MR 논문
1.UMT (CVPR, 2022)
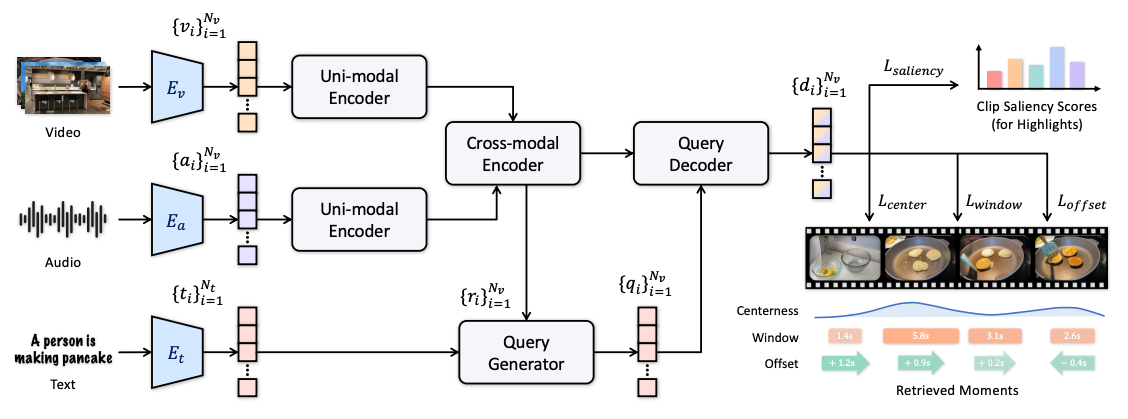
x
2025년 4월 15일
2.QD-DETR (CVPR, 2023)
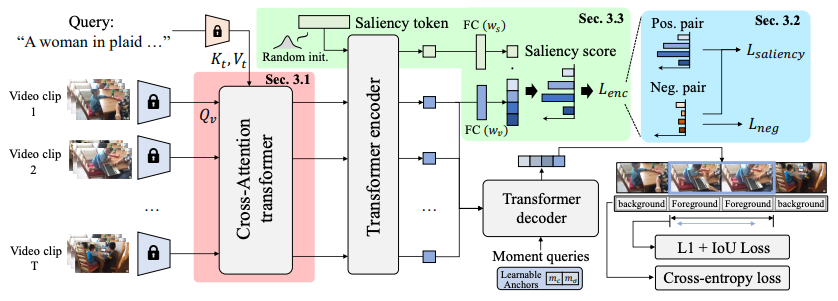
효과적인 인코더 구조
2025년 4월 15일
3.EaTR (ICCV, 2023)
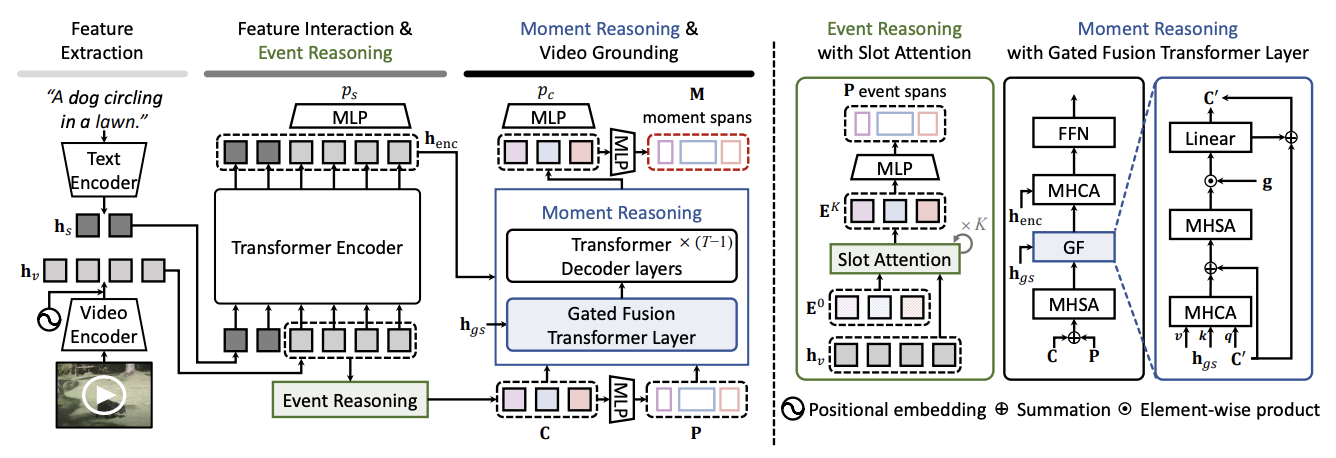
인코더는 구식, 디코더 설계 흥미로움
2025년 4월 15일
