
💡 5장 목표
- 스케줄링 유형 및 알고리즘
- 스레드 스케줄링
- 멀티 프로세서 스케줄링
- 실시간 스케줄링
- 운영체제별 예시
multi-programming의 목적은 CPU 이용률(Maximum CPU utilization)을 최대화하기 위해 항상 실행 중인 프로세스를 갖게 하는 것이다. 즉, 할 일이 있을 때 CPU가 무조건 일하게 하기 위해서 멀티 프로그래밍을 하는 것이다.
CPU-I/O Burst Cycle
- 프로세스 실행은 CPU 실행과 I/O대기의 Cycle로 구성
- CPU burst: CPU만 연속적으로 사용하는 것, CPU를 필요로 하는 부분?
- CPU burst로 시작하여 두 상태를 교대로 왔다갔다 하며 프로세스 실행
- CPU burst의 프로세스에 어떤 순서로 CPU를 할당할 것인지가 CPU scheduling
- 보통 CPU burst-time(CPU를 필요로 하는 시간)은 짧다. AI계산 등 몇몇 경우에 길기도 함
CPU Scheduler
CPU 스케줄러는 CPU를 필요로 하는 ready queue에 있는 프로세스 중 하나를 선택하여 CPU 코어에 할당한다. ready queue는 다양한 방식으로 정렬된다.
- CPU 스케줄링은 아래와 같은 상황에서 발생한다.
- 프로세스가 running state에서 waiting state로 바뀔 때 (I/O를 기다릴 때)
- 프로세스가 running state에서 ready state로 바뀔 때 (time sharing 등의 interrupt, 혼자 CPU를 독점하지 않도록)
- 프로세스가 waiting state에서 ready state로 바뀔 때 (I/O완료, 우선 순위 기다림)
- 프로세스가 terminates (작업 종료)
- 1, 4번은 CPU가 더이상 필요하지 않은 상태라서 CPU사용 권한을 넘긴다 → non-preemptive(비선점)
- 비선점 스케줄링: CPU를 사용 중인 프로세스의 CPU사용 권한을 강제로 빼앗지 않는다. 그 프로세스가 더이상 CPU가 필요없다고 하는 경우에만 권한을 가져온다. (그 프로세스는 계속 CPU 점유 가능)
- 2, 3번은 일울 다 마치지 못해 CPU가 필요하지만 일단 CPU 사용 권한을 넘긴다 → preemtive(선점)
- 선점 스케줄링: CPU를 사용 중인 프로세스의 CPU 사용 권한을 강제로 빼앗을 수 있다. (time sharing이나 우선 순위의 이유로)
- 성능이 좋지만, 아래와 같은 민감한 상황에서 위험할 수 있다.
- 공유 데이터에 접근, 커널 모드에서의 선점, 중요한 OS작업 중 인터럽트 발생 가능성 → race condtion 발생 가능
Dispatcher
CPU스케줄링에 의해 프로세스가 바뀔 때, 기존 프로세스의 정보는 저장하고 새로운 프로세스의 정보를 로드하는 작업
- switching context
- switching to user mode
- 프로그램을 다시 시작하기 위해 user program을 적절한 위치로 이동
dispatch가 소요되는 시간을 Dispatch latency라고 한다.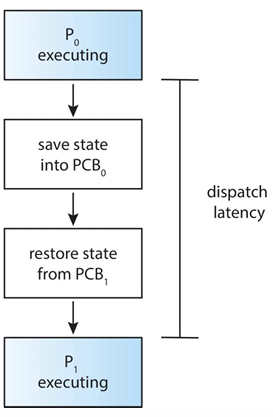
Scheduling Criteria
스케줄링 기준
- CPU 사용률(utilzation)
최대화- 가능한 한 CPU를 바쁘게 유지 시키기
- 처리량(Throughput)
최대화- 단위 시간 당 완료된 프로세스의 개수
- 총 처리 시간, 반환 시간(Turnaround time)
최소화- 특정 프로세스가 완료되는데 소요되는 시간
- 메모리에 들어가기 위해 기다린 시간 + ready queue에서 기다린 시간 + CPU에서 자신을 실행한 시간 + I/O시간
- 대기 시간(Waiting time)
최소화- ready queue에서 CPU를 기다린 총 시간
- 응답 시간(Response time)
촤소화- 처음으로 CPU를 할당 받을 때까지 기다린 시간 (waiting time과 다름)
🔹Scheduling Algorithm
1. First-Come, First-Served(FCFS) Scheduling
- 비선점형 알고리즘
- CPU를 먼저 요청하는 프로세스가 CPU를 먼저 할당받음
- FIFO Queue로 쉽게 관리, 구현 가능
- 공평하지만 상황에 따라 평균 대기 시간이 매우 길어질 수 있다.
만약 프로세스 3개가 아래와 같을 때,

프로세스가 P1, P2, P3 순서로 도착했다면, P1의 대기시간은 0ms, P2는 24ms, P3는 27ms이다. (평균 대기 시간 17ms)
프로세스가 P2, P3, P1 순서로 도착했다면, P1의 대기시간은 6ms, P2는 0ms, P3는 3ms이다. (평균 대기 시간 3ms)
- 이처럼 다른 프로세스들이 하나의 긴 프로세스를 기다리는 것을 호Convoy effect라고 한다.
- 이 효과로 인해 짧은 프로세스들이 먼저 처리되도록 허용될 때보다 CPU와 장치 이용률이 저하되는 것이다.
2. Shortest-Job-First(SJF) Scheduling
- 비선점형이거나 선점형일 수 있다.
- 선점형이면 shortest-remaining-time-first algorithm (아래 예시 있음)
- CPU burst time이 가장 작은 프로세스를 먼저 CPU에 할당
- 평균 대기 시간이 가장 작은 알고리즘
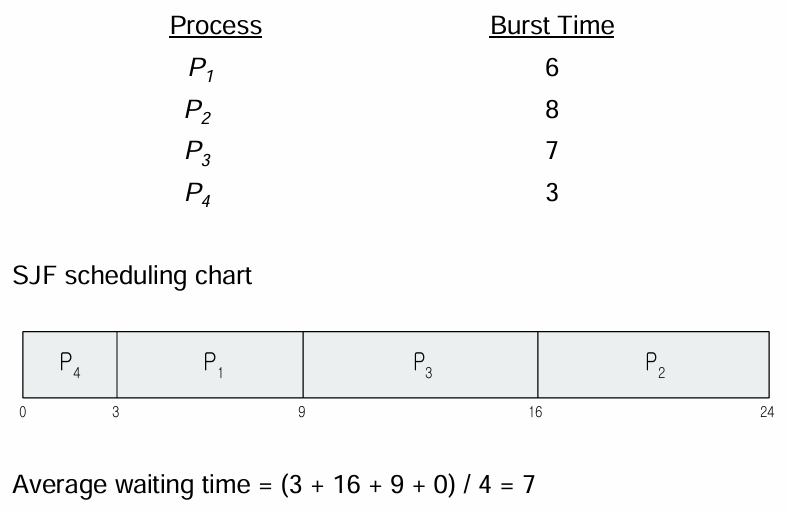
- 하지만, 다음 CPU burst time을 미리 아는 것이 어려움
Next CPU Burst 길이 추정하기
- 다음 CPU 버스트 길이를 정확히 알 수 없으므로, 이전 버스트와 유사할 것으로 추정한다.
