
💡 4장 목표
- CPU 이용의 기본 단위 Threads
- Multi-threaded programming
- Thread Library API
- implicit threading, thread pools, fork-join, Grand Central Dispatch
Thread는 프로세스의 resource를 공유하기 때문에 multi-processor에 비해 multi-thread는 경량화되고 좋은 병렬성을 가진다.
🔸Multi-thread process
Motivation
최근 대부분의 application은 multi-thread를 활용한다. Multi-thread를 사용하면 하나의 application이 여러 작업을 동시에 수행할 수 있다. 예를 들어, 웹 서버에서는 화면 업데이트, 데이터 가져오기, 스펠링 체크, 네트워크 관련 기능 등 각 기능을 독립적인 thread로 만들어 동시에 수행함으로써 성능을 향상시킬 수 있다. 많은 운영체제의 kernel들은 multi-thread의 형태를 가진다.
Multi-thread는 multi-processor를 사용하는 것보다 효율적인데,
- thread는 프로세스보다 생성 시간이 빠르고
- 한 프로세스의 자원을 여러 thread가 공유하기 때문에 컴퓨터 자원을 적게 차지하며
- thread 간 통신이 더 빠르다
결과적으로 multi-thread를 통해 프로그래밍이 단순화되고 효율성이 증가한다. Thread는 커널과 라이브러리 수준에서 지원된다.
Multi-thread
- 프로세스 안에 하나의 Thread vs 한 프로세스 안에 여러개의 Thread
- 각 Thread는 register, stack, PC는 각자 가짐
- 공유할 수 있는 code(instruction), data, files은 공유함
→ multi processor보다 multi thread로 concurrency를 구현하는 것이 더 좋은 이유 (thread 생성이 빠르고, 자원을 적게 차지하고, thread간 통신이 빠름)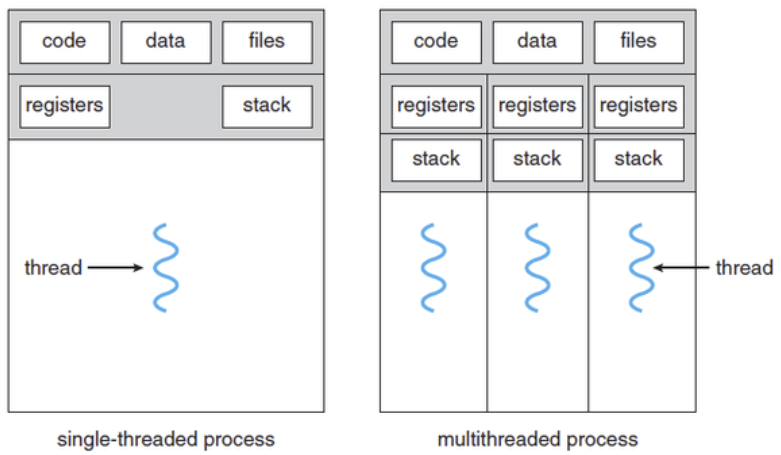
Server에 활용되는 Multi-thread example
서버는 수많은 여러 클라이언트의 요청을 처리해야한다. 서버는 요청이 들어오면 서버는 thread를 생성하고, 해당 요청을 도맡아 처리한다. 즉, 서버를 multi-thread로 구현하여 여러 요청을 동시에 처리한다.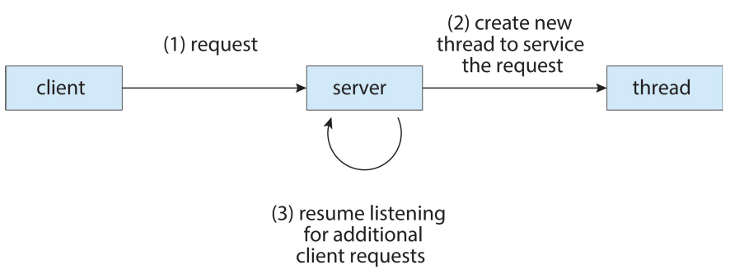
Benefits
- Responsiveness(응답성)
- 일부분(thread)이 blocking 되더라도 다른 쓰레드는 계속 일하므로 프로그램의 수행이 계속 됨
- Resource sharing(자원 공유)
- thread는 자신이 속한 프로세스의 resource들과 memory를 공유하기 때문에 리소스를 적게 차지
- global data를 공유하기 때문에 쓰레드 간 통신 가능
- Economy(경제성)
- 프로세스 생성을 위해 memory와 resource를 할당하는 것은 비용이 많이 듦
- Thread는 자신이 속한 process의 resource를 공유하기 때문에 생성에 적은 자원을 차지
- 많이 만들 수 있음, context switching이 빠름
- Scalability(규모 적응성)
- multi-processor 구조에서 더욱 증가할 수 있음
- 각 thread가 다른 processor에서 parallel하게 수행될 수 있기 때문
- ex) 쓰레드를 많이 만들어서 multi-core 아키텍처 (코어마다 쓰레드 할당 가능)
- Concurrency(병행): 소프트웨어적인 측면에서 동시에 수행하는 것 (multi-processor, thread)
- Parrallel(병렬): 실제로 하드웨어가 여러 개 있어서 동시에 수행 (multi-computer, core, CPU)
🔸Multi-core Programming
- 단일 CPU인데, CPU의 핵심 디바이스인 Core가 여러개
Concurrency vs Parallelism
- single-core 시스템에서 Concurrent 실행
- 단순히 thread의 실행이 시간에 따라 교대로 실행
- ex) CPU schedular는 시스템의 프로세스 사이를 빠르게 오고 가며 프로세스를 진행시켜 마치 병렬 실행하는 듯한 착각

