이 글은 lighthouse 점수를 어떻게 올리는지를 다루는 글이 아닙니다.
과제
웹 최적화에 대한 지식이 없을 무렵 나는 회사를 다니며 첫 서비스를 출시하게 되었다.
그리고 그 때 찍어둔 스크린샷을 발견했다.

성함이 구글이신 교수님께서 만드신 lighthouse 는 일종의 과제인 것임을..
문득 내가 과제를 잘하고 있는지 궁금해져서 교수님의 채점기를 이용해보았다.

Performance 과제 제출해야되네..
웹 최적화
웹 최적화는 요구되는 지식이 굉장히 많다.
뭐 하나 검색하기 시작하면 끝도 없이 연결되는데 어느순간보면 브라우저 탭이 왜 이렇게 많이 떠있는건지?;
이번 포스팅을 통해 현재 서비스 중인 프로젝트를 중심으로(최적화를 곁들인) 경험한 것을 작성해보려고 한다.
코드의 수준
개인적으로 최적화와 관련해서는 이게 가장 중요하다고 생각한다.
내가 생각하는 '코드의 수준'이란, 코드가 얼마나 잘 작성되었는지를 의미한다.
'얼마나 잘 작성되었는지'는 다음과 같이 생각해볼 수 있을 것 같다.
- 불필요한 코드를 사용하고 있지 않은지?
- 불필요한 렌더링을 유발하고 있지 않은지? (react)
- 불필요한 렌더링을 유발하고 있지 않은지? (layout)
- 불필요한 네트워크를 수행하고 있지 않은지?
- ..그리고 위 생각은 또 다른 꼬리를 물고 늘어질 수 있다.
- 불필요한 코드를 사용하고 있지 않은지?
- 중복된 코드를 사용하고 있지 않은지?
- 반복문을 쓸데없이 돌고 있지 않은지?
- 이 코드는 자료구조를 활용하는게 효과적이지 않을지?
- ..
- 불필요한 렌더링을 유발하고 있지 않은지? (react)
- 불필요한 상태 관리를 하고 있지 않은지?
- 중복되는 상태를 사용하는 곳은 없는지?
- 굳이 필요없는 상태를 들고 있지 않은지?
- 의존성 배열은 정확히 사용하고 있는지?
- ..
- 불필요한 렌더링을 유발하고 있지 않은지? (layout)
- js 를 올바르게 사용하고 있는지?
- css 를 올바르게 사용하고 있는지?
- layout(reflow) 를 남용하고 있지는 않은지?
- ..
- ..
사실 이런 부분들을 모두 고려하면서 개발하는 것은 참 어려운 것 같다.
이 부분은 내 '실력'에 '경험'이 녹아들어야 가능하다고 생각한다.
그래서 남들이 말하는 '좋은 코드'를 찾아보는게 중요하다고 생각한다.
또 다른 방법으로는 코드 리뷰를 통해 새로운 시각에서 내 코드를 확인해줄 동료가 있다면 이 또한 좋은 영향을 줄 수 있을 것이라 생각한다.
나는 혼자 개발하는 슬픈 현실에서 벗어나기 위해 틈틈히 라이브러리를 까보거나 여러 글을 읽어보는 것으로 부족함을 채워나가고 있다.
어쨋든 웹 최적화에 있어 가장 중요한 본질은, 웹은 개발을 통해 만들어진 결과물인 것이고, 그 결과물은 결국 코드가 좌우한다고 생각한다.
끝없는 최적화
코드를 잘 작성하는 것도 중요하지만 이와 별개로 최적화와 관련된 키워드들은 수없이 많다.
FCP, LCP, TBT, CLS, ..
이 키워드들은 또 TTI, Cache, CDN, Code Splitting, Lazy loading .. 와 같은 키워드로 연결될 수 있다.
중요한 것은 이 키워드들은 대부분 서로에게 영향을 주는 관계라는 것이다.
어느 한 부분의 성능을 개선해야지! 하고 작업을 시작하면 어느새 목표했던 것과는 다른 파트를 건드리고 있는 모습이 떠오른다. 어쨋건 많이 시도해보고 경험해보자.
Next.js 는 멋지다!
Next의 이미지에 대한 얘기를 해보려고 한다.
React에서 이미지를 사용할 때에는 Intersection Observal API 를 통해 초기 로드를 막고, 이미지의 확장자 또한 직접 png, webp, .. 종류별로 구분하고 브라우저를 체크하여 사용해서 페이로드를 줄이고자 했었다.