- 이전 버스트들의 값을 평균내는데, 최근 버스트에 더 큰 가중치를 두는 지수 평균(exponential averaging)을 사용한다.
- 한 단계만 떼어 보면, 실제 이전 버스트와 추정한 이전 버스트 값을 평균내서 다음 버스트 값을 추정

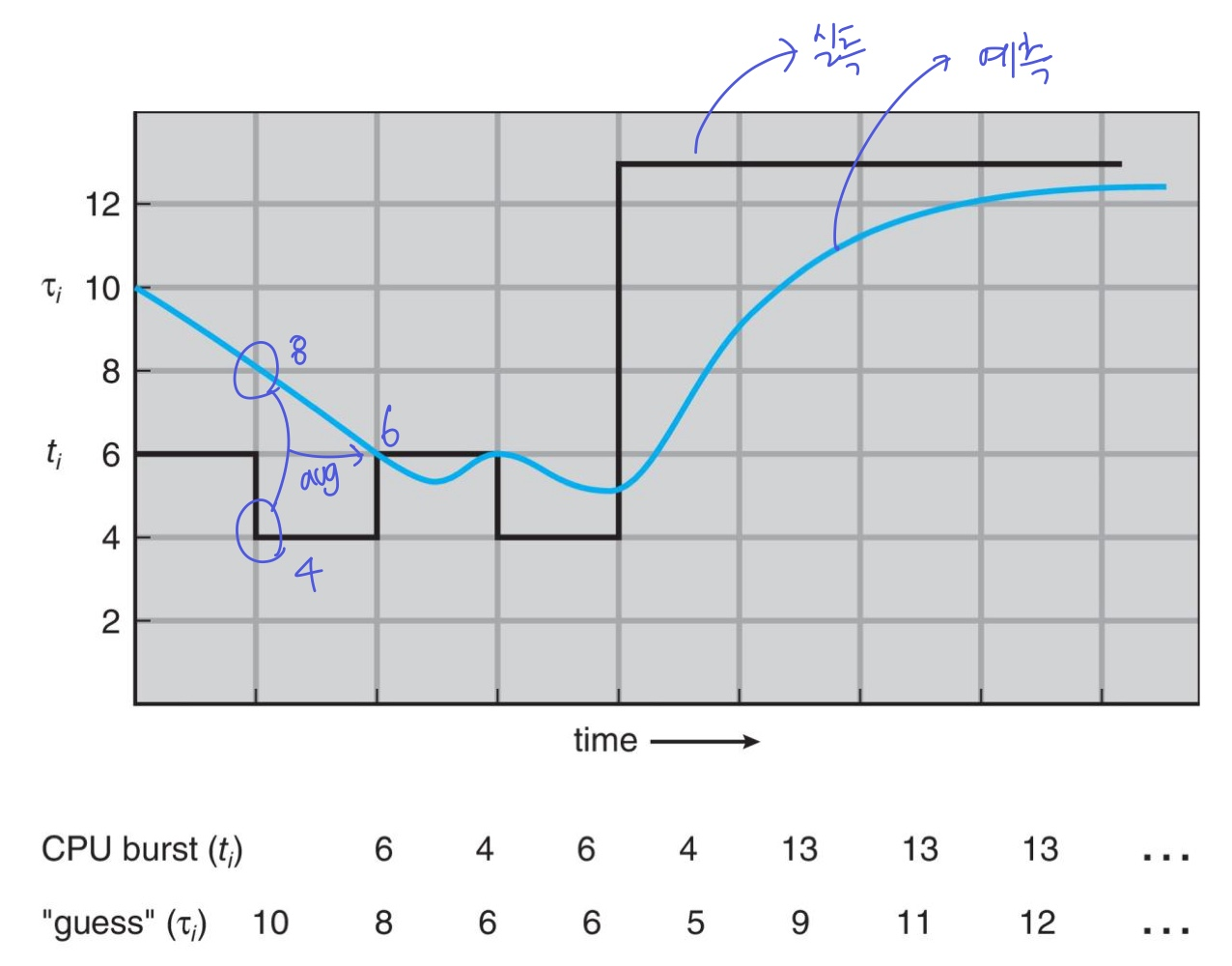
- 전체적으로 보면, 최근 버스트에 더 큰 가중치를 두는 모습

- 한 단계만 떼어 보면, 실제 이전 버스트와 추정한 이전 버스트 값을 평균내서 다음 버스트 값을 추정
shortest-remaining-time-first algorithm (선점형)
- 비선점형이 비효율적이어서 나온 방법
- 수행 하다가 남은 burst보다 더 짧은 burst를 가진 프로세스가 있으면 권한 넘김

3. Round-Robind(RR) Scheduling
- time-sharing system
- 시간 조각(time quantum)이라고 하는 작은 단위의 시간을 정의하여 사용 (보통 10-100ms)
- ready queue는 circular queue로 동작하며, CPU스케줄러는 ready queue를 돌면서 한 번에 한 프로세스에세 한 번의 시간 조각 동안 CPU를 할당
- ready queue에 n개의 프로세스, time quantum이 q일 때
- 각 프로세스는 1/n 비율로 CPU 시간을 할당받고, 하나의 실행에서 최대 q시간 단위까지 사용 가능
- 할당 받은 한 프로세스를 제외한 나머지 기다리는 프로세스는 n-1개이므로, 최대 (n-1)q시간을 기다린다
- 각 time quantum이 끌날 때마다 타이머가 인터럽트를 발생시켜 다음 프로세스를 스케줄링
성능
- q가 너무 크면 → FCFS와 유사
- q가 너무 작으면 → 기다리는 (n-1)q시간은 줄어들지만, context switch의 오버헤드가 너무 커짐 (context switch가 너무 많이 발생)
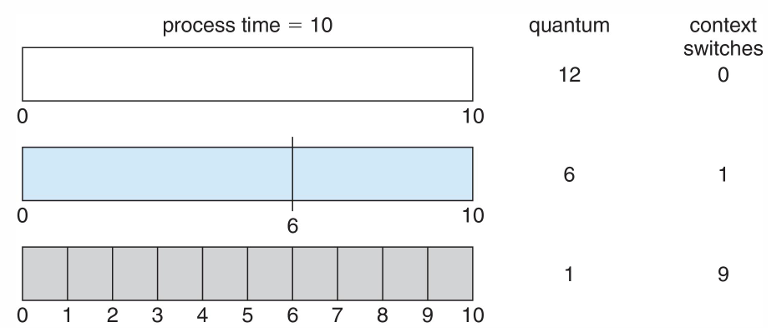
- RR의 단점은 q에 따른 turnaround time인데, 운이 좋아서 time quantum에 맞게 일이 끝나면 turnaround time이 짧을 순 있지만 그만큼 길어질 수도 있다. 일정하지 않다
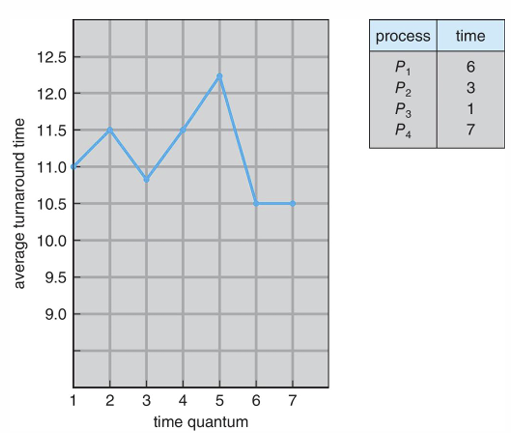
→ RR은 time quantum의 크기에 매우 많은 영향을 받는다.
