
Amazon Rekognition
- ML을 사용하여 이미지 및 동영상에서 개체, 사람, 텍스트, 장면 찾기
- 사용자 확인을 위한 안면 분석 및 안면 검색, 사람 수 계산 • "익숙한 얼굴" 데이터베이스 생성 또는 유명인과 비교
- 사용 사례:
- 라벨링
- 콘텐츠 조정
- 텍스트 감지
- 얼굴 감지 및 분석(성별, 연령대, 감정...)
- 얼굴 검색 및 인증
- 유명인사 인정
- 경로 지정(예: 스포츠 게임 분석용)
- 사용 사례:
Amazon Rekognition – 콘텐츠 조정

- 부적절하거나 원치 않거나 불쾌감을 주는 콘텐츠 감지(이미지 및 비디오)
- 보다 안전한 사용자 경험을 만들기 위해 소셜 미디어, 방송 매체, 광고 및 전자 상거래 상황에서 사용
- 플래그가 지정될 항목에 대한 최소 신뢰 임계값 설정
- Amazon Augmented AI(A2I)에서 수동 검토를 위해 민감한 콘텐츠에 플래그 지정
- 규정 준수 지원
Amazon Transcribe
- 음성을 텍스트로 자동 변환
- 자동 음성 인식(ASR)이라는 딥 러닝 프로세스를 사용하여 음성을 텍스트로 빠르고 정확하게 변환합니다.
- Redaction을 사용하여 개인 식별 정보(PII)를 자동으로 제거합니다.
- 다국어 오디오에 대한 자동 언어 식별 지원
- 사용 사례:
- 고객 서비스 통화 기록
- 자막 및 자막 자동화
- 완전히 검색 가능한 아카이브를 만들기 위해 미디어 자산에 대한 메타데이터 생성
Amazon Polly
- 딥 러닝을 사용하여 텍스트를 생생한 음성으로 변환
- 말하는 애플리케이션을 만들 수 있습니다.
Amazon Polly – Lexicon & SSML
- 발음 어휘를 사용하여 단어의 발음을 사용자 지정합니다.
- 양식화된 단어: Jung2an => "junghan"
- 약어:AWS=>"AmazonWebServices"
- 어휘를 업로드하고 SynthesizeSpeech 작업에서 사용
- 일반 텍스트 또는 Speech로 표시된 문서에서 음성 생성
SSML(Synthesis Markup Language) – 더 많은 사용자 지정 가능- 특정 단어나 구를 강조하기
- 음성 발음 사용
- 숨소리 포함, 속삭임
- 뉴스 캐스터 말하기 스타일 사용
Amazon Translate
- 자연스럽고 정확한 언어 번역
- Amazon Translate를 사용하면 해외 사용자를 위해 웹사이트 및 애플리케이션과 같은 콘텐츠를 현지화하고 대량의 텍스트를 효율적으로 쉽게 번역할 수 있습니다.
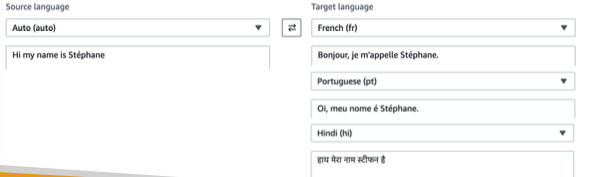
Amazon Lex & Connect
- Amazon Lex: (Alexa를 지원하는 동일한 기술)
- 음성을 텍스트로 변환하는 자동 음성 인식(ASR)
- 텍스트, 발신자의 의도를 인식하는 자연어 이해
- 챗봇, 콜센터 봇 구축 지원
- 아마존 커넥트:
- 전화 받기, 고객 응대 흐름 생성, 클라우드 기반 가상 컨택 센터
- 다른 CRM 시스템 또는 AWS와 통합 가능
- 선불금 없음, 기존 컨택 센터 솔루션보다 80% 저렴

Amazon Comprehend
- 자연어 처리 – NLP
- 완전 관리형 서버리스 서비스
- 머신러닝을 사용하여 텍스트에서 통찰력과 관계 찾기
- 텍스트 언어
- 핵심 문구, 장소, 사람, 브랜드, 이벤트 추출
- 텍스트가 얼마나 긍정적인지 부정적인지 이해합니다.
- 토큰화 및 품사를 사용하여 텍스트 분석
- 주제별로 텍스트 파일 모음을 자동으로 구성
- 샘플 사용 사례:
- 고객 상호 작용(이메일)을 분석하여 무엇이 긍정적이거나 부정적인 경험으로 이어지는지 파악합니다.
- Comprehend가 발견할 주제별로 기사 작성 및 그룹화
Amazon Comprehend Medical
- Amazon Comprehend Medical은 구조화되지 않은 임상 텍스트에서 유용한 정보를 감지하고 반환합니다.
- 의사의 메모
- 퇴원요약서
- 검사결과
- 케이스 메모
- NLP를 사용하여 개인 건강 정보(PHI) 탐지 – DetectPHI API
- 문서를 Amazon S3에 저장하거나 Kinesis Data Firehose로 실시간 데이터를 분석하거나 Amazon Transcribe를 사용하여 Amazon Comprehend Medical에서 분석할 수 있는 텍스트로 환자 설명을 기록합니다.
Amazon SageMaker
- 개발자/데이터 과학자를 위한 ML 모델 구축을 위한 완전 관리형 서비스
- 일반적으로 모든 프로세스를 한 곳에서 수행하기 어려움
- 서버 프로비저닝
- 기계 학습 프로세스(간소화): 시험 점수 예측