- multi-core 시스템에서 Parallelism
- 물리적으로 한 순간에 동시 실행
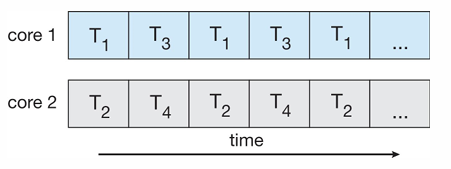
- 물리적으로 한 순간에 동시 실행
Type of Parallelism
- Data Parallelism: 데이터를 쪼개서 동시 수행 → 각 코어에서 동일한 연산 (하나의 일을 여러 코어가 함께 수행)
- Task Parallelism: task를 쪼개서 동시 수행 → 동일한 데이터지만 task가 많은 경우, 각 코어마다 다른 연산 수행
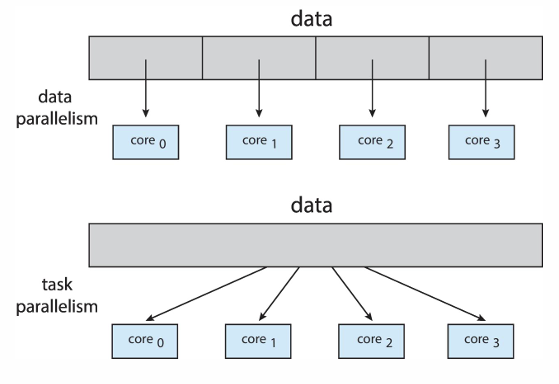
Challenges
멀티코어, 멀티 프로세서 환경에서 프로그래밍은 난이도가 어렵다
- Dividing activities: Application을 분석하여 여러 task로 나눠서 분배할 영역 찾아야 함
- Balance: 찾아진 부분들이 전체 작업에 균등한 기여도록 가지도록 해야함
- Data splitting: Application이 여러 task로 나뉘는 것처럼, task가 접근하는 data도 각 core에서 사용할 수 있도록 나눠야함
- Data dependency: task가 접근하는 데이터가 dependency가 있는지 없는지 검토해야함
- ex) A를 처리해야 B를 처리할 수 있는 로직 → 동시 수행 불가능
- 검토해서 동시 처리 할 것과 안할 것을 따져야함
- Testing and Debugging: 디버깅 어렵다!
Data dependency (Amdahl’s Law)
Serial(직렬) 및 Parallel(병렬) component가 혼합된 application에서 코어 수에 따른 성능 향상에 대한 법칙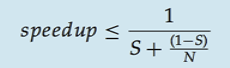
- S: Serial components의 비율
- 직렬, 순서에 따라 해야하는 일 = dependency를 가지는 일
- 1-S: Parallel components의 비율
- 동시에 수행할 수 있는 일
- N: 코어의 수
- speed up: 코어의 처리 속도를 얼마나 올릴 수 있는가
application에서 S는 줄일 수 없다. 1-S는 N개의 코어가 동시에 수행하면서 시간을 줄일 수 있다. 분모는 처리 시간을 의미하고, 역수는 처리 속도를 의미한다.
예를 들어서 S가 25%이고, 코어가 1에서 2로 증가한다면, 1.6배 속도를 향상시킬 수 있다.
코어 수와 처리 속도는 비례하지 않는다.
application에서 serial component가 없는 이상적인 경우라면(빨간색), 코어의 수에 비례해서 linear하게 처리 속도가 증가할 것이다. 하지만 serial component는 존재하고, 비율이 커질수록 코어 수에 따라 ideal하게 속도가 증가하지 않는다.
그래서, serial component가 적을수록 application에서 parallel하게 동작하기 좋은 것이다.
🔸User/Kernel threads
thread는 사용자/커널 수준에 따라 사용되는 종류가 다르다.
- User thread: 사용자 수준 라이브러리에서 thread를 제공하고 관리