4.BAM-DETR (ECCV, 2024)
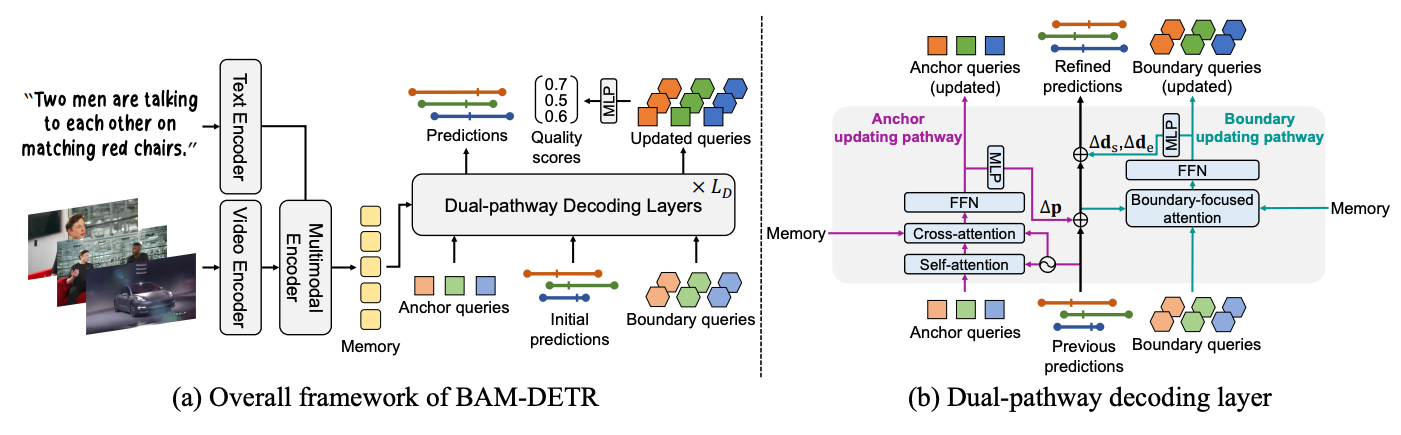
quality-based score 좋고 start, end 모델링한 디코더 구조를 나중에 좀 더 개발할 수도 있을 것 같다.
2025년 4월 15일
5.EMB (2022, ECCV)
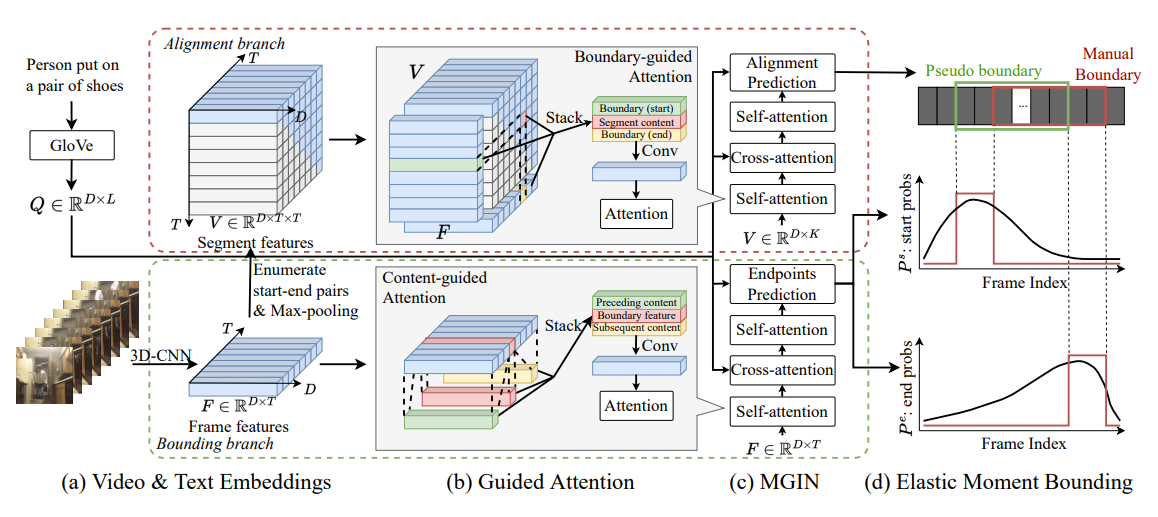
Video Input에 맞는 EMB 생성과 guided attention
2025년 4월 16일
