
서론
지난 시간에 그래서 그거 해보셨어요? (feat. nGrinder) 과정을 통해 부하테스트를 진행해봤고, 브레이크 포인트 테스트를 진행하던 와중에 몇가지 문제점을 확인해볼 수 있었다.
정리해보면 크게 두가지 문제점을 알 수 있었다.
- 트래픽이 증가하면서 레이턴시가 대폭 증가했다.
- 테스트 도중
ConnectionClosedException이 발생하면서 에러가 발생했다.
이번에는 이 두가지 문제가 왜 발생했고 어떻게 해결할 수 있는지 알아보자.
흐름을 구석구석 파헤치면서 우리가 알게모르게 최적화가 되고있던 부분도 파악해보자.
요청에서 응답까지
주소창에 https://www.naver.com 을 치면 무슨일이 일어나나요? 라는 질문이 생각난다.
갑자기 뭔말인가? 싶을 수 있겠지만 이번 문제를 해결하는데 있어 필요한 질문이라고 생각한다.
이번 테스트에 사용했던 https://{API 호출 주소}/v2/shops를 호출했을 때 어떤 일이 일어나는지 알아보자.
서버에 닿기까지
우선 주소창에 https://koreatech.in 이라는 임의의 주소를 친다고 가정하자.
이에 컴퓨터는 DNS 서버에서 IP 주소를 획득하고 해당 IP 주소에 값 주세요~ 요청을 보낼 것이다.
/v2/shops는 IP 주소를 획득한 다음에 보자
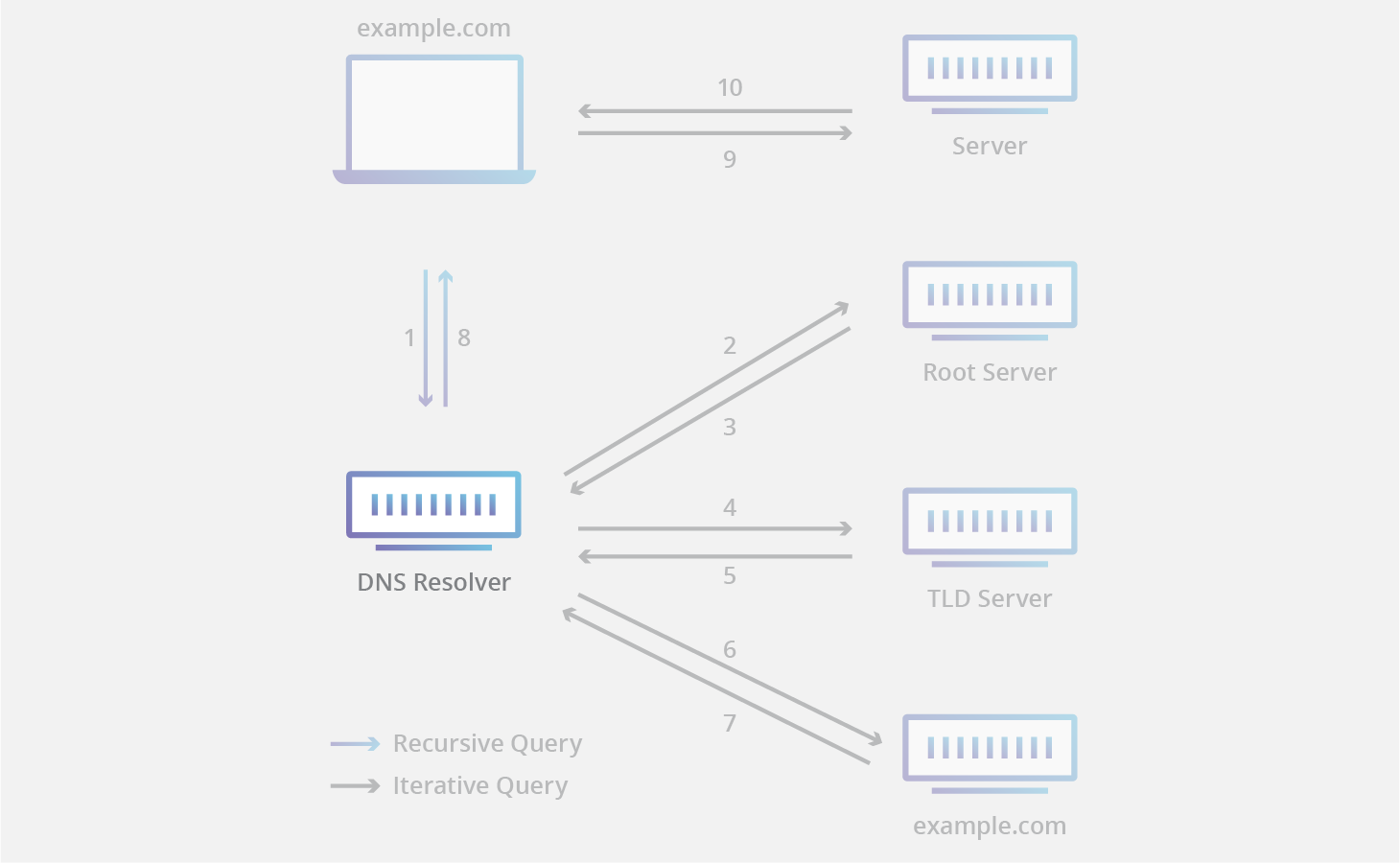
위 그림에 따르면 example.com이라고 검색했을 때 DNS Resolver(혹은 로컬 DNS라고도 칭한다)를 통해 Root Server, TLD(Top-Level DNS) Server, SLD(Second-Level DNS) Server를 거쳐서 탐색을한다.
DNS 동작 원리에 대해서 예전에 잠깐 정리를 시도했던 1% 네트워크의 초반부 정리 내용이 등장한다.
그렇다면 궁금증이 생긴다.
DNS 서버에게 일일히 IP 주소를 요청하면 성능상 낭비 아닌가?
사실 너무 간단하게 표현해서 그렇지 DNS는 캐싱된다.
아하! IP 주소를 캐싱하는구나!
캐싱을 끼고 흐름을 다시 보면 다음과 같은 흐름이 이어진다.
https://koreatech.in 을 입력한다
-> 로컬 DNS 캐시를 확인한다.
-> (없다면) DNS Resolver 서버에 요청한다.
-> Resolver 캐시를 확인한다.
-> (없다면) Resolver가 DNS 쿼리를 전파한다.
-> 루트 서버에 쿼리를 보낸다. (TLD 서버에 대한 정보를 제공한다)
-> TLD 서버에 쿼리를 보낸다. (권한이 있는 DNS 서버에 대한 정보를 제공한다)
-> 권한 있는 DNS 서버(SLD DNS)에 쿼리를 보낸다. (도메인 이름에 대한 IP 주소를 반환한다)
-> DNS Resolver 는 이 IP 값을 캐싱한다. (TTL이 있다)
-> 클라이언트에게 응답한다.
Cache Hit의 관점으로 보면 아래 그림처럼 표현할 수 있다.
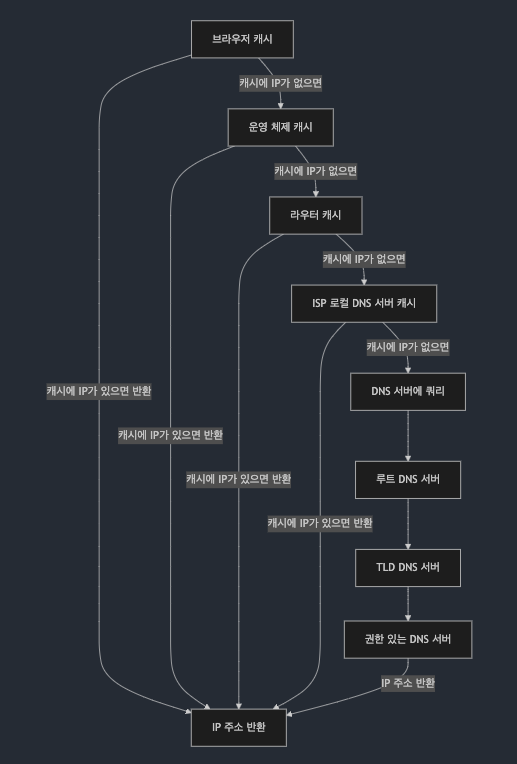
이 흐름을 통해 아하! DNS 서버에게 IP 주소를 얻어오는 것에 대해서도 최적화가 일어나고 있었구나! 를 알 수 있다.
눈으로 확인하고싶어요 👀
실제로 어떻게 캐싱이 되고있는지 눈으로 보고싶다..!!!
하지만 Mac OS에서는 로컬 DNS 캐시 정보를 확인할 수 없다...! 그저 DNS 캐시 정보를 Flush 하는 방법밖에 나오지 않는다. (GPT한테 물어보니까 Mac OS의 보안상의 이유라고 말하긴한다)
그래도 궁금하니 잠들어있는 Windows 노트북을 꺼내서 ipconfig /displaydns 명령어로 한번 확인해보자.
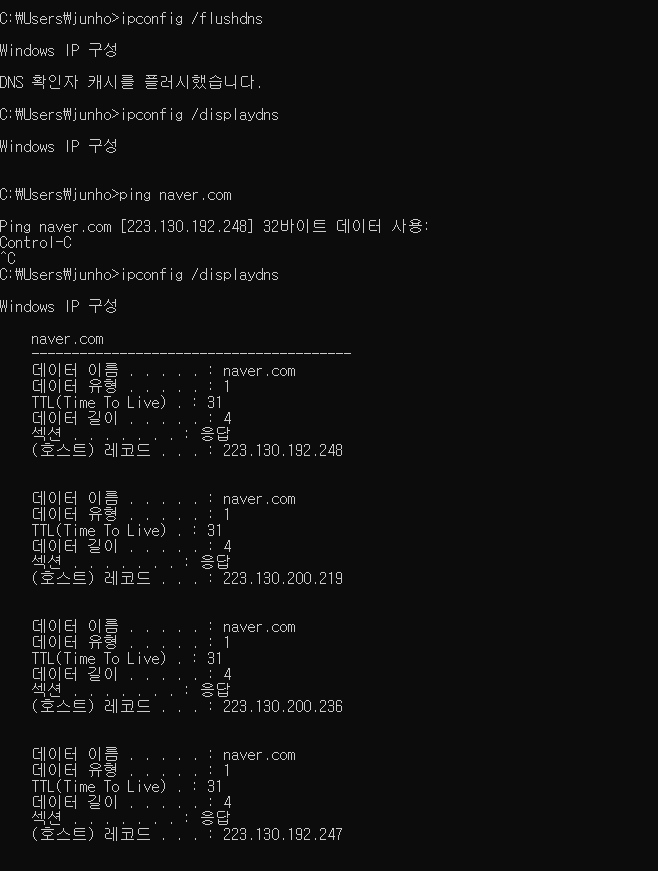
보기 편하게 ipconfig /flushdns 명령어를 수행해 캐시되어있는 dns를 비우고 확인을 해봤다.
