기계 번역 분야의 최신 고성능 모델들은 Transformer 아키텍쳐를 기반으로 하고 있음
- GPT : Transformer Decoder 아키텍쳐 사용
- BERT : Transformer Encoder 아키텍쳐 사용
이전에는 기계 번역이나 language modeling을 위해, RNN, LSTM, GRU 같은 모델들이 제안되었음
소스 문장에 대한 문맥 정보를 고정된 크기의 context vector에 압축하는 방식
→ 병렬처리 어렵고, 메모리-속도 측면 비효율적인 한계점
본 논문에서는 오직 Attention 메커니즘만 사용하여 성능 향상 시킴
Attention
Attention을 위한 세 가지 입력 요소 : Query, Key, Value
- 물어보는 주체 → Query
- 물어보는 대상 → Key
Attention을 이용해, 한 문장 내의 특정 단어가 다른 단어들과 어떤 연관성을 가지고 있는지 구할 수 있음
ex) "I am a teacher."
'I'가 다른 단어들에 대해 어떤 연관성을 갖는지 측정한다면,
- Query : 'I'
- Key : 'I', 'am', 'a', 'teacher'
Query가 주어지면, 각각의 Key에 대한 Attention Score를 구하고
각 Attention Score에 Value 값들을 곱해서
가중치가 반영된 결과값인 Attention Value를 구하는 것
Transformer
Attention 메커니즘만 활용해도, 다양한 자연어처리 task에서 좋은 성능을 낼 수 있음
→ RNN, CNN 필요하지 않음
하지만, RNN, CNN을 사용하지 않는다면, 문장 속 각 단어들의 순서 정보를 줄 수 없음
→ Positional Encoding 사용
Encoder - Decoder로 구성
Attention 과정을 여러 레이어를 거쳐 반복
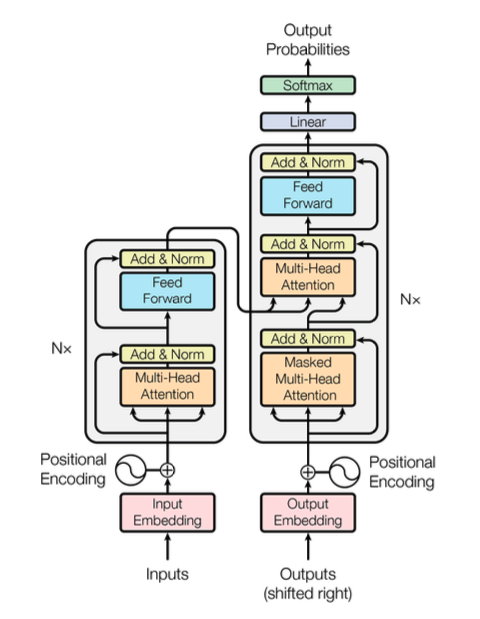
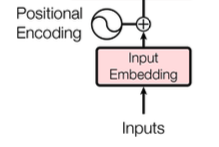
Input Embedding
Input Embedding Matrix :
ex) "I am a teacher."