- context swich < 10 usec가 되도록 q를 적당히 정해야 함
- 보통 time quantum은 context switch 시간에 비해 충분히 커야하고, CPU burst의 80%는 time quantum보다 짧아야 한다.
q=4일 때,
- SJF보다 turnaround time(30)이 길지만, response time(11)은 짧다

Priority Scheduling
- 위의 3가지 방식들처럼 각 프로세스는 우선 순위를 가진다.
- 가장 높은 우선 순위를 가진 프로세스에게 CPU 할당

주요 문제 - Starvation
- 낮은 우선 순위를 가진 프로세스들이 CPU를 무한히 대기(starvation)할 수도 있다
- 이를 해결하기 위해 Aging → 오랫동안 시스템에서 대기하는 프로세스들의 우선순위를 점진적으로 높이거나, CPU할당을 많이 받은 프로세스의 우선순위를 점진적으로 낮추기
우선 순위가 같은 경우 → RR
- 우선 순위가 같은 프로세스를 RR로 해결 (q=2ms)

Multilevel Queue Scheduling
- priority scheduling에서, 우선 순위에 따라 ready queue를 그룹으로 분리
- 높은 우선순위를 가진 그룹 먼저 수행
- 각 queue들은 자신의 스케줄링 알고리즘을 가질 수 있다
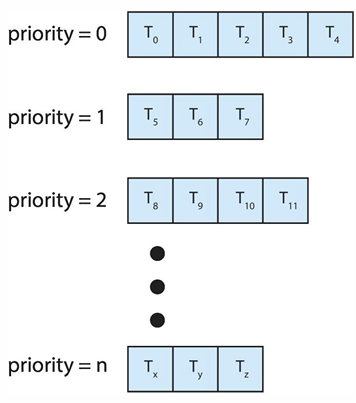
- 우선순위는 프로세스 타입에 따라 결정
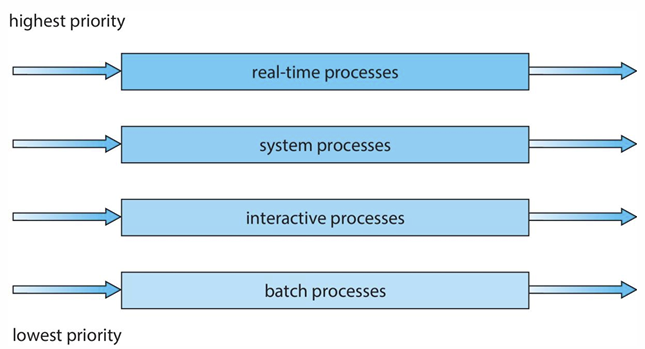
원래는 한 큐가 끝날 때까지 수행하는데, Feedback을 사용하여 여러 queue 사이에서 이동하며 수행할 수 있다.
- Aging을 구현하는데 사용될 수 있다.
- 각 프로세스의 CPU 사용 패턴에 따라 동적으로 우선순위를 조절
주요 파라미터
- queue의 수
- 각 queue의 스케줄링 알고리즘
- 프로세스가 높은 우선 순위 queue로 이동하는 조건(upgrade)
- ex) 프로세스가 특정 시간 동안 CPU를 사용하지 않거나, 특정 작업 완료할 때
- 프로세스가 낮은 우선 순위 queue로 이동하는 조건(demote)
- ex) 프로세스가 특정 시간 이상 CPU를 점유하거나, 자원을 과도하게 사용할 때
- 서비스가 필요한 프로세스가 들어갈 queue를 결정하는 방법
- 새로운 프로세스가 어떤 queue에 배치될지를 결정
3개의 큐(RR(8ms), RR(16ms), FCFS)가 있는 경우 (높은 우선순위 순)
- 새로운 프로세스가 Q0에 들어와서 CPU를 할당받으면 8ms동안 실행
- 만약 8ms 내에 작업이 완료되지 않으면 해당 프로세스는 Q1으로 이동
- Q1에서 16ms내에 작업이 완료되지 않으면 해당 프로세스는 선점(preempted)되어 Q2로 이동
- Q2에서 FCFS으로 처리 (가장 낮은 우선 순위)
짧은 작업을 우선으로 끝내고, 한 큐에서 다 끝나지 않는 작업은 다음 우선순위의 큐로 나머지 작업들을 넘김(demote)
→ 짧은 작업에 높은 우선순위를 두는 방법(SJF과 유사)이며, 다양한 알고리즘 방법을 융합하여 사용할 수 있는 장점을 가짐

🔹Thread Scheduling
프로세스 안에는 여러 스레드가 존재할 수 있다.
유저 레벨 스레드와 커널 레벨 스레드 사이는 Light Weight Process(LWP)라는 경량 프로세스가 있다. 커널마다 존재하는 LWP는 many-to-one과 many-to-many 모델에서 유저 레벨 스레드를 커널 레벨 스레드에 매핑하는 역할을 한다
- 이 때, 한 프로세스에 있는 여러 유저 레벨 스레드에 중 한 스레드를 LWP를 할당하기 위해 스케줄링하는게 process-contention scope(PCS)이다.
