
Kinesis Data Analytics
Kinesis Data Analytics는 상태 유지 이벤트 처리, 스트리밍 ETL 및 실시간 분석을 포함한 다양한 사용 사례에 특화된 Java, Scala, Python 및 SQL 기반의 유연한 API를 제공합니다.
Kinesis Data Analytics를 살펴봅시다 여기에는 두 가지 종류가 있는데, SQL 애플리케이션용과 Apache Flink용이 있습니다.
SQL 애플리케이션용 Kinesis Data Analytics
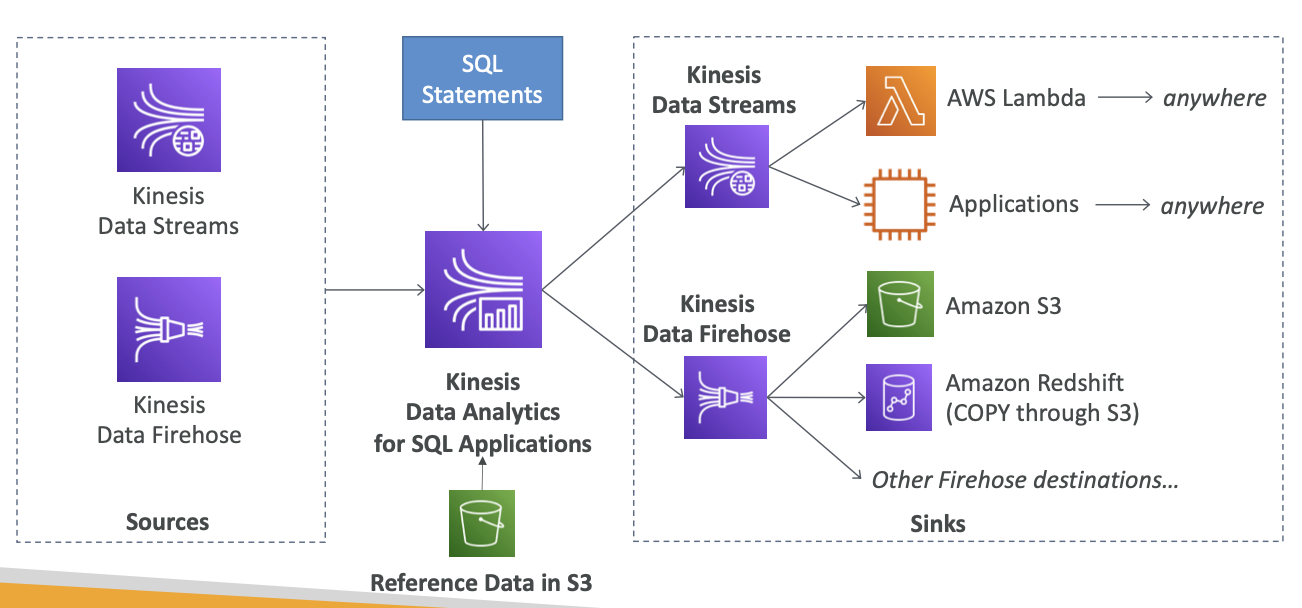
- SQL 애플리케이션용 Kinesis Data Analytics는 중앙에 위치하여 Kinesis Data Streams와 Kinesis Data Firehose 데이터 소스에서 데이터를 읽습니다.
- 둘 중 한군데서 데이터를 읽어 온 다음 SQL 문에 적용하여 실시간 분석을 처리할 수 있습니다.
- Amazon S3 버킷의 데이터를 참조해 참조 데이터를 조인할 수도 있습니다.
- 그렇게 되면 실시간 데이터가 풍성해질 것입니다.
- 그리고 여러 대상에 데이터를 전송하려하는데, 총 두 가지 방법이 있습니다.
- Kinesis Data Firehose로 바로 보내면 Amazon S3 Amazon Redshift이나 Amazon OpenSearch 또는 기타 Firehose 대상에 전송됩니다
- Kinesis Data Streams에 보내면 EC2에서 실행하는 애플리케이션이나 AWS Lambda로 스트리밍하는 데이터를 실시간으로 처리할 수 있습니다
Kinesis Data Analytics (SQL application)
- SQL을 사용하여 Kinesis Data Streams 및 Firehose에 대한 실시간 분석
- Amazon S3의 참조 데이터를 추가하여 스트리밍 데이터 보강
- 완전 관리형, 프로비저닝할 서버 없음
- 자동 스케일링
- Kinesis Data Analutics에 전송된 데이터만큼 비용을 지불합니다.
