본 논문은 모델 아키텍처 변경에 주로 집중을 했던 이전 연구들과 달리, 성능 개선을 이끌 수 있는 각종 테크닉들에 대해 강조함
사소한 트릭들의 조합으로 비슷한 학습 시간에서 정확도 향상을 이끌어 낼 수 있음을 보임
Training Procedures
일반적인 전처리 기법
-
이미지를 랜덤으로 선택해 32-bit floating point type으로 변경
-
이미지를 랜덤하게 Crop 하고 동일한 사이즈로 조정 (pre-trained model에 맞는 input size)
-
Flip 기법, 채도/명도 변경, PCA 노이즈 입히기 등 데이터 증강
-
Normalize 하여 input으로 사용
-
Randomly sample an image and decode it into 32-bit floating point raw pixel values in [0, 255]
-
Randomly crop a rectangular region whose aspect ratio is randomly sampled in [3/4, 4/3] and area randomly sampled in [8%, 100%], then resize the cropped region into a 224-by-224 square image.
-
Flip horizontally with 0.5 probability.
-
Scale hue, saturation, and brightness with coefficients uniformly drawn from [0.6, 1.4].
-
Add PCA noise with a coefficient sampled from a normal distribution N (0, 0.1).
Efficient Training
Large-batch training
GPU가 허용하는 한 batch size를 최대한 키우는 것이 좋고, batch size를 키우는 만큼 더 많은 epoch를 줘야 하지만 학습 시간이 증가하는 문제 발생
-
Linear scaling learning rate
batch size가 크다는 것은 해당 batch로 얻은 gradient 값을 더 신뢰할 수 있다는 의미이므로, 더 큰 learning rate를 사용할 수 있음따라서, batch size를 키울 때, learning rate도 선형적으로 함께 증가시켜, 학습 시간이 늘어나는 문제를 개선함
-
Learning rate warmup
learning rate는 초반에는 점점 증가하다가, 특정 값에 도달하면 워밍업을 마치고 천천히 감소하도록 함 -
Zero γ
ResNet의 residual block 끝 부분에 들어가는 배치 정규화에서, γ 값을 0으로 초기화하여 학습 초기의 학습 난이도를 낮춤 -
No bias decay
일반적으로 모든 weight, bias에 대해 decay를 적용시키지만, weight에 대해서만 decay를 적용한 경우 성능이 향상됨
Low-precision training
기존과 달리 16-bit floating point를 활용해 계산 속도를 향상시킴
16-bit + 32-bit floating point를 잘 결합해 사용하는 테크닉
→ Efficient Training 적용 결과, 속도 개선 및 성능 향상을 보임
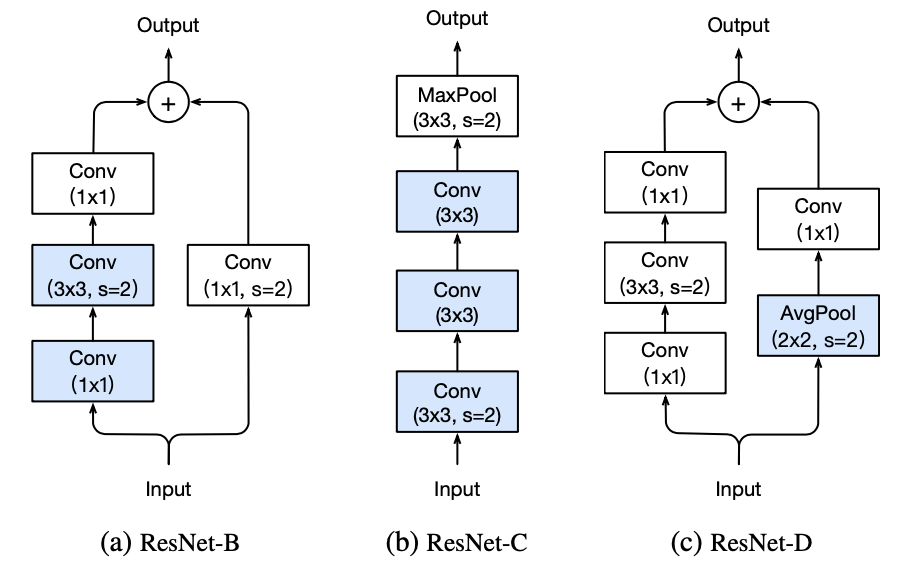
Model Tweaks
모델 아키텍쳐의 매우 일부만 바꿨음에도 불구하고 성능 향상을 이룰 수 있음을 보임
(Tweaks : 조금씩 바꾸거나 조정하는 작업)
ResNet-A → ResNet-B → ResNet-C
총 3번에 걸쳐 구조를 점진적으로 바꿈으로써 정확도가 향상됨을 보임
Training Refinements
Efficient Training과 Model Tweaks에 더불어 추가적으로 학습 시 적용할 수 있는 4가지 트릭들에 대해 설명함
Cosine Learning Rate Decay
learning rate가 특정 epoch까지는 선형적으로 증가시키고, Cosine 함수를 따라 점진적으로 감소하도록 함
Label Smoothing
정답인 레이블에 대해서만 확률을 모두 주는 것이 아닌, 오답인 레이블에 대해서도 조금씩 확률을 부여하도록 Loss를 구성함
Knowledge Distillation
큰 데이터셋으로 학습된 Teacher model이 존재할 때, 그것의 결과값을 정답값으로 삼아 Student model을 학습 시켜, 작은 모델 복잡도를 가지고 높은 성능을 낼 수 있도록 함
Mixup Training
학습 데이터셋으로부터 두 개의 이미지와 레이블을 뽑고, 이미지와 레이블을 각각 섞어서 새로운 이미지와 레이블을 생성함
이렇게 생성된 데이터를 학습 데이터셋에 추가하여 모델의 학습 능력과 일반화 성능을 향상 시킴
본 논문은 ResNet 모델에 다양한 트릭들을 적용한 결과들을 비교하고, 결론적으로 이미지 분류에서 사소한 트릭의 조합이 성능 향상을 이끌어 낼 수 있음을 보임
추가로 Object Detection, Semantic Segmentation에서도 유사한 성능 향상을 얻을 수 있는 지 실험함
Object Detection과 달리 Semantic Segmentation에서는 Cosine Decay만 적용 했을 때 성능 향상을 보임
Semantic Segmentation은 pixel 단위로 어떤 클래스인지 분류하는 Task임
Label Smoothing, Knowledge Distillation, Mixup 같은 기법이 pixel blurring을 유도할 수 있기 때문에, pixel-level accuracy 측면에서 성능이 하락한 것일 수 있음