- kernel의 thread를 할당 받아야 함 (kernel의 thread 위에서 지원됨)
- 주요 라이브러리: POSIX Pthreads, Window threads, Java threads, …
- Kernel thread: 커널(OS)에서 thread를 제공하고 직접 관리
- CPU가 kernel thread를 scheduling
- Window, Linux, Mac OS X, iOS, Andriod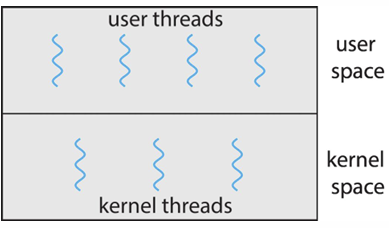
User thread와 Kernel thread의 mapping 관계에 따라 나뉘는 Multi-threading Model들은 아래와 같다
Many-to-One
- 많은 user thread가 하나의 kernel thread로 mapping
- 간단하고 효율적임
- 하지만, 한 kernel thread가 blocking되면, user thread들도 모두 blocking될 수 있음 → process 전체가 block
- 한 번에 한 thread만이 kernel에 접근할 수 있기 때문에 core가 많더라도 parallel으로 실행될 수 없음
- user space의 multi-thread가 multi-core시스템에서 parallel하게 실행될 수 없음
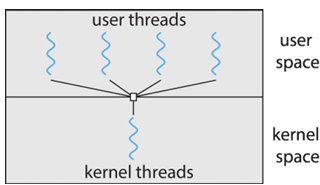
One-to-One
- 각 user thread가 하나의 kernel thread로 mapping
- 한 kernel thread가 blocking되더라도 다른 thread가 실행될 수 있음 → many to one 보다 더 많은 parallel
- 하지만, user thread를 생성할 때 그에 따른 kernel thread를 생성해야함 → overhead가 발생하여 application의 성능을 저하시킬 수 있음 (그래서 시스템에 의해 thread의 수 제한됨)
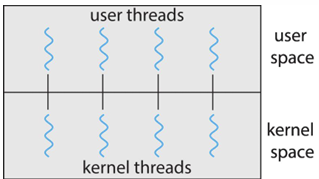
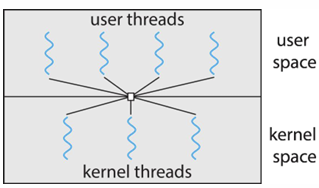
Many-to-Many
- 여러 개의 user thread가 그보다 작은 수 혹은 같은 수의 kernel thread로 multiplex
- kernel thread의 수는 OS나 application에 따라 결정
- 흔하진 않음!
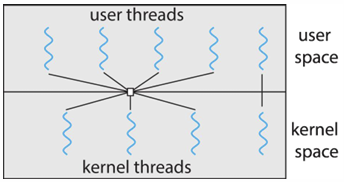
Two-level Model
- Many-to-Many와 One-to-One이 결합한 모델
🔸Thread Libraries
Thread library는 프로그래머에게 thread를 쉽게 생성하고 관리할 수 있는 API를 제공한다. 구현하는 데에는 크게 2가지 방법이 있다.
Implement
- user space에서 라이브러리 제공 (kernel 지원X)
- OS에 의해 지원되는 kernel-level 라이브러리 구현
Librarys & APIs
여러 thread library가 존재하고, 각 library는 프로세스 fork과정과 비슷하게 thread 관련 API를 제공한다.(생성, 기다림, 종료, …)
- POSIX Pthreads
- POSIX 표준, UNIX, Linux, Mac OS등에서 사용