브라우저로 접속한 뒤 ipconfig /displaydns를 실행해보니 내가 접속한 사이트가 dns 캐싱 목록에 없었다!
브라우저에서 캐싱하면서 로컬 설정의 캐시에는 남지 않는 것 같아서 직접 ping을 날리면서 캐싱하도록 유도해봤더니 잘 남는것을 확인할 수 있었따.
이를 통해 OS 측에서 DNS 캐싱이 잘 이뤄지고 있다는 것을 확인했다 (Windows에 대해서만)
브라우저 캐싱도 확인하고싶어 Chrome을 확인해봤는데 아래 주소로 접속해보니 캐싱된 사이트가 안뜬다
chrome://net-internals/#dns
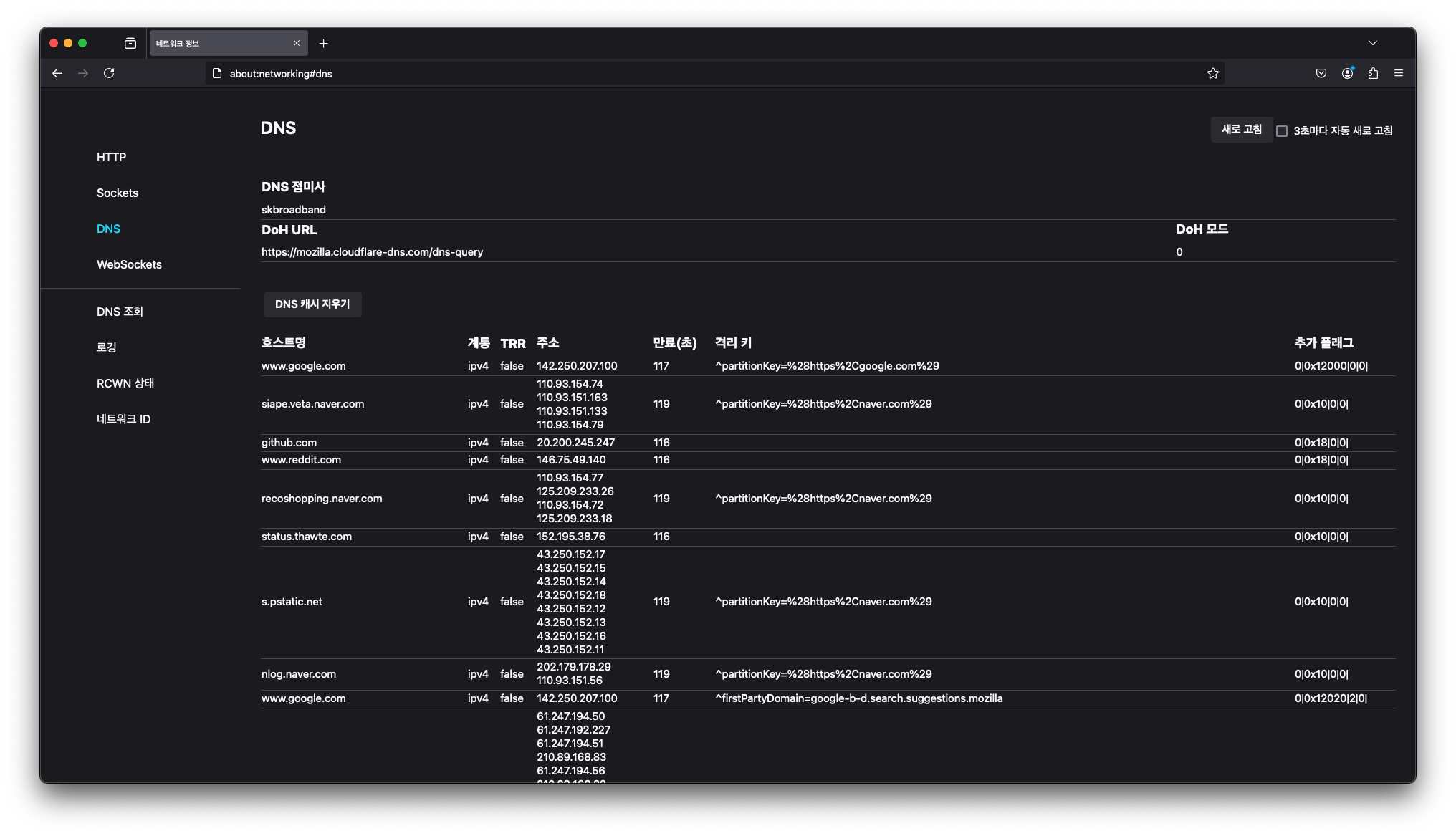
아쉬운대로 FireFox에서는 확인이 가능한것으로 확인하여 파이어폭스로 캐시되는것을 확인했다.
about:networking#dns 로 접속하면 확인할 수 있다.
이로써 브라우저도 캐싱을 잘 하고 있다는것을 확인했다.
사실 크롬도 DNS 캐싱 여부를 확인하는 방법은 있다.
chrome://net-export/을 통해 브라우저의 모든 로그를 파일로 찍어볼 수 있고 이 사이에서 DNS 캐싱이 수행되고 있는 지 로그를 확인해볼 수 있다.
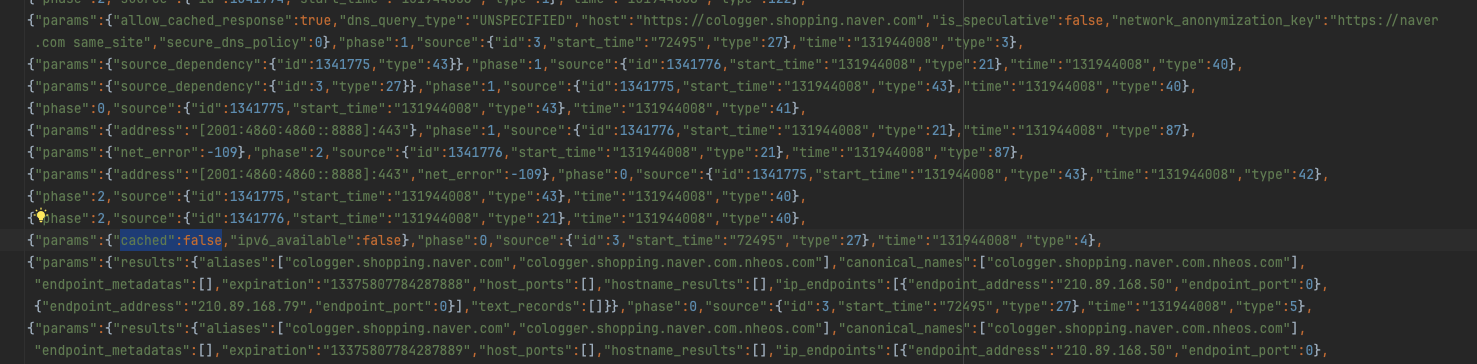
이렇게 로그가 뜨는데 "cached" 속성을 확인하면 된다. 브라우저에서 캐싱된 값을 활용했는지에 대한 유무를 나타낸다고 한다.
우리집 공유기가 DNS 캐싱을 하나? 도 궁금해져서 확인해봤으나 DNS Resolver의 역할은 하지 않는듯 보인다.
아쉽지만 DNS Resolver(혹은 라우터)의 캐싱 내역은 확인이 어려워보이므로 이론적으로 이해하고 패스~
TCP/IP
Http 통신은 하는 TCP 프로토콜을 기반으로 통신을 한다. TCP는 신뢰성 있는 통신을 보장하기 위해 3-way-handshake 과정을 통해 시작한다.
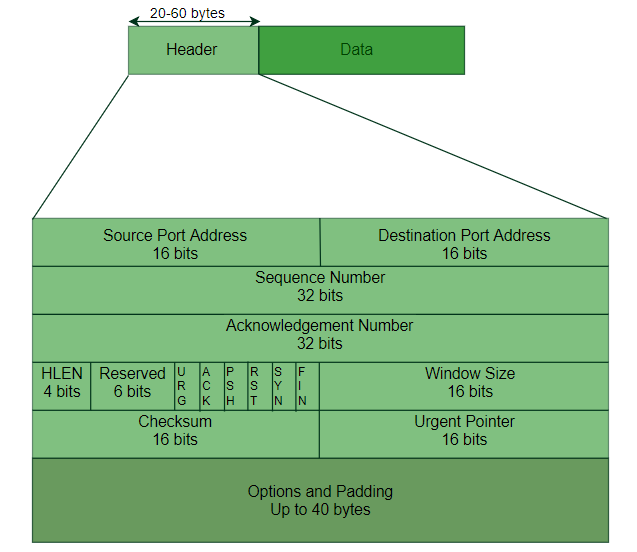
TCP 세그먼트의 구조를 살펴보면 Header, Data 부분으로 나눠 볼 수 있는데 Header의 정보를 한번 살펴보자.
- 출발지/목적지 포트 주소 (각 16비트)
- 시퀀스 번호 (32비트)
- 확인 응답 번호 (32비트)
- 헤더 길이 (4비트)
- 제어 플래그 (URG, ACK, PSH, RST, SYN, FIN)
- 윈도우 크기
- 체크섬
- 긴급 포인터
TCP는 통신과정에서 이 세그먼트를 가지고 총 3번의 handshake를 진행한다.
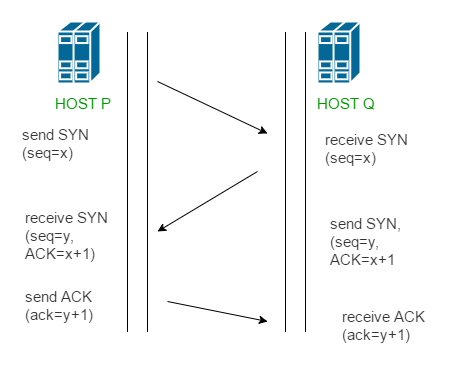
- 클라이언트가 서버에 연결을 요청한다. (SYN 플래그와 초기 시퀀스 번호 전송)
- 서버가 클라이언트 요청 수신 확인. (SYN-ACK 플래그와 자신의 시퀀스 번호 전송)
- 클라이언트가 서버의 응답 확인. (실제 데이터 전송 시작 가능)
(클라) 연결요청 - (서버) 수신확인 - (클라) 응답확인 의 과정이 반복되는것도 비용 아닌가? 의심이 든다.
Https 프로토콜을 사용한다면 TLS Handshake까지 고려해줘야한다.
TLS 암호화를 사용하는 통신 세션을 실행하는 프로세스로 Https 프로토콜 동작방식의 근간이 된다.