6.CG-DETR (2024)
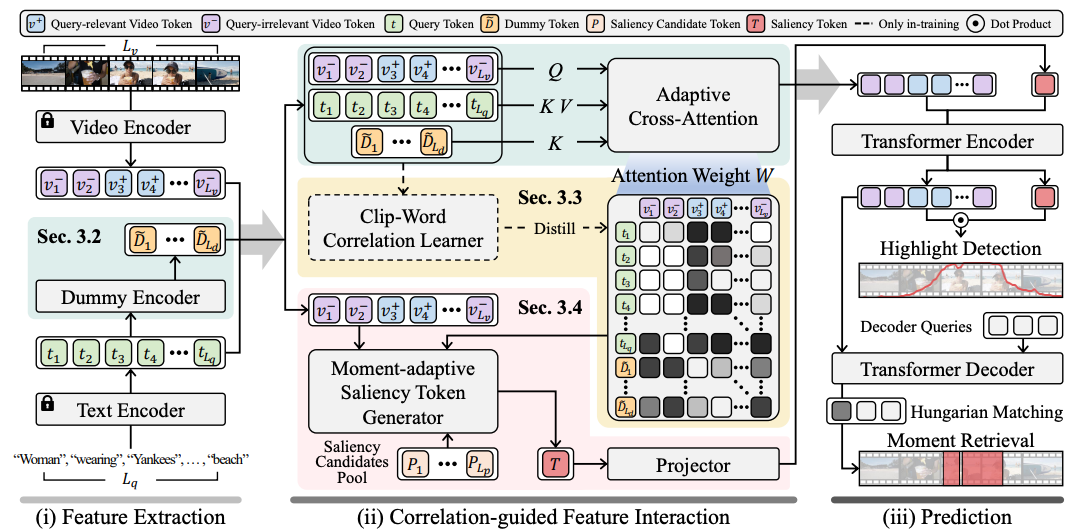
인코더 많이 발전시킴. Adaptive Cross attention, Attention Weight를 이용해 추가로 많이 학습, Saliency token 형성방식 고도화.
2025년 4월 21일
7.MH-DETR (IJCNN, 2024)
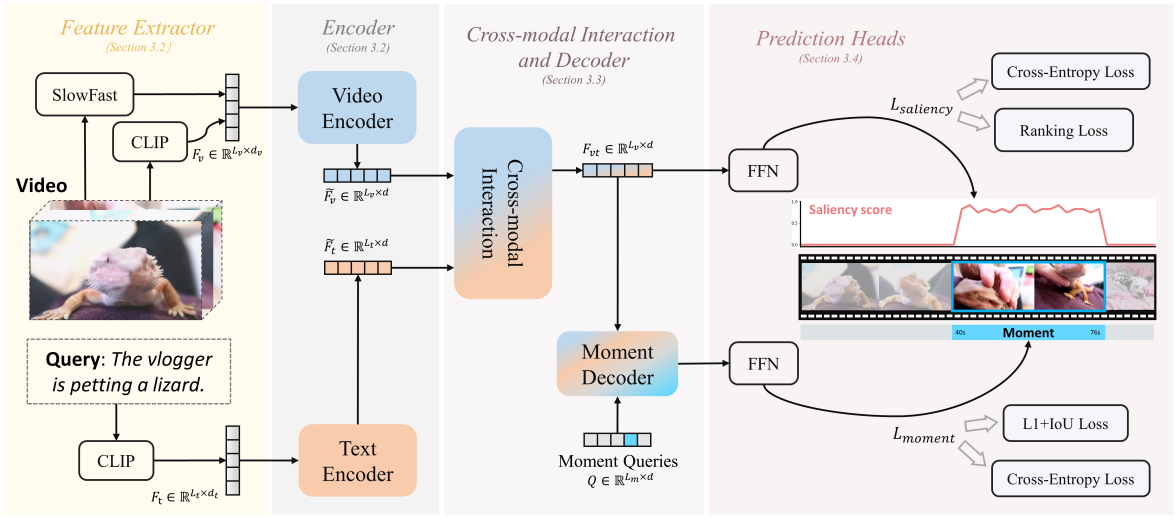
Moment-DETR에서 인코더 살짝 업데이트한 논문. 딱히 참고할점 없음.
