이미지 인식 분야에 Transformer 아키텍쳐를 적용하여, 기존 CNN 모델과 성능을 비교한 연구
기존 CNN 모델처럼 주어진 입력 이미지를 픽셀 단위로 처리하는 것이 아닌, 전체 이미지를 하나의 sequence로 보는 접근 방식 (주어진 입력 이미지를 나열된 단어들처럼 처리)
→ 이미지 내의 픽셀들 간 상관관계를 고려할 수 있어, 효과적인 특징 추출 가능
VIT(Vision Transformer)로 하고자 하는 것 → Image Classification
입력된 이미지가 어떤 클래스인지 분류하는 것
Network
자연어처리에 사용된 Transformer 내부 구조와 차이가 있음
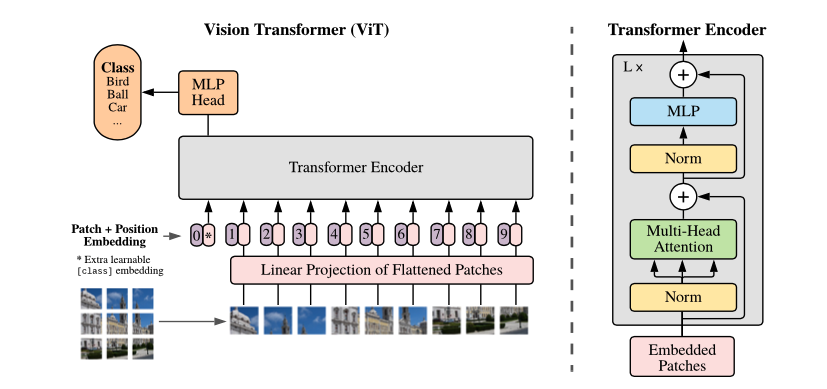
Embedded Patches
- 입력 이미지를 9개의 Patch로 나눔
