'Attention Is All You Need' 논문을 읽고 이해가 부족하여 교수님께서 보내주신 자료로 다시 한 번 공부했다.
Machine Translation(기계 번역)에서의 Transformer는 특정 언어의 문장을 입력으로 받고, 그것을 다른 언어로 번역해 출력한다.

Transformer의 내부는 인코더와 디코더로 구성되어있다.
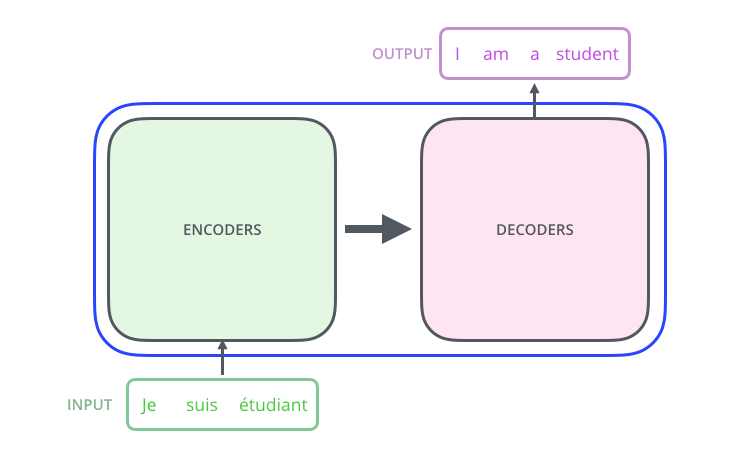
인코딩 구성요소는 인코더의 스택으로 구성되어있다.
디코딩 구성요소도 디코더의 스택으로 구성되어있다.
(논문에서는 6개의 인코더, 디코더 사용)
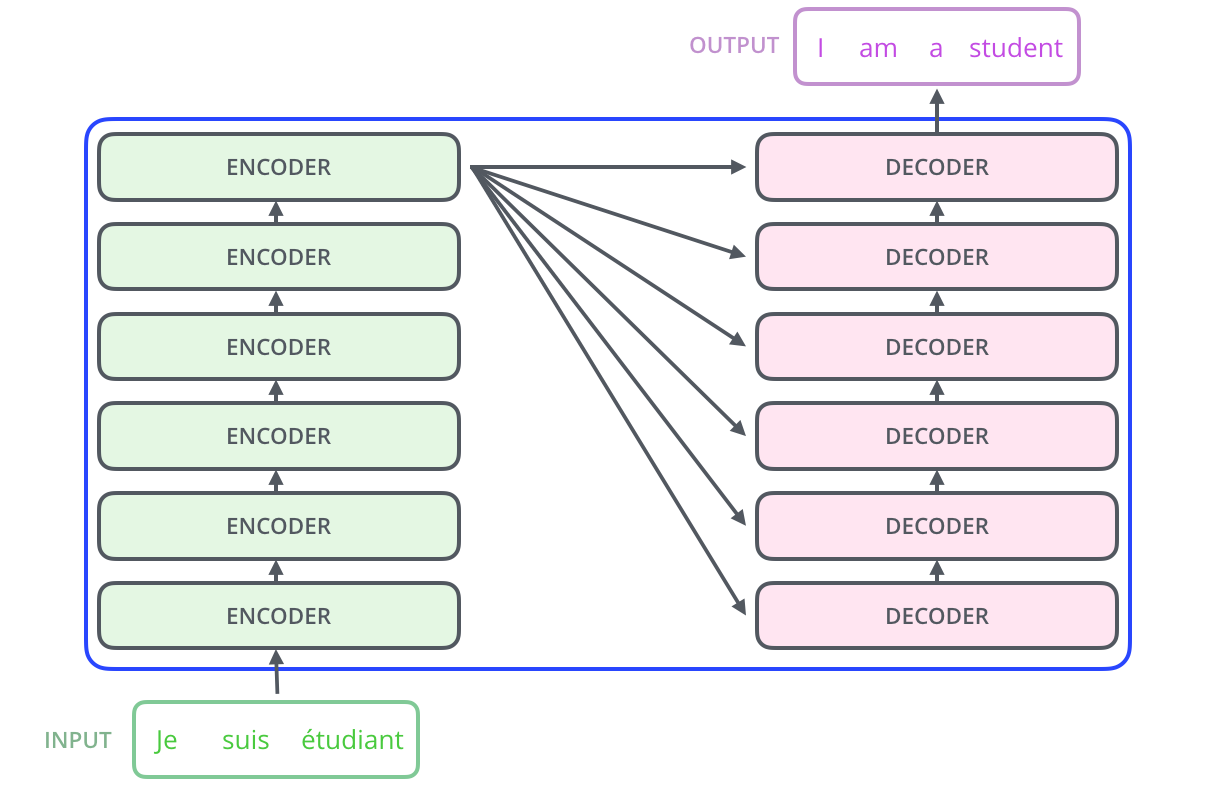
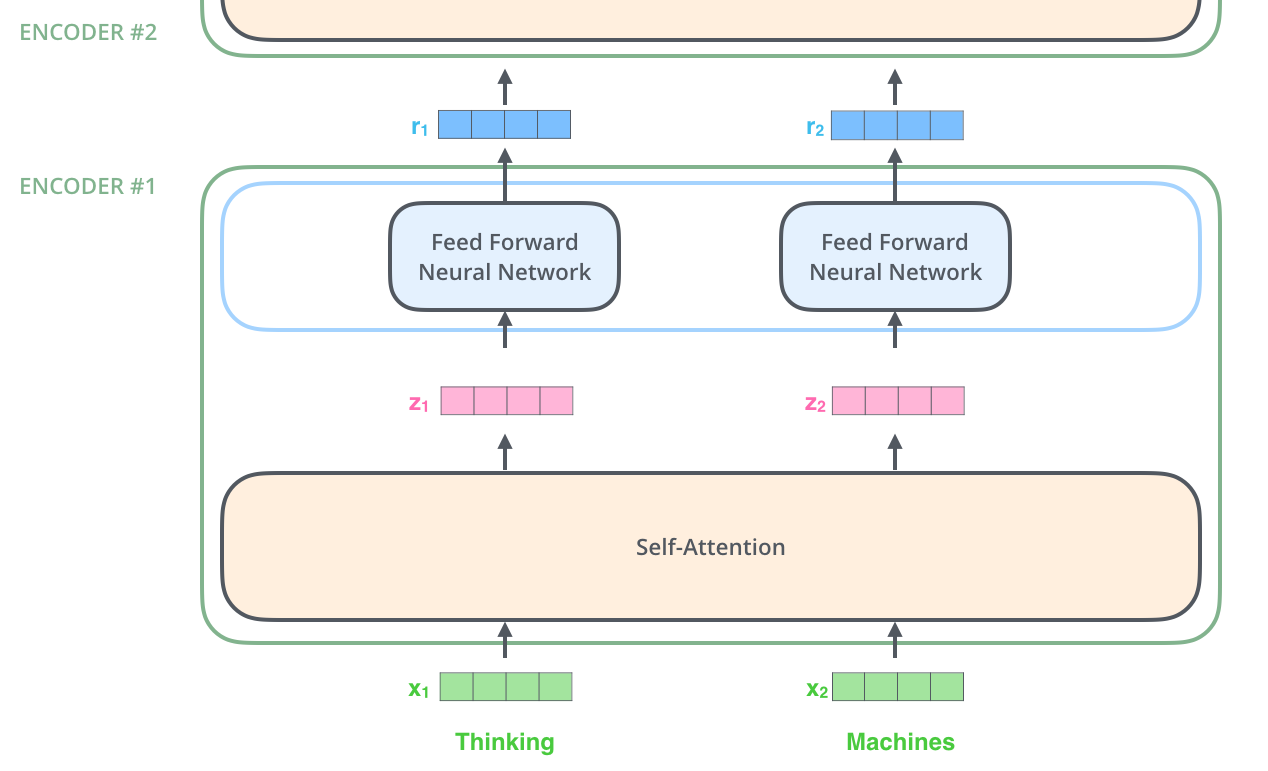
Encoder & Decoder
인코더는 모두 같은 구조를 가지며, 두 개의 하위 레이어로 나뉜다.
