
EMR
EMR이란?
Amazon EMR은 Apache Spark, Apache Hive 및 Presto와 같은 오픈 소스 프레임워크를 사용하여 페타바이트급 데이터 처리, 대화식 분석 및 기계 학습을 위한 업계 최고의 클라우드 빅 데이터 솔루션입니다.
- EMR은 "Elastic MapReduce"를 나타냅니다.
- EMR은 Hadoop 클러스터(빅 데이터)를 생성하여 방대한 양의 데이터를 분석하고 처리하는 데 도움이 됩니다.
- 클러스터는 프로비저닝해야하며, 수백 개의 EC2 인스턴스로 구성될 수 있습니다.
- EMR은 Apache Spark, HBase, Presto, Flink...와 함께 번들로 제공됩니다.
- EMR이 모든 프로비저닝 및 구성을 처리합니다.
- Auto Scaling 및 Spot 인스턴스와 통합
- 사용 사례: 데이터 처리, 기계 학습, 웹 인덱싱, 빅 데이터...
Amazon EMR – Node types & purchasing
- 마스터 노드: 클러스터 관리, 조정, 상태 관리 - 장기 실행
- 코어 노드: 작업 실행 및 데이터 저장 - 장기 실행
- 작업 노드(선택 사항): 작업을 실행하기 위한 용도 – 일반적으로 Spot
- 구매 옵션:
- 온디맨드: 신뢰할 수 있고 예측 가능하며 종료되지 않음
- 예약형(최소 1년): 비용 절감(사용 가능한 경우 EMR이 자동으로 사용)
- 스팟 인스턴스: 저렴하고 종료될 수 있으며 안정성이 떨어짐
• 장기 실행 클러스터 또는 예약, 임시(임시) 클러스터를 가질 수 있습니다.
Amazon QuickSight
Amazon QuickSight란?
Amazon QuickSight는 아마존이 제공하는 서버리스 매니지드 BI 상품입니다. 특정 데이터에 대한 시각화 대시보드를 생성하고 다른 사용자와 공유할 수 있습니다.
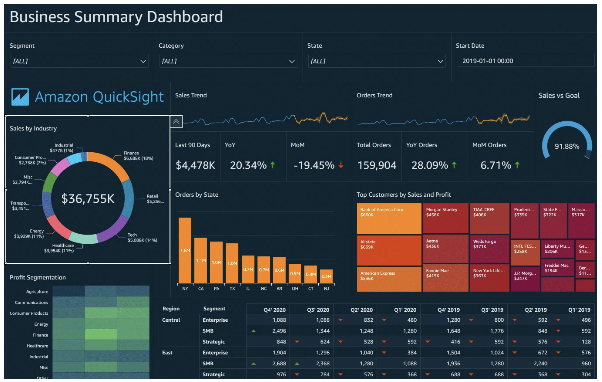
- 대화형 대시보드 생성을 위한 서버리스 기계 학습 기반 비즈니스 인텔리전스 서비스
- 세션당 가격으로 빠르고 자동으로 확장 가능하며 웹사이트에 삽입가능합니다.
- 사용 사례:
- 비즈니스 분석
- 시각화된 구현
- 임시 분석 수행
• 데이터를 사용하여 비즈니스 인사이트 얻기
• RDS, Aurora, Athena, Redshift, S3와 통합...