- 각각의 Patch들을 순서대로 Embedding 하여, Transformer Encoder 입력으로 넣음
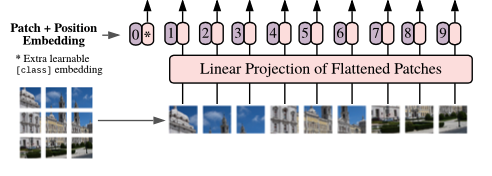
Patch는 순서가 중요하므로, 가장 앞 부분에 Position Embedding을 넣어줌
Position Embedding을 각각에 맞는 Patch에 더해줌으로써, 위치 값을 보존해줄 수 있음
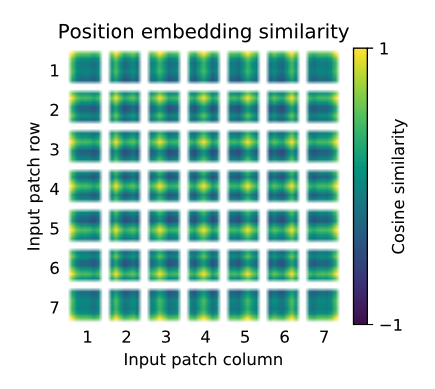
(왼쪽 상단의 Patch의 경우, 왼쪽 상단이 가장 활성화 되어있음)
Encoder
-
각각의 Embedding 된 9개의 Patch가 Encoder의 입력으로 들어가게 되면,
각각을 모두 Normalization 취하고, Concatenation 시켜서 합침 -
Query, Key, Value 형태로 나눠주고, Self-Attention 수행함