- Self-Attention + Feed Forward Neural Network
디코더도 모두 같은 구조를 가지며, 동일한 두 개의 하위 레이어를 가지고 있다.
하지만, 디코더에는 입력 문장 속 관계에 집중할 수 있도록 도와주는 Attention 레이어가 추가로 존재한다.
- Self-Attention + Encoder-Decoder Attention + Feed Forward Neural Network
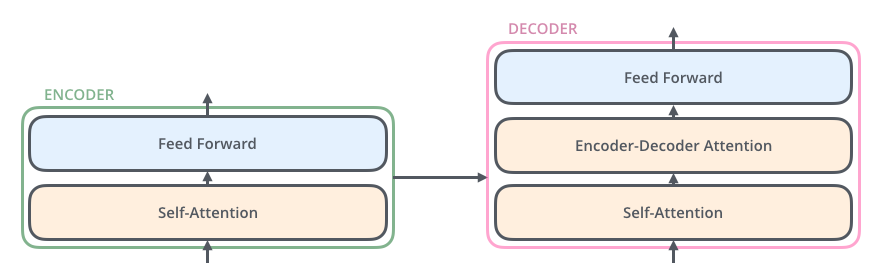
Self-Attention Layer
인코더로 들어온 input은 가장 먼저 Self-Attention 레이어를 통해 흐른다.
(이 레이어는 인코더가 특정 단어를 인코딩 할 때, 문장 속 다른 단어들을 살펴볼 수 있도록 도와준다.)
Feed Forward Neural Network
Self-Attention Layer의 output은 Feed Forward Neural Network에 들어간다.