시험 점수를 예측할 모델을 구축한다고 해봅시다 어떻게 해야 할까요?
- 먼저 제가 개발자이거나 데이터 과학자라면 제 학생들의 실제 시험 점수에 관한 모든 데이터를 수집할 겁니다.
- 그러면 10,000명의 학생에게 IT 분야의 경력이 몇 년인지 데이터베이스 경력은 몇 년인지 얼마나 강의를 들었는지 연습 시험은 몇 번이나 치렀는지 등을 조사해서 가능한 많은 데이터를 수집하고 해당 데이터를 라벨링 하겠죠.
- 어떤 열이 무슨 데이터와 대응하는지 정해야 하고 또한 점수도 필요합니다
- 여기서 점수는 진짜 시험에서 얻은 점수를 뜻합니다 누군가 670점을 넘지 못했다면 강의 과정을 완전히 끝내지 못해서겠죠?
- 누군가는 높은 점수로 통과했을 겁니다 그러면 890점이나 934점이 될 수도 있어요
- 다시 말해 학생마다 특정한 점수를 얻게 됩니다 그러면 이렇게 수집한 데이터를 기반으로 점수가 어떨지 예상할 수 있을 거예요
- 이제 라벨링을 합니다 실제로는 상당히 복잡한 작업이에요
- 다음은 머신 러닝 모델을 구축해야 합니다 과거 데이터를 통해 점수를 예측하는 모델입니다
- 머신 러닝 모델을 구축한 후에는 훈련 및 조정이 필요해요 이것도 꽤 어려운 부분이죠
- 데이터와 출력이 더 들어맞도록 점차 모델을 개선하는 거죠
- SageMaker는 전 과정에서 도움을 줍니다 라벨링, 구축, 그리고 훈련 및 조정까지요 그뿐만이 아닙니다 머신 러닝 모델을 생성해서 잘 작동된다고 합시다 그러면 이제 사용을 해야죠
- 바로 머신 러닝 모델을 배포 하는 거죠 그러면 새로운 데이터가 들어옵니다. - 예를 들어 여러분이 새로운 학생이면 제가 설문 조사를 합니다 IT 경력이 몇 년인지 AWS를 얼마나 다루었는지 강의는 얼마나 들었는지 등이요
- 그리고 여러분이 제공한 데이터를 가지고 앞서 생성한 머신 러닝 모델에 적용합니다
- 그러면 머신 러닝은 가지고 있는 데이터에 근거하여 이 학생이 906점으로 합격할 것을 예측합니다.
- 이 모든 과정, 즉 라벨링과 구축, 훈련 및 조정, 적용 모두 SageMaker에서 가능합니다
Amazon Forecast
- ML을 사용하여 매우 정확한 예측을 제공하는 완전 관리형 서비스
- 예: 비옷의 향후 판매 예측
- 데이터 자체를 보는 것보다 50% 더 정확함
- 예측 시간을 몇 개월에서 몇 시간으로 단축
- 사용 사례: 제품 수요 계획, 재무 계획, 리소스 계획, ...

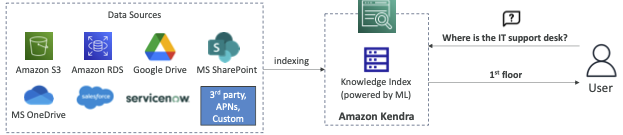
Amazon Kendra
- 머신 러닝 기반의 완전 관리형 문서 검색 서비스
- 문서 내에서 답변 추출(텍스트, PDF, HTML, PowerPoint, MS Word, FAQ...)
- 자연어 검색 기능
- 사용자 상호 작용/피드백을 통해 학습하여 선호하는 결과를 촉진(증분 학습) - 검색 결과를 수동으로 미세 조정하는 기능(데이터의 중요성, 최신성, 사용자 지정 등)
Amazon Personalize
- 실시간 맞춤 추천으로 앱을 구축하는 완전 관리형 ML 서비스
- 예: 개인화된 제품 추천/순위 재지정, 맞춤형 다이렉트 마케팅
- 예: 사용자가 정원 가꾸기 도구를 구매하고 구매할 다음 단계에 추천 제공
- Amazon.com에서 사용하는 것과 동일한 기술
- 기존 웹사이트, 애플리케이션, SMS, 이메일 마케팅 시스템 등에 통합 ...
- 몇 달이 아닌 며칠 만에 구현(ML 솔루션을 구축, 교육 및 배포할 필요가 없음) - 사용 사례: 소매점, 미디어 및 엔터테인먼트...

Amazon Textract
- AI 및 ML을 사용하여 스캔한 모든 문서에서 텍스트, 손글씨 및 데이터를 자동으로 추출합니다.

- 양식 및 테이블에서 데이터 추출
- 모든 유형의 문서(PDF, 이미지 등) 읽기 및 처리
- 사용 사례:
- 금융 서비스(예: 인보이스, 재무 보고서)
- 의료(예: 의료 기록, 보험 청구)
- 공공 부문(예: 세금 양식, ID 문서, 여권)
AWS Machine Learning - Summary
- Rekognition: 얼굴 감지, 레이블 지정, 유명인 인식
- Transcribe: 오디오를 텍스트로(예: 자막)
- Polly: 텍스트를 오디오로
- Translate:: 번역
- Lex: 대화형 봇 구축 – 챗봇
- Connect: 클라우드 컨택 센터
- Comprehend:: 자연어 처리
- SageMaker: 모든 개발자 및 데이터 과학자를 위한 기계 학습 • 예측: 매우 정확한 예측 구축
- Kendra: ML 기반 검색 엔진
- Personalize: 실시간 맞춤형 추천
- Textract: 문서에서 텍스트 및 데이터 감지

42seoul, blockchain, web 3.0