Next 는 어떤가?
빌드 시에는 static 한 이미지들을 전부 최적화한 후 .cache/images 에 저장해두고 클라이언트에서 요청 시 빠르게 응답할 것이다.
실제로 server/image-optimizer.js 의 ImageOptimizerCache Class 내부 코드를 확인해보면 static 한 이미지는 ${PATH}/_next/static/media 로 url 을 지정하는 것을 확인할 수 있는데, 그 결과 next 로부터 캐시된 정적 이미지는 아래와 같이 서빙되는 것을 확인할 수 있다.
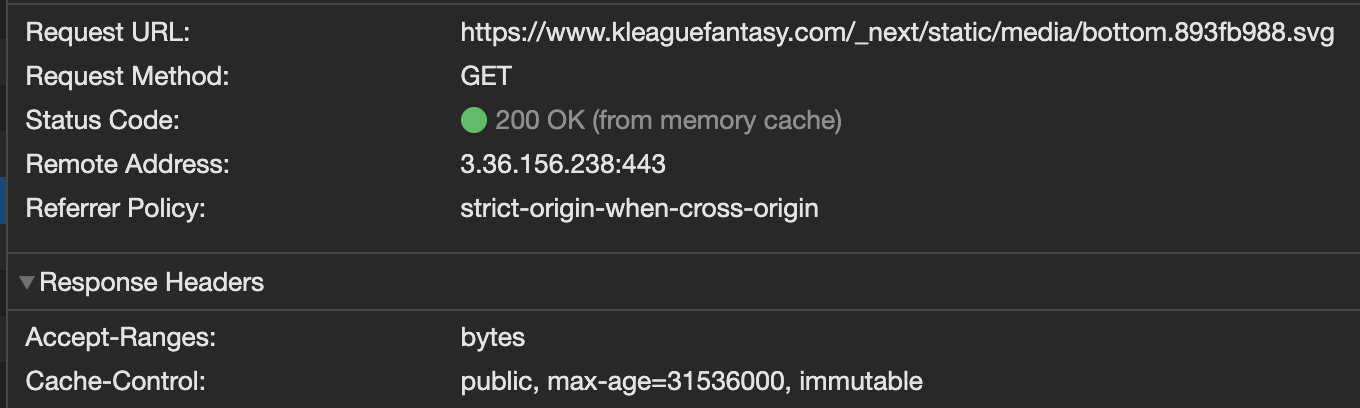
런타임의 리모트 이미지는 어떻게 동작할까?
client/image.js, server/image-optimizer.js 를 읽어보았다. (Next.js 12 기준)
-
client/image.js
가장 먼저, 우리가 사용하는 Image 컴포넌트는 client/image.d.ts 에서 import 한 Image 이며, 그 Image 는 client/image.js 의 Image function 에 해당한다.
Image 함수는 사용자로부터 src, quality, priority, loading, .. 와 같은 params 를 받은 후, 몇 가지의 config (shared/lib/image-config : next.config.js 에서도 설정할 수 있는 deviceSizes 같은 default 값들이 설정) 파일과 함께 style 을 지정하고 jsx 를 최종적으로 반환한다.
- 그 과정에는 next/image 의 대표 기능인 뷰포트 시점에 이미지를 보여주는 lazy-loading (client/use-intersection.js : Intersection Observal API를 사용) 과 같은 기능들이 포함되어 있다.
- Image 컴포넌트에는${host}/_next/image?url=${remote}&w=${width}&q=${quality}와 비슷한 형태의 srcString 이 포함되어 있다. (특정 loader 를 사용하면 srcString이 변경되는 것 같다.) 이 strString 이 반환값인 ImageElement jsx 의 img src 에 해당한다.
반환된 Image jsx 의 img 태그는 src 에 해당하는 리소스를 Next 서버에 요청하게 된다. -
server/image-optimizer.js
image-optimizer.js 에는 요청된 image의 params(url, quality, placeholder, ..) 를 검증하는 ImageOptimizerCache 부터 Etag 를 만드는 getHash, 요청된 이미지를 최적화하는 imageOptimizer, 최적화된 이미지를 반환하는 sendResponse 등 다양한 함수와 클래스가 구현되어있다.