-
[ Skip Connection ] Norm + Attention 수행한 값과, 수행하지 않은 값을 더함
-
다시 Normalization 취하고, MLP를 통과시킴
-
[ Skip Connection ] Norm + MLP 수행한 값과, 수행하지 않은 값을 더함
-
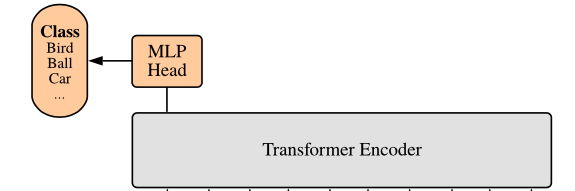
Encoder의 최종 ouput 출력
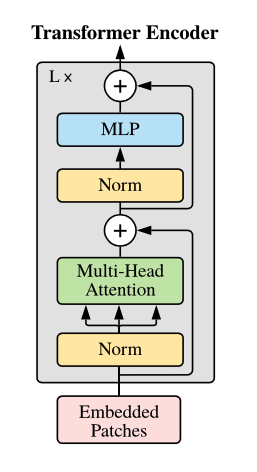
Encoder의 output은 MLP를 거쳐, 이미지의 클래스를 분류함
A nice GIF visualization of the architecture
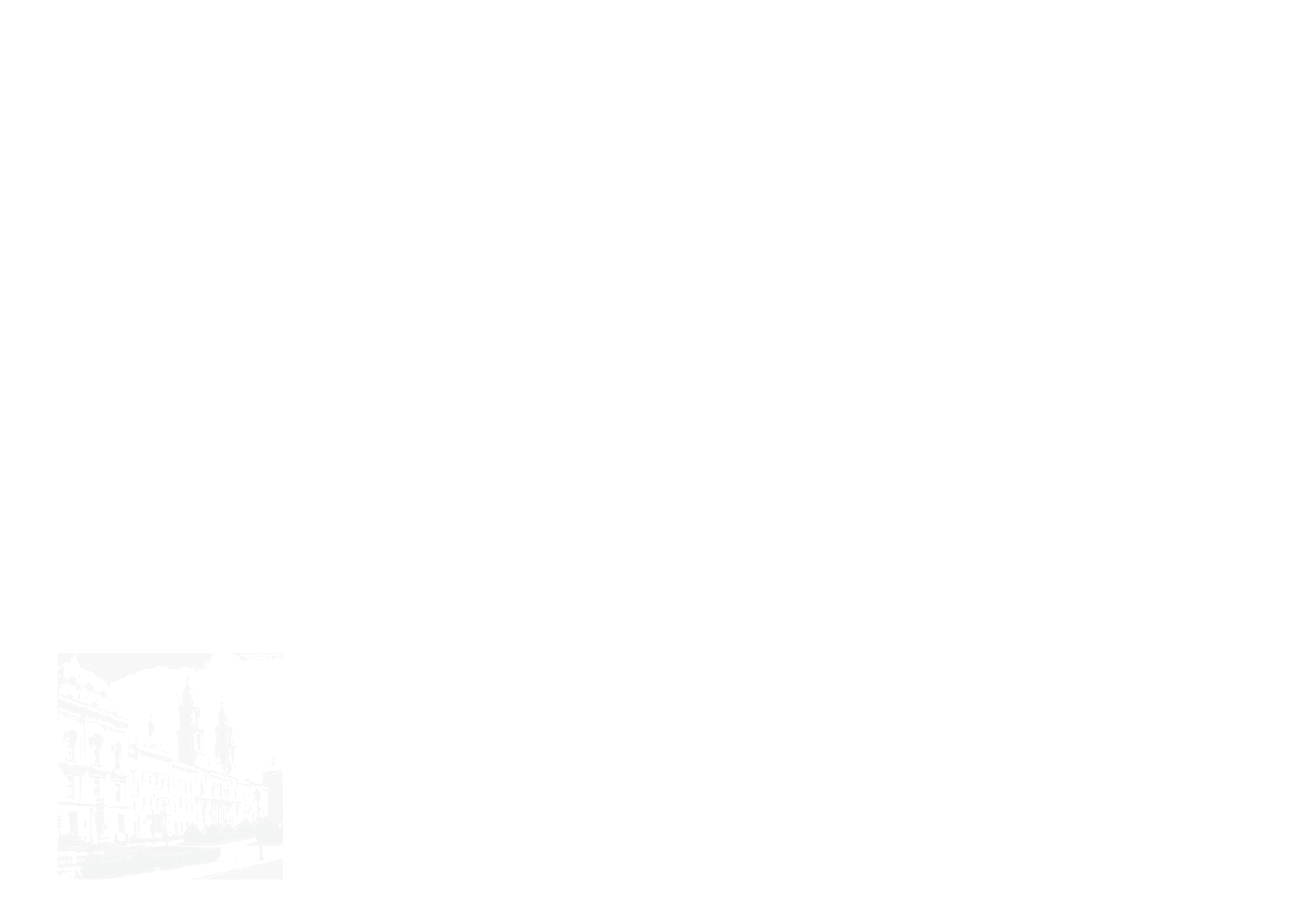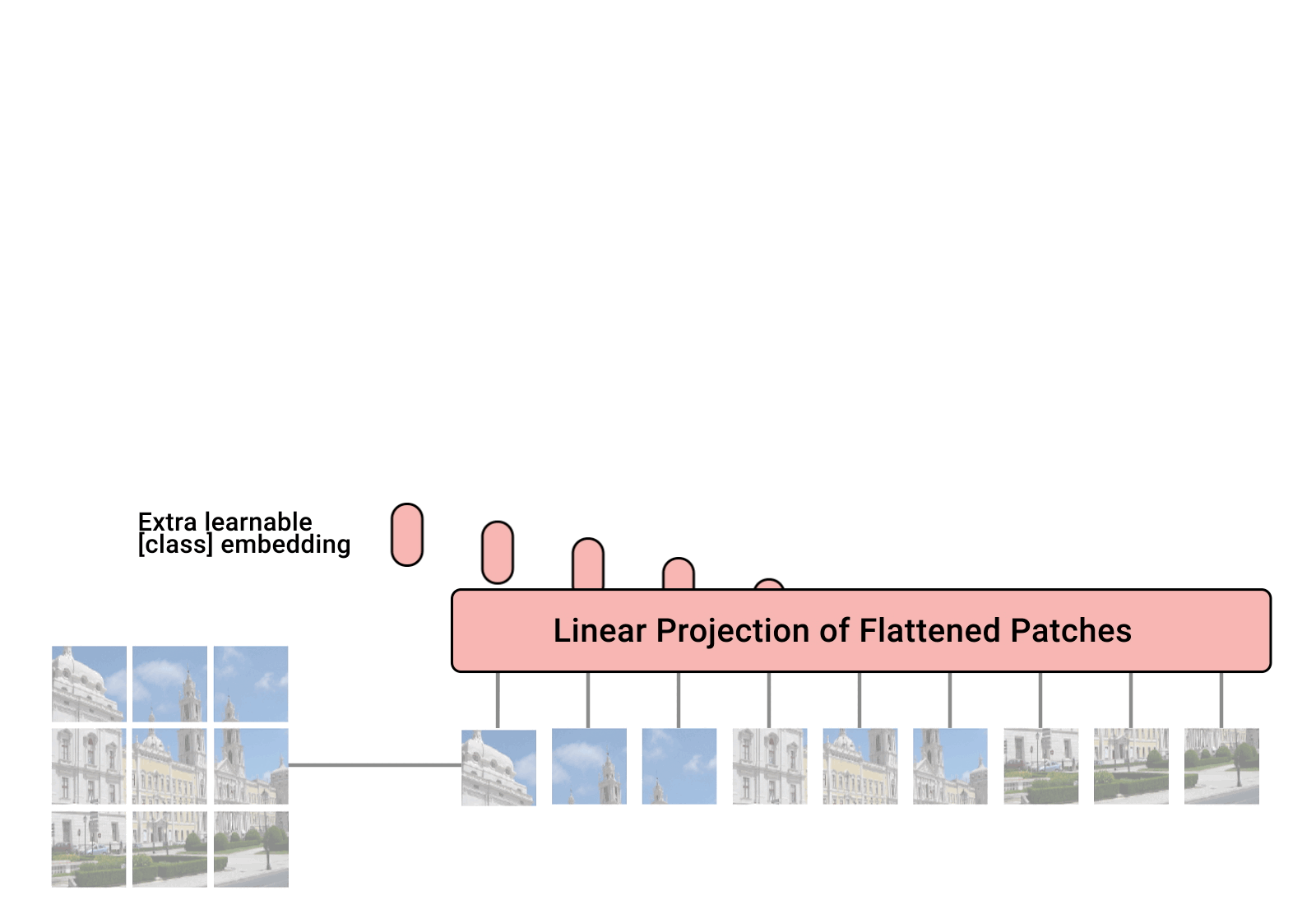