2025년 4월 21일
8.TR-DETR (AAAI, 2024)
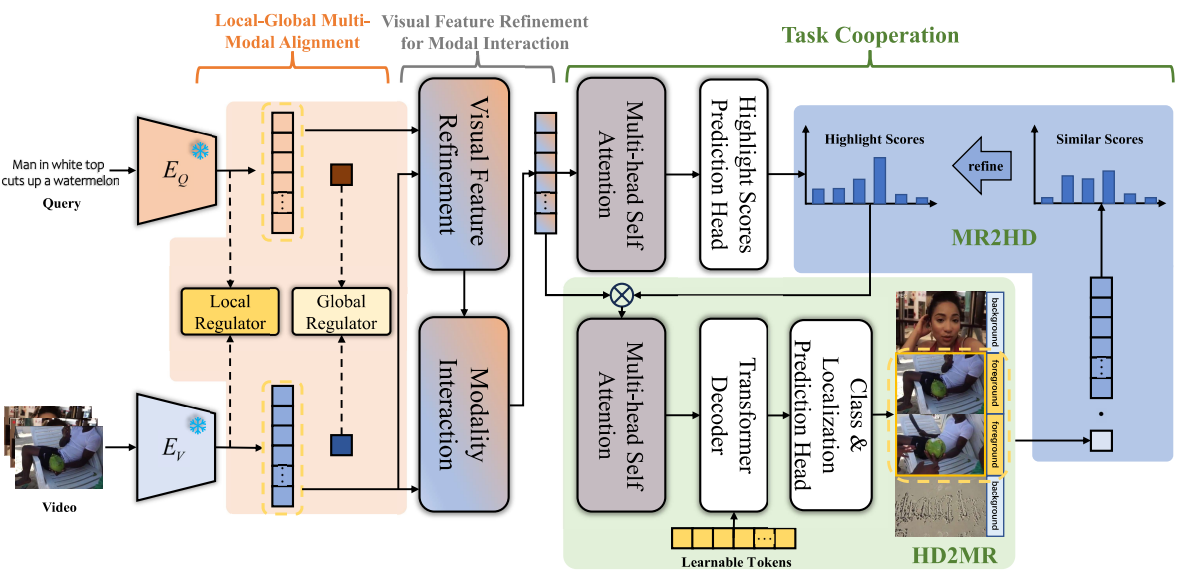
Task 상호작용도 흥미롭고 인코더도 많이 참고할 부분이 있는 논문 (visual refinement, joint feature 뽑는 모듈)
2025년 4월 22일
9.R2-Tuning (ECCV, 2024)
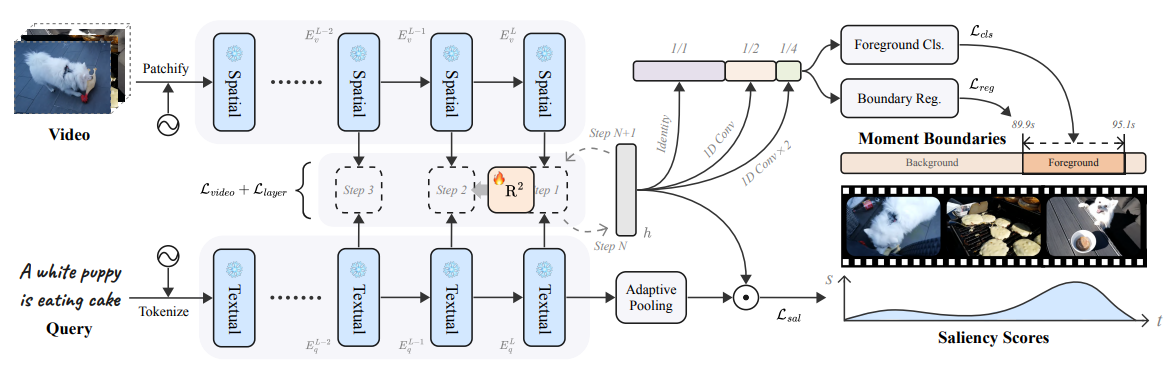
디코더는 단순 UniVTG. 하지만, CLIP만을 활용해 text와 video를 잘 반영한 feature를 뽑아내서 SOTA 성능을 내서 인상깊음.