단어 개수만큼 행(4)을 가지고, 임베딩 차원과 같은 크기의 데이터로 열 (논문에서는 512)이 채워짐
단어 각각의 위치 정보를 포함하고 있는 임베딩을 사용해야 하기 때문에, Positional Encoding 사용
이를 통해, [ 입력 문장에 대한 정보 + 단어의 위치 정보 ] 를 Attention의 입력으로 넣을 수 있음
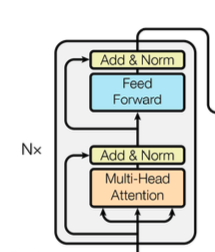
Encoder
Encoder Self-Attention :
인코더에서 한 문장 내의 각 단어가 서로에게 어떤 연관성을 갖고 있는지 구함
→ 전반적인 입력 문장에 대한 문맥 정보를 잘 학습하도록 함
Residual Learning :
레이어를 건너 뛰고 그대로 다음 레이어로 넣어주는 기법
기존 정보를 그대로 입력 받으면서, 추가적으로 잔여 부분만 학습하도록 함
→ 전반적인 학습 난이도 낮아져, 초기의 모델 수렴 속도가 높아짐 (성능 향상)
[ Attention 수행된 값 + Residual Learning 으로 더해진 값 ] 에 Normalization 수행함
이렇게 Attention + Normalization 반복하는 방식으로, 여러 인코더 레이어를 중첩해서 사용함
가장 마지막 인코더 레이어에서 나온 출력값이 디코더의 입력으로 들어가게 됨
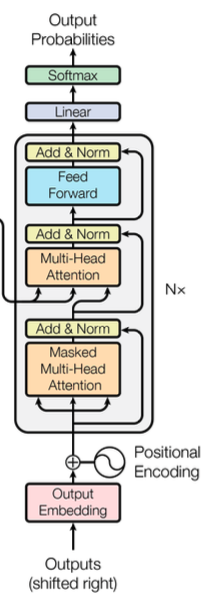
Decoder
인코더와 마찬가지로, Positional Encoding 사용해 [ 입력 문장에 대한 정보 + 단어의 위치 정보 ] 로 Attention의 입력으로 들어감
디코더 레이어에는 2개의 Attention 메커니즘이 들어감
-
Masked Decoder Self-Attention :
디코더에서 각 단어들이 서로에게 어떤 가중치를 가지는지 구하도록 하여, 출력되고 있는 문장에 대한 전반적인 표현을 학습하게 함
Masking 사용하여 모든 출력 단어를 참고하지 않고, 앞 쪽에 등장했던 단어들만 참고하도록 함 -
Encoder-Decoder Attention :
디코더의 출력 단어가 인코더의 출력 정보를 받아와 사용할 수 있도록 함
→ 출력되고 있는 단어가 소스 문장에서의 어떤 단어와 어떤 연관성이 있는지 구함
(디코더의 Query가 인코더의 Key, Value를 참조하는 것)
ex) 입력 : "I am a teacher." / 출력 : "나는 선생님입니다."
출력되고 있는 단어가 '선생님' 이라면, 그것이 'I', 'am', 'a', 'teacher' 중 어떤 단어와 가장 높은 연관성을 갖는지 구할 수 있음
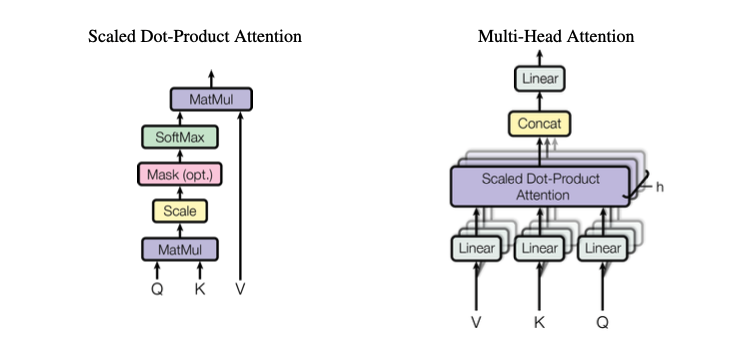
Multi-Head Attention
Transformer에 사용되는 Attention은 여러 개의 Head를 가짐
Scaled Dot-Product Attention :
각각의 Query가 각각의 Key에 대해 어떤 가중치(확률값)를 갖는지 계산함
-
Query, Key가 입력으로 들어가면,
Dot Product - Scaling - (Masking) - Softmax 수행
→ Attention Energies 구함 -
그렇게 만들어진 가중치(확률값)와 Value 값을 곱하여, 가중치가 적용된 결과를 만듦
→ Attention Value 구함
Scaled Dot-Product Attention에 Query, Key, Value가 들어갈 때, h개의 서로 다른 Query, Key, Value 쌍으로 구분되어 들어감
→ h개의 서로 다른 Attention 컨셉을 만들어, 다양한 특징을 학습하도록 유도
- 서로 다른 Head끼리 각각 Query, Key, Value 쌍을 받아서 Attention 수행
- 각 Head에 대한 Attention 결과값을 일 자로 쭉 이어붙이는 Concatenation 수행
Why Self-Attention
- 각 레이어마다 계산 복잡도가 줄어듦
- Recurrence 제거하여, 병렬처리 가능
- long-range dependency 처리 가능
- 신경망을 설명 가능한 형태로 만듦
CNN, RNN 같이 Recurrent 한 레이어를 모두 빼버리고, Attention 메커니즘만 활용한
Transformer 아키텍쳐를 제안함
이를 통해, 높은 병렬성을 얻고 성능 개선함