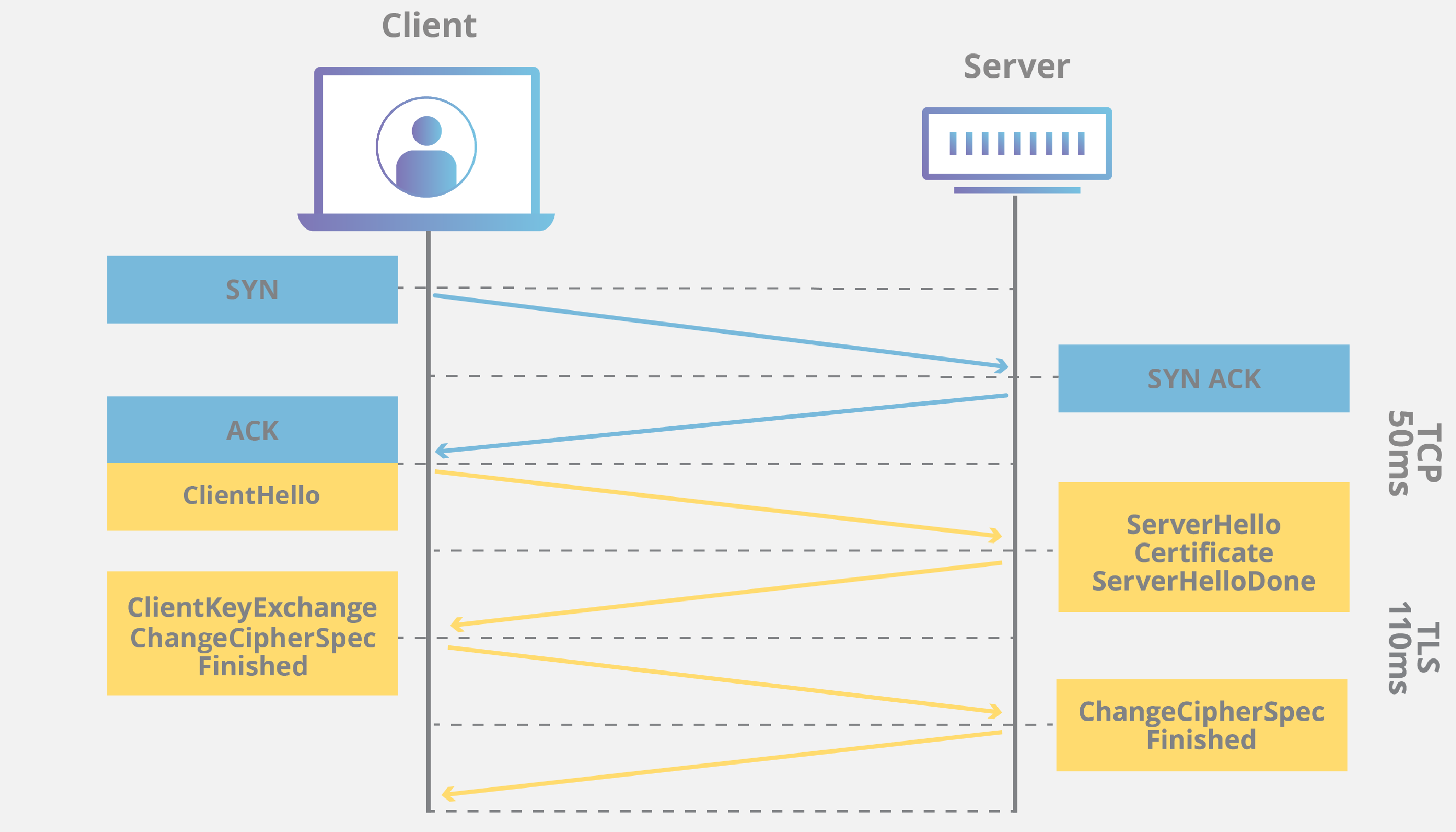
TLS Handshake는 다음과 같은 과정을 거친다.
-
클라이언트가 서버에 보안 연결을 요청한다.
- Client Hello 메시지 전송
- 지원하는 TLS 버전, 암호화 스위트, 랜덤값 전송
- SNI(Server Name Indication) 포함
-
서버가 보안 매개변수를 선택하고 인증을 제공한다.
- Server Hello 메시지로 암호화 방식 선택
- 서버의 인증서 전송
- 서버의 공개키와 랜덤값 전송
-
클라이언트가 키 교환을 수행한다.
- 서버의 인증서 검증
- Pre-master secret 생성
- 서버의 공개키로 암호화하여 전송
- 양측에서 master secret 생성
-
보안 통신을 시작한다.
- Change Cipher Spec 메시지로 암호화 시작 알림
- Finished 메시지로 핸드셰이크 완료 확인
- 이후 모든 통신은 협상된 암호화 방식으로 진행
눈으로 확인하고싶어요 👀
이 값은 네트워크 환경에 따라 시간이 다르게 걸릴 수 있으니 현재 글에서 측정한 값은 모든 환경에서의 표준 값이 아닙니다!
단순히 요청이 왔다갔다 하는 RTT만 확인하면 데이터를 송/수신하는 과정까지 포함하게되니까 정확히 확인해보기 위해 패킷 분석 도구를 활용해보자.
RTT(Round Trip Time): 네트워크 요청을 시작한 후 응답을 받는 데 걸리는 시간을 의미한다.
와이어샤크를 이용해 패킷을 한번 살펴보자.
(설치 및 사용법은 생략한다)

요청을 보내고 데이터를 받을 때 까지의 패킷들을 가져와봤다.
실제 패킷을 보니 3-Way Handshake 외의 과정들도 확인해 볼 수 있다.
3Way handshake는 0.271688s 만큼의 시간이 걸렸다. (패킷 No.67 -> No.70)
그 뒤에는 TLS Handshake가 시작된다. (패킷 No.71)
서버로부터 Client Hello를 받고 (패킷 No. 72) 키 교환을 수행한다. (패킷 No. 81, N0.84)

Mermaid로 도식화하면 대략 이런 느낌으로 볼 수 있을것 같다.
3-way handshake의 시간이 0.27초 가량 소요되었고, TLS handshake는 0.15초가량 소요되었다.
첫 SYN 부터 데이터 송신까지 시간을 재보니 0.428742초가 걸렸다.
0.4초가량의 handshake 과정이 조금 오래걸린다고 생각된다.. 이거는 어떻게 성능을 높일까?
Http의 버전에 따른 성능 차이
Http 1.0에서는 기본적으로 Keep-Alive를 지원하지 않아 Connection: Keep-Alive 헤더를 명시적으로 표현하여 비표준 확장형으로 구현할 수 있었다.
Http 1.1부터는 Keep-Alive가 표준이 되었고 별도로 Keep-Alive 헤더를 명시하지 않아도 기본적으로 연결을 유지한다.
Http 2.0부터는 멀티플렉싱을 도입해서 하나의 TCP 연결로 여러 파일을 병렬로 전송이 가능하다.
Http 2.0에 대한 자세한 개선점은 이야기할 내용이 많아 다른 글로 나눠써보려고한다.
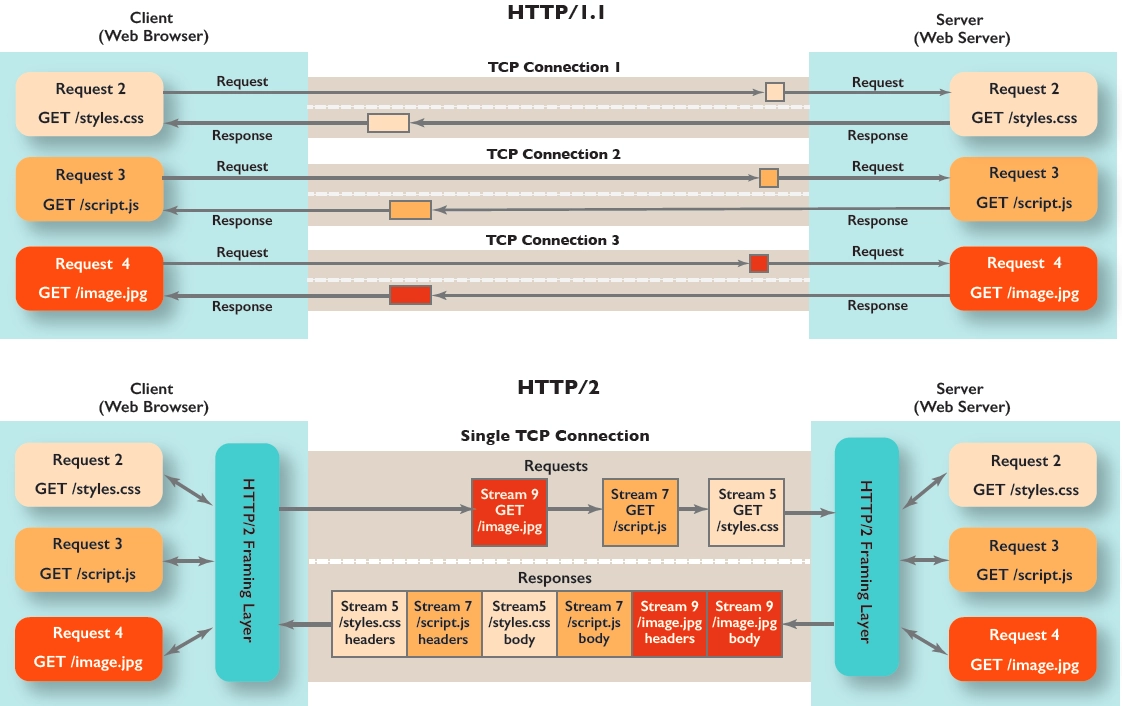
그림으로 확인해보면 이렇다. TCP Connection 하나에 여러 요청에 대한 Stream을 열고 멀티플렉싱이 가능하다.
현재 Koin은 http/1.1 을 사용하고있는걸 보아하니 이점을 개선해도 좋아보인다.
h2가 http/2 를 사용하고 있는걸 의미한다.