• 데이터를 QuickSight로 가져온 경우SPICE 엔진을 사용한 인메모리 계산
• Enterprise 버전:열 수준 보안(CLS) 설정 가능
QuickSight Integrations
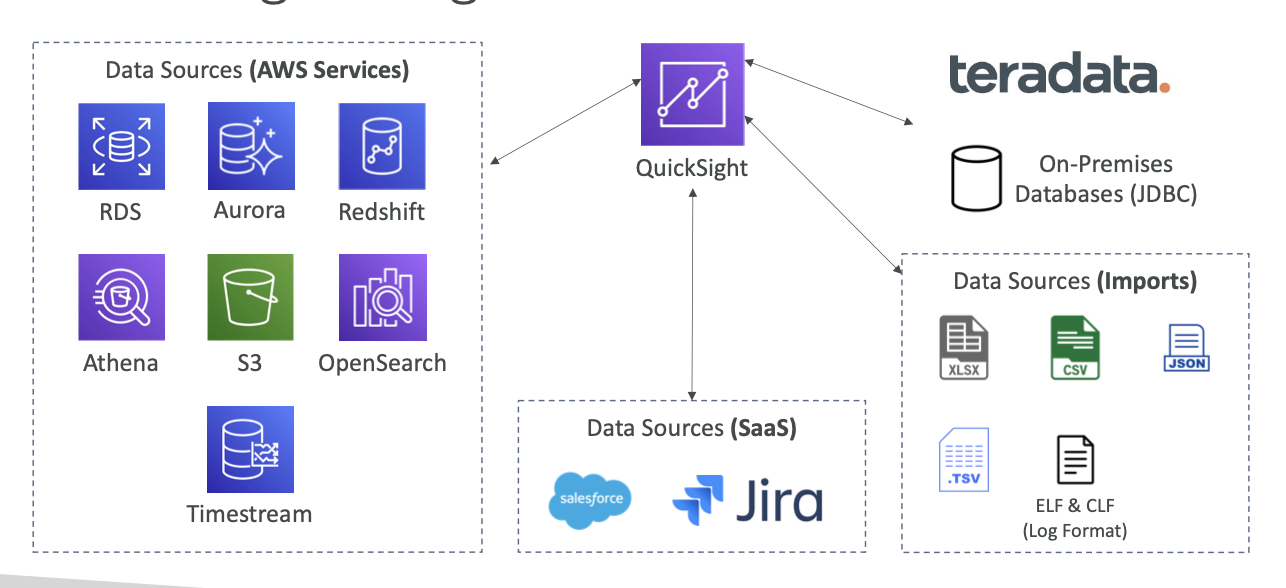
QuickSight – Dashboard & Analysis
- 사용자(표준 버전) 및 그룹(엔터프라이즈 버전) 정의
- 이러한 사용자 및 그룹은 QuickSight 내에만 존재합니다!!
(IAM이 아님)
- 이러한 사용자 및 그룹은 QuickSight 내에만 존재합니다!!
- 대시보드...
- 공유할 수 있는 분석의 읽기 전용 스냅샷입니다.
- 분석 구성 유지(필터링, 매개변수, 컨트롤, 정렬)
- 분석 또는 대시보드를 사용자 또는 그룹과 공유할 수 있습니다. • 대시보드를 공유하려면 먼저 게시해야 합니다.
- 대시보드를 보는 사용자는 기본 데이터도 볼 수 있습니다.
AWS Glue
AWS Glue란?
AWS Glue는 분석, 머신 러닝(ML) 및 애플리케이션 개발을 위해 여러 소스에서 데이터를 쉽게 탐색, 준비, 이동 및 통합할 수 있도록 하는 확장 가능한 서버리스 데이터 통합 서비스입니다.
- 관리형 추출, 변환 및 로드(ETL) 서비스
- extract, transform, and load - 분석을 위해 데이터를 준비하고 변환하는 데 유용함
- 완전한 서버리스 서비스
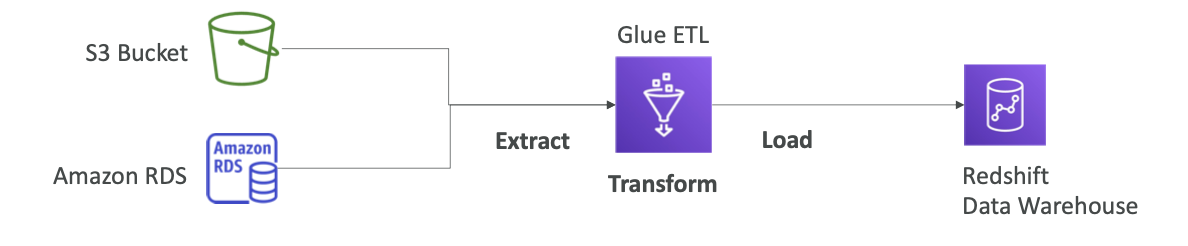
S3 버킷이나 Amazon RDS 데이터베이스에 있는 데이터를 데이터 웨어하우스인 Redshift에 로드할 경우를 예로 들어 보겠습니다.