- 출력:
- Kinesis Data Streams: 실시간 분석 쿼리에서 스트림 생성
- Kinesis Data Firehose: 분석 쿼리 결과를 대상으로 전송
- 사용 사례:
- 시계열 분석
- 실시간 대시보드
- 실시간 지표
Apache Flink용 Kinesis Data Analytics
• Flink(Java, Scala 또는 SQL)를 사용하여 스트리밍 데이터 처리 및 분석
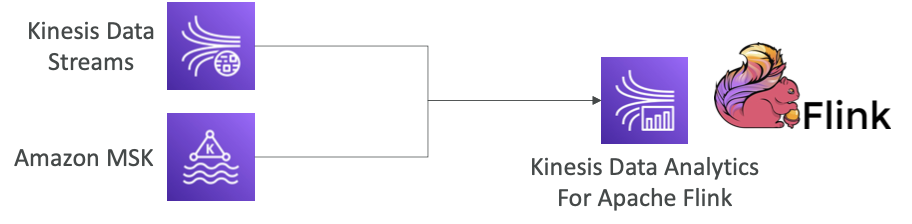
- Flink는 코드로 작성해야 하는 특별한 애플리케이션입니다
- Flink 애플리케이션을 Kinesis Data Analytics의 Flink 전용 클러스터에서 실행할 수 있습니다. (백그라운드)
- AWS의 관리형 클러스터에서 Apache Flink 애플리케이션 실행
- 컴퓨팅 리소스 프로비저닝, 병렬 계산, 자동 확장
- Apache Flink을 사용해 두 개의 메인 데이터 소스인 Kinesis Data Streams나 Amazon MSK의 데이터를 읽을 수 있습니다.
- 애플리케이션 백업(체크포인트 및 스냅샷으로 구현)
- 모든 Apache Flink 프로그래밍 기능 사용
- Flink는 Firehose에서 읽지 않습니다(대신 SQL용 Kinesis Analytics 사용).
- 실시간이 아닙니다.
Apache Kafka용 Amazon 관리형 스트리밍(Amazon MSK)
Amazon MSK는 완전관리형 Apache Kafka를 통해 실시간으로 스트리밍 데이터를 손쉽게 수집하고 처리하게 해줍니다.
- Amazon Kinesis의 대안
- AWS에서 완벽하게 관리되는 Apache Kafka
- 클러스터 생성, 업데이트, 삭제 허용
- MSK는 Kafka 브로커 노드 및 Zookeeper 노드를 생성 및 관리합니다.
- MSK 클러스터를 VPC, 다중 AZ(HA의 경우 최대 3개)에 배포합니다.
- 일반적인 Apache Kafka 오류로부터 자동 복구
- 데이터는 원하는 기간 동안 EBS 볼륨에 저장됩니다.
- MSK 서버리스
- 용량 관리 없이 MSK에서 Apache Kafka 실행
- MSK는 리소스를 자동으로 프로비저닝하고 컴퓨팅 및 스토리지를 확장합니다.