정확한 호출 조건은 어디인지 모르겠지만 이 중에서 imageOptimizer, resizeImage async function 이 이미지를 최적화하는 부분에 해당하며, 특히 sharp(없을 시에 Squoosh) 에 의존하여 이미지를 최적화하고 있음을 확인할 수 있다.standalone mode 로 배포된 프로덕트에서
Error: 'sharp' is required to be installed in standalone mode for the image optimization to function correctly와 같은 에러 메세지가 이미지 하나당 한줄씩 로그에 찍히는 것을 확인할 수 있다. standalone mode 의 경우 sharp 에 의존하여 이미지를 최적화하기 때문에 빌드 버전에 sharp 를 설치해주거나 이미 설치했는데도 sharp 를 확인하지 못하는 경우process.env.NEXT_SHARP_PATH에 sharp 경로를 작성해주면 로그가 더이상 찍히지 않는 것을 확인할 수 있다.- server/image-optimizer.js 에서 이 부분을 핸들링하고 있는 것을 확인할 수 있다.
-
sendResponse 를 통해 반환된 이미지는 클라이언트로 전달되어 사용자에게 보여지게 된다.
Next.js 는 멋지다?
어떻게 배포하냐에 따라 다르겠지만 Next.js 서버는 기본적으로 싱글 스레드로 동작할 것이다.
싱글 스레드 기반의 환경은 이벤트 루프 방식을 채택해 I/O를 포함한 수많은 요청을 빠르게 처리하는 것에 강점을 가지고 있다.
Next 서버는 SSR 뿐만 아니라 특정 시각마다 ISR 을 통해 SSG 를 진행하는 등 많은 작업을 진행하는데,
여기에 CPU-intensive한 요청까지 많아진다면..
서버 인프라 자원이 원활하지 않은 경우 이는 성능 문제로 이어질 것이고, 결국 클라이언트에도 부정적인 영향을 미치게 되지 않을까?
React의 RSC, 아직 실험적 기능이지만 Next14의 partial prerendering 을 보면 웹 개발 트렌드는 서버측 렌더링으로 변화하고 있는데 과연 문제될만한 부분은 없을지 여러 글들을 찾아보고 정리해서 추후 포스팅해봐야겠다.
Cloud Run 탈출기
절대로 GCP 의 Cloud Run 을 비판하는 내용이 아닙니다..
초기 프로젝트는 container serverless 기반 관리형 플랫폼인 Cloud Run에서 서비스 했었다.
Cloud Run 의 특징 중 하나는 CPU 에 대한 인프라(2 vCPU, 4 vCPU, ..)를 직접 설정해 주는 것이 아닌 상황에 맞게 자동으로 scale 되는 형태라는 것이다.
마주했던 문제는,
1. 리모트 이미지의 로드가 기본적으로 느림
2. 무한 스크롤 기능(이미지 요청이 많은)에서 스크롤 시 리모트 이미지의 로드가 굉장히 느림
2번의 문제가 굉장히 심각했는데, 평균 60kb 정도의 크기를 갖고 있는 이미지 중 일부 이미지의 TTFB가 평균 20sec, 최대 100sec 까지 측정됐었다.
60kb 이미지의 TTFB, 즉 pending 의 평균 시간이 20sec.. 20ms 도 아닌 20sec 이었다.
그 때 기준 하루 평균 1000명 정도가 방문하는 수준의 서비스였는데.. 이게 말이 되는 수치인가?
Next.js 의 next/image 를 사용하고 있었기 때문에 서버에서 최적화를 해주고 서빙을 해주기까지의 시간이 오래 걸리는 것인가? 싶어 next/image 를 기본 img 태그로 변경하고 측정해보았다.
당연히 리소스 크기가 더 큰 최적화되지 않은 이미지가 전달되었음에도 불구하고 next/image 보다 빠른 결과를 확인할 수 있었다.
하지만 평균 TTFB 는 15sec 정도였고, 이는 절대로 서비스할 수 없는 수치에 해당한다.
당시 Google Startup Program의 지원을 받고 있었기에 관련 지원팀에게도 문의를 했었지만 아쉽게도 정확한 원인을 찾을 수 없었다.
내 지식으로는 Cloud Run 이 내부적으로 cpu를 어떤 식으로 scale 해서 할당해주는 것인지 모르겠지만 이미지 요청이 순간적으로 많아지는 순간 서버 인프라 자체가 원활하지 않아 서빙이 느리다는 판단할 수 밖에 없었고, 결국 Cloud Run 에서 탈출하기로 결정했다.