- 만약 thread를 10개 만들었다면 10번 for문 돌아서 기다림..

- POSIX 표준, UNIX, Linux, Mac OS등에서 사용
- Windows


- JAVA
- Explicitly creating threads: thread class를 생성하거나, 수행할 interface 구현하거나 (후자가 일반적)


- Executor interface: thread pool을 미리 생성해두고, task가 생겼을 때 일 시킴 → 생성/수행 과정을 분리해서 유연성을 증가시키고 지연 시간을 줄임



- Explicitly creating threads: thread class를 생성하거나, 수행할 interface 구현하거나 (후자가 일반적)
🔸Implicit Threading
multi-core processing이 발전함에 따라,수백 또는 수천개의 Thread를 가진 application이 등장했다. 이에 따라 프로그래머가 직접 API를 사용해서 thread를 만드는 Explicit(명시적) threading에서 프로그램의 정확성을 유지하기가 어려워졌다. 이를 해결하기 위해 Implicit(암묵적) threading이 등장한다.
- Implicit Threading: Thread생성과 관리를 프로그래머가 아닌 compiler와 run-time libraries가 수행
- 프로그래머의 부담을 줄이고 코드의 복잡성 감소, 더 쉽게 multi-threading환경 구현 가능
Implicit threading을 사용해서 설계하는 5가지 방법
- Thread Pools
- Fork-join
- OpenMP
- Grand Central Dispatch
- Intel Threading Building Blocks
Thread Pools
- Thread pool은 미리 생성된 여러 thread가 작업을 기다리는 구조
- 새로운 thread를 생성하는 것보다 만들어둔 thread로 요청을 처리하는 것이 더 빠름
- Thread pool 크기에 맞춰 application 내의 thread 수를 제한할 수 있음 → 시스템 resource 효율적 관리(유연하게)
- 수행할 task와 task 생성을 분리하여 다양한 실행 전략 적용 (ex. 작업을 주기적으로 실행하도록 예약)
- Window, Java에는 thread pool을 지원하는 API가 존재
- Window

- Java


- Window
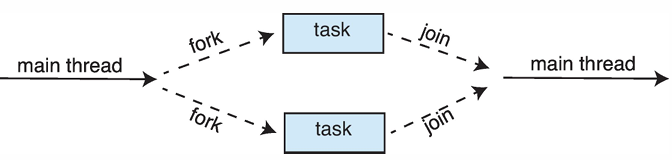
Fork-Join Parallelism
- 여러 thread(task)를 Fork한 후, 작업이 완료되면 다시 Join하여 결과를 얻는 방식
- task를 분할하여 병렬로 처리할 수 있음
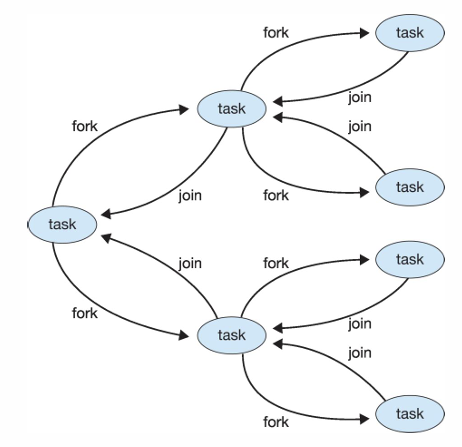
Fork-Join의 일반적인 알고리즘
- 작업이 충분히 작으면 바로 해결
- 그렇지 않다면 fork하여 subtask로 분할 → 병렬로 처리
- 모든 작업이 완료된 후 결과를 join하여(끝나기를 기다림) 결합

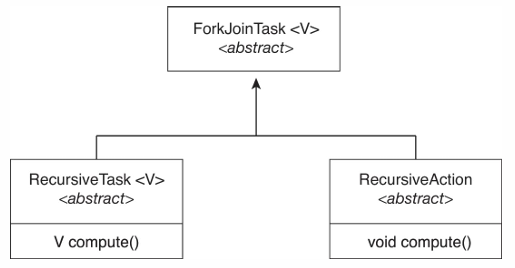
Fork-Join in Java
ex)리스트의 모든 값을 더하는 task가 있을 때, 리스트를 쪼개서 task 실행
- ForkJoinTask: abstract base class
- RecursiveTask: ForkJoinTask를 확장한 class
- task가 작으면(threadhold) 직접 계산하고, 크면 fork() → 재귀적으로
- join()한 최종 결과를 반환
- RecursiveAction: RecursiveTask와 같은 역할이지만 결과를 반환하지 않음

