얻을만한 아이디어
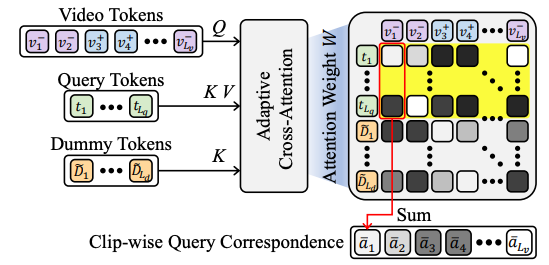
- Adaptive Cross Attention을 사용해서 인코더 구조를 더 발전시킨 것과 Attention Weight의 값으로 추가로 학습을 해서 성능을 높인 것이 인상깊다.
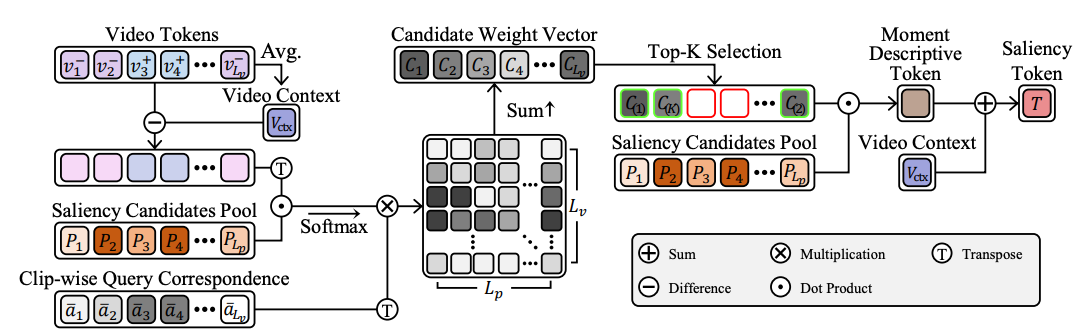
- Saliency token도 candidate pool에서 뽑고, attention weight의 값을 같이 이용해서 saliency token 만든 것도 흥미롭다.
- saliency token이나 dummy token을 만드는 방식도 단순히 learnable parameter를 쓰는 것이 아니라, saliency candidates pool을 사용하고 text query에 따라 만드는 것도 참고할만 하다.
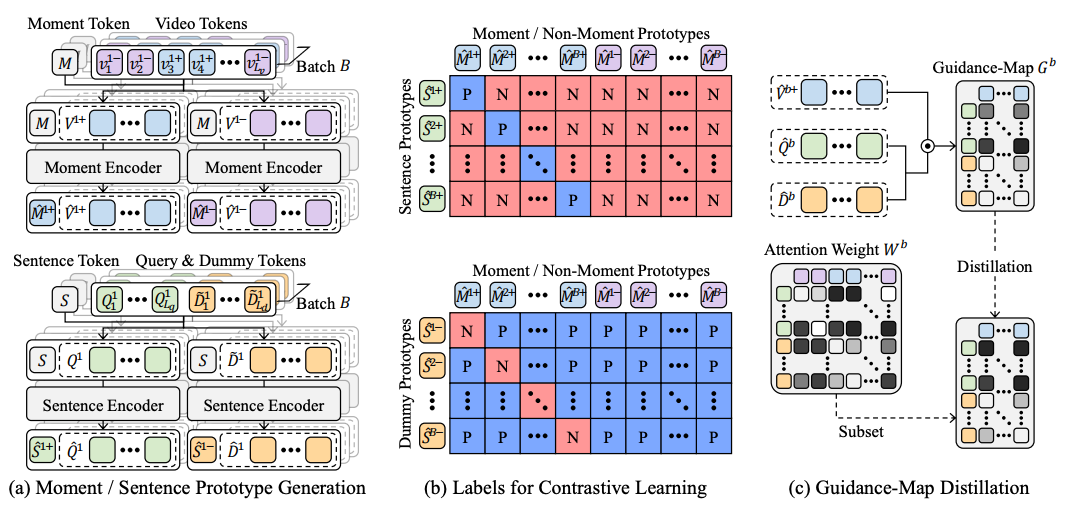
- 각 dummy token별 역할구분을 위한 직교 loss나, distill loss에서 분포를 배우기위해 KL divergence loss를 사용한 것도 참고하면 좋을 것 같음
Contribution
- QD-DETR보다 더 발전시킨 인코더 구조 (디코더는 다루지 않음)
- 단순 cross-attention이 아닌 Adaptive Cross-attention
- moment token, sentence token을 따로 만들고 그것들로 대조학습한 후에, 그 과정에서 생긴 clip-word 관계를 답안으로 weak-supervision으로 사용함
- Saliency token을 만드는 방식 고도화(Saliency Candidate Pool에서 적당한 것을 뽑아서 가중치 곱해서 Saliency token으로 사용. 이 때, Attention Weight에서 query 가중치 합한 값을 같이 이용)
특이점
- text 벡터들로 dummy token을 만듬.
- adaptive Cross-Attention에서 만들어진 Attention Weight에서 query weight를 합친 값을 이용해서 추가로 학습시킴 (이때, GT saliency score가 0이 아니면 1로 둬서 학습시킨다는 것이 특징)
- dummy token들의 역할을 나누기 위해서 직교성 loss도 추가함
- KL divergence loss를 사용해 distill loss를 구함
전체 아키텍쳐
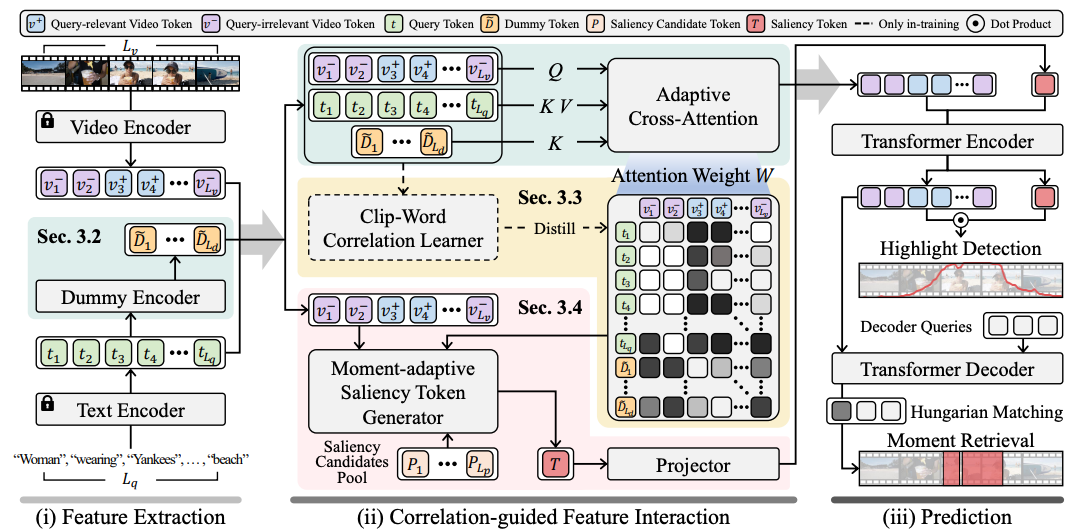

논문 읽은거 자꾸 까먹어서 기록