(각 output(벡터)에 정확히 똑같은 Feed Forward Network가 독립적으로 적용된다.)
임베딩 알고리즘을 사용하여, 입력된 단어를 벡터로 변환함으로써 시작한다.
이러한 단어 임베딩은 최하단 인코더에서만 발생한다.
- 각 단어를 벡터(size 512)로 임베딩
- ex) X1, X2, X3

모든 인코더들은 벡터들의 리스트를 받아 처리한다고 할 수 있다.
- [ X1, X2, X3 ] -> ENCODER
리스트의 사이즈는 기본적으로 학습 데이터에서 가장 긴 문장의 길이로 설정한다.
단어 임베딩 벡터들로 채워진 입력 시퀀스가 구성되면,
각 벡터들은 인코더의 두 레이어를 통과하고 다음 인코더로 전달된다.
- Self-Attention Layer -> Feed Forward Layer -> ENCODER
각 position에 해당하는 단어 임베딩 벡터는 자기만의 path를 통해 흐른다.
- Self-Attention Layer : 각 path 사이 dependencies가 있다.
- Feed Forward Layer : 각 path 사이 dependencies가 없다.
따라서, Feed Forward Layer를 통과할 때는 다양한 path가 병렬적으로 실행될 수 있다.
”The animal didn't cross the street because it was too tired"
위 문장이 input으로 들어와, 이를 번역하고자 한다.
it이 animal과 street 중 무엇을 가리키는 것인지 알고리즘은 알기 어렵다.
Self-Attention은 각 단어를 더 잘 인코딩 하는데 도움이 되는 단서를 입력 시퀀스 속 다른 단어들에게서 찾는다.
따라서 모델이 it을 처리할 때, it과 animal의 연관성을 파악하여 인코딩 할 수 있다.
Self-Attention
먼저 벡터를 이용한 Self-Attention 계산을 단계 별로 살펴본다.
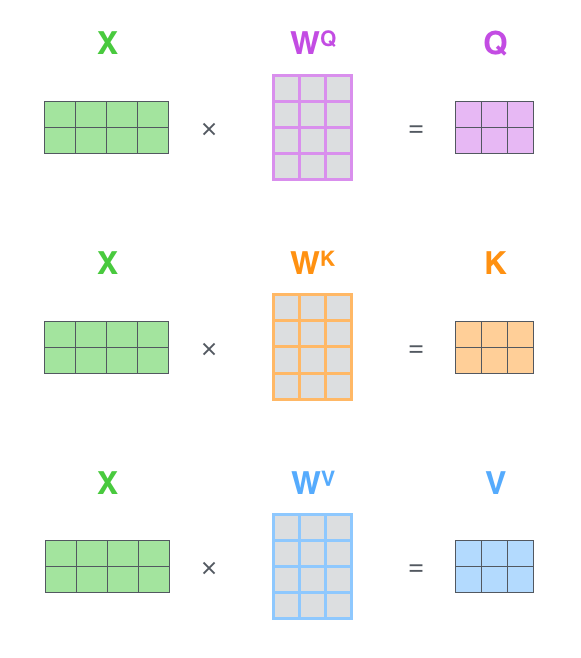
- 인코더의 입력으로 들어온 각 단어 임베딩 벡터로부터 Query/Key/Value 벡터를 생성한다.
Query/Key/Value 벡터는 단어 임베딩 벡터와 Query/Key/Value 가중치 행렬의 행렬곱 연산으로 생성된다.
-
입력 단어 : 'Thinking', 'Machines'
-
단어 임베딩 벡터 : X1, X2
-
Query/Key/Value 가중치 행렬 : Wq, Wk, Wv
-
Query/Key/Value 벡터 :
X1 x Wq = q1, X1 x Wk = k1, X1 x Wv = v1
X2 x Wq = q2, X2 x Wk = k2, X2 x Wv = v2
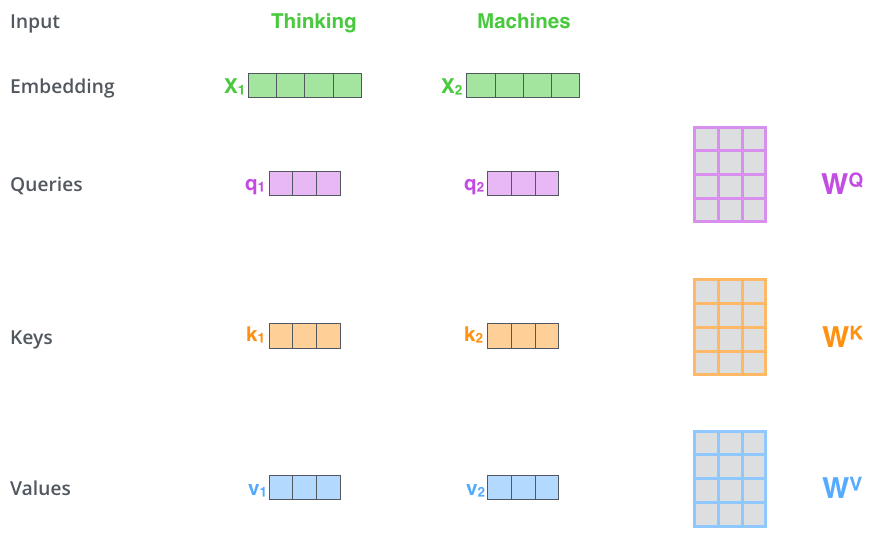
Query/Key/Value 가중치 행렬은 학습 과정에서 학습된 행렬이다.