나중에 든 생각이지만 그 당시 하나의 load balancer 를 사용했었는데(단순히 배포를 위해) scale 된 N개의 Next 서버에 1:N으로 요청을 매치해줬을테니 load balancer 의 수를 늘려서 M:N 형태로 요청을 매치해주는 형태의 테스트를 진행해봤어야 했을까? 라는 생각이 든다.
하지만 애초에 오픈된 서비스도 아닌 개발 단계에서부터 그랬었기 때문에 큰 차이 없었을 것 같기도 하다..
GCP Compute Engine 으로 이사했더니..
Cloud Run 에서의 탈출을 결정한 후, 직접 서버 인프라를 설정할 수 있는 GCP 의 Compute engine 으로 이사를 진행했다.
그리고 매우 놀라운 결과를 얻을 수 있었다.
평균 50-70ms 정도의 기존 대비 몇십배나 향상된 TTFB 수치(사실상 정상적인 수치)를 확인할 수 있었다.
심지어 e2-medium(2vCPU, 4GB) 의 아주 저렴한 머신을 선택했음에도 이러한 차이를 보였다.
돈을 투자해보자 - 인프라 성능 높이기
마음 속 어딘가에 인프라의 성능을 높이면 그렇게 큰 차이는 없겠지만 TTFB 가 빨라지긴 하겠지? 돈 좀 부어서 확인해보고 싶다 라는 욕심이 존재했다.
어느 덧 시간이 흘러 프로덕트는 AWS 의 ECS 로 또 한번의 이사를 진행했다.
이사를 진행하고 다시 한번 이미지의 서빙을 확인해본 결과는 '별 차이 없음' 이었다.
최근에 AWS로부터 지원을 받게 되어 크레딧을 마음껏 사용할 수 있는 조건이 주어져서(압도적 감사)
마음 속에 간직해뒀던 인프라 성능에 대한 테스트를 진행해보았다.
Disable cache on
Analytics 기준 가장 많이 방문하는 페이지 측정
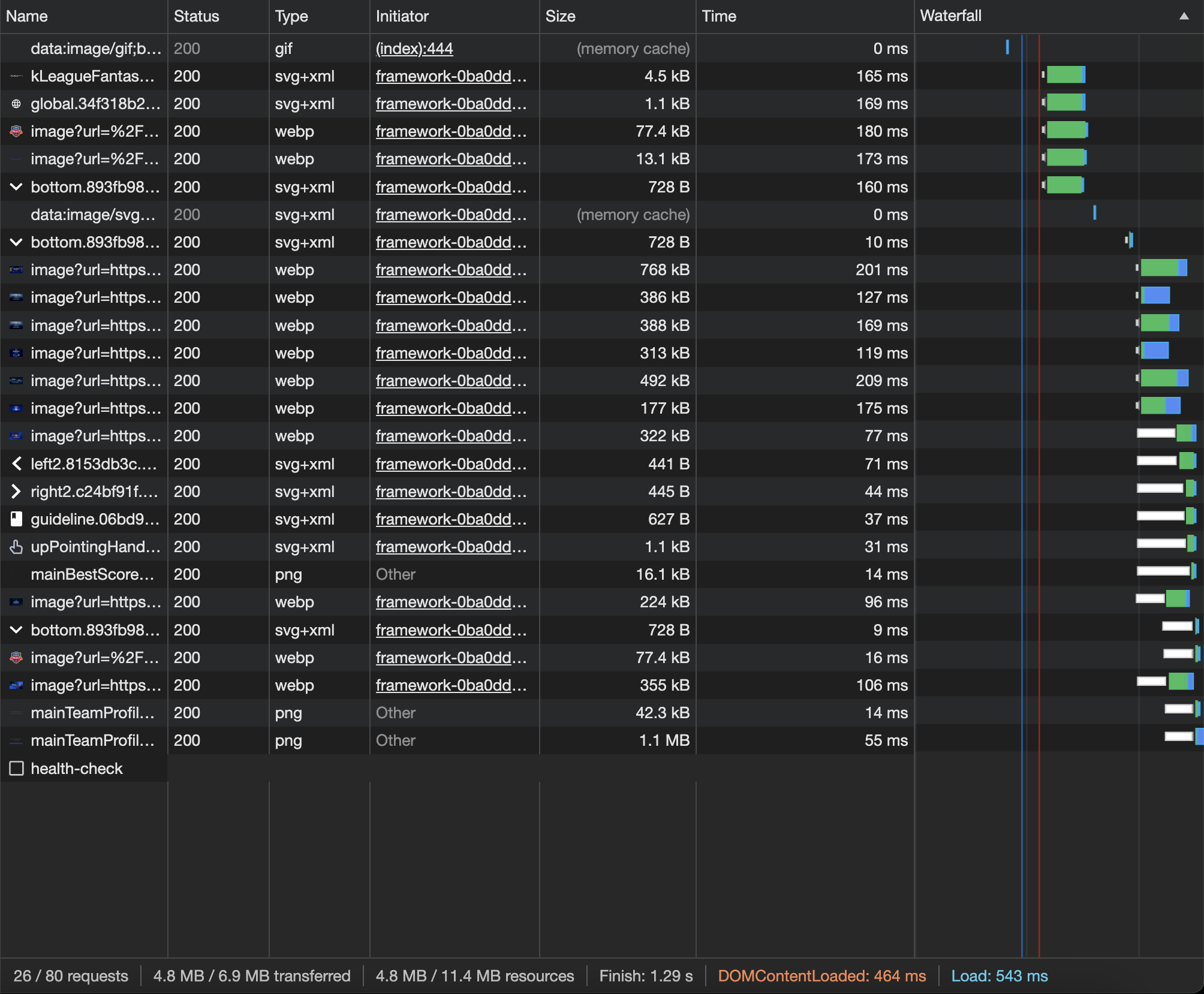
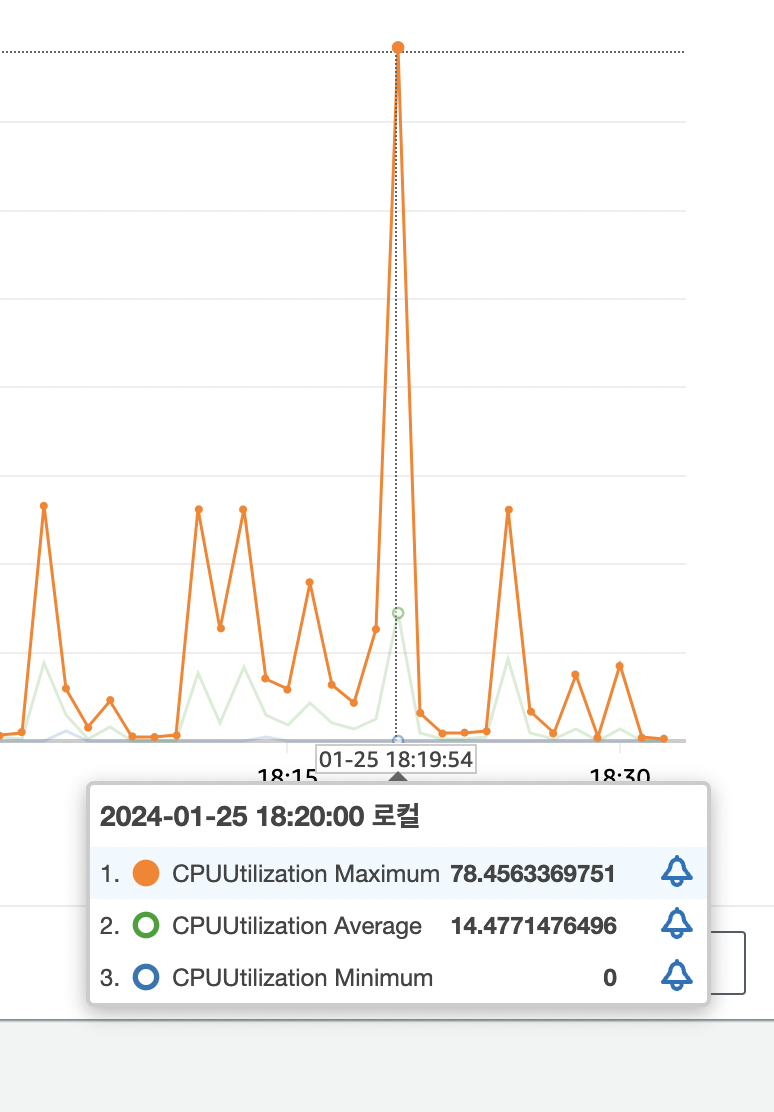
테스트 대상 : 2vCpu 4GB | 8vCpu 16GB
테스트1 : 부하 없는 테스트
테스트2 : 1000개의 스트레스 부하 발생
테스트는 5회씩 진행 후 평균값을 결과로 사용
-
2vCpu 4gb, 부하 테스트 X
-
8vCpu 16gb, 부하 테스트 X

부하 없이 진행한 테스트는 예상했던대로 큰 차이가 없었다.
