록으로 copy해서 몰아버린다음에 지운다. 이것이 Garbage Collection
- Garbage collection을 위한 공간을 제공하기 위해 overprovisioning(실제 제공 용량보다 큰 용량 예약)을 할당
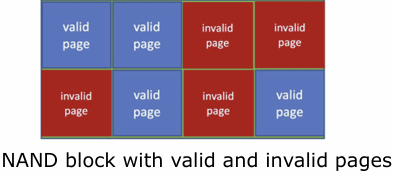
- Garbage collection을 위한 공간을 제공하기 위해 overprovisioning(실제 제공 용량보다 큰 용량 예약)을 할당
Volatile Memory
휘발성 메모리, 주기억장치
- RAM을 사용하여 가상의 디스크 드라이브 생성
- 속도가 아주 빠른 임시 저장 공간으로 사용
Disk
Attachment
- CPU에 연결된 메인 버스가 아닌 디스크 전용 I/O 버스를 통해 디스크에 접근
Address Mapping
- 디스크 드라이브는 큰 1차원 배열의 논리블록으로 주소 지정, 연속적인 공간으로 보임
- 실제 물리주소는 동그란 disk에 존재 (몇번 트랙의 몇번 섹터인지)
🔹Scheduling
1. HDD Scheduling
OS는 여러 프로세스가 하드디스크에 접근을 요청했을 때, 어떤 프로세스를 먼저 받아줄지 정해야한다. 이 때 주안점은 seek time 줄이기⭐
스케줄링을 통해 디스크 암이 움직이는 경로?를 조정하게 되는 것이라 이걸 효율적으로 움직이게 하는게 중요
프로세스가 하드디스크로의 I/O요청을 보내고, I/O 디바이스 드라이브가 해당 요청 트랙이 디스크의 어디에 있는지를 알아낸다.
1. FCFS
- 요청이 도착한 순서대로 처리
- 비효율적인 디스크암 이동, 이동 거리 길어짐
2. SCAN
- 디스크암이 디스크의 한쪽 끝에서 다른 쪽 끝으로 이동하며 있는 요청 처리
- 안쪽→바깥쪽→안쪽→…
- 엘레베이터 알고리즘이라고도 함
- FCFS보다 이동 거리가 짧다. 하지만 요청이 불균형하거나, 엘베 놓친 것처럼 암이 금방 지나간 곳에 요청이 뒤늦게 발생하면 대기 시간 너무 길어짐 → C-SCAN
C-SCAN
- 한 방향으로만 스캔, 한쪽 끝에 도달하면 요청을 처리하지 않고 즉시 반대편으로 돌아감
3. SSTF
- Shortest Seek Time first, 가장 가까운 요청 먼저
- 일반적으로 사용되는 알고리즘
+) Deadline
하지만 여전히 어떤 알고리즘을 쓰더라도 starvation 문제 발생 (너무 오래 기다림)
-> 그래서 각 요청의 deadline을 지정해서 설정한 시간 안에는 처리되도록 하는 방법을 추가하기도 함
2. NVM Scheduling
물리적 이동 시간(디스크 암, 회전 대기 시간)을 고려할 필요가 없어서 그냥 FCFS로 스케줄링
그래도 최적화를 할 수 있는 여지 존재
- garbage collection
- 근처 요청 한꺼번에 처리
🔹Error detection and Correction
메모리, 디스크 등의 오류 감지
- 패리티 비트
- 해시 함수
오류 수정
- 추가적인 오류 수정 코드(ECC)
- 하지만 ECC가 더 크면 좀 그렇겟지
🔹Storage Device Management
스토리지가 데이터 저장을 효율적으로 하기 위한 프로세스
- Formatting: 트랙과 섹터를 다시 설정하는 것
- 디스크를 섹터로 나눠 각각 채우는 것은 low-level(physical) formating
- 물리적 디스크를 쪼개서 한 파티션을 logical disk처럼 사용하는 것은 logical formating
- 각 파티션은 한 파일 시스템일 수 있고, 별도의 장치 처럼 취급할 수 있고, ..
