High-Resolution Image Synthesis with Latent Diffusion Models
논문을 읽고 내용을 간략히 정리함
Diffusion Model
Diffusion Model은 점진적인 Denoising 작업을 통해 데이터 분포를 학습하는 확률 모델임
입력 이미지 X0에 점진적으로 가우시안 노이즈를 부여하여 완전한 랜덤 노이즈 XT를 만들고,
XT의 노이즈 제거 시 분포를 예측하도록 학습함
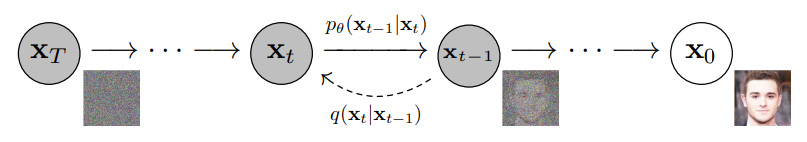
즉, 노이즈로부터 원본 이미지로 복원하는 과정을 학습하여 이를 바탕으로 이미지 생성을 수행함

Latent Diffusion Model
(1) Perceptual Image Compression
기존 Diffusion Model은 'pixel space' 이미지 자체에 노이즈를 추가/제거 하기 때문에, 고해상도 이미지의 경우 컴퓨팅 비용이 많이 소요되었음
이를 해결하기 위해 AutoEncoder를 이용하여 원본 이미지를 저차원의 'latent space'로 압축하도록 함
저차원 공간에서 학습과 샘플링을 수행할 수 있으므로 계산 효율성을 높일 수 있었음
(2) Conditioning Mechanism
Conditioning은 다른 모달리티를 통해 이미지 합성 과정을 제어할 수 있도록 함
다양한 모달리티를 전처리 할 수 있는 cross-attention 연산을 통해, 기존 U-Net 네트워크에 투입함
이를 통해 Text, Image, Semantic Map 등 입력이 이미지 합성에 영향을 줄 수 있도록 함
결국 LDM은 pixel-based DM 보다 더 적은 컴퓨팅 자원으로 훌륭한 성능을 유지할 수 있었음
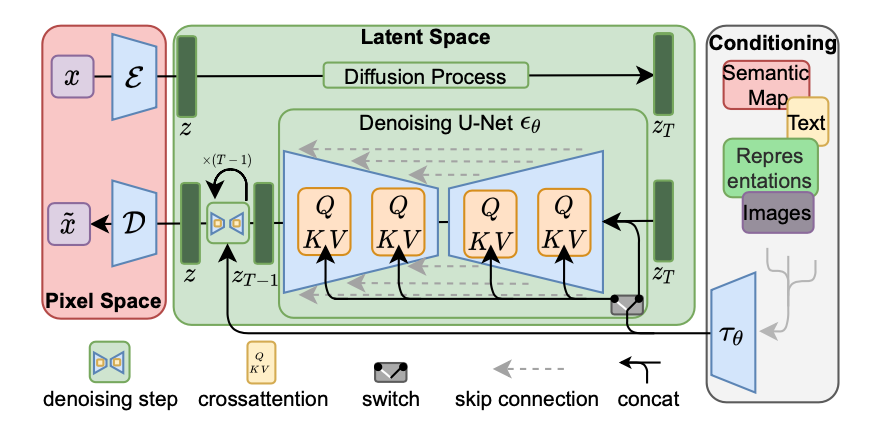
(1) Encoder : 입력 이미지는 Encoder를 거치며 작은 사이즈(64x64)의 latent vector로 압축됨
(2) Diffusion Process : 노이즈를 점진적으로 더해주는 과정을 통해, noisy latent vector가 생성됨
(3) Denoising : 노이즈를 점진적으로 제거함
(4) Conditioning : 다양한 모달리티의 입력을 처리하여 Denoising에 적용됨