새로 생성된 Query/Key/Value 벡터는 단어 임베딩 벡터보다 차원이 더 작다.
Query/Key/Value 벡터는 64차원이고, 임베딩 벡터 및 인코더의 입출력 벡터는 512차원이다.
반드시 차원이 더 작아야 할 필요는 없다.
(논문에서는 Multi-head Attention 연산을 일정하게 하기 위해 이를 선택함)
- Attention Score를 계산한다.
- 특정 단어를 인코딩 할 때, 입력 문장 속 다른 단어들에 대해 얼마나 초점을 둘 지의 정도
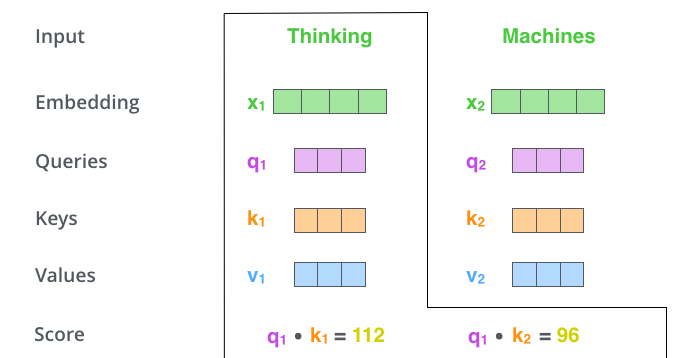
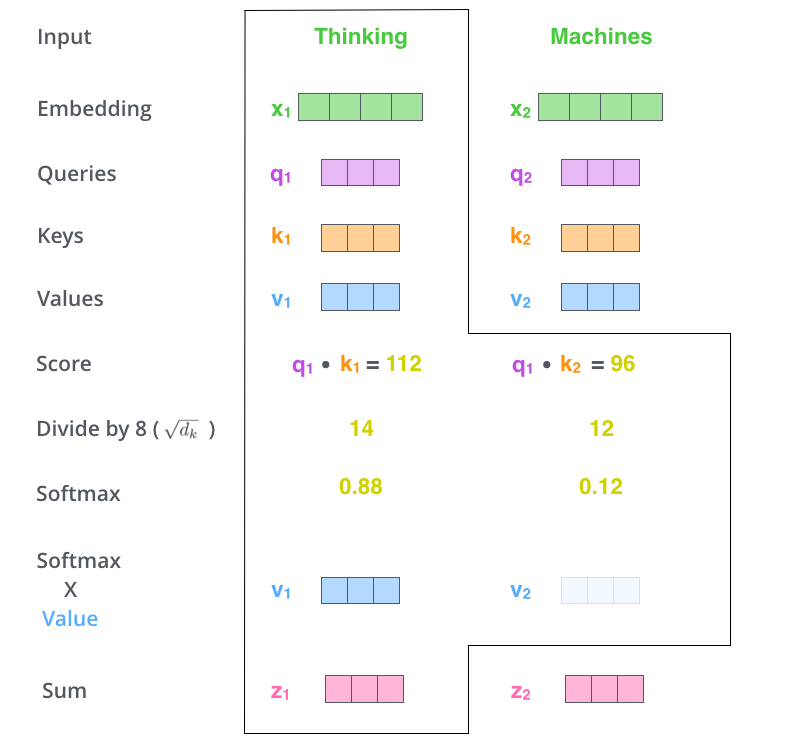
'Thinking'을 인코딩을 위한 Attention Score를 계산해보자.
- 선택한 단어 : 'Thinking'
- 단어 임베딩 벡터 : X1
- Query 벡터 : q1
- Key 벡터 : k1
- Value 벡터 : v1
Attention Score는 Query 벡터와 Key 벡터의 내적 연산으로 계산된다.