- Root Partition: OS를 포함하는 파티션, 부팅할 때 가장 먼저 마운트
- OS 로딩을 위한 부트스트랩 로더 프로그램이 부트블록 파티션에 저장이 되어있는 것이다. 즉, 부팅 관련도 하드디스크에 저장되어있다.
- 마운트 할 때 파일 시스템 초기화
물리적 디스크는 아래와 같이 파티셔닝되고, MBR에는 boot code와 파티션 정보를 담은 partition table이 있다.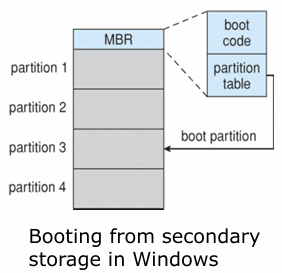
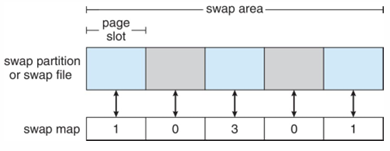
🔹Swap-Space Management
메인 메모리가 모든 프로세스를 수용할 수 없을 때, 더 많은 공간을 필요로 하는 경우 swap
- swap 공간도 쪼개서 사용
- swap map은 해당 슬롯을 사용 중인 프로세스 개수를 나타냄
🔹Storage Attachment
CPU가 저장 장치에 연결하는 방법
- Direct Attached Storage, DAS
- Host-attached(호스트 연결), 로컬 연결
- 메인 버스를 통해 디스크 컨트롤러에 직접 접근
- Fibre channel과 같은 고속 아키텍처로 빠르게 전달 가능
- Network-Attached Storage, NAS
- 네트워크를 통해 저장소 접근 (네트워크를 통해 저장소 제공)
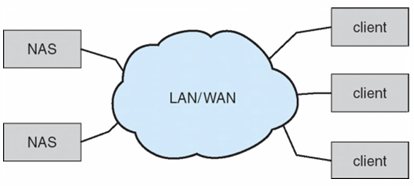
- 네트워크를 통해 저장소 접근 (네트워크를 통해 저장소 제공)
- Cloud storage
- 클라우드를 통해 저장소 접근 (클라우드가 저장소 제공)
- NAS는 파일 시스템으로 제공되는 반면, 클라우드 저장소는 API를 사용하여 접근
- Dropbox, Amazon, Onedrive, iCloud …
Storage Array (RAID)
- 디스크 여러개를 연결하여 배열로 이어 붙임
- 여러개의 디스크를 동시에 사용 가능, I/O병럴처리를 통한 속도 향상
- 중요 데이터를 여러 디스크에 복제 저장 가능 → 한 디스크가 고정나더라도 다른 디스크에서 데이터 계속 사용 가능
- 중복 제거 기능으로 저장 공간 효율적 사용
- 에러 처리 및 복구
Storage Area Network(SAN)
- 하나 이상의 storage array로 구성된 고속 데이터 전송을 위한 스토리지 전용 네트워크
- 다수의 호스트가 여러 storage array에 연결
- 클라이언트는 SAN을 통해 위 storage array와 연결
- 이때, 클라이언트는 서버 API 또는 데이터 프로세싱을 통해 SAN에 연결 (오류 발생 방지)
- 그래서 SAN에는 고성능 네트워크가 필요
- Fiber channel switches 또는 InfiniBand등과 같은 고성능 네트워크로 연결
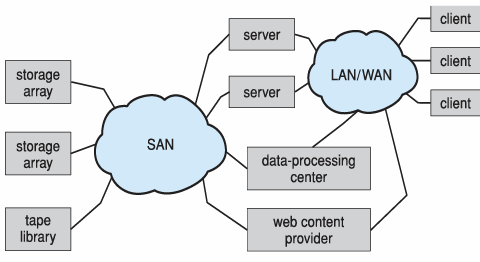