- 더 나아가, 커널 레벨 스레드에 CPU를 할당하기 위해 스케줄링 하는게 system-contention scope(SCS)이다. → 이는 PCS와 다르게 한 프로세스가 아닌 모든 시스템 차원에서 경쟁
스레드를 만들 때 PTHREAD_SCOPE_PROCESS 또는 PTHREAD_SCOPE_SYSTEM라는 스코프 옵션을 제공하는 API를 사용하여 스레드 스케줄링 방식을 정할 수 있다.
-
Linux와 macOS는 PTHREAD_SCOPE_SYSTEM만 지원한다


🔹Multiple-Processor Scheduling
- Multiple-processor는 CPU가 여러개인 경우이다
- Multicore processor는 한 CPU 내에 코어가 여러개인 경우로, compute cycle과 memory access일을 돌아가면서 수행한다.
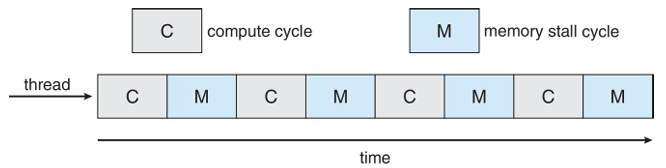
- 여러 CPU/core가 한 개의 ready queue를 공유하거나, 각자의 ready queue를 가질 수 있다.
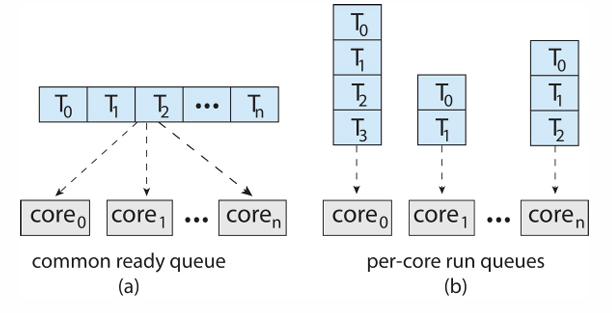
- 여러 CPU/core가 한 개의 ready queue를 공유하거나, 각자의 ready queue를 가질 수 있다.
Multithreaded Multicore system
Multithreaded multicore는 한 코어 내에 하드웨어 스레드가 여러개인 경우로, 한 스레드가 compute cycle할 때 다른 스레드가 memory access를 동시에 수행할 수 있다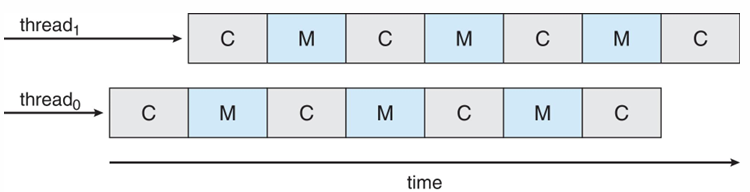
위와 같이 1개의 CPU 내에 여러 코어, 여러 스레드를 가지는 구조를 Chip-multhtreading(CMT)라고 하며, 소프트웨어 입장에서는 8개의 CPU를 사용하는 것과같은 효과를 가질 수 있다.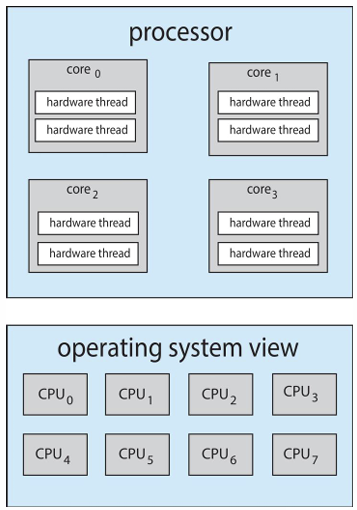
위에서 소프트웨어 내의 스레드 스케줄링에 대해 봤는데, 하드웨어 스레드가 추가되면서 스케줄링 단계가 하나 더 추가됐다.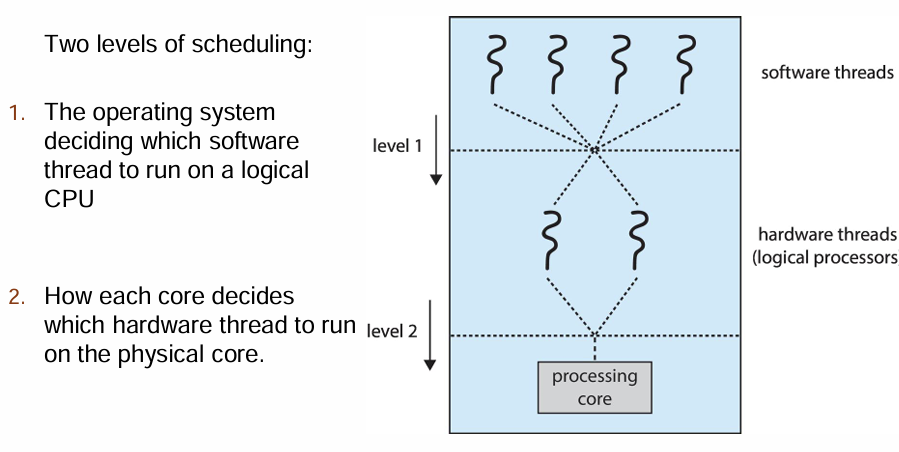
Load balancing
SMP(symmetric multiprocessing; CPU마다 같은 역할)이라면, 모든 CPU가 공평하게 일을 분배 받아야 한다. 이것이 Load balancing
공평하지 않다면, 아래와 같은 migration을 진행
- Push migration: 일부 CPU만 일이 많은 경우, 일이 적은 CPU로 일을 보냄
- Pull migration: 일부 CPU만 일이 적은 경우, 일이 많은 CPU로 부터 일을 받아옴
Processor Affinity
CPU가 여러개일 때, 어떤 작업이 어떤 CPU에 적합한지(친밀, affinity)
- Soft affinity: 이전에 일했던 CPU → 캐시가 남아있어 성능에 도움이 될 수 있다.