2025년 4월 22일
10.LLMEPET (ACM MM, 2024)
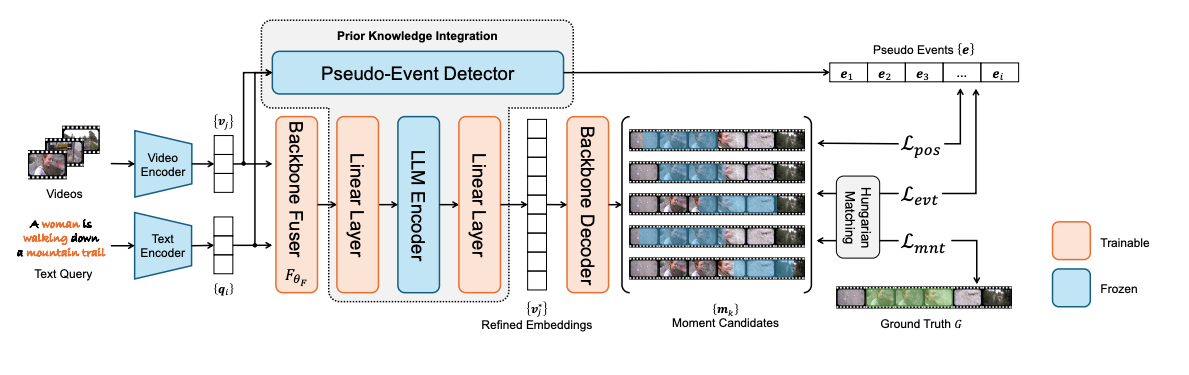
plug-in 방식으로 만들어진 LLM 인코더를 통한 refinement와 Pseudo-Event loss 구성. 나중에 한번 써보고 성능이 진짜 유의미하게 증가되는지 테스트해볼법하다.
2025년 4월 22일
11.MR BLIP (2024)
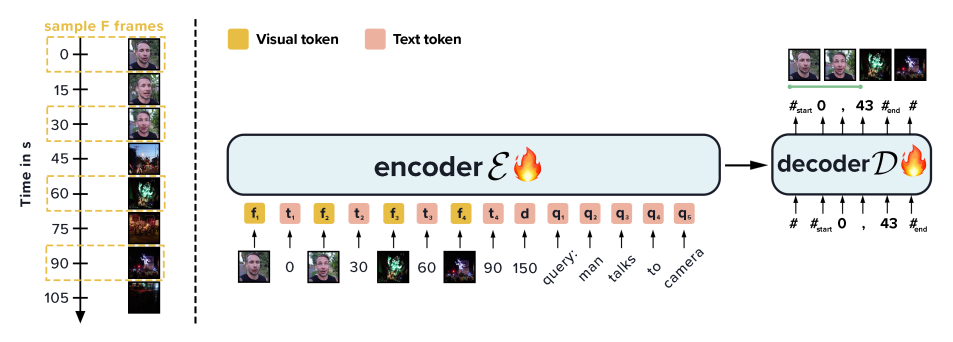
BLIP2로 간단히 구현했는데 성능이 상당히 높게 나온 논문.