- Glue를 사용해 추출한 다음 일부 데이터를 필터링하거나 열을 추가하는 등 원하는 대로 데이터를 변형할 수 있습니다.
- 그런 다음 최종 출력 데이터를 Redshift 데이터 웨어하우스에 로드합니다
AWS Glue – 데이터를 Parquet 형식으로 변환
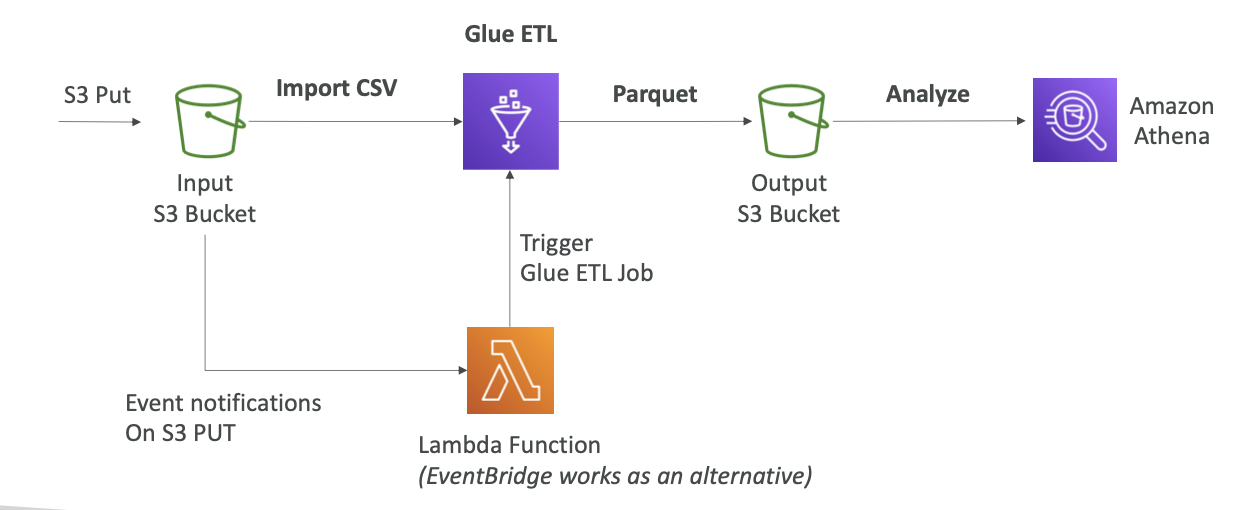
Parquet은 열 기반의 데이터 형식이므로 Athena 같은 서비스와 함께 사용하면 효과적입니다.
예를 들어 S3 버킷에 CSV 형식으로 된 데이터를 삽입한다고 해 보겠습니다.
- Glue ETL 서비스를 사용해 CSV 파일을 가져와 Glue 서비스 내에서 Parquet 형식으로 변환한 다음 출력 S3 버킷으로 데이터를 보냅니다.
- Parquet 형식으로 변환하면 Amazon Athena가 파일을 훨씬 더 잘 분석합니다.
- 전체 과정을 자동화할 수도 있는데, 파일이 S3 버킷에 삽입될 때마다 Lambda 함수로 이벤트 알림을 보내 Glue ETL 작업을 트리거하는 겁니다.
- Lambda 함수 대신 EventBridge를 사용해도 됩니다.
Glue Data Catalog: 데이터 세트 카탈로그

- Glue Data Catalog는 Glue 데이터 크롤러를 실행해 Amazon S3, Amazon RDS Amazon DynamoDB 또는 호환 가능한 온프레미스
JDBC 데이터베이스에 연결합니다.- Glue 데이터 크롤러는 데이터베이스를 크롤링하고 데이터베이스의 테이블 열, 데이터 형식 등의 모든 메타 데이터를 Glue 데이터 카탈로그에 기록합니다.