- Fiber channel switches 또는 InfiniBand등과 같은 고성능 네트워크로 연결
🔹RAID Structure
여러 개의 하드디스크 배열을 사용 (Redundant Array of Inexpensive(independent) Array)
- 중복성(동시성)을 이용한 신뢰도 향상
- 중요 데이터를 복제하여 한 디스크가 고정나더라도 데이터 손실 방지
- 성능 향상
- 여러 디스크의 병렬처리로 속도 향상
- NVRAM과 결합하여 더 빠르게 가능
- 에러 처리
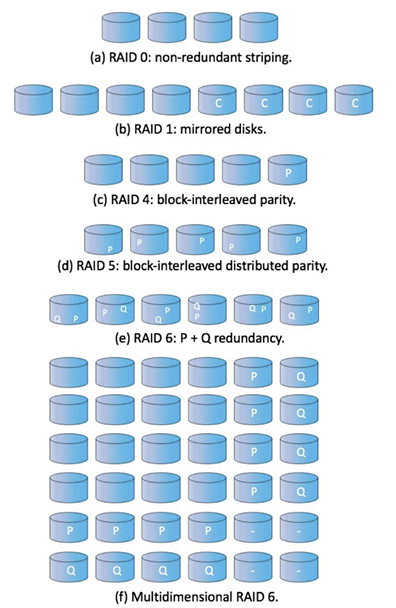
RAID 레벨
6개의 레벨로 구성되어 있으며, 각 레벨은 데이터의 저장 방식에 따라 다름
| RAID 0 | Striping | • 줄무늬처럼 데이터를 여러 디스크에 분산하여 저장 (한 디스크 꽉채우고 다음 디스크가 아니라, 디스크별로 하나씩 넣기) • 이는 여러 디스크의 데이터를 동시에 읽을 수 있도록 해줌 |
| RAID 1 | Mirroring/Shadowing | 각 디스크의 데이터를 완전 복사 |
| RAID 1+0 / 0+1 | Mirrored stripe / Striped mirror | 복사하고 스트라이핑 = 복사해서 스트라이핑 |
| RAID 4 | Block-interleaved distributed parity | • 패리티 비트를 가진 디스크 하나 추가 • 병목 현상 발생 가능 |
| RAID 5 | Block-interleaved distributed parity | • 패리티를 각 디스크마다 분산해서 가지도록 • 병목 현상 보완 |
| RAID 6 | P+Q redundancy | 패리티 뿐만 아니라, 에러 복구 코드도 추가 |
| Multidimensional RAID 6 | 양방향, 2차원으로 RAID를 만들어 더욱 효율적으로 |
추가 기능
- 스냅샷: 특정 시점의 파일 시스템 상태를 저장, 복구 가능하도록 함
- 복제: 데이터 자동 복사를 통해 복구 지원
- ZFS: 파일 시스템 레벨 에러 처리
- RAID는 스토리지 레벨에서만 디스크 에러에 대한 처리 → 파일 시스템 레벨 에러 처리는 안함.
하지만 ZFS를 사용하면 storage pool로 저장소를 공유하고 필요한 만큼 저장소를 제공해준다.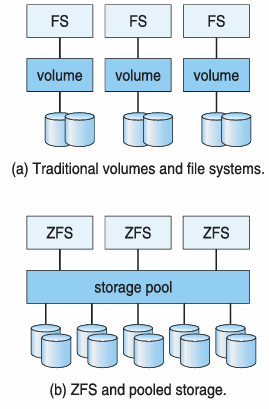
- RAID는 스토리지 레벨에서만 디스크 에러에 대한 처리 → 파일 시스템 레벨 에러 처리는 안함.
Object storage
용량이 큰 데이터를 스토리지에 1:1로 매핑해서 저장하는 것이 아닌, 오브젝트를 사용해서 저장 (오브젝트 단위로 저장)
- 오브젝트는 논리적인 저장 공간으로, 여러 노드에 걸쳐있으며, 복사 기능을 가진다.
- N개의 시스템에 N개의 복사본 저장
- 오브젝트 저장소 관리 소프트웨어: Hadoop file system(HDFS), Ceph