- Hard affinity: 하드웨어적으로 작업이 잘 맞는, 성능이 좋은 CPU
NUMA and scheduling
메모리마다 접근 시간이 다르다는 NUMA를 고려하여 CPU를 할당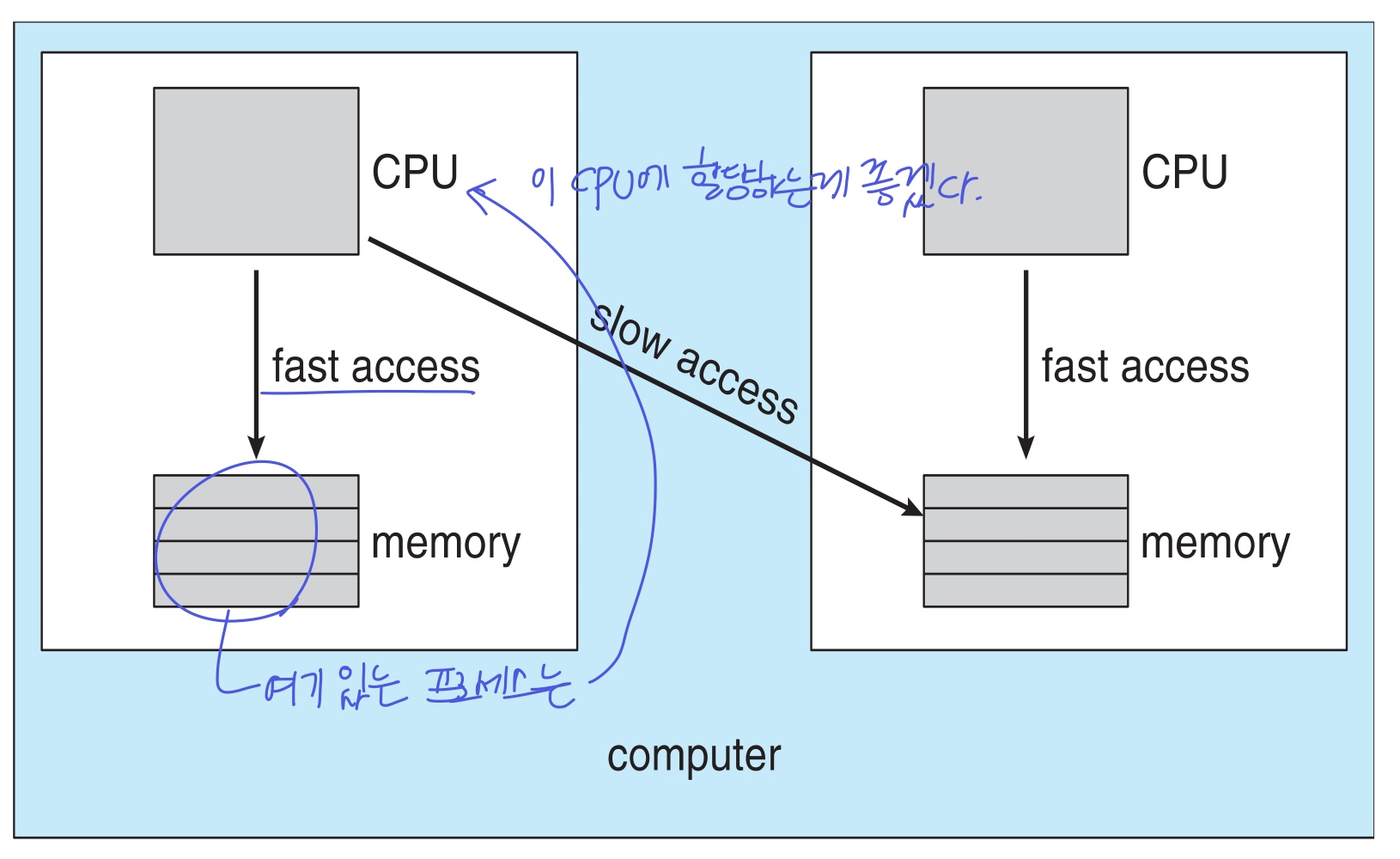
🔹Real-Time CPU Scheduling
빨리 수행하는 것이 아닌, 특정 기한(Dead line)내에 작업을 완료했는지가 성능을 나타낸다.
- Soft real-time system: dead line 내에 작업을 완료하지 못해도 나머지 작업을 수행하긴 한다. 하지만 성능이 떨어지고 스케줄링이 보장되지 않는다.
- Hare real-time system: 작업이 반드시 dead line 내에 완료되어야 하며, 그렇지 않은 나머지 작업은 수행되지 않는다.
Event Latency
Interrupt, Dispatcher 등과 같은 이벤트를 기다리고 수행하는 시간은 실시간 시스템에 큰 영향을 미친다. 이를 알면 dead line 내에 수행 가능한지 알 수 있기 때문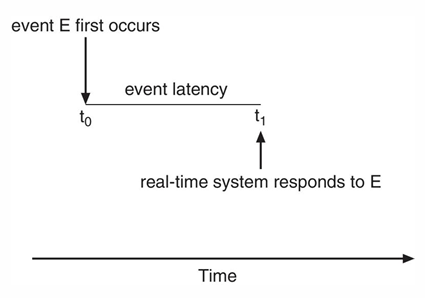
이벤트를 기다리고 수행하는 시간은 Event latency라고 하며, 두가지 종류가 있다.
1. Interrupt Latency: 인터럽트가 발생한 순간부터 인터럽트를 처리하는 루틴(ISR, interrupt service routine)이 시작될 때까지 걸리는 시간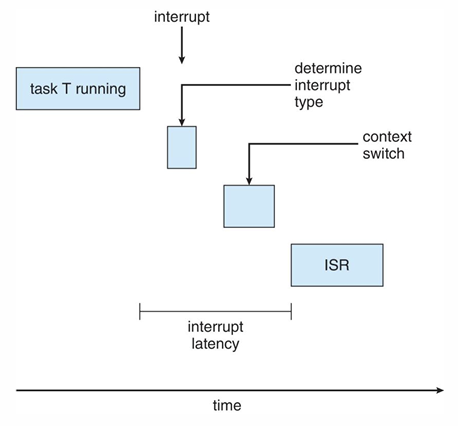
2. Dispatch latency: 현재 프로세스를 CPU에서 제거하고, 다른 프로세스로 스위치하는데 걸리는 시간
- Conflict phase(충돌 단계): 낮은 우선순위의 프로세스가 특정 리소스를 독점하고 있을 때, 해당 리소스를 사용하기 위해 높은 우선순위의 프로세스가 기다리게 되는 시간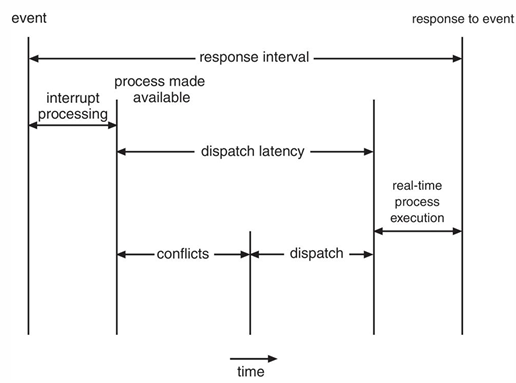
Priority-Based Scheduling
실시간 스케줄러는 선점적(preemptive) 우선순위 기반 스케줄링을 지원해야한다. (실시간 프로세스가 CPU를 필요로 할 때, 바로 응답해주는 것)
하지만 soft real-time만을 보장하며, hard real-time을 위해서 주어진 기한 내에 처리할 수 있는 능력을 제공해야한다.