- 따라서 ETL을 수행하기 위한 Glue 작업에 활용될 모든 데이터베이스, 테이블 메타 데이터를 갖게 됩니다.
- Amazon Athena는 데이터와 스키마를 검색할 때 백그라운드에서 AWS Glue Data Catalog를 활용합니다.
- Amazon Redshift Spectrum과 Amazon EMR도 마찬가지입니다.
Glue – 높은 수준에서 알아야 할 사항
Glue Job Bookmarks: 새 ETL 작업을 실행할 때 이전 데이터의 재처리를 방지. 즉, 오래된 데이터 재처리 방지- 글루 Elastic views:
- SQL을 사용하여 여러 데이터 저장소에서 데이터 결합 및 복제
- 가령 RDS 데이터베이스와 Aurora 데이터베이스 Amazon S3에 걸친 뷰를 생성 - 커스텀 코드 없음, Glue는 소스 데이터의 변경 사항을 모니터링합니다. (서버리스)
- 여러 데이터 스토어에 분산된 구체화된 뷰인 "가상 테이블"(구체화된 보기)을 생성하여 활용
- SQL을 사용하여 여러 데이터 저장소에서 데이터 결합 및 복제
- Glue DataBrew: 사전 구축된 변환을 사용하여
데이터 정리 및 정규화 - Glue Studio: Glue에서 ETL 작업을
생성, 실행 및 모니터링하는 새로운 GUI
- Glue Streaming ETL (Apache Spark Structured Streaming 기반):ETL 작업을 배치 작업이 아니라스트리밍 작업으로 실행- Kinesis Data Streaming, Kafka, MSK(관리형 Kafka)와 호환 가능
AWS Lake Formation
AWS Lake Formation란?
AWS Lake Formation는 데이터 레이크를 손쉽게 구축, 보호 및 관리할 수 있는 완전관리형 서비스입니다.
- 데이터 레이크 = 분석 목적으로 모든 데이터를 보관하는 중앙 집중식 저장소
- 며칠 만에 데이터 레이크를 쉽게 설정할 수 있는
완전 관리형 서비스 - 데이터를 Data Lake로
검색, 정리, 변환 및 수집 - 많은 복잡한 수동 단계(데이터 수집, 정리, 이동, 카탈로그 작성 등) 및 중복 제거(ML 변환 사용)를 자동화합니다.
- 데이터 레이크에서
정형 및 비정형 데이터 결합 - 즉시 사용 가능한 소스 청사진:
S3, RDS, 관계형 및 NoSQL DB - 모든 데이터를 한곳에서 처리하는 장점
- AWS Lake Formation에 연결된 애플리케이션에서는 세분화된 액세스 제어가 가능 (
행 및 열 수준) - AWS Glue를 기반으로 구축
- Glue와 직접 상호작용을 하진 않습니다.