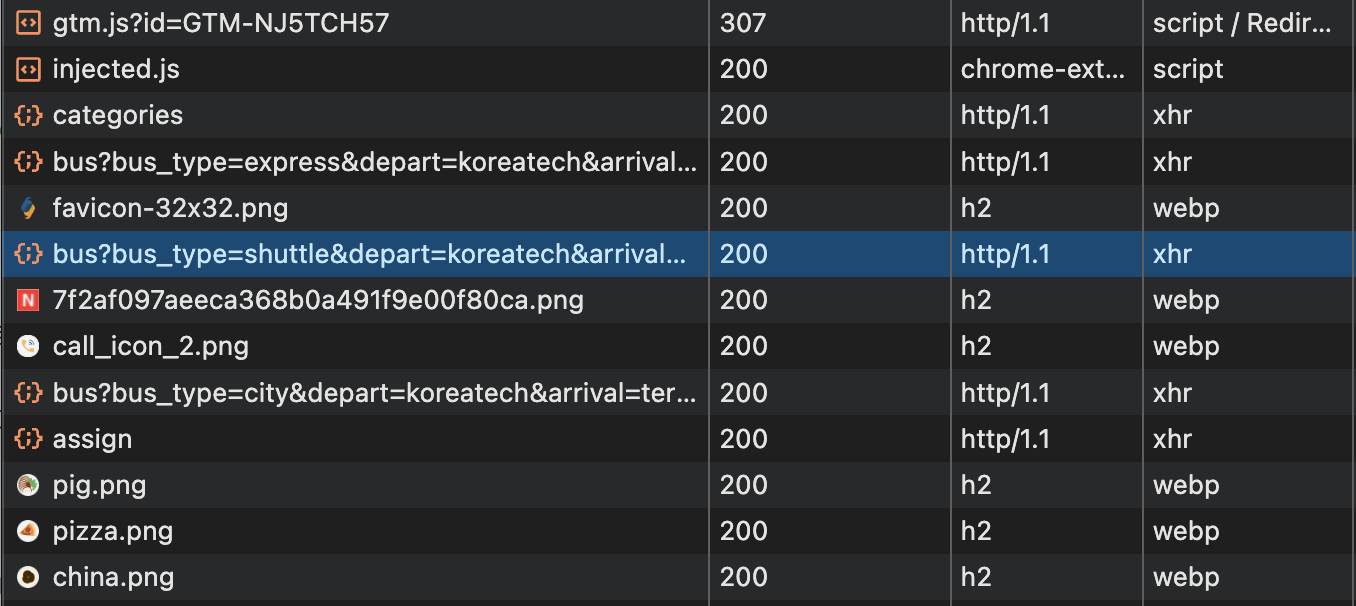
사용중인 도구, 브라우저가 Http/2 버전을 지원하는지 확인해보고 도입하면 좋을 것 같다.
추가로 Http/3도 있다. TCP/IP와 TLS가 구분되어 통신이 이뤄지는 것을 UDP 위에서 한번으로 줄여버린 QUIC 프로토콜을 사용한다고 한다.
확실히 최고의 속도를 낼 수 있을 것 같은데 이 내용은 학습이 더 필요할 것 같아 잘 정리된 글들을 첨부하고 넘어가본다.
QUIC 프로토콜 | 구글 또 너야?, HTTP/3란? | cloudflare
서버에 접속한 뒤에는
현재 운영중인 서비스 인프라 구조도를 기반으로 흐름을 분석한다.
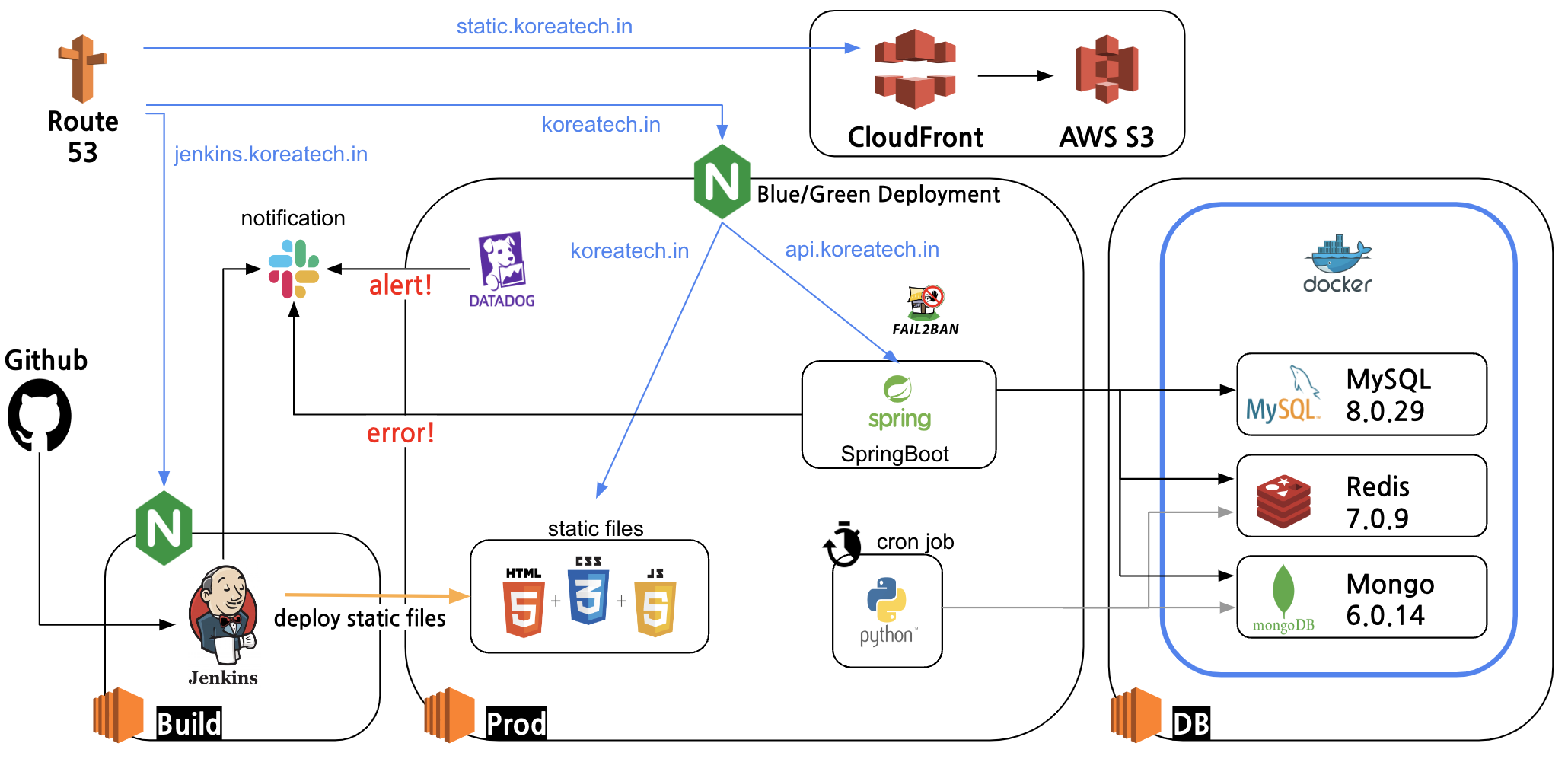
이제 서버의 IP 주소를 알아내서 서버에 접근한다.
우선 EC2에 접근하기 전에 AWS에서 보안 규칙에 따라 접근 가능한 규칙(포트 혹은 기타 규칙)에 해당하는지 확인한다. 만약 인바운드 규칙이 허용되지 않은 포트라면 접근이 막힐 것이다.
여기에서는 접근하고자하는 (https이므로) 443 포트가 허용된것으로 가정하고 이어서 진행해보겠다.
서버에 접근할 때 이 요청은 웹 서버인 Nginx에 닿는다.
Nginx에서는 들어온 요청에 대해 다양한 일을 수행할 수 있다. 정적 자원을 반환해줄 수도 있고, 들어온 요청을 WAS에 넘겨줄 수도 있다. 만약 IP Ban 리스트에 올라있는 IP라면 요청을 바로 반려시킬 수도 있다.
이번 요청은 정상적인 요청이고, API를 요청하므로 서버 내부에 있는 SpringBoot에 요청을 넘겨준다.
(ex. http://localhost:8080)
SpringBoot에 접근한 뒤에는
의식의 흐름 주의! ⚠️
이제 Spring의 세상에 들어온다.
내가 알고싶은건 Http 요청이 어떻게 들어오고, 어떻게 처리되는지가 궁금하다.
Tomcat 위키백과를 한번 살펴볼 필요가 있다.
https://en.wikipedia.org/wiki/Apache_Tomcat
한국어판에서는 설명되어있지 않은 Components라는 항목을 볼 수 있다.
대략적으로 요약하자면 Tomcat에는 다음과 같은 컴포넌트들이 구성되어있다고 한다.
- Catalina: Tomcat의 서블릿 컨테이너다. 서블릿 및 JSP 사양을 구현한다.
- Coyote: Tomcat의 커넥터 컴포넌트로 HTTP 1.1 혹은 2 프로토콜을 웹서버로서 지원한다.
- Jasper: Tomcat의 JSP 엔진이다.
- Cluster: 대규모 애플리케이션 관리를 위해 추가되었다.
- High availability: 시스템 업그레이드를 라이브 환경에 영향을 주지 않고 스케줄링 할 수 있는 기능을 돕는다.
그렇다면 우선 Coyote라는 친구를 살펴볼까 싶다.
Tomcat 살펴보기
SpringBoot 3.1.5 버전을 사용하고 있기 때문에 Tomcat 버전이 10.1.15 버전이다.
Tomcat 라이브러리를 보면 coyote 모듈이 있는것을 볼 수 있다.
뭔가 들어있는게 많아서 뭐부터 봐야할지 모르겠다! 이럴때는 아키텍처를 보는게 조금 도움이 될 것 같다.
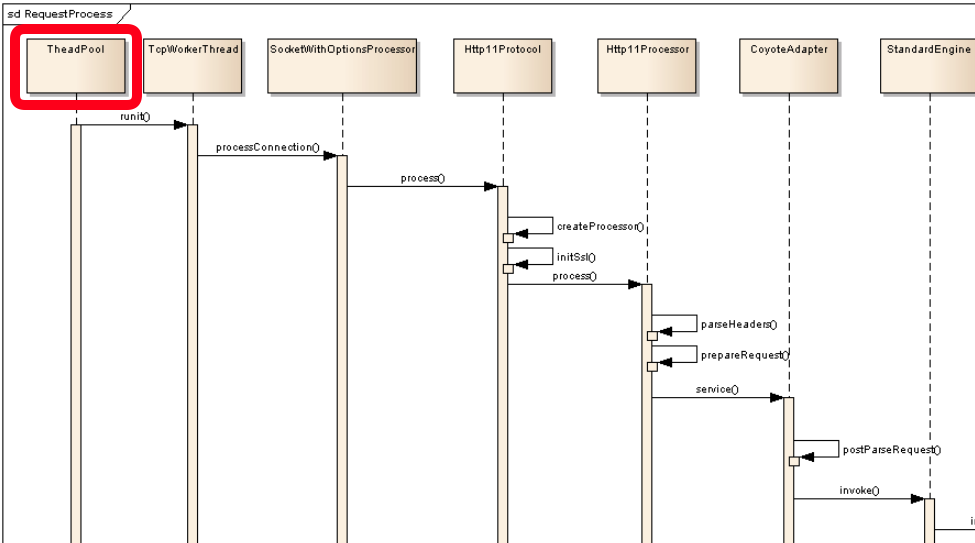
조금 투박하게 생겼지만 나름 Tomcat 공식문서에서 제공하는 아키텍처다.