2025년 4월 22일
12.FlashVTG (WACV, 2025)
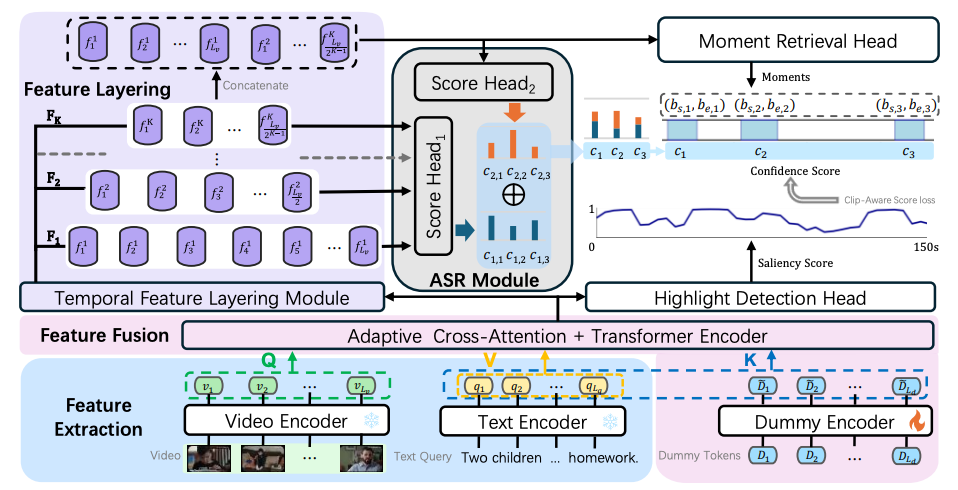
Feature Pyramid와 그에 따른 점수모듈 만든 것. 아주 간단한 기여인데 성능은 많이 오름. 나머지는 거의다 기본이라 발전할 점은 많이 보임.
2025년 4월 22일
13.SG-DETR (2024)
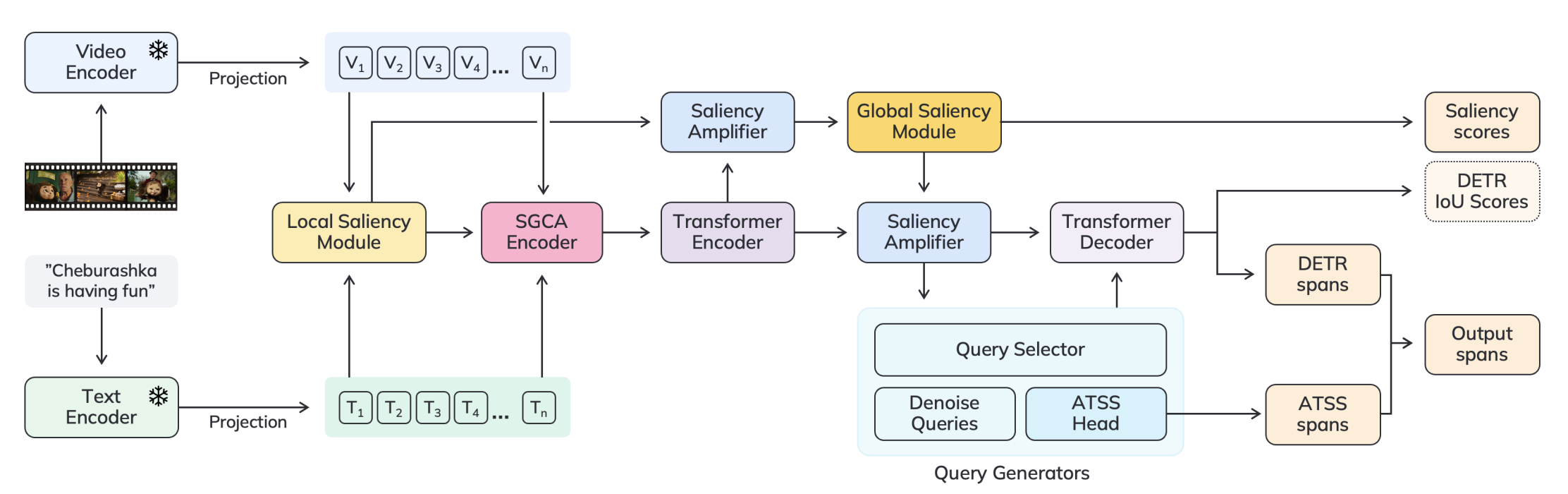
contribution이 많아서 여기서 더 업그레이드할 부분을 찾아보면 좋을 것 같다. 아직 임시로 올린 글이라 더 자세히 탐구해봐야될 것 같다.
2025년 4월 28일