(5) Decoder : 노이즈 제거된 latent vector는 Decoder를 거치며 원본 이미지 형태로 복원됨
Experiments
(1) Perceptual Compression Tradeoffs
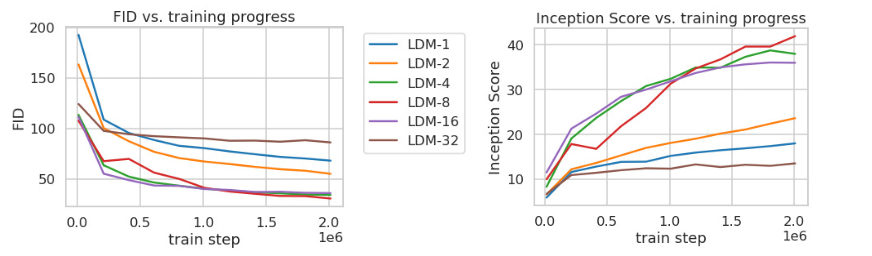
이미지 Downsampling 정도에 대한 비교 실험을 진행함
Downsampling factor = {1, 2, 4, 8, 16, 32}
LDM-{1, 2} : Downsampling을 적게 한 경우, 학습이 느린 속도로 진행됨
LDM-32 : Downsampling을 많이 한 경우, 샘플의 품질이 저하됨
즉, 이미지를 너무 조금 압축하면 학습이 오래 걸리고, 너무 많이 압축하면 학습이 잘 되지 않음
FID score 비교를 통해, Downsampling factor = {4, 8}을 최적의 값으로 도출함
(2) Unconditional Latent Diffusion
특정 조건이나 입력 없이, 주어진 데이터의 분포를 학습하여 새로운 이미지를 생성하는 실험을 진행함
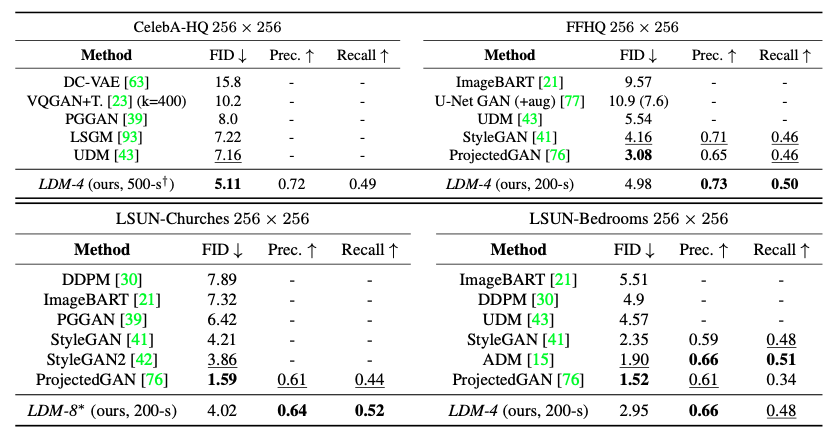
CelebA-HQ, FFHQ, LSUN-Churches, LSUN-Bedrooms 등의 데이터셋을 이용하고,
FID score, Precision-and-Recall을 통해 생성 이미지의 품질을 평가함
다른 Diffusion Model 보다 비교적 적은 parameter와 리소스를 사용함에도 좋은 성능을 보임
(3) Conditional Latent Diffusion
가장 대표적인 것은 Text to Image Generation 이지만, Semantic Synthesis, Inpainting 목적으로도 활용할 수 있음
하지만, Super Resolution 같이 정확하고 세밀한 생성이 요구되는 경우, 어느 정도 한계가 있어 적합하지 않을 수 있다고 함
-
Text to Image Generation

-
Semantic Synthesis

-
Inpainting

Conclusion
- 기존 Diffusion Model의 품질 저하 없이 효율적인 학습 및 샘플링을 수행할 수 있는 Latent Diffusion Model 제안
- Conditioning Mechanism을 통해 광범위한 조건부 이미지 합성 수행 가능
추가로 공부할 것들..