여기서 눈여겨볼 만한 점은 ThreadPool에서 처리가 시작된다는 점이다.
Http 요청을 처리한다고 해서 coyote 모듈을 까봐야겠다라고 생각했는데 실상은 Tomcat의 Thread Pool에서 Thread가 작업을 할당받은 시점부터 요청이 처리되기 시작한다는 것을 알 수 있다.
그렇다면 트래픽이 증가하면서 레이턴시가 대폭 증가했다.라는 문제에 가장 가까운것은 저 Thread Pool일 것이라고 생각해볼 수 있겠다.
Tomcat Thread Pool 살펴보기
구글에 tomcat thread pool이라고 검색하고 스크롤을 내리다보니 공식문서가 나왔다.
위 문서는 8.5에 대한 문서라서 혹시 몰라 10.1 버전에 맞는 Executor 문서를 확인했다.
https://tomcat.apache.org/tomcat-10.1-doc/config/executor.html
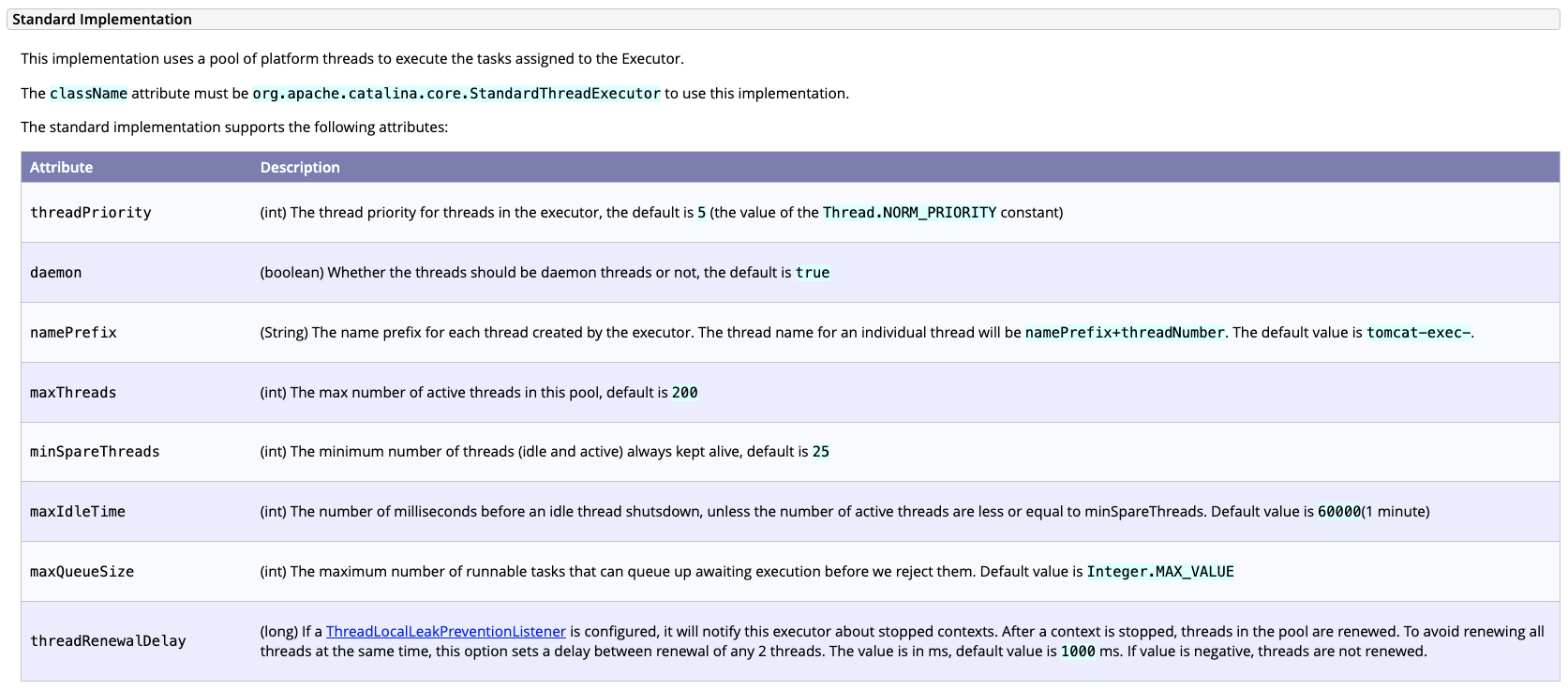
들어가보면 위와 같은 내용이 있는데 왜 트래픽이 증가하면서 레이턴시가 대폭 증가했을까?에 대한 실마리가 보인다. 중요한 값들만 보자면 다음과 같다.
- maxThreads: Thread Pool에서 활성되는 최대 Thread 개수로 기본값은 200이다.
- maxQueueSize: 실행 대기열의 크기를 의미한다. 기본값은
Integer.MAX_VALUE이다.
Thread Pool에서 동시에 200개 만큼의 스레드가 작업을 할당받고 처리할 수 있다고한다.
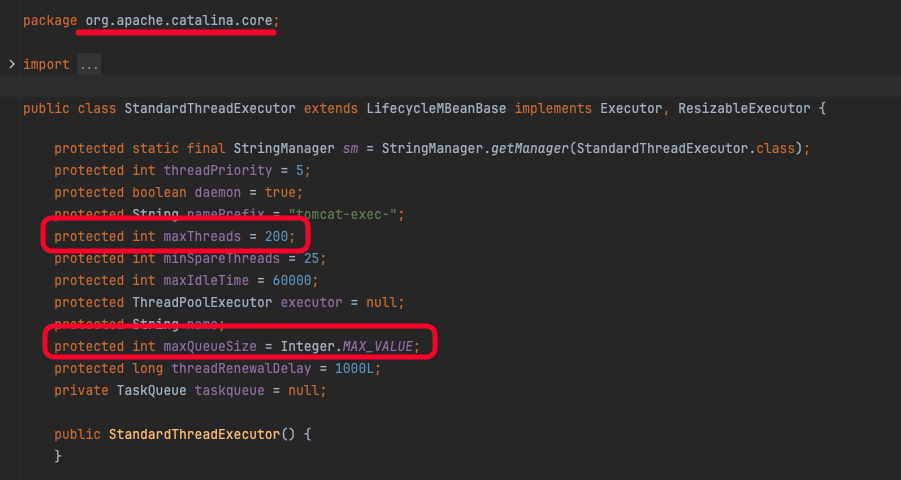
실제로 StandardThreadExecutor 클래스를 확인해보면 Default 값으로 위와 같이 설정되어있는 것을 확인해볼 수도 있다.
조금 더 쉽게 표현한 baeldung의 그림을 가져와봤다.
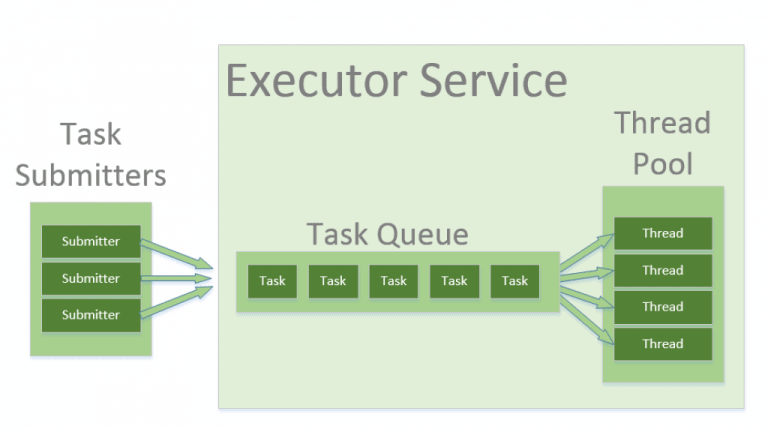
Tomcat Thread Pool을 기준으로
이제 요청이 와서 Thread Pool의 개수에 영향을 미칠 수 있다는 것을 알았다.
하지만 아직 의문점은 해소되지 않았다. 왜 200개의 스레드가 한꺼번에 처리를 못하지?, 왜 레이턴시가 증가하지? 라는 연쇄적은 물음표가 생긴다. 이 API가 200개의 스레드로는 한참 부족한 처리량인건가?
비즈니스 로직을 한번 살펴보자
public ShopsResponseV2 getShopsV2(ShopsSortCriteria sortBy, List<ShopsFilterCriteria> shopsFilterCriterias) {
if (shopsFilterCriterias.contains(null)) {
throw KoinIllegalArgumentException.withDetail("유효하지 않은 필터입니다.");
}
List<Shop> shops = shopRepository.findAll();
LocalDateTime now = LocalDateTime.now(clock);
Map<Integer, ShopInfoV2> shopInfoMap = shopCustomRepository.findAllShopInfo(now);
return ShopsResponseV2.from(shops, shopInfoMap, sortBy, shopsFilterCriterias, now);
}눈여겨볼 점은 shopCustomRepository.findAllShopInfo(now) 이 로직이다.
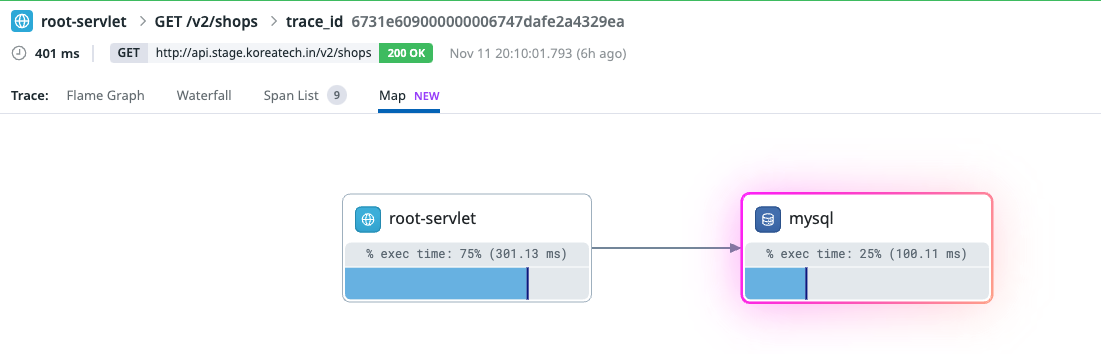
이 구문으로 하여금 DB에 Select 쿼리를 날려서 조회한다는 것을 알 수 있고 실제로 로그도 그렇게 남고있다.
Thread는 200개나 할당받고있는데 DB가 그 처리량을 못버티는게 아닐까? 생각해볼 수 있겠다.