Apache Kafka at a high level
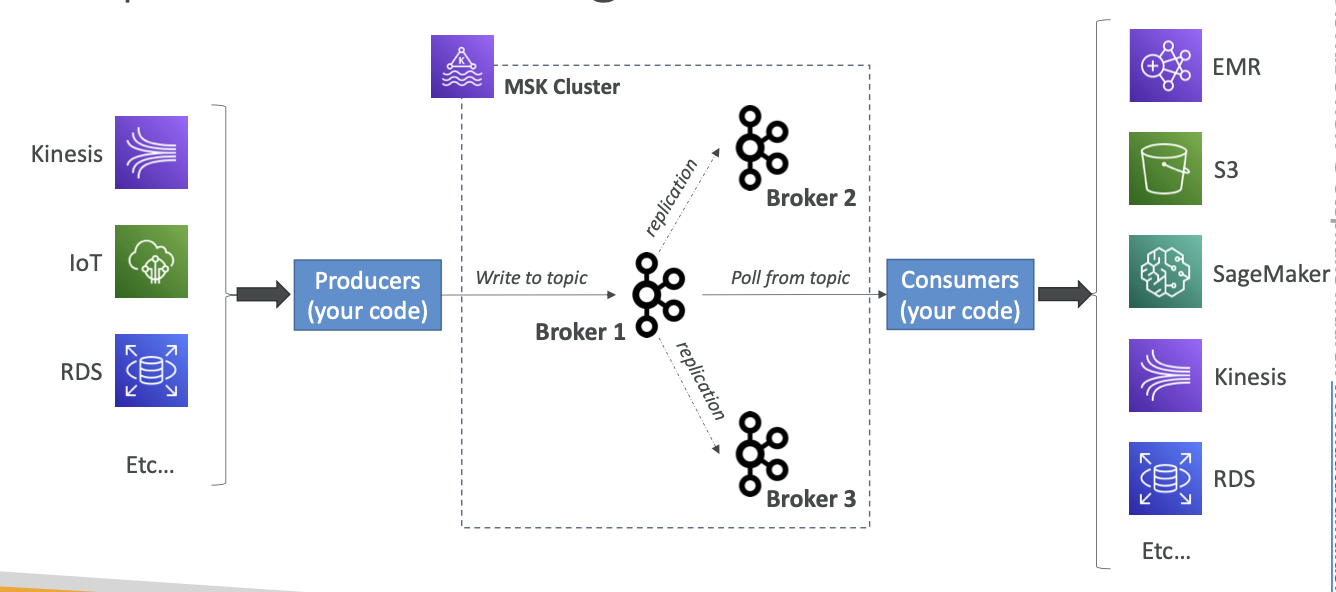
- Apache Kafka는 데이터를 스트리밍하는 방식입니다.
Kafka 클러스터는 여러 브로커로 구성되고 데이터를 생산하는 생산자는 Kinesis, IoT, RDS 등의 데이터를 클러스터에 주입합니다.- Kafka 주제로 데이터를 전송하면 해당 데이터는 다른 브로커로 완전 복제됩니다.
- Kafka 주제는 실시간으로 데이터를 스트리밍하고 소비자는 데이터를 소비하기 위해 주제를 폴링합니다.
- 소비자는 데이터로 원하는 대로 처리하거나 EMR, S3, SageMaker, Kinesis RDS 등의 대상으로 보냅니다.
Kinesis Data Streams vs. Amazon MSK
Kinesis Data Streams
• 1MB 메시지 크기 제한
• 샤드가 있는 데이터 스트림
• 샤드 분할 및 병합
• TLS 기내 암호화
• KMS 미사용 암호화
아마존 MSK
• 기본값 1MB, 더 높게 구성(예: 10MB)
• 파티션이 있는 KafkaTopics
• 주제에만 파티션을 추가할 수 있습니다. (제거 불가)
• PLAINTEXT 또는TLS 기내 암호화
• KMS 미사용 암호화
• EBS스토리지 비용지불하면 1년 이상 데이터 보관 가능
Amazon MSK Consumers
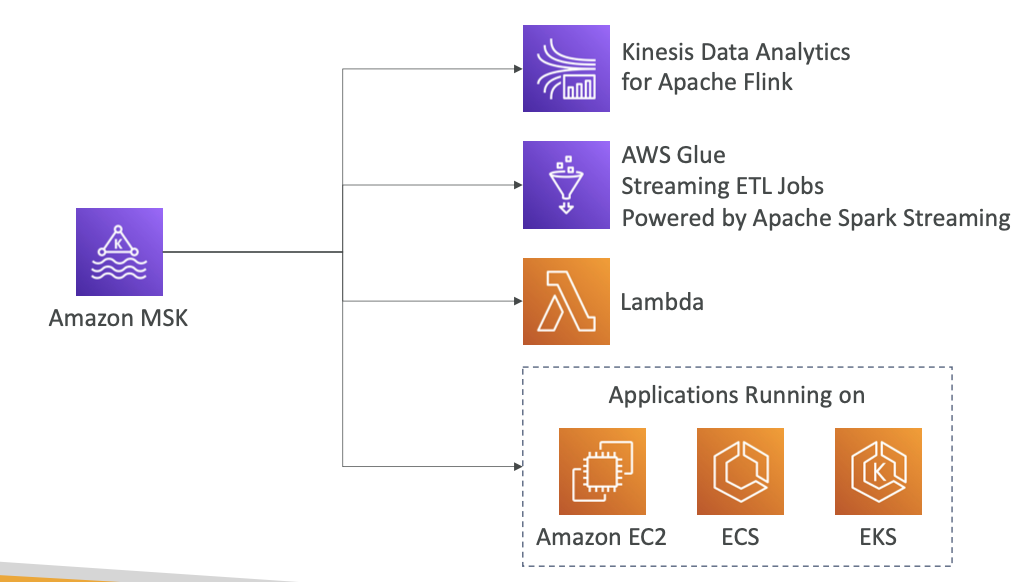
- MSK의 데이터를 소비하는 방법은 여러 가지입니다.