Perodic Process → Periodic Job
(위에서 본 event 작업 이외에는) 일정한 간격으로 CPU를 필요로 하는 주기적 프로세스가 존재한다.
- process time(cpu brust) t, deadline d, period p
- 0 ≤ t ≤ d ≤ p
- 주기적 작업의 비율 rate = 1/p → 얼마나 자주 실행되는지를 나타냄
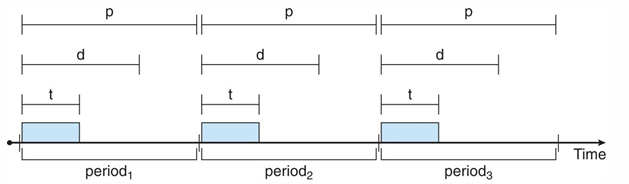
1. Rate Montonic Scheduling
- 주기가 짧은 프로세스가 우선 순위를 가짐 (자주 수행되므로)
아래와 같은 두 개의 프로세스가 있는 경우 (deadline은 주기와 같음)
만약, 우선순위가 지켜지지 않아 P2가 먼저 실행되면, 스케줄러는 P1의 기한을 지키지 못한다. (50을 넘음)
우선순위에 따라 P1이 먼저 실행되면, P1이 작업을 마치고 P2가 실행된다. P2는 35 중 30만 작업을 완료하지만, P1의 주기가 돌아와 선점된다. P1이 끝나면 P2가 이어서 실행되고 나머지 작업 5를 마친다. → 두 프로세스는 75에 완료되고 다시 반복하기 전 25가 유휴상태가 된다.



- non-optimal: 최적의 기법이긴 하지만, CPU이용률에 한계가 있기 때문에 CPU자원을 최대화해서 사용하는 것은 불가능하다.
- Deadline miss: 만약 P2의 주기와 기한이 80이라면, P2는 기한 내에 작업을 마치지 못한다.

2. Earliest Deadline First(EDF) Scheduling
- deadline이 이른 프로세스가 우선 순위를 가짐 (동적으로)
50에서 P1의 한 주기가 끝났고, 이제는 P2의 deadline이 더 빠르게 때문에 P2가 우선 순위를 가져 60까지 P2 수행

- deadline miss 없음, Optimal함 → reatime scheduling에서 최적의 방법
- Rate-Monotonic 스케줄링보다 유휴시간이 적지만, ready queue에 프로세스가 들어올 때마다 deadline을 확인해야 해서 overhead가 크다.
3. Proportional Share Scheduling
프로세스에게 CPU 시간을 공정하게 할당하기 위해, 스케줄러는 시간을 쪼개서 각 프로세스에게 분배
- 총 공유 수 T: 시스템의 모든 프로세스가 사용할 수 있는 CPU시간의 총 합
- 프로세스에 할당된 공유 N: 각 프로세스는 T중에서 N을 할당받는다 (N < T)
- 각 프로세스는 N/T 비율만큼 CPU 시간을 할당받는다.
T=100이고, 3개의 프로세스 A, B, C에게 각각 50, 15, 20씩 할당한 경우 → A는 CPU시간의 50%, B는 15%, C는 20%를 할당받는다. A는 50%의 CPU를 독점하는 것이다.
POSIX (API)
우선 순위가 같은 경우 FIFO 또는 RR 알고리즘을 사용한다.
스레드를 만들 때, POSIX API를 통해 SCHED_FIFO 또는 SCHED_RR 옵션을 지정할 수 있다


❗일반적으로 Real-time 테스크가 non Real-time 테스크보다 더 높은 우선순위를 가진다. (아레 운영체제들의 공통 내용)
🔹OS examples
1. Linux
- 2.5버전 이전
- 선점형 및 우선순위 기반
- 우선순위 범주는 time-sharing과 real-time로 나눠짐
- 0~99는 real-time, 100~140은 nice value
- real time이 더 높은 우선순위를 가진다
- nice value는 낮은 우선 순위로 다른 프로세스에게 nice하다는 것이다
- RR방법을 사용하여, 높은 우선순위는 긴 time quantum을 할당받는다
- 할당 받은 시간을 다 못쓰면 active, 다 쓰면 expired
- 테스크는 CPU마다 가지는 Runqueue 자료 구조를 track
- active, expired 두 그룹의 배열
- active가 더이상 없으면, 두 배열 바뀜
- 위와 같은 방식으로 우선순위가 낮아도 기회가 오는데, interrupt 반응 시간이 느리다는 단점
- 2.6.23버전 이상
- 프로세스마다 우선순위 레벨(class) 배정
- default, realtime, … 등
- 각 레벨끼리는 독립적
- 스케줄러는 높은 우선 순위의 레벨과 높은 우선 순위의 테스크를 선택
- target latency로 모든 프로세스가 한 번의 기회는 가지도록, 공평성
- vruntime: 각 테스크의 vruntime을 유지하여 우선 순위에 따른 감소율 decay factor를 적용
- vruntime은 얼마나 cpu 시간을 할당 받았는지를 나타낸다. 할당을 많이 받을수록 높은 우선순위를 가졌다는 것을 알 수 있다. (vruntime이 크면 높은 우선 순위)
- vruntime이 크면 작은 decay factor를 적용하여 vruntime이 조금씩 줄어들도록 한다. 즉, 우선순위가 조금씩 떨어진다.
- vruntime이 작으면 큰 decay rate?를 적용하여 vruntime이 빠르게 증가하도록 한다. 즉, 우선순위를 크게 높인다.
- 트리 형식으로 vruntime을 나타내면 아래와 같고, 가장 오른쪽에 낮은 우선순위의 테스크가 배치된다.
