데이터베이스에서 두개 이상의 컬럼을 결합하여 행을 유일하게 식별할 수 있는 키를 만든 것을 복합키라고 한다. 복합키는 이력 테이블, 트랜잭션 테이블 등에서 많이 사용된다.
이러한 복합키는 키를 구성하는 컬럼의 순서에 따라서 조회, 삽입 성능이 차이날 수 있다. 어떠한 경우에 성능 차이가 나고, 성능 차이가 나는 이유를 데이터베이스 작동 원리와 함께 알아보자.
인덱스 순서에 따른 조회 성능 차이
복합키를 가진 테이블에서 행 조회 시 첫번째 컬럼이 중요한 역할을 한다. 복합키에 명시된 컬럼 순서대로 인덱스가 구성되기 때문에 복합키의 첫번째 컬럼은 선택도(Selectivity)가 높은 컬럼을 선택하는 것이 좋다. 예시를 통해 실제 데이터베이스가 어떻게 조회하는지 살펴보자.
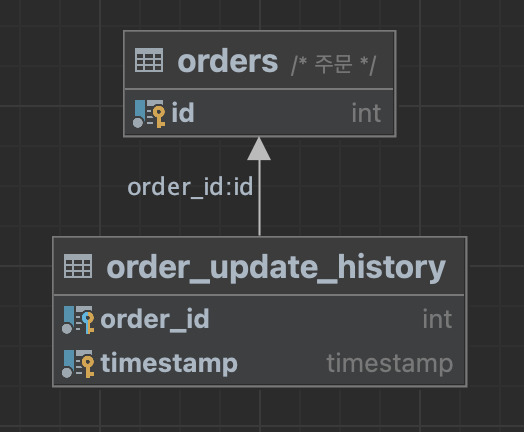
위 ERD는 간단한 주문 테이블과 주문 수정 이력 테이블이다. 주문 수정 이력 테이블은 주문 ID와 변경 일자인 timestamp 컬럼을 복합키로 가지고 있다.
order_id, timestamp 순서로 복합키 구성
create table order_update_history
(
order_id int not null,
timestamp timestamp not null,
primary key (order_id, timestamp),
constraint order_update_history_orders_null_fk
foreign key (order_id) references orders (id)
);
insert into orders (id) values (1);
insert into order_update_history (order_id, timestamp) values (1, '2023-05-27 10:45:12');order_id, timestamp 순서로 복합키를 구성 후 주문 수정 이력 테이블을 조회한 후, 실행계획 type을 확인해 조회가 어떻게 동작하였는지 확인한다.
복합키 인덱스는 위 DDL문에서 보는 것과 같이 order_id, timestamp 순서로 구성되어 있다. 따라서 인덱스는
- order_id 탐색
- timestamp 탐색
순서로 행을 조회한다.
explain select * from order_update_history where timestamp = '2023-05-27 10:45:12';위와 같이 timestamp만을 조회하는 경우의 옵티마이저 실행계획 type을 확인해보면

인덱스 스캔을 하지 못하고 인덱스를 전체 모두 읽는 index 타입의 조회를 한 것을 알 수 있다.
timestamp, order_id 순서로 복합키 구성
반대로 timestamp, order_id 순서로 복합키를 구성한 테이블에서 주문 수정 이력을 조회해보자.
create table if not exists order_update_history
(
order_id int not null,
timestamp timestamp not null,
primary key (timestamp, order_id),
constraint order_update_history_orders_null_fk
foreign key (order_id) references orders (id)
);위와 동일한 쿼리를 실행 후 옵티마이저 실행계획 type을 확인해보자.

인덱스 순서만 바꾸고 동일한 쿼리를 수행했는데 인덱스 스캔으로 효율적인 조회를 한 것을 확인할 수 있다. 주문 수정 이력 테이블을 분석해보면 order_id 하나에 여러 timestamp 값이 조합되어 수정 이력 테이블이 만들어지는 것을 알 수 있다. 따라서 timestamp 값이 더 선택도(selectivity)가 높다. 또한 이력 테이블 특성 상 특정 시기 range 기준으로 조회하는 경우가 대부분 이기에 timestamp 컬럼을 복합키 인덱스 첫번째 순서로 두어 조회 성능을 최적화할 수 있는 것이다.
인덱스 순서에 따른 삽입 성능 차이
복합키 인덱스 순서에 따라서 삽입 성능도 차이가 날 수 있다.
B-트리 노드 삽입 동작 원리
삽입 성능 차이를 이해하기 위해서는 B-트리 계열의 삽입 동작 원리에 대해 알아야한다. MySQL과 같은 관계형 데이터베이스의 인덱스는 B-트리 구조(정확히는 B+트리 등 변형, 최적화된 구조를 사용함)를 따른다. B-트리는 같은 레벨에 리프 노드가 위치하며 이 때문에 노드의 삽입, 삭제, 검색이 모두 일정한 시간복잡도를 가지는 자료구조이다.
B-트리에서 새로운 노드를 추가할 때에 다음과 같은 순서로 동작을 수행하여 데이터를 정렬해 저장한다.
- 데이터 삽입
- (삽입 공간 부족 시)새로운 페이지 생성 및 분할
- 키 재배치
- 부모 노드 업데이트
연속적인 값과 불연속적인 값
결론부터 말하자면 연속적인 값이 복합키 인덱스 첫번째 순서에 배치되어야 삽입 성능이 향상된다. 위 주문 수정 이력 테이블에서는 timestamp가 연속적인 값에 해당된다.
연속적인 값을 삽입할 때에는 데이터가 항상 리프노드 맨 오른쪽에 삽입된다(가장 크기 때문). 따라서 위 B-트리 데이터 삽입 단계에서 2, 3번 단계가 덜 자주 발생한다.
반대로 불연속적인 값(랜덤값)을 삽입하였을 때에는 리프 노드의 다양한 위치에 삽입이 되고, B-트리의 여러 곳에서 페이지 생성 및 분할이 자주 발생한다. 페이지 생성과 데이터 이동은 디스크 I/O를 유발하고, 이로 인해 삽입 성능이 떨어질 수 있다.
관련 자료
MySQL의 IN() v.s. EXISTS v.s. INNER JOIN 성능 비교