- Apache Flink용 Kinesis Data Analytics를 사용해 Apache Flink 앱을 실행하고 MSK 클러스터의 데이터를 읽어 오면 됩니다
- AWS Glue로 ETL 작업을 스트리밍해도 됩니다 Glue는 Apache Spark Streaming으로 구동되죠.
- Amazon MSK를 이벤트 소스로 이용하려면 Lambda 함수를 사용할 수 있고,
- 자체 Kafka 소비자를 생성해 원하는 플랫폼에서 실행할 수도 있습니다. 예) Amazon EC2 인스턴스나 EC2 클러스터, EKS 클러스터
Big Data Ingestion Pipeline
• 수집 파이프라인이 완전히 서버리스가 되기를 원합니다.
• 실시간으로 데이터를 수집하고 싶습니다.
• 데이터를 변환하고 싶습니다.
• SQL을 사용하여 변환된 데이터를 쿼리하려고 합니다.
• 쿼리를 사용하여 생성된 보고서는 S3에 있어야 합니다.
• 해당 데이터를 웨어하우스에 로드하고 대시보드를 생성하려고 합니다.
Big Data Ingestion Pipeline 사용하면됩니다.
AWS Data Pipeline은 온프레미스 데이터 소스뿐 아니라 여러 AWS 컴퓨팅 및 스토리지 서비스 간에 데이터를 안정적으로 처리하고 지정된 간격으로 이동할 수 있게 지원하는 웹 서비스입니다
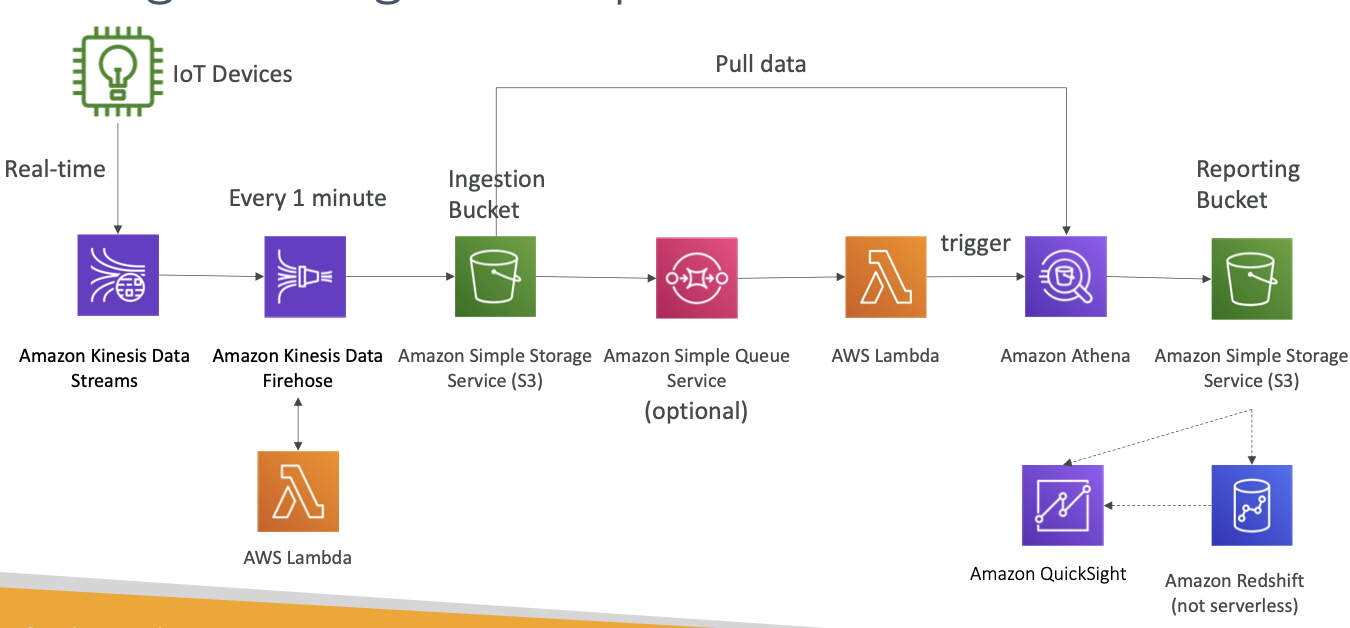
- 데이터 생산자가 IoT 장치라고 가정해 보겠습니다. Amazon 클라우드 서비스 중 IoT Core는 매우 유용한 기능으로 IoT 장치 관리를 돕습니다.