DB와 Connection을 맺는 과정은 TCP/IP로 이뤄져서 연결에 시간이 오래걸린다. Tomcat은 DBCP를 통해 이를 해소했다. 따라서 TCP/IP로 인한 DB Connection 성능 이슈는 넘어간다.
그런데 왜 DB의 성능부족으로 처리되지 않는 요청들이 단체로 에러가 안나고 TPS가 늘어나기만할까?
Tomcat의 Http
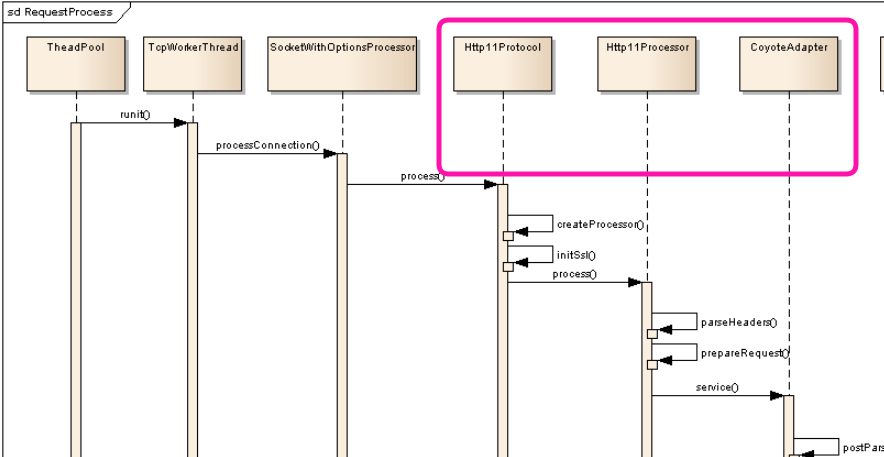
Thread Pool에서 worker Thread가 할당되고, DBCP를 할당받기 사이에 Http 처리가 있는 것을 다시 상기시킬 필요가 있다.
마찬가지로 http에 대한 공식문서도 손쉽게 찾을 수 있었다.

여기서 중요한 문장이 하나 있다.
If still more simultaneous requests are received, Tomcat will accept new connections until the current number of connections reaches maxConnections.
Connections are queued inside the server socket created by the Connector until a thread becomes available to process the connection.
Once maxConnections has been reached the operating system will queue further connections. The size of the operating system provided connection queue may be controlled by the acceptCount attribute.
If the operating system queue fills, further connection requests may be refused or may time out.여전히 더 많은 동시 요청이 수신되면 Tomcat은 현재 연결 수가 최대 연결 수에 도달할 때까지 새 연결을 수락합니다. 연결은 연결을 처리할 스레드를 사용할 수 있을 때까지 커넥터가 생성한 서버 소켓 내부에서 대기열에 대기합니다. 최대 연결 수에 도달하면 운영 체제는 추가 연결을 대기열에 추가합니다. 운영 체제에서 제공하는 연결 대기열의 크기는 acceptCount 속성으로 제어할 수 있습니다. 운영 체제 큐가 가득 차면 추가 연결 요청이 거부되거나 시간이 초과될 수 있습니다.
요청이 Tomcat에 처음 도달 할 때 maxConnections 만큼 소켓 내부의 대기열에서 대기하고, 만약 최대로 찰 경우 OS의 Queue에 담긴다는 내용이다.


실제 설정값들을 보니 Tomcat에서 만든 소켓 내부에 들어가는 요청 대기열 크기의 기본 값이 8192만큼의 크기를 가지고, 이 값이 다 찼을 때 acceptCount가 차기 시작하는데 이 값의 크기는 기본 값이 100이다.

connectionTimeout의 기본값은 60초 (1분)으로 꽤나 오래 기다려주는 편이라는것을 알 수 있다.
tomcat과 함께 제공되는 server.xml의 기본값은 20초라고 하는데 SpringBoot 내장 톰캣을 사용하니 여기서는 고려할 사항이 아니다.
속성들을 정리해보면 다음과 같다.
- connectionTimeout: 연결 후 요청 URI 라인이 제공되기를 기다리는 최대 시간(밀리초)이다. 기본값은 60초
- maxConnections: 서버가 동시에 수락하고 처리할 수 있는 최대 연결 수다. 기본값은 8192
- acceptCount: 최대 연결 수에 도달했을 때 대기할 수 있는 추가 연결 요청의 최대 수다. 기본값은 100
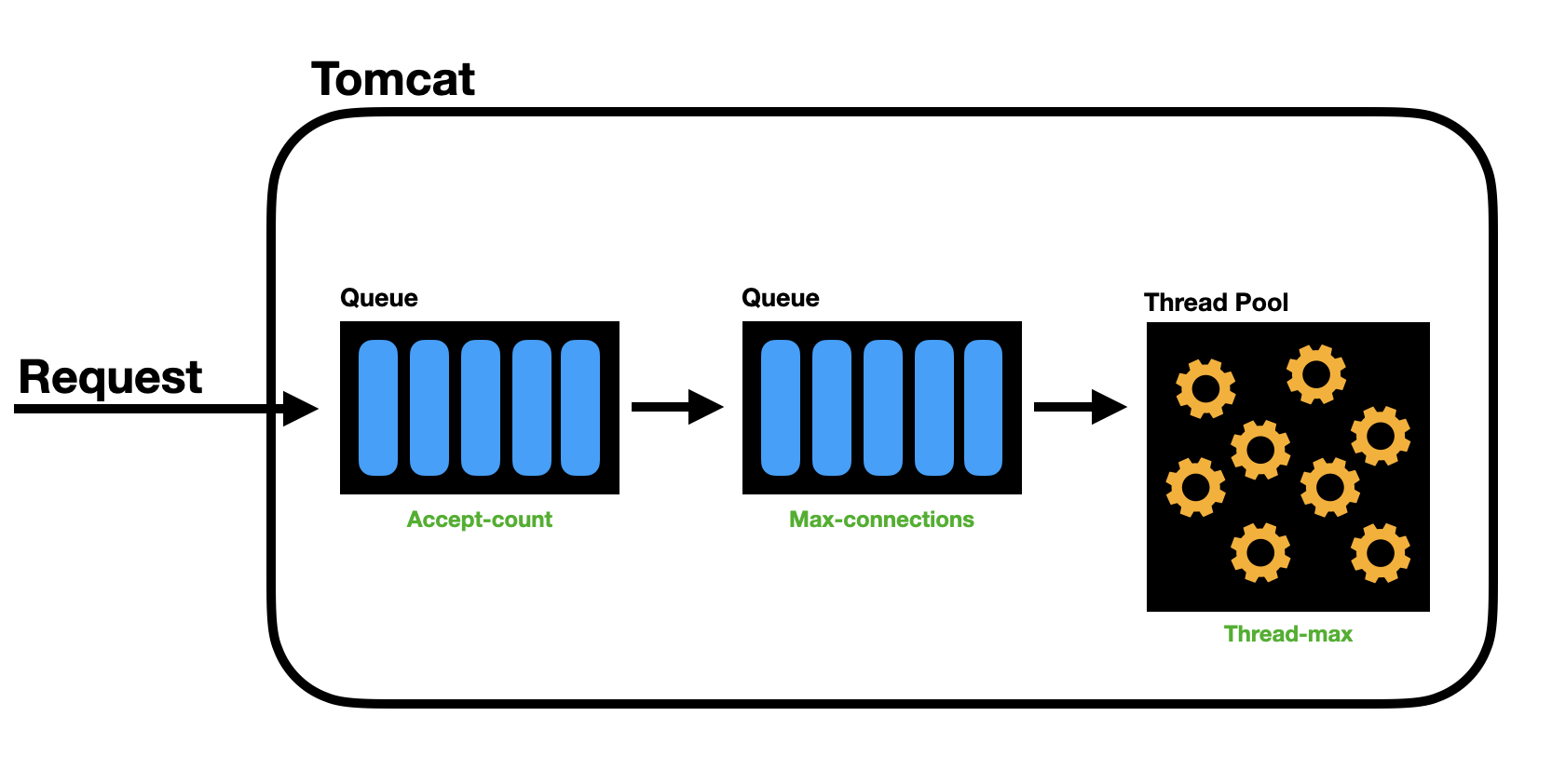
도식화하면 각 설정들이 이렇게 들어가는것을 알 수 있다.
Spring Boot와 Tomcat
그래도 Tomcat을 내장으로 띄워서 사용하는 SpringBoot인데 가만 생각해보면 SpringBoot가 Tomcat의 기본 설정값을 바꿔놨을 수도 있다는 생각이 든다.
간단한 구글 검색으로 Baeldung 문서를 하나 찾을 수 있었다.
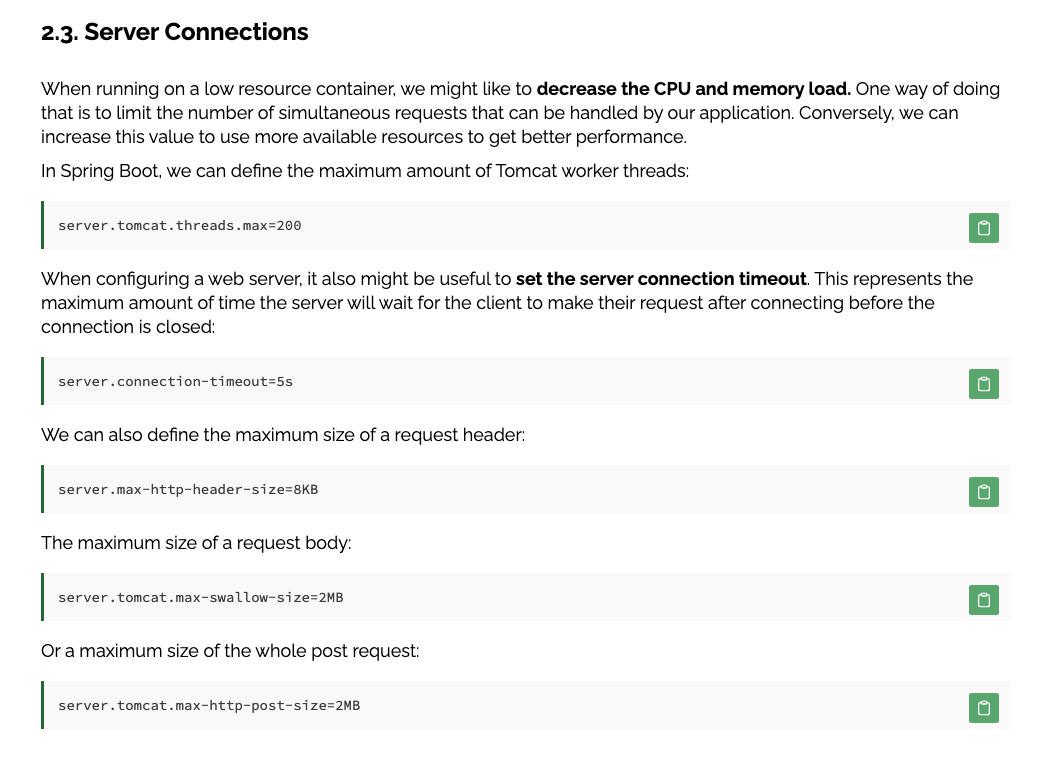
오? 아까봤던 tomcat의 Thread Pool 최대 스레드 개수를 설정할 수 있다고 한다.
server.tomcat 아래의 설정들을 한번 살펴보자.
