얻을만한 아이디어
- moment query 구현한 아이디어는 괜찮은데 성능이 생각보다 안좋은 이유가 인코더가 별로여서일까? (sal loss도 margin loss 1개이긴함)
- Input에 맞게 동적으로 바뀌는 moment query 아이디어는 좋은 것 같다.
- Event-aware로 성능을 높일 수 있는데 모든 GT가 Event로 안되어있을 수도 있을 것 같다는 생각도 든다. 그래서 오히려 Event로 해서 성능이 떨어질수도 있지 않을까 라는 생각도 들었다.
- 근데 일단 Event-aware하게 설계했더니 성능이 올랐으니까 인코더도 좋게 해서 한번 실험해보고 싶긴하다.
Contributions
- event-aware dynamic moment query 구현 (디코더 건드린 논문)
- Video Input에 따라 동적으로 Event로 나눠지는 moment query 구현
특이점
- 인코더는 구식인데 디코더를 잘 설계했다. 이를 좀 더 발전시킬수 있을까?
전체 아키텍쳐
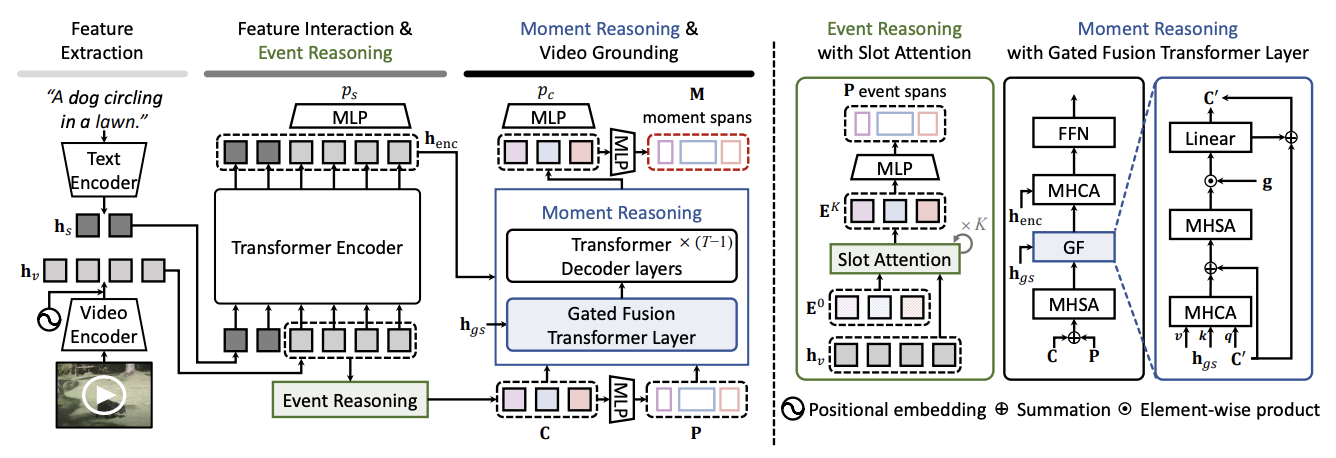
- Event Reasoning: Slot Attention으로 N개의 event slot 만듬 (이것이 곧 moment query)
오른쪽 그림에 나와있듯이, slot attention은 N개 learnable 파라미터를 query로, Video feature를 key, value로 해서 K번 수행 (GRU 대신 residual summation 사용)
이 때, cross attention과 거의 유사하지만 attention weight 구할 때 softmax를 열방향으로 한번 해주고, 행방향으로는 단순 정규화시켜줌. () <- 여기서는 열방향인데 transpose시켜줄거라 저렇게 생각해도됨. - MLP 씌워서 P event spans 만듬 (중심, 너비)
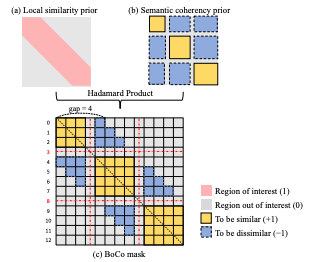
- TSM 기반 UBoCO로 pesudo event timestamp 라벨 만듬 (훈련은 안시키고, 그냥 바로 추론해서 정답라벨로 사용)
대각요소 중에 평균 이하 값 없애고 크기3 sliding window 사용해서 max 값 남김
-> 이것을 이용해서 P와 간의 훈련 진행
- Moment Reasoning: gated fusion transformer layer (sentence-relevent한 moment query를 강화시키고 관련없는 moment query는 억제하기 위함)
max pooling해서 구하고 gated fusion transformer layer 통과시켜서 구현
Ablations
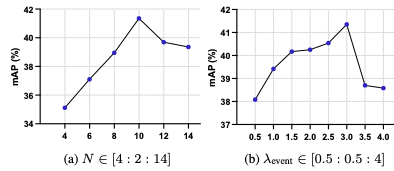
- 인코더 별로 안좋은데, 위와 같이 추가했을 때 성능이 좋아지는 모습 ( 추가안해도 그냥 Input에 의해 dynamic하게 moment queries 설정해도 성능 오르긴하네?)

- GF가 가장 성능이 좋았음

- 나 N 같은 하이퍼 파라미터가 많이 민감한 것 같음

논문 읽은거 자꾸 까먹어서 기록