- IoT Core는 장치에서 실시간으로 전송받은 데이터를 Kinesis Data Stream으로 직접 전달합니다.
- Kinesis의 데이터 스트림은 빅 데이터가 실시간으로 Kinesis 서비스에 전송되도록 허용합니다.
- Kinesis Data Firehose는 Kinesis와 통신해서 거의 1분마다 Amazon S3 버킷에 데이터를 입력하고 오프로드하도록 할 것입니다.
여기까지를수집 버킷이라고 합니다 이렇게 해서 여러 장치에서 많은 데이터를 실시간으로 얻을 수 있는 파이프라인이 마련됐습니다- 또한, S3 버킷에 데이터를 매분 입력해 줄 뿐만 아니라 람다 함수를 이용해 빠른 속도로 데이터를 정리하거나 변형하도록 도와주기도 하는데 이때 람다 함수는 Kinesis Data Firehose와 직접 연결된 상태입니다.
- 데이터 수집 버킷은 어떤 기능을 수행할까요?
- SQS 대기열을 작동할 수 있는데 이건 선택 사항입니다. SQS 대기열은 람다 함수를 실행합니다 (S3 버킷이 Lambda를 직접 작동할 수 있기 때문에)
- Lambda가 Amazon Athena SQL 쿼리를 실행하면 Athena 쿼리는 수집 버킷에서 데이터를 가져와 SQL 쿼리를 생성하는데 전부 서버리스입니다.
- 여기서 만든 서버리스 쿼리 출력값은 앞에 있는 보고용 S3 버킷으로 보고하도록 세팅하겠습니다
- 이 과정에서 데이터를
보고하고 정리, 분석까지 이루어졌습니다.
- QuickSight를 통해 직접 시각화할 수도 있는데요
- QuickSight는 Amazon S3 버킷으로 데이터를 시각화하거나 Amazon Redshift 같은 데이터 웨어하우스에 데이터를 입력해 분석하기도 합니다.
- 여기서 Redshift는 서버리스가 아니라는 점 기억해야합니다. Redshift 데이터 웨어하우스는 QuickSight의 엔드 포인트로 작용합니다
- 이제껏 본 내용을 바탕으로 빅 데이터 수집 파이프라인이 뭔지 핵심을 짚어 보자면 실시간 데이터 수집과 변형 서버리스 Lambda와 Redshift 활용 데이터 웨어하우스 QiuckSight 활용 시각화를 꼽을 수 있을 것 같습니다.
Big Data Ingestion Pipeline 첨언
- IoT Core를 사용하면 IoT 기기에서 데이터를 수집할 수 있습니다.
- Kinesis는 실시간 데이터 수집에 적합합니다.
- Firehose는 거의 실시간(최저 1분)으로 S3에 데이터를 전달하도록 지원합니다.
- Lambda는 데이터 변환을 통해 Firehose를 지원할 수 있습니다.
- Amazon S3는 SQS에 대한 알림을 트리거할 수 있습니다.
- Lambda는 SQS를 구독할 수 있습니다(Connector S3를 Lambda에 포함할 수 있음).
- Athena는 서버리스 SQL 서비스이며 결과는 S3에 저장됩니다.
- 보고 버킷에는 분석된 데이터가 포함되어 있으며 AWS QuickSight, Redshift 등과 같은 보고 도구에서 사용할 수 있습니다.