SpringBoot의 application.properties (혹은 yaml) 내용은 사실 spring autoconfigure의 기능이다. @ConfigurationProperties()에 매핑되는 클래스에 대한 내용을 손쉽게 설정할 수 있게 도와준다. 이번 tomcat의 경우 ServerProperties 라는 클래스를 별도의 설정파일로 관리할 수 있도록 해주는 것이다.
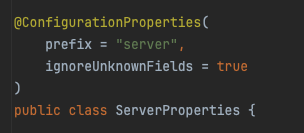
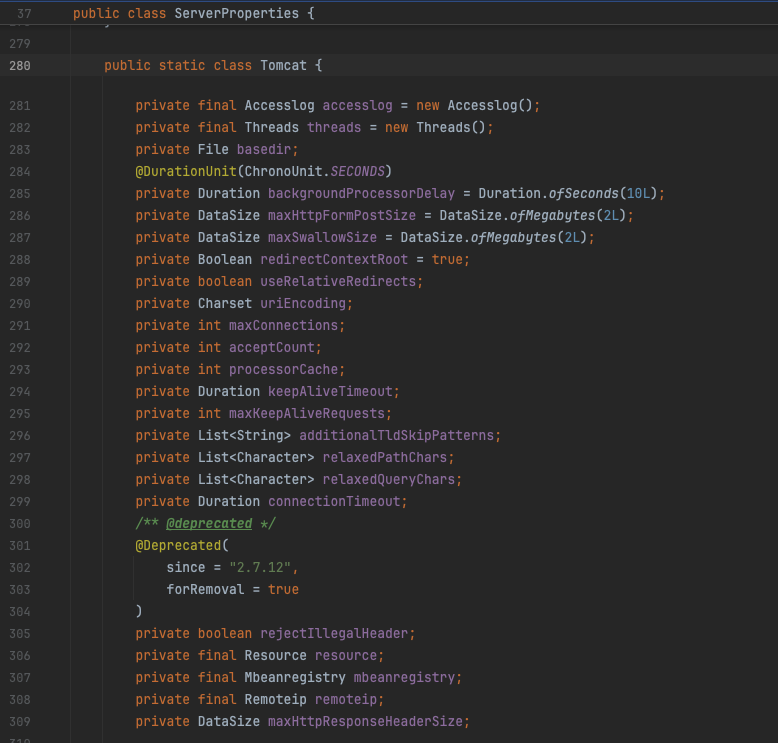
Spring Boot가 정의하고있는 Tomcat 클래스다! 아까 봤던 공식문서에 있는 값들이 정의되어있다.
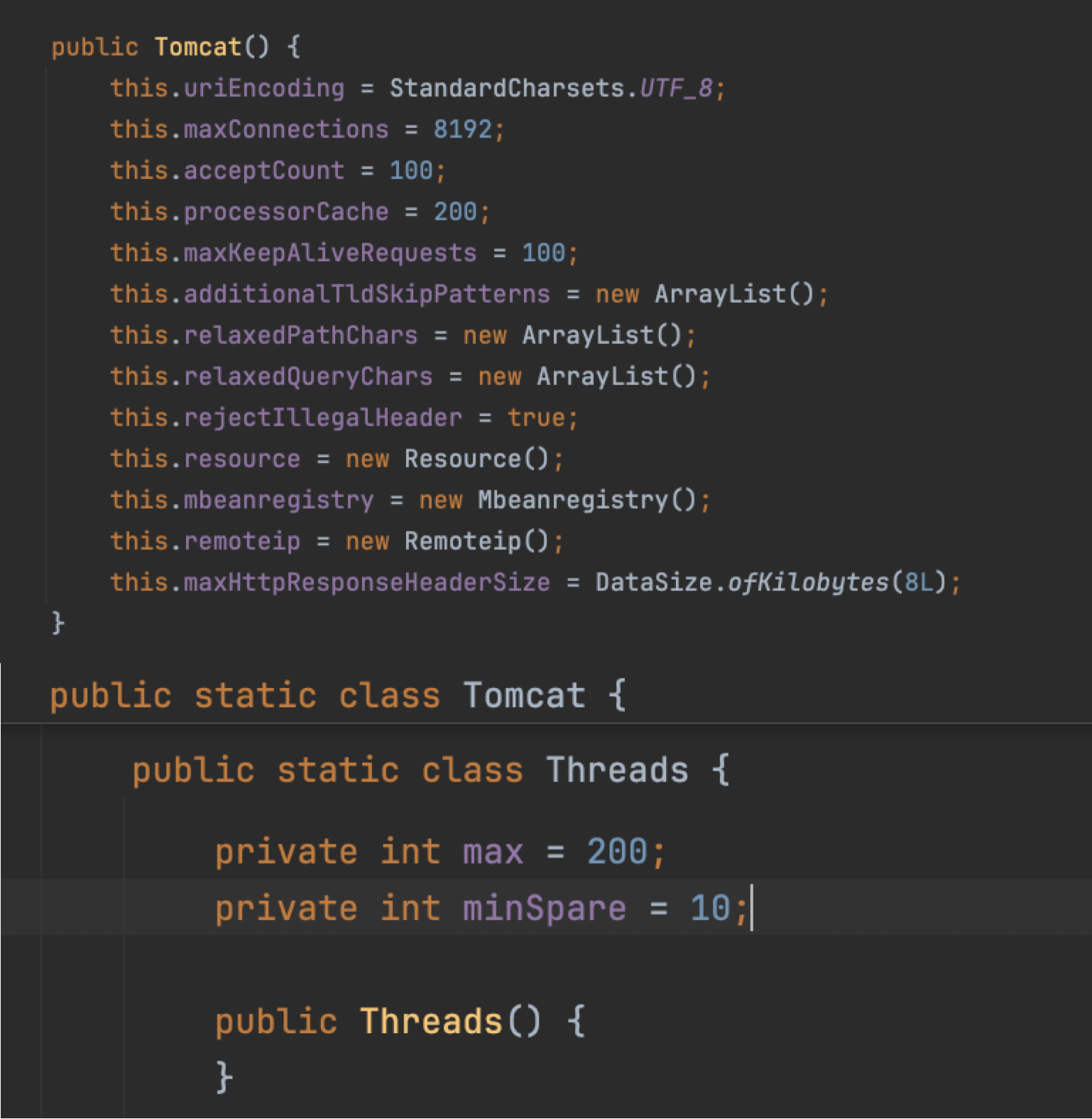
다행히도(?) 기본 값은 Tomcat의 값을 따르고 있는 것을 볼 수 있었다.
다시 DBCP로 돌아와서
DBCP로 다시 돌아와서 Connection Pool을 구현하는 라이브러리에 대해 살펴보자.
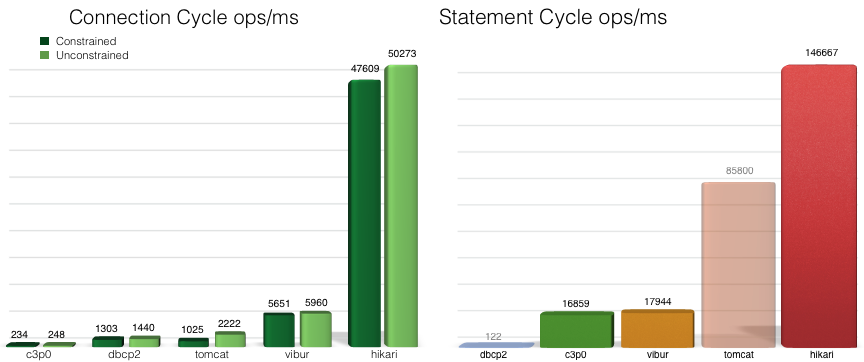
HikariCP Github에서 제공하는 벤치마크다. 본인들 사이트라서 신뢰할만할까 싶긴한데 그래도 거짓말은 안쳤겠지..ㅎㅎ
이처럼 dbcp2, c3p0, tomcat, hikari 등등 Connection Pool을 구현하는 라이브러리가 여럿 존재한다.
벤치마크만 봐도 압살이라서 HikariCP를 안쓸 이유가 없어보인다.
SpringBoot는 무엇을 사용하고있을까?

공식문서를 살펴보면 기본적으로 HikariCP를 사용하고, Tomcat, Commons DBCP2 순서대로 사용하고, 다 없다면 Oracle UCP를 사용한다고 명시되어있다. 역시 HikariCP가 잘만들긴 했나보다.