- n개의 노드가 있을 때, vruntime이 가장 작은 노드를 찾는데 log(n)시간이 걸린다. 근데 보통 포인터를 쓴다 함
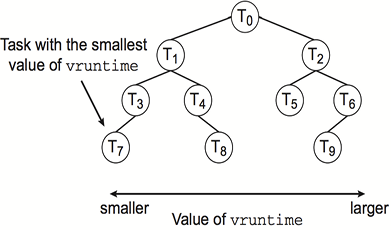
- n개의 노드가 있을 때, vruntime이 가장 작은 노드를 찾는데 log(n)시간이 걸린다. 근데 보통 포인터를 쓴다 함
- vruntime은 얼마나 cpu 시간을 할당 받았는지를 나타낸다. 할당을 많이 받을수록 높은 우선순위를 가졌다는 것을 알 수 있다. (vruntime이 크면 높은 우선 순위)
- 우선순위 영역 존재

- load balancing 및 numa를 인지하고, 코어가 빠르게 사용할 수 있는 메모리 공간과 함께 scehdling domain을 지정
- 웬만하면 domain 안에서만 움직여서 캐시 효과를 극대화하고 속도 저하를 최소화
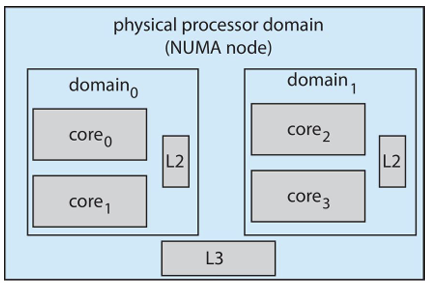
- 웬만하면 domain 안에서만 움직여서 캐시 효과를 극대화하고 속도 저하를 최소화
- 프로세스마다 우선순위 레벨(class) 배정
2. Window
- 32레벨의 우선순위 class REALTIME_PRIORITY_CLASS
HIGH_PRIORITY_CLASS
ABOVE_NORMAL_PRIORITY_CLASS
NORMAL_PRIORITY_CLASS
BELOW_NORMAL_PRIORITY_CLASS
IDLE_PRIORITY_CLASS
- 각 class 마다 상대적인 우선순위를 정할 수 있는 값도 가진다. TIME_CRITICAL
HIGHEST
ABOVE_NORMAL
NORMAL (얘가 기본)
BELOW_NORMAL
LOWEST
IDLE
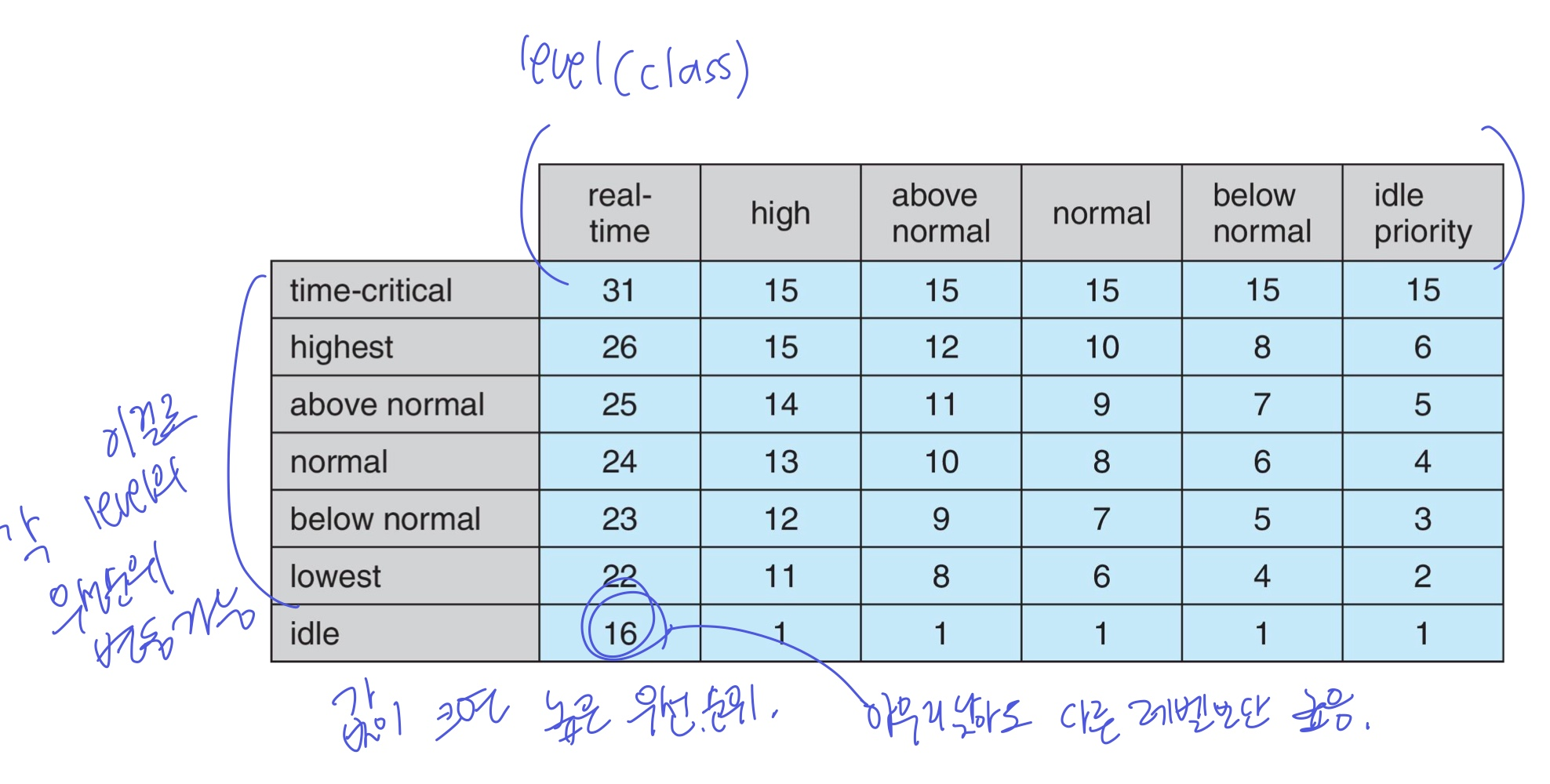
- CPU를 사용하지 않는 wait 상태에서는 우선순위가 낮아지고, ready로 가야 우선순위가 높아진다.