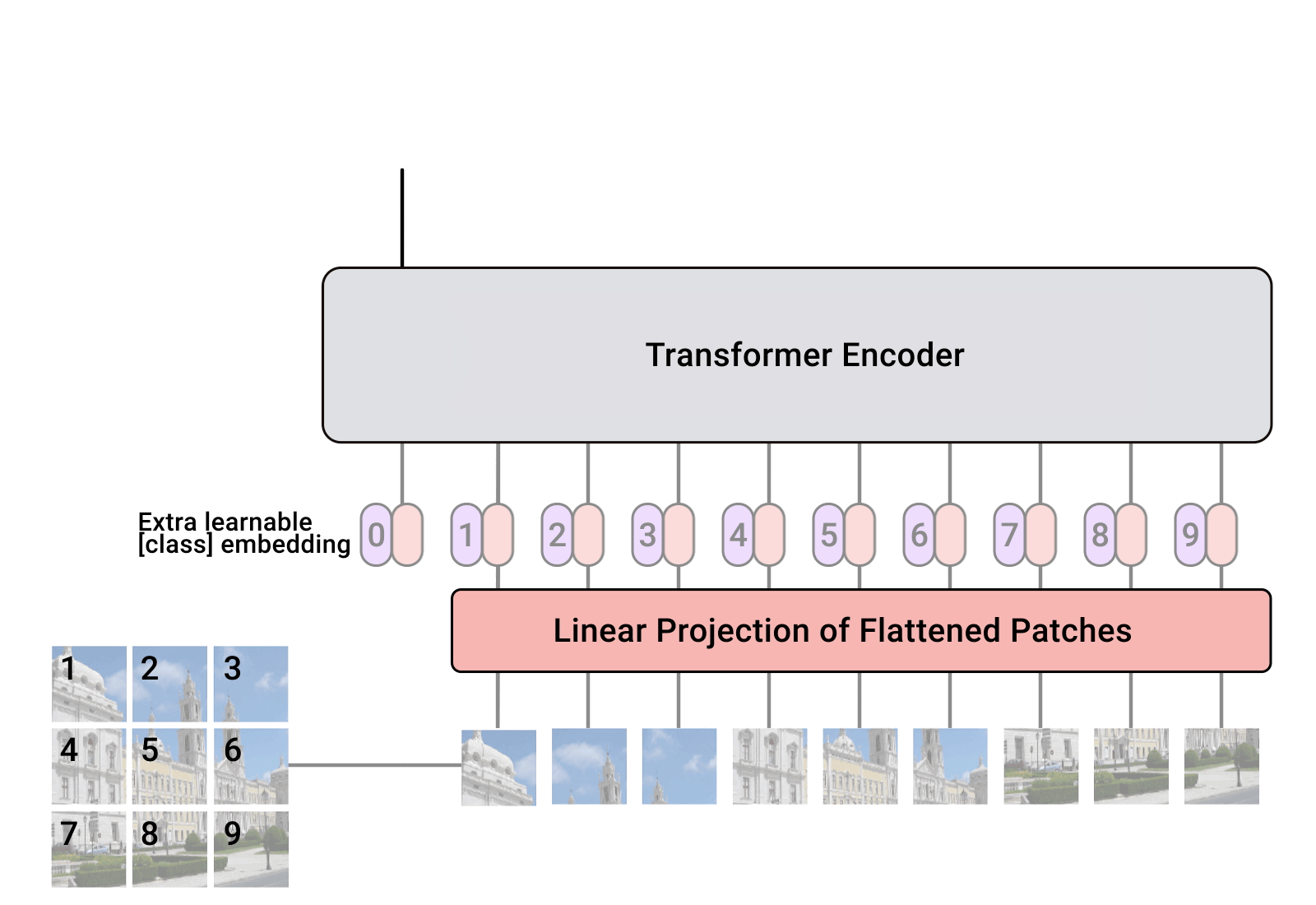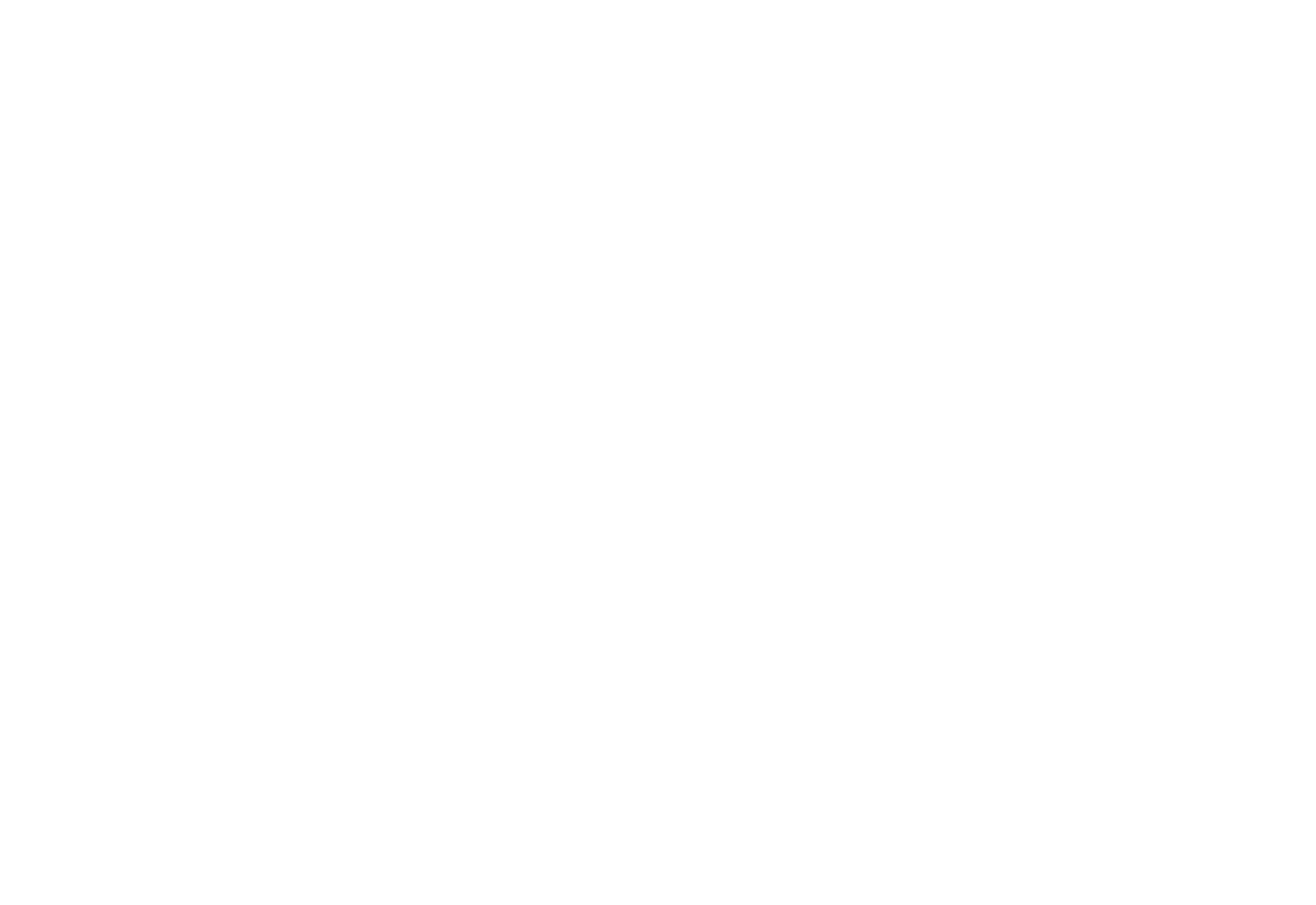
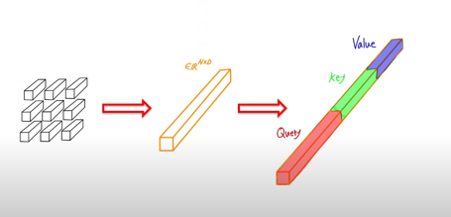
자세한 이해를 위해
- 원본 이미지를 9개 Patch로 나누고, 각각의 Patch를 1차원으로 만듦
- Linear Projection으로 하나의 벡터로 만듦
- 3배 차원으로 늘리고, 3등분 하여 각각을 Query, Key, Value로 할당함
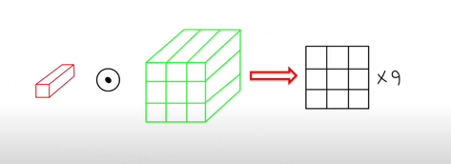
- Head의 개수만큼 Self-Attention 연산을 수행함
- 각 Query와 각 Key 간 행렬 곱 연산을 수행함
- Patch는 총 9개였으므로, 총 9개의 output이 나오게 됨
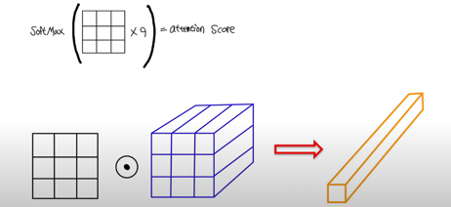