- 첫 번째 점수 : q1 · k1
- 두 번째 점수 : q1 · k2
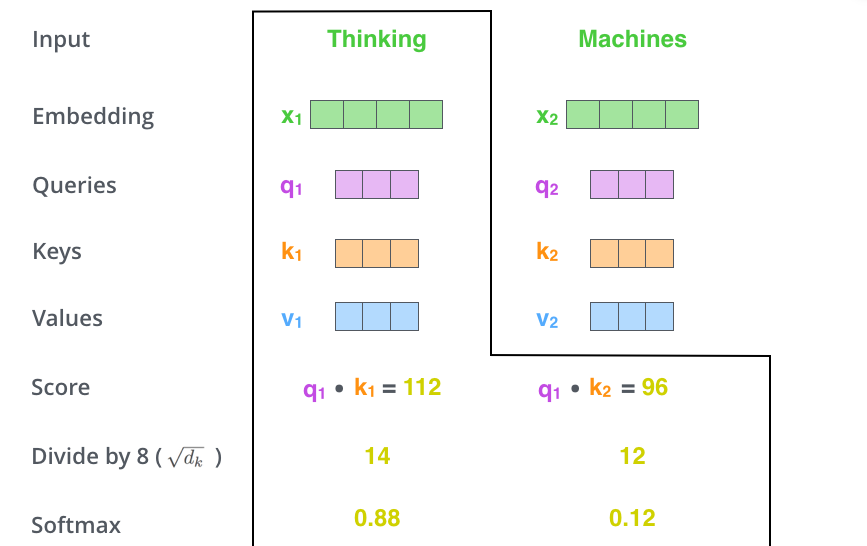
- Attention Score를 Key 벡터의 차원의 제곱근으로 나눈다.
논문에서는 Query/Key/Value 벡터의 차원을 64로 설정한다.
따라서, 위에서 구한 Attention Score를 8로 나눠준다.
이를 통해 더 안정적인 gradients를 얻을 수 있다.
- Softmax를 취한다.
Softmax를 통해 Attention Score를 양수이자, 총합이 1이 되도록 한다.
Softmax Score는 해당 position에서 각 단어가 얼마나 표현되어야 하는 지를 결정한다.
일반적으로 해당 position에 위치한 단어의 Score가 가장 높겠지만, 현재 단어와 관련 있는 다른 단어에도 주목하는 것이 유용할 수 있다.
즉, Self-Attention은 해당 position에서 가장 관련이 높은 단어에 집중하면서도, 다른 관련 단어들도 적절히 고려한다.
- 각 Value 벡터에 Softmax Score를 곱한다.
Softmax Score는 각 단어의 중요도를 표현하는 값으로, 값이 클수록 해당 단어에 더 많은 가중치가 부여된다.
이 값을 각 Value 벡터에 곱함으로써, 집중하고자 하는 단어의 값은 보존하고 관련 없는 단어의 영향을 최소화시킨다.
작은 수를 곱해 특정 단어의 값을 상대적으로 작게 만들어, 모델이 중요한 단어에 더 집중할 수 있도록 할 수 있다.
- 가중치가 적용된 Value 벡터들을 합한다.
이를 통해 현재 단어와 관련 있는 다른 단어들의 정보를 포착하고, 그들의 의미적인 상호작용을 반영한 Representation을 생성한다.
이러한 과정으로 Self-Attention Layer의 output이 출력된다.
해당 output은 Feed Forward Layer에 전달될 수 있다.
실제 구현에서는 위와 같은 벡터가 아닌 행렬로 수행된다.
다음으로는 행렬을 이용한 Self-Attention 계산을 살펴본다.
- 인코더의 입력으로 들어온 전체 단어 임베딩 행렬로부터 Query/Key/Value 행렬을 생성한다.
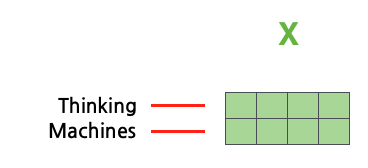
단어 임베딩들을 하나의 행렬로 패킹한다.
이 행렬에서 각 행은 문장에 들어있는 각 단어에 해당한다.
학습시킨 가중치 행렬과 행렬곱 연산을 수행한다.
-
단어 임베딩 행렬 : X
-
Query/Key/Value 가중치 행렬 : Wq, Wk, Wv
-
Query/Key/Value 행렬 : X x Wq = q, X x Wk = k, X x Wv = v
- 나머지 단계를 하나의 공식으로 압축하여 수행한다.
- Attention Score 계산 - Query 행렬과 Key 행렬 간 내적 연산
- Key 행렬의 차원의 제곱근으로 나누기
- Softmax 취하기
- Value 행렬에 Softmax Score 곱하기
이를 통해 Self-Attention Layer의 output을 출력한다.
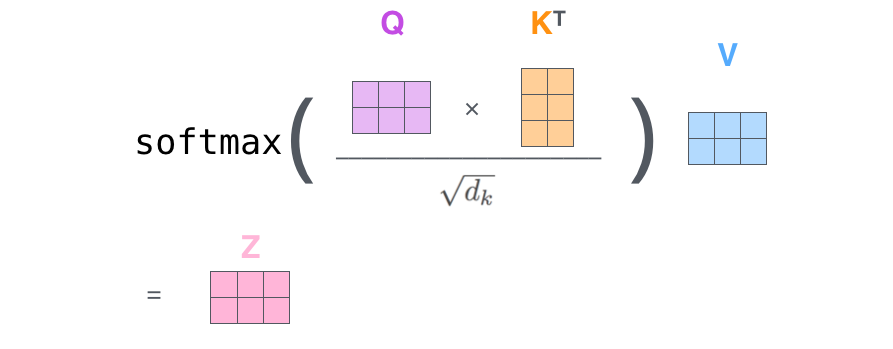
Multi-head Self-Attention
본 논문은 Multi-head Self-Attention 메커니즘으로 Self-Attention Layer를 더욱 다듬었다.