- forground window(전경 창)은 3배의 우선순위 부스트
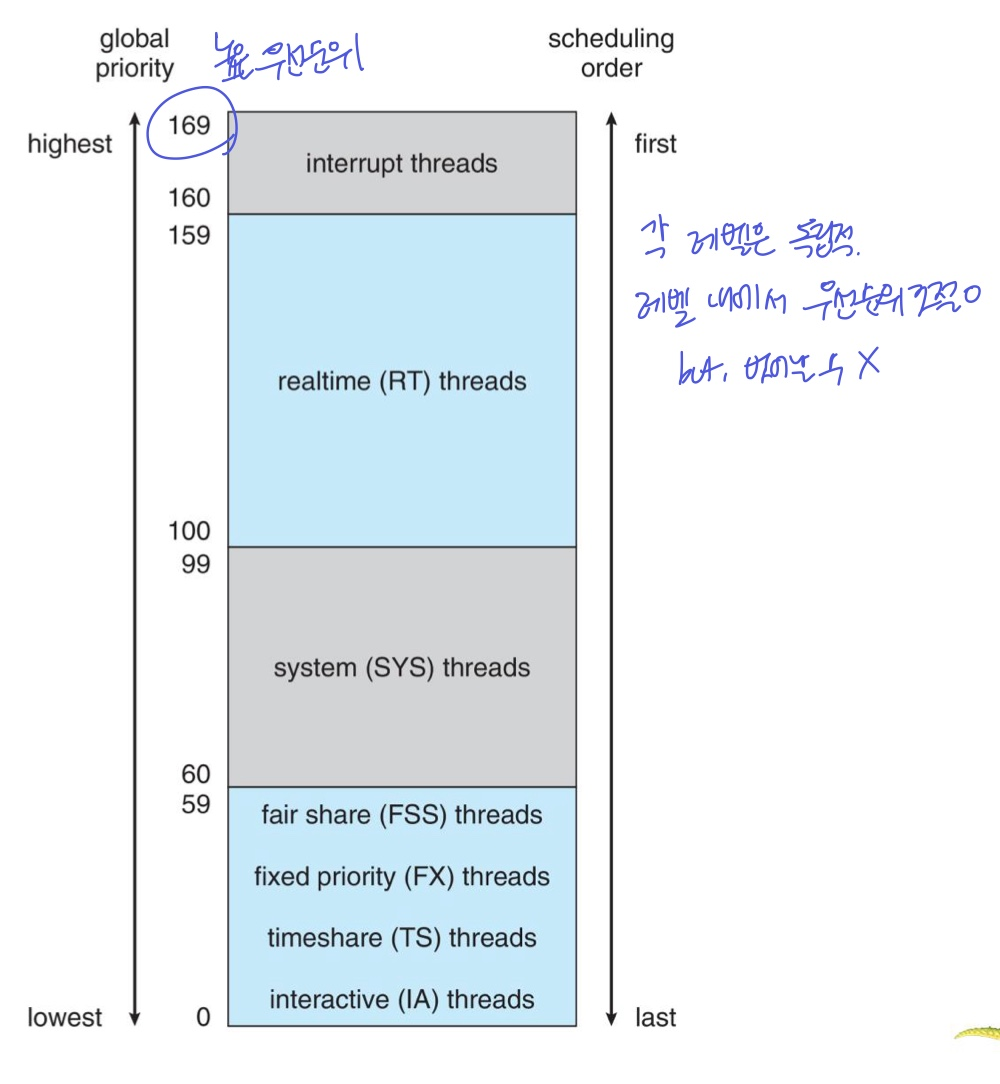
3. Solaris
- 역시나 얘도 우선순위 class를 가진다. 시간 공유(Time Sharing, TS): 기본, multi-level feedback queue
대화형(Interactive, IA)
실시간(Real Time, RT)
시스템(System, SYS)
공정 공유(Fair Share, FSS)
고정 우선순위(Fixed Priority, FP)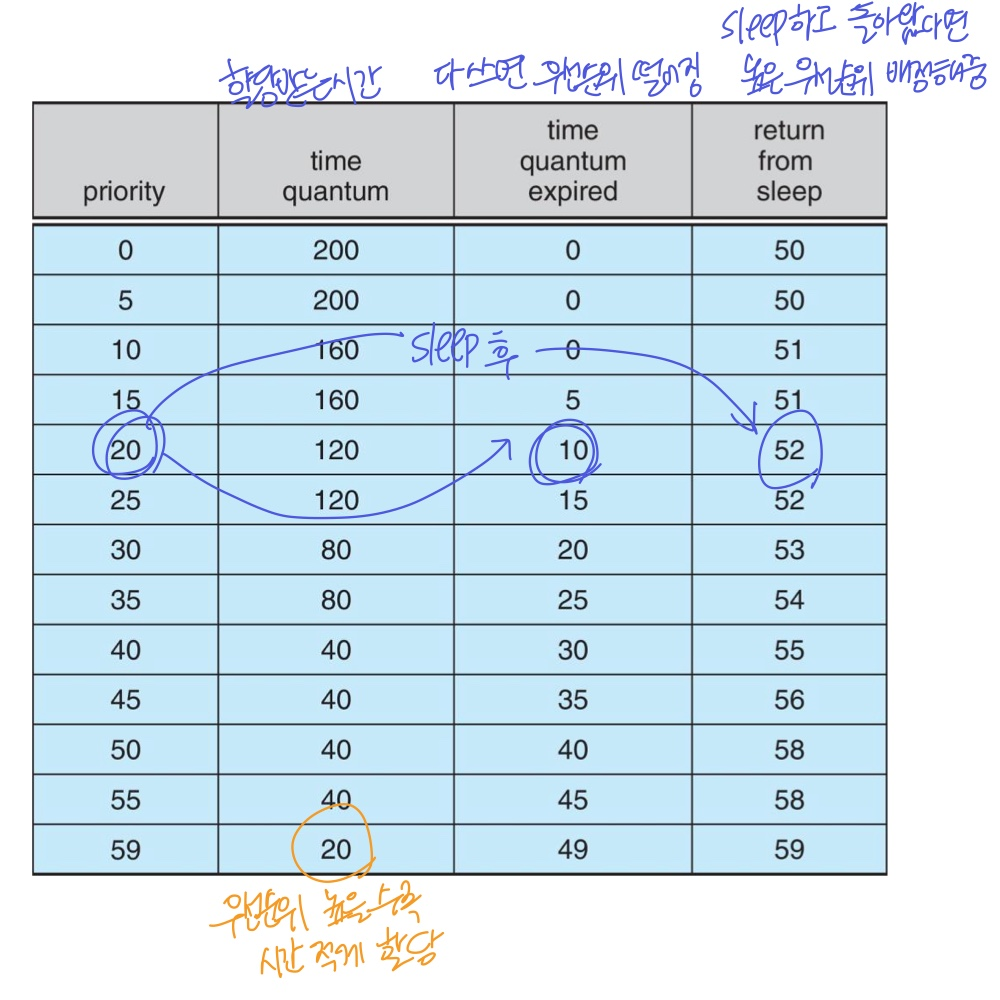
Algorithm Evaluation
운영체제마다 디테일한 알고리즘이 다르며, 이를 평가하기 위한 다양한 방법들이 존재한다.
- Deterministic modeling
- 정해진 입력값으로 성능을 측정, 수치적 계싼
- Queueing Models
- queue가 서버에 연결되어 서비스 받기를 기다리는 모델 (마치 ready queue가 CPU 할당을 기다리는 것 처럼)
- 확률 분포로 성능을 평가
- Little’s formula
- Queueing model에서 n = ʎ x W 라는 이론
- 큐의 길이, 대기 작업 개수 n
- 서비스 받기까지 기다린 시간 W
- 1초에 큐에 도착하는 프로세스 개수 ʎ
- 만약 1초에 7개가 도착하고, 큐에 평균적으로 17개가 있다면 2만큼 기다릴 것이다.
- Queueing model에서 n = ʎ x W 라는 이론
- Simulation
- 시뮬레이션을 위한 데이터는 랜덤/계산/실측값 을 사용
- Implementation
- 실제 구현, 정확하지만 구현 비용이 발생