- 해당 값에 Softmax를 취해, Attention Score를 구함
- Attention Score와 각 Value 간 행렬 곱 연산을 수행함
- 최종적으로 Attention 모듈의 output 벡터 출력함
정리
(1) Linear Project 된 1차원 벡터인, 각 Patch들에 Position Embedding을 더해줌
(2) 그 값을 Normalization 시키고, Multi-Head Attention에 넣어줌 (Skip Connection으로 기존의 값 보존)
(3) 한 번 더 Normalization 시키고, MLP를 통과시킴 (Skip Connection으로 기존의 값 보존)
(4) 최종 output 벡터를 출력함
(5) 그 값을 MLP 모델에 넣어, Image Classification 수행함
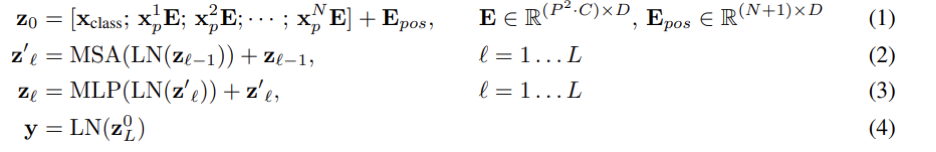
Hybrid Architecture
각각의 Patch를 Linear Projection으로 1차원 벡터로 만드는 것이 아니라, CNN으로 출력된 feature map을 Transformer의 입력으로 사용하는 방식 또한 가능하다고 말하고 있음
결론
ViT는 이미지를 작은 패치들로 분할하여, 표준 Transformer Encoder의 입력으로 사용함
ViT는 ImageNet과 같은 대규모 이미지 인식에서는 뛰어난 결과를 얻었지만, CIFAR10과 같은 소규모 데이터셋에서 처음부터 학습시킬 때는 성능이 떨어졌음
그 이유는 ViT는 CNN에 비해 inductive bias가 부족하기 때문임
하지만, 충분한 크기의 데이터가 제공되거나 모델이 대규모 데이터셋에 대해 pre-train 되었을 때 그 한계점이 극복될 수 있음