Multi-head Self-Attention은 여러 개의 Attention Head를 사용하여 모델이 입력 시퀀스의 다양한 위치에 집중할 수 있는 능력을 향상시킨다.
각 Head는 독립적으로, 학습된 Query/Key/Value 가중치 행렬을 갖고 서로 다른 Query/Key/Value 행렬을 생성한다.
즉, 서로 다른 관점에서 입력 시퀀스를 처리할 수 있는 것이다.
따라서 모델은 한 번의 Attention만 사용하는 것보다 더 다양한 정보를 수집할 수 있다.
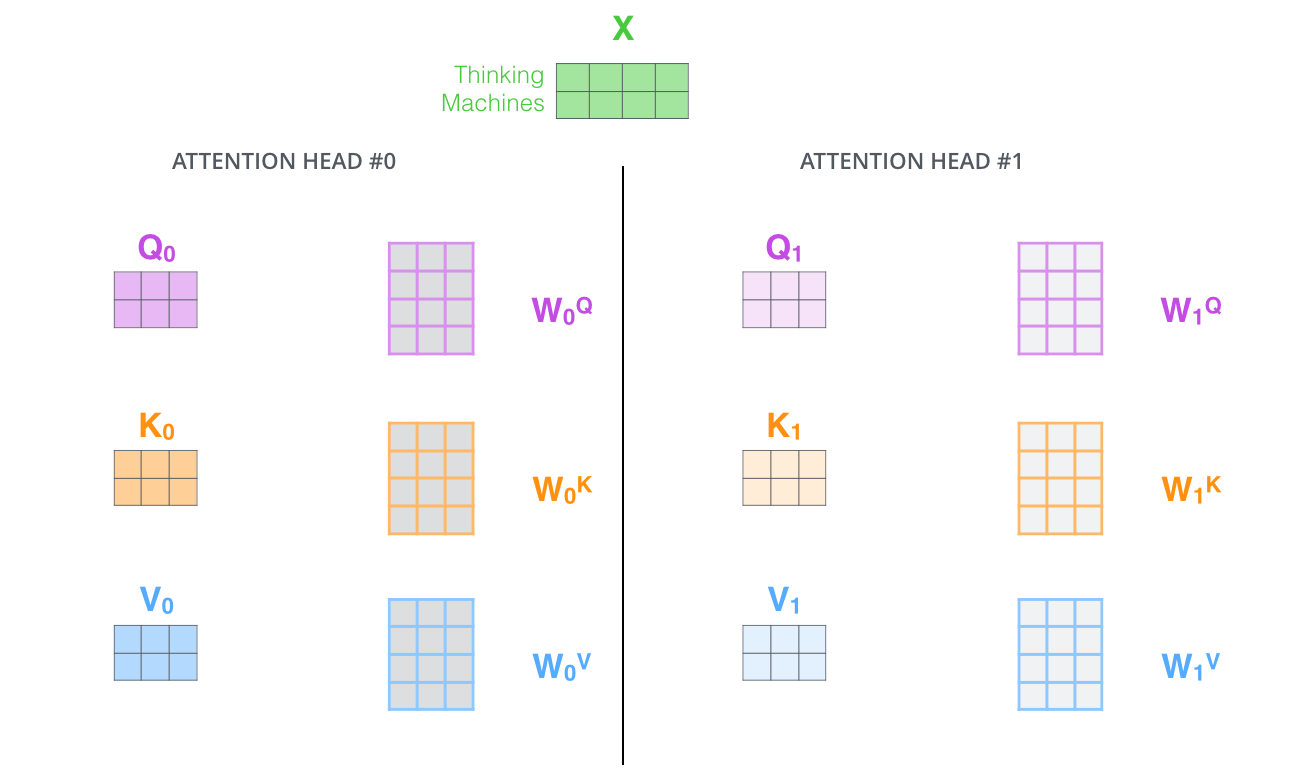
Transformer에서는 총 8개의 Head를 사용한다.
8개 Head에서 Self-Attention 과정이 이루어지면,
8개의 서로 다른 가중치 행렬에 의해, 8개의 Z 행렬이 생성된다.