- 2vCpu 4gb, 1000개 스트레스 부하 발생

- 8vCpu 16gb, 1000개의 스트레스 부하 발생

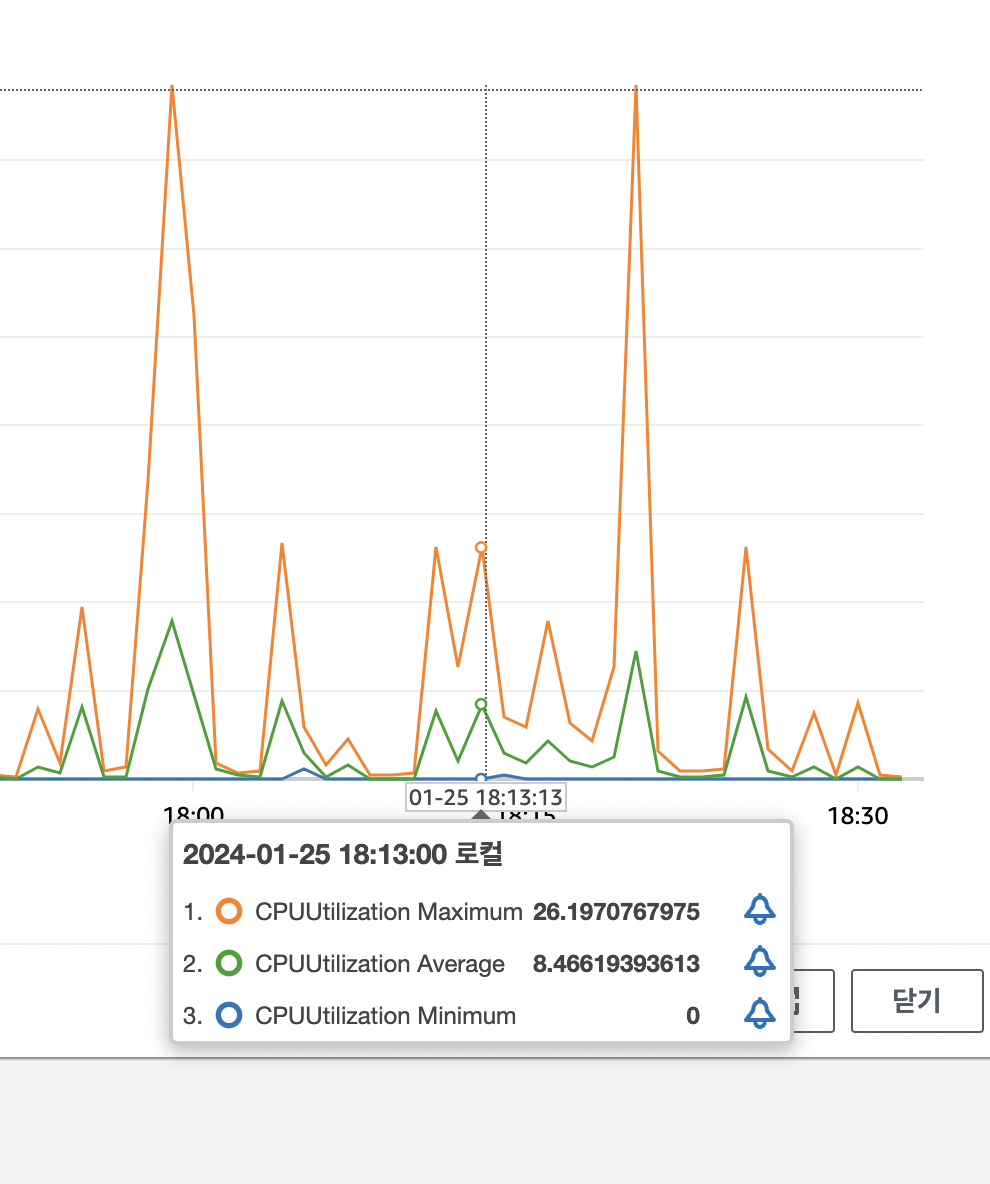
스트레스 테스트 시에는 각 리소스마다 평균 1초가 빨라졌는데 전체로 따지면 50% 빠르게 처리되었다.
cpu 는 최대 사용량 기준으로 각각 78%, 26% 로 측정되었다.