OpenMP
- C, C++, FORTRAN을 위한 컴파일러 directives(지시문)과 API의 집합
- shared-memory 환경에서의 parallel programming을 지원
- OpenMP는 병렬로 실행할 수 있는 코드 블록인 parallel regions를 식별
#pragma omp parallel: 컴파일러에게 Core 수만큼의 thread 생성해서 parallel하게 수행해달라는 directive → OpenMP가 별렬로 실행할 수 있는지 식별할 수 있도록 힌트를 주는 것
- 컴파일러가 parallel하게 loop를 실행할 수도 있음

Grand Central Dispatch
- MacOS 및 iOS를 위한 Apple 기술, [C, C++, objective-C]언어의 확장, API, runtime-library 제공
- GCD는 병렬로 실행할 수 있는 섹션을 식별해주고, 대부분의 thread 관련 사항 관리
- 블록은 “^{ }”으로 정의되며, 블록 안에 parallel하게 수행할 부분을 넣음 → OpenMP와 비슷하게, 블록을 통해 힌트를 주는 것

- 블록은 dispatch queue에 배치되며, 큐에서 제거된 블록은 thread pool의 thread에 할당 됨
- 블록은 “^{ }”으로 정의되며, 블록 안에 parallel하게 수행할 부분을 넣음 → OpenMP와 비슷하게, 블록을 통해 힌트를 주는 것
- Dispatch queue의 2가지 유형
- Serial Queue(직렬 큐): FIFO 순서대로 블록 제거, 프로세스 당 하나의 큐(main queue), 프로그래머가 추가적으로 생성 가능
- Concurrent Queue(병렬 큐): FIFO순서로 블록이 제거되지만 여러 블록이 동시에 제거될 수 있음
- Swift에서는
dispatch_async()API를 사용해 parallel한 영역을 지정하고 큐에 들어감- Swift에서는 task를 closure(block과 비슷한 개념)로 정의

- Swift에서는 task를 closure(block과 비슷한 개념)로 정의
Intel Threading Building Blocks
- parallel C++ 프로그램을 설계하기 위한 template libarary
- TBB를 사용한 parrallel_for 루프 (v array에 있는 task를 parallel하게 수행)
#include <tbb/tbb.h> // parallel_for(size_t(0), n, [=](size_t i) {apply(v[i]);}); tbb::parallel_for(0, N, [](int i) { // 작업 수행 });
🔸Threading Issues
Semantics of fork() and exec()
Multi-thread program에서는 의미가 달라질 수 있다.
- 만약, 한 프로그램의 Thread가 fork()를 호출하면, 새로운 프로세스는 모든 thread를 복제해야하는가? 아니면 호출한 thread만 복제해야하는가?
- exec() 또한 모든 thread가 새로운 task를 할 것인지, 하나의 thread만 일을 할 것인지
→ 몇 UNIX는 두 가지 버전의 fork()와 exec()를 모두 지원, Application 목적에 따라 설정
Signal handling
UNIX 시스템에서 Signal은 특정 이벤트가 발생했음을 프로세스에게 알리기 위해 사용한다. Signal은 software interrupt라고 생각할 수 있다.
- Signal 처리를 위한 signal handler가 존재
- 특정 이벤트에 의해 신호 생성
- 신호가 프로세스에 전달
- 신호는 두 가지 signal handler 중 하나에 의해 처리
- default
- user-defined
- 모든 신호는 kernel이 신호를 처리할 때 사용하는 default handler를 가짐
- user defined signal handler는 default handler를 오버라이드할 수 있음
- single-thread의 경우, 신호는 프로세스에 전달 됨
- multi-thread의 경우, 신호를 받을 thread를 설정할 수 있음
- 신호를 프로세스 내 모든 thread에 전달
- 프로세스 내 특정 thread에 전달
- 프로세스의 모든 신호를 수신할 특정 thread 지정
Thread Cancellation
thread가 완료되기 전에 종료하는 과정으로, 종료될 thread를 target thread라고 한다.
- Asynchrounous Cancellation(비동기적 취소): target thread를 즉시 종료
- Deffered Cancellation(지연 취소): target thread가 주기적으로 취소되어야하는지를 확인하고, 취소해도 되는 상태일 때 취소
- thread cancellation 요청을 호출해도, 실제 취소는 thread 상태에 달려있음