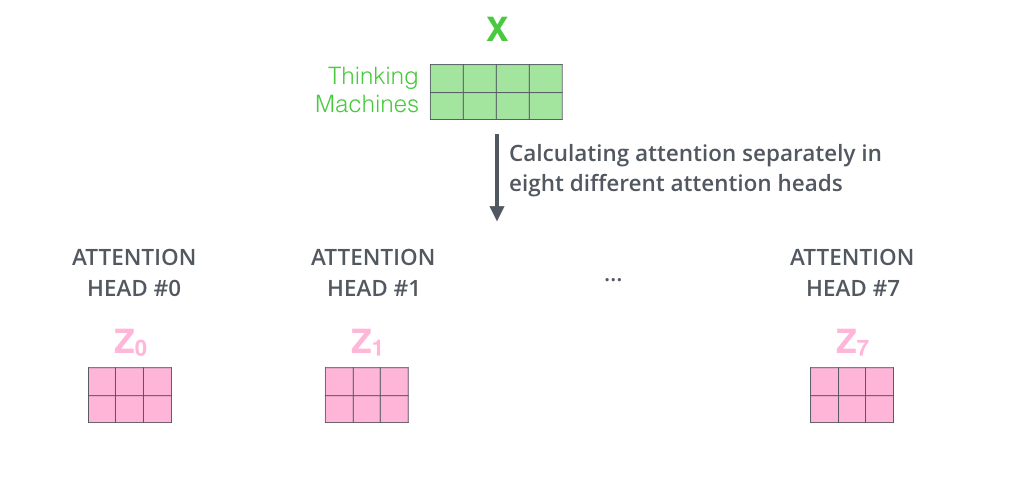
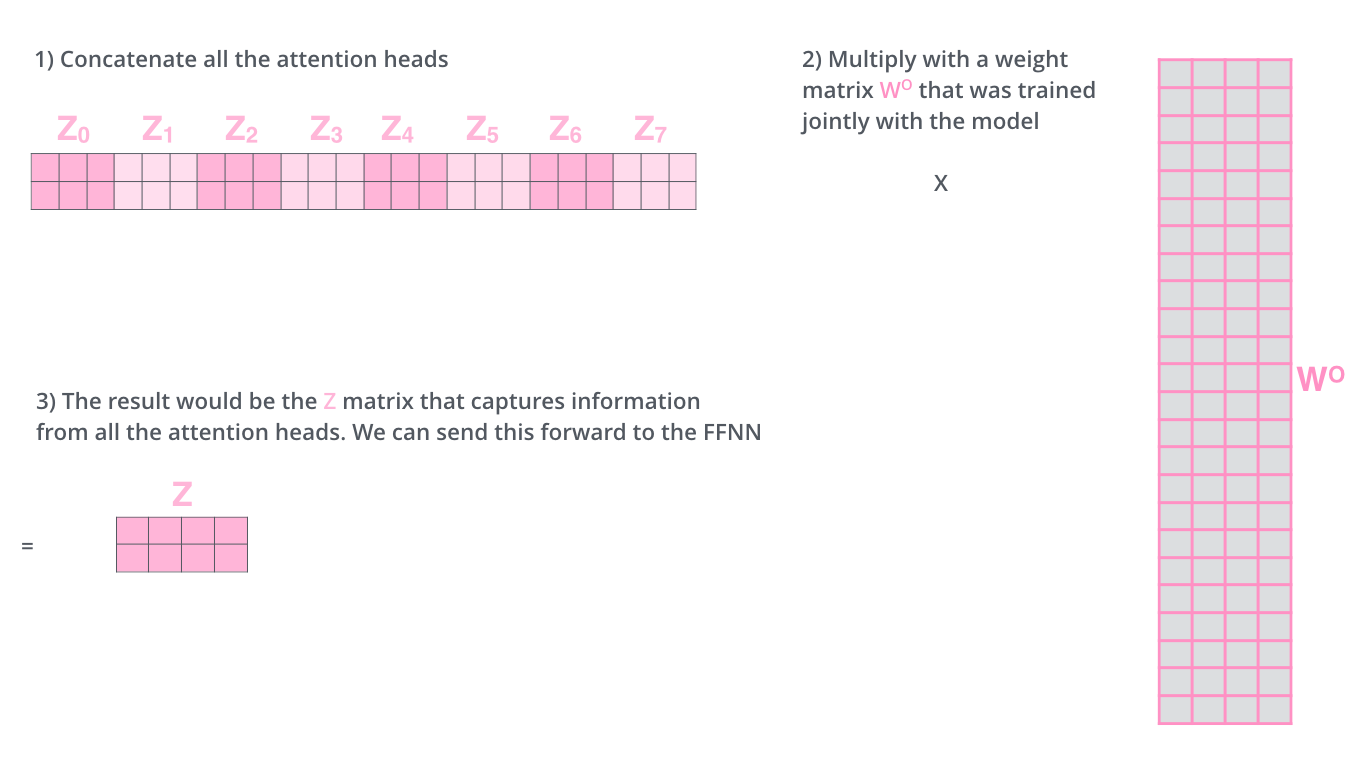
이후에 등장하는 Feed Forward Layer는 하나의 행렬을 입력으로 받는다.
그러므로 여러 개의 Z 행렬을 하나로 압축해야 한다.
모든 Z 행렬들을 concatenate 하고, 가중치 행렬 Wo로 곱해준다.
이를 통해 모든 Head의 정보를 담은 하나의 Z 행렬이 생성된다.