=> 서버의 성능 역시 웹 최적화에 영향을 미친다.
사실 동시 접속자 1000명을 고려한 테스트는 현재 프로덕트의 DAU 수준에 비해 조금 과한 부분이긴 한데..
확실한건 8vCpu, 16GB 도 1000명을 상대하기엔 역부족이었다.
잘나가는 서비스들은 대체 어느 정도 사양의 인프라를 사용하는건지..?
돈을 투자해보자 - CDN
매 테스트마다 CDN Cache 에 대한 invalidation(무효화) 작업을 수행
총 5회의 Miss, HIT 테스트 수행 후 평균값 선택
CDN 은 AWS 의 CloudFront 를 이용
-
invalidation 진행된 후의 최초 리소스 (Miss from cloudfront)

-
캐시된 리소스 (HIT from cloudfront)
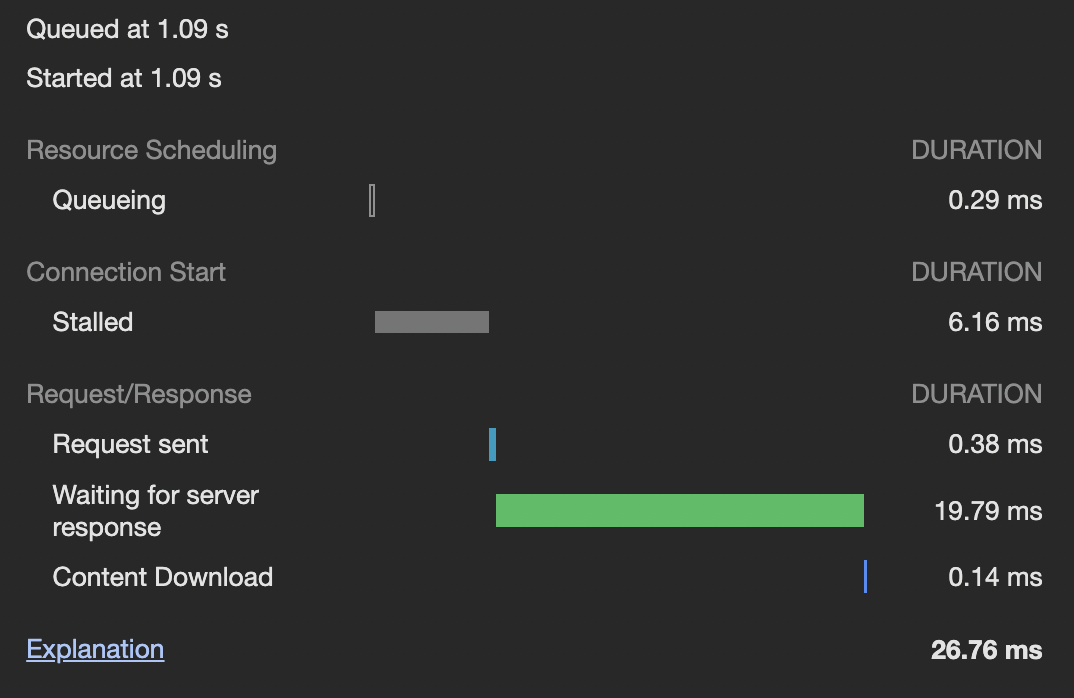
해당 리소스를 기준 약 70%,
모든 리소스를 기준 평균 40% 정도의 처리속도가 향상됨을 확인할 수 있었다.
CDN 은 적용 후 캐시 컨트롤 조절에 대한 추가 작업이 필요하지만, 서비스에 사용할 수 있는 자본이 충분하다면 높은 순위로 고려해야할 선택지라고 생각한다.
마무리
프론트엔드는 최적화를 경험할수록 그 끝이 어디인지 모르겠다.
그래도 2년동안 많이 성장하지 않았을까?
무언가를 적용하고 발전하는 모습을 눈으로 확인할 때만큼 재밌는 경험은 없는 것 같다.
다음 최적화 글을 작성할 때까지 열심히 수련하자.
