얻을만한 아이디어
- 모르겠음
Contribution
- multi-modal learning을 통해 최초로 MR, HD 수행 (즉, Audio 정보도 사용)
- flexibility (텍스트 쿼리 없거나, 오디오 안넣는 등의 상황에서도 동작)
특이점
- Centerness loss에서 gaussian focal loss 사용
(쉽게 말하면, GT center을 1로 하고, 정규분포 그려서 그걸 정답 라벨로 사용. 나머지는 focal loss와 똑같은데, otherwise 부분에서 부분만 추가하여 정답근처일때는 loss 적게 함.
전체 아키텍쳐
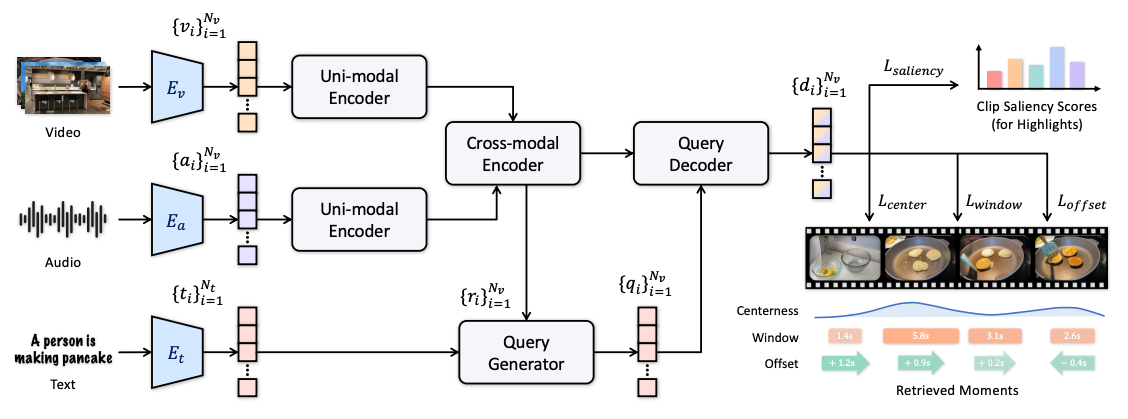
- uni-modal Encoder: MHSA + FFN으로 구성
- Cross-modal Encoder: 단순 cross-attention 아님 (이유1: 시간적 중복, 도움 안되는 잡음, 이유2: 연산복잡도 큼)
- Query Generator: 를 query로, 를 key, value로 해서 clip별 Query 임베딩 획득
- Query Decoder: 를 query로, 를 key, value로 해서 디코딩
- Dense Regression 방식을 사용해서 clip별로 Center, window, offset, saliency score 구함.
Cross-modal Encoder
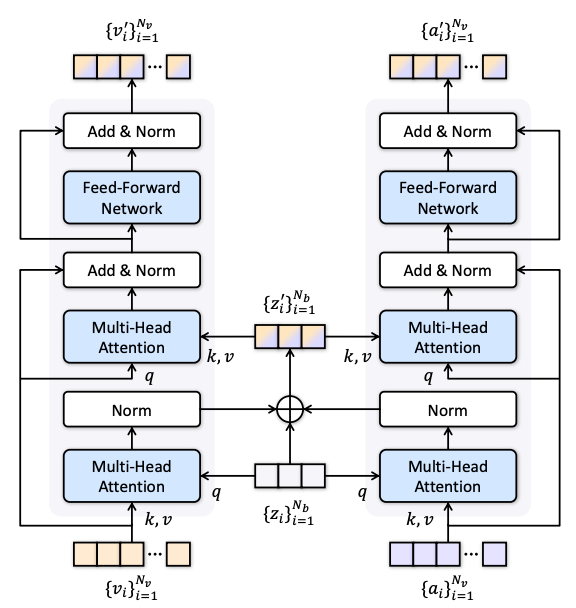
- 에 Video, Audio Modality 정보 압축해서 섞은거 다시 확장해서 자기 modality로 가져가는 방식
- 는 보다 훨씬 작은 수. 본 논문에서는 =4로 하였음.
- 압축되면서 불필요한 noise도 삭제되는 효과가 있다고 함.

논문 읽은거 자꾸 까먹어서 기록