이제 이것을 Feed Forward Layer에 전달할 수 있다.
전체 과정을 다음과 같이 표현할 수 있다.
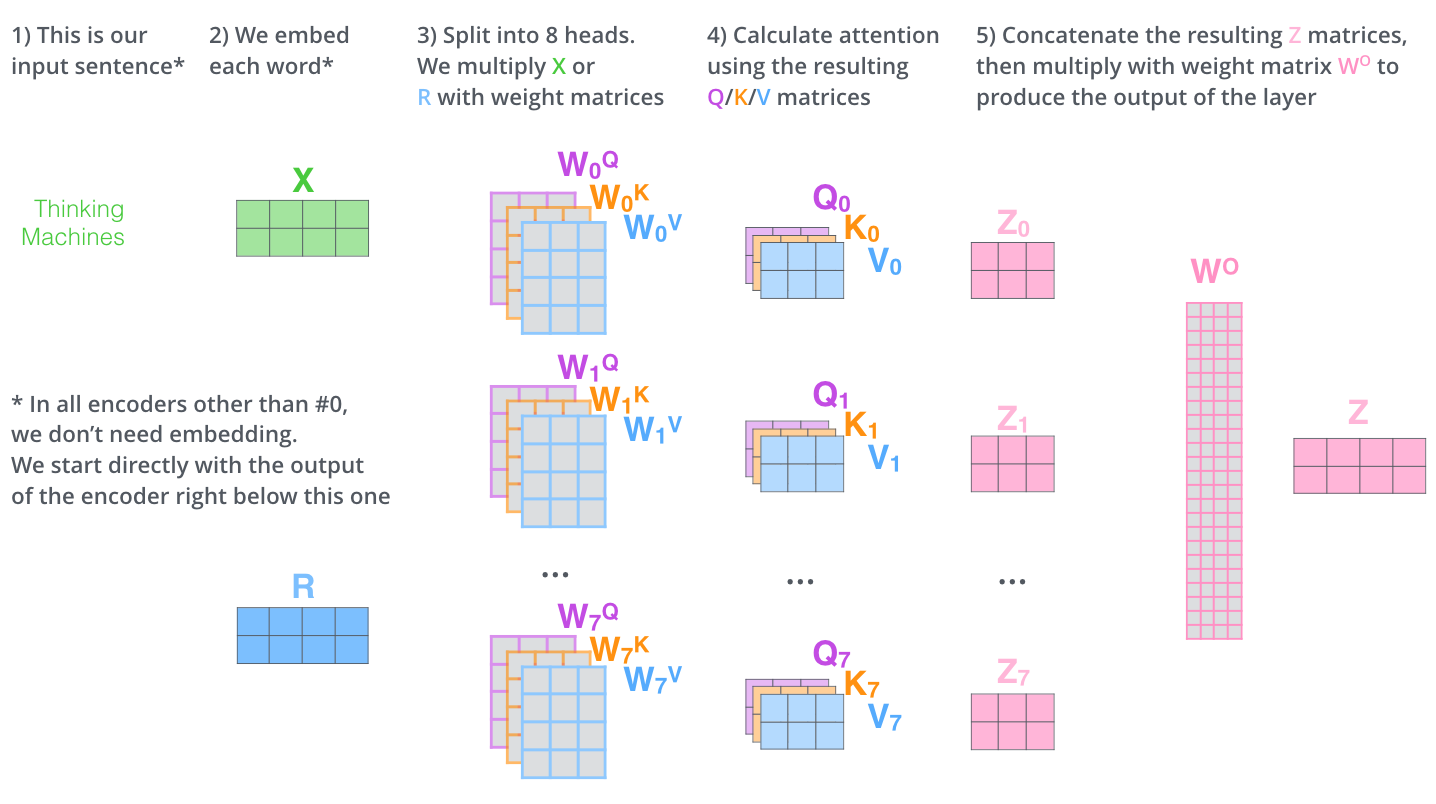
1) 입력 문장은 'Thinking', 'Machines' 이다.
2) 각 단어를 임베딩 하여, 행렬을 생성한다.
- 맨 처음 인코더에서만 단어 임베딩을 수행한다.
- 나머지는 이전 인코더의 출력을 받아 사용한다.
3) 8개의 Head로 나눈다.
- 각 Head는 별도의 Query/Key/Value 가중치 행렬을 가진다.
- 이를 이용해 Query/Key/Value 행렬을 생성한다.
4) Attention 연산을 수행한다.
- Query/Key/Value 행렬을 이용한다.
- Attention Score : Query 행렬과 Key 행렬의 내적 연산
- Key 행렬의 차원의 제곱근으로 나누기
- Softmax Score : Softmax 취하기
- Z 행렬 : Value 행렬과 Softmax Score를 곱하기
5) Z 행렬들을 하나로 합친다.
- Z 행렬들을 모두 concatenate 한다.
- 합쳐진 Z 행렬에 가중치 행렬 Wo를 곱한다.
- 최종 결과 Z 행렬을 출력한다.