AWS Lake Formation
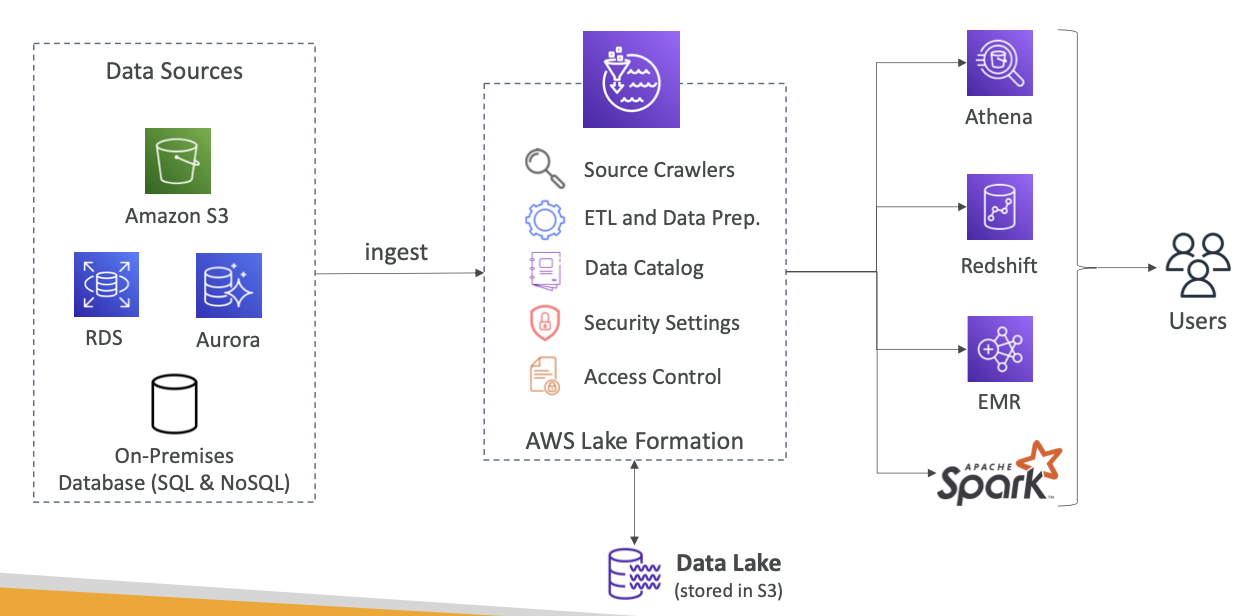
- 앞서 설명한 대로 Lake Formation은 Amazon S3에 저장되는 데이터 레이크의 생성을 돕습니다.
- 데이터 소스로는 Amazon S3 RDS, Aurora SQL, NoSQL 같은 온프레미스 데이터베이스가 있고 Lake Formation의 블루프린트를 통해 데이터를 주입합니다.
- Lake Formation에는 소스 크롤러와 ETL 및 데이터 준비 도구 데이터 카탈로깅 도구가 포함됩니다.
- Glue의 기본 서비스에 해당되고, 데이터 레이크의 데이터를 보호하는 보안 설정과 액세스 제어도 포함됩니다.
- Lake Formation을 활용하는 서비스로는 Athena, Redshift, EMR Apache Spark 프레임워크 같은 분석 도구가 있습니다.
- 사용자는 이와 같은 서비스를 통해 Lake Formation 및 데이터 레이크에 연결합니다.
Centralized Permissions Example

Lake Formation의 핵심적인 개념은 중앙화된 권한이라고 할 수 있습니다.
- 회사가 데이터 분석에 Athena와 QuickSight를 사용할 때, 사용자는 허용된 데이터만 볼 수 있어야 하고 읽기 권한이 있어야 합니다.
- 데이터 소스는 Amazon S3 RDS, Aurora 등이라고 상황을 가정해보겠습니다.
- 우리는 특정사용자에게만 접근을 허용하기 위해, Athena에 보안을 설정하거나 QuickSight에서 사용자 수준의 보안을 설정할 수 있습니다.
- S3 버킷 정책이나 사용자 정책에 보안 설정을 할 수도 있죠 RDS, Aurora도 마찬가지고요.
- 이렇게 보안을 관리할 곳이 많아지면 엉망이 될 것입니다.
어떻게 하면 좋을까요?
- Lake Formation이 답입니다
- 액세스 제어 기능과 열 및 행 수준 보안이 있으니, Lake Formation에 주입된 모든 데이터는 중앙 S3 버킷에 저장되지만 모든 액세스 제어와 행, 열 수준 보안은 Lake Formation 내에서 관리하게 때문에 간편합니다.
- 따라서 Lake Formation에 연결하는 서비스는 읽기 권한이 있는 데이터만 볼 수 있게 됩니다.
- Athena, QuickSight 등 어떤 도구를 사용하든 Lake Formation에 연결하면 한곳에서 보안을 관리할 수 있습니다

42seoul, blockchain, web 3.0