- 만약 thread에서 취소가 비활성화된 경우, cancellation은 이를 활성화할 때까지 기다림(pending)
- default는 deffered cancellation으로 설정되어있음
- thread가 cancellation point에 도달할 때만 취소가 발생
- ex) pthread_testcancel()
- Linux에서는 thread cancellation은 신호를 통해 처리됨
- Java에서는 interrupt() 메소드를 사용하여 thread의 interrupted status를 설정하고, thread는 interrupt되었는지 확인하며 cancellation을 실행


Thread-Local storage
Thread마다 독립적으로 가지는 storage가 있고, thread를 구분할 수 있는 데이터를 가진다.
- 각 thread가 자신의 데이터 복사본을 가질 수 있게 해줌
- Thread creation process를 제어할 수 없는 경우 유용 (ex. thread pool)
- thread에는 local variables을 담는 stack도 존재하는데, 이는 function을 호출하는 동안 존재하고 function이 끝나는 경우 사라짐
- 하지만 TLS는 function이 끝나도 사라지지 않음 → static data와 유사
Schedular Activations
kernel thread가 CPU나 core를 할당받아 동작하는 것처럼, user thread는 lightweight process(LWP)를 할당받아야 동작할 수 있다. lightweight process는 kernel thread마다 존재한다. → 계층구조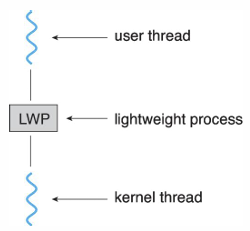
- 이러한 계층구조는 보통 상위 레이어에서 function을 call하고 하위 레이어에서 실행하여 상위 레이어에게 서비스를 제공
- 근데 Schedular Activation은 하위 레이어에서 상위 레이어를 호출할 수 있는 upcall을 제공
- kernel에서 thread library의 upcall hander로의 통신 메커니즘
- 이러한 통신을 통해 user thread와 kernel thread의 소통이 가능해짐
- ex) Many-to-Many모델과 two-level모델 모두 적절한 수의 kernel thread가 application에 할당되도록 유지하기 위한 통신이 필요
🔸OS Examples
각 OS에서 thread가 어떻게 구현되있는지를 알아본다.
Windows Threads
- Windows API는 kernel level에서 One-to-One mapping으로 구현되는 thread를 제공
- window의 Thread 구성요소
- thread ID
- 프로세서의 상태를 나타내는 register set
- user/kernel stack (thread가 user mode와 kernel mode에서 실행될 때 독립적인 스택을 가짐)
- private storage area (thread마다 독립적으로 가지는 공간)
-> 위 구성요소에서 ID를 제외하고, 동작하는 thread에서 변화하는 값으로 thread의 context를 의미 (context switching과정을 위해 저장해야하는 값)
- Thread를 관리하기 위한 window의 data structures
- ETHREAD(Executive Thread Block): thread 시작 주소, parent 프로세스의 포인터, KTHREAD에 대한 포인터를 포함 (in kernel space)
- KTHREAD(Kernel Thread Block): 스케줄링 및 동기화 정보, kernel stack, TEB에 대한 포인터를 포함 (in kernel space)
- TEB(Thread Environment Block): thread ID, user stack, thread-local storage를 포함 (in user space)
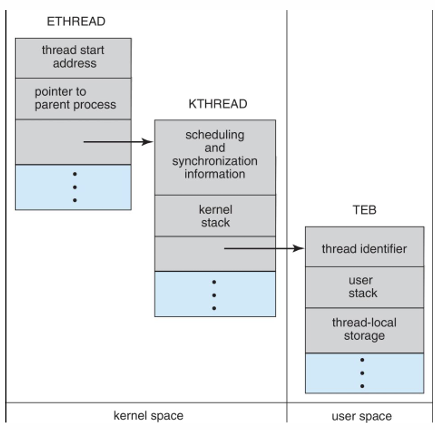
Linux Threads
- Linux에서는 thread를 task라고 나타냄
- thread는 clone() system call을 호출하여 생성
- clone()은 child task가 parent task(프로세스)의 주소 공간을 공유할 수 있도록 허용
- 다양한 flag를 통해 thread의 동작 제어 (parent task의 어디까지 공유받을 것인지)
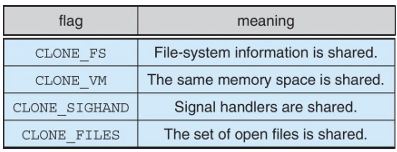
struct task_struct: 프로세스 데이터 구조