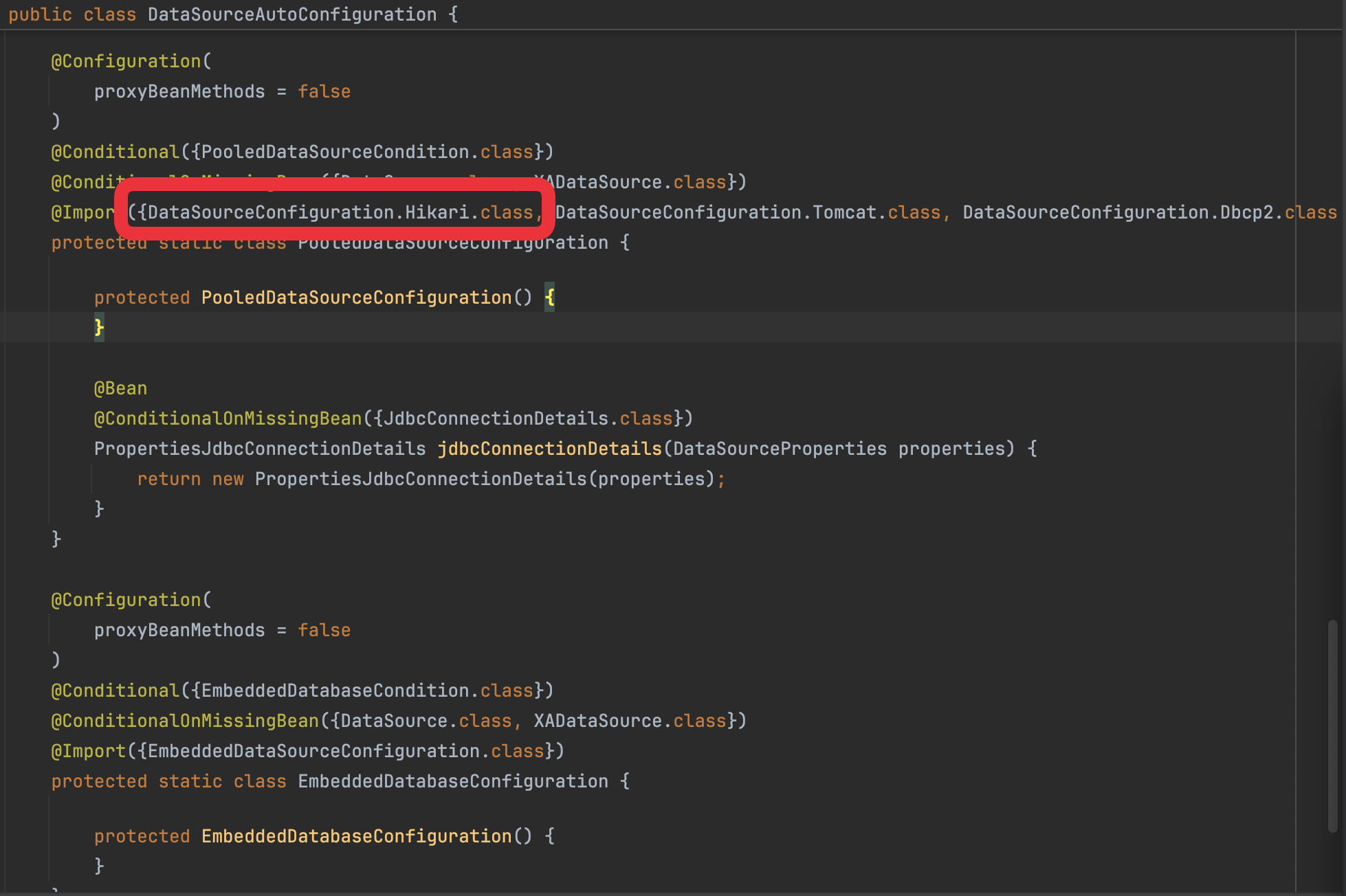
실제로 SpringBoot DataSourceAutoConfiguration 코드를 살펴보면 공식문서에서 설명한 순서대로 Import가 구성되어있는 것을 볼 수 있다.
별도로 spring.datasource.type 속성을 지정하지 않는 한 가장 먼저 선언되어있는 Hikari가 기본으로 사용된다.
한줄요약 하자면 SpringBoot의 JDBC Connection Pool 라이브러리는 기본적으로 HikariCP를 사용한다.
HikariCP 커넥션풀 몇개?
HikariCP의 설정을 살펴보자.
공식 Github의 README를 확인하면 기본 설정값이 나온다.
- autoCommit:
- 커넥션풀에서 반환된 커넥션의 기본 자동 커밋
- 기본값:
true
- connectionTimeout
- 커넥션풀에서 커넥션을 얻을 때 까지 기다리는 시간
- 기본값:
30000(30 seconds)
- idleTimeout
- 커넥션풀에서 IDLE(유휴)상태로 유지될 수 있는 최대 시간
- 기본값:
600000(10 minutes)
- keepaliveTime
- 기본값:
0(disabled)
- 기본값:
- maxLifetime:
- 커넥션 풀 내의 각 커넥션이 유지될 수 있는 최대 시간이다. 커넥션이 장시간 연결되는 현상을 방지하기 위한 설정값이다.
- 기본값:
1800000(30 minutes)
- connectionTestQuery:
- 커넥션 연결 전에 테스트 쿼리를 날리는 옵션이다. MySQL의 경우 SELECT 1을 날리게된다.
- 기본값: none
- minimumIdle:
- 커넥션 풀에서 유지하려고 하는 최소 유휴 연결 수를 설정한다. 예를 들어 총 커넥션 개수가 이 값보다 적으면 HikariCp가 추가적으로 IDLE 상태의 커넥션을 만든다.
- 기본값:
maximumPoolSize와 동일하다.
- maximumPoolSize:
- 커넥션풀의 최대 크기를 설정한다. 이 값은 실제 데이터베이스와 연결하는 커넥션의 최대 수를 결정한다.
- 기본값:
10
대략 성능에 직결될 것 같은 볼 부분들을 가져와봤다.
이 중 maximumPoolSize와 connectionTimeout값을 보자.
30초의 Timeout.. 어디서 봤는데?
지난 글의 복선 회수하기
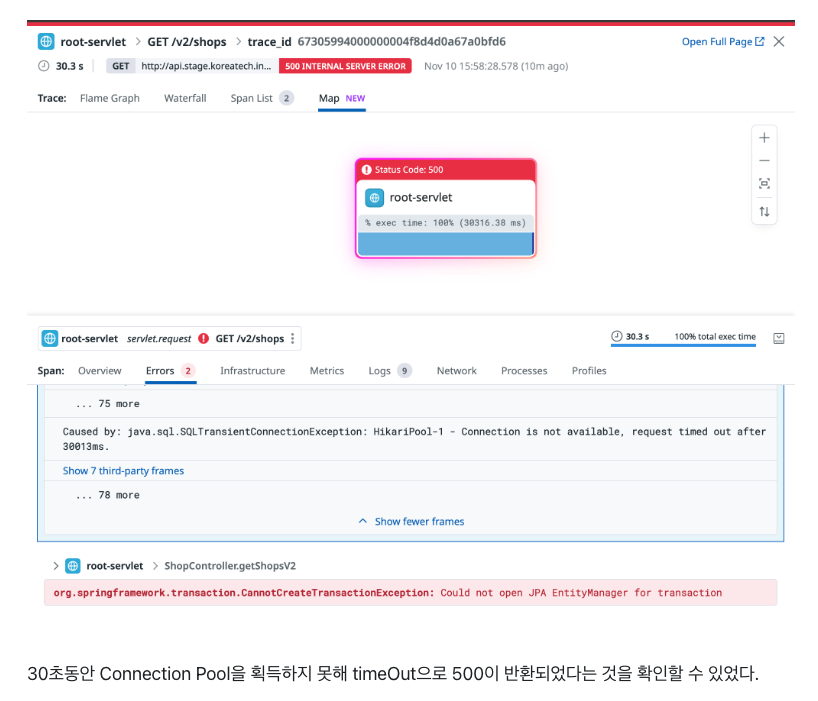
바로 이 connectionTimeout 설정으로 인해 30초동안 connection을 기다리다 나는 에러였음을 다시 확인해볼 수 있다.
근데 maximumPoolSize가 10개인데 DB가 10개의 커넥션을 처리 못하나? 무슨 문제가있지? 의문점이 든다.
DB의 관점에서
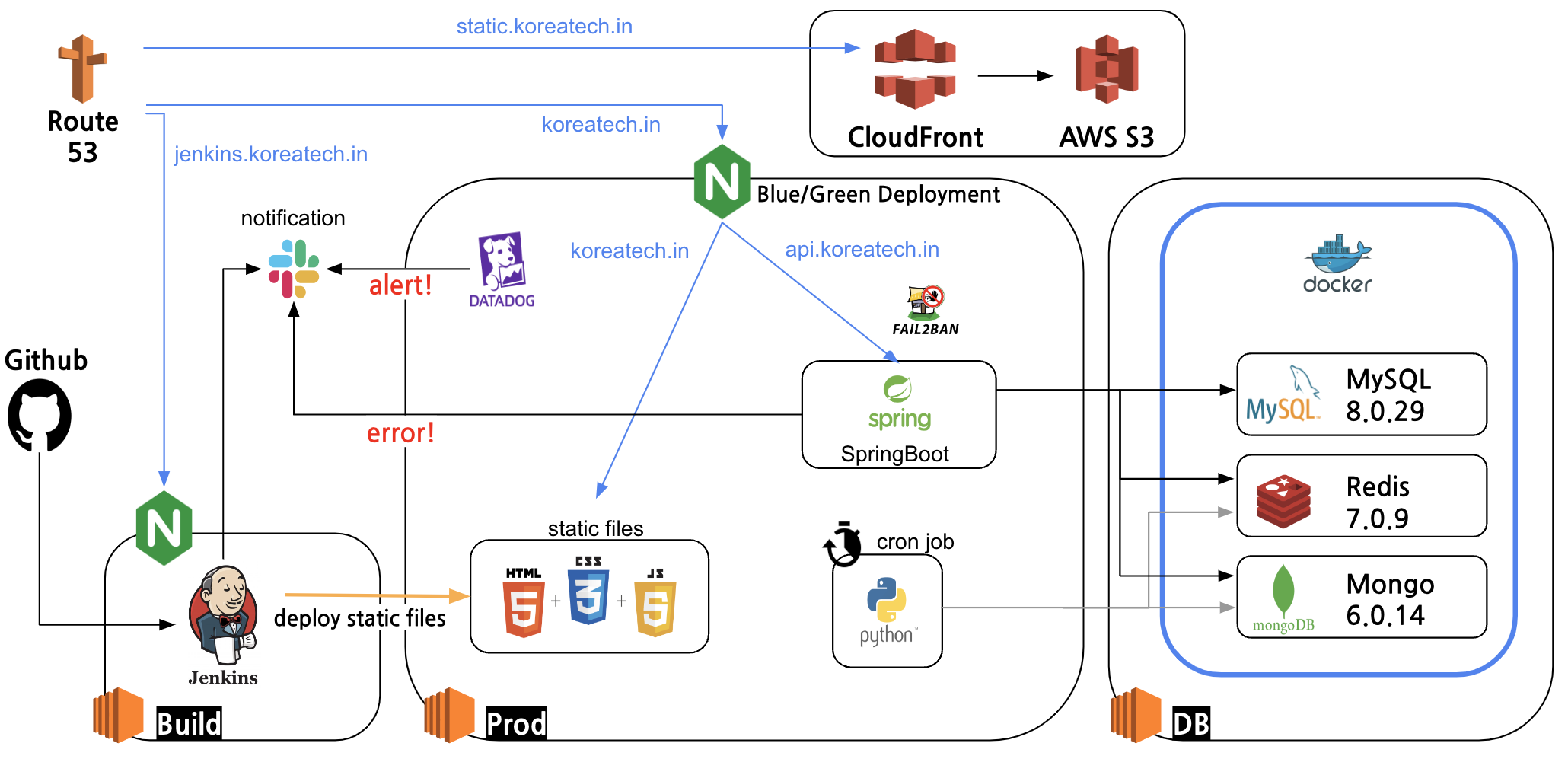
위 아키텍처에서 별도로 떠있는 서버를 확인해보자

DB가 떠있는 서버의 사양은 AWS EC2 t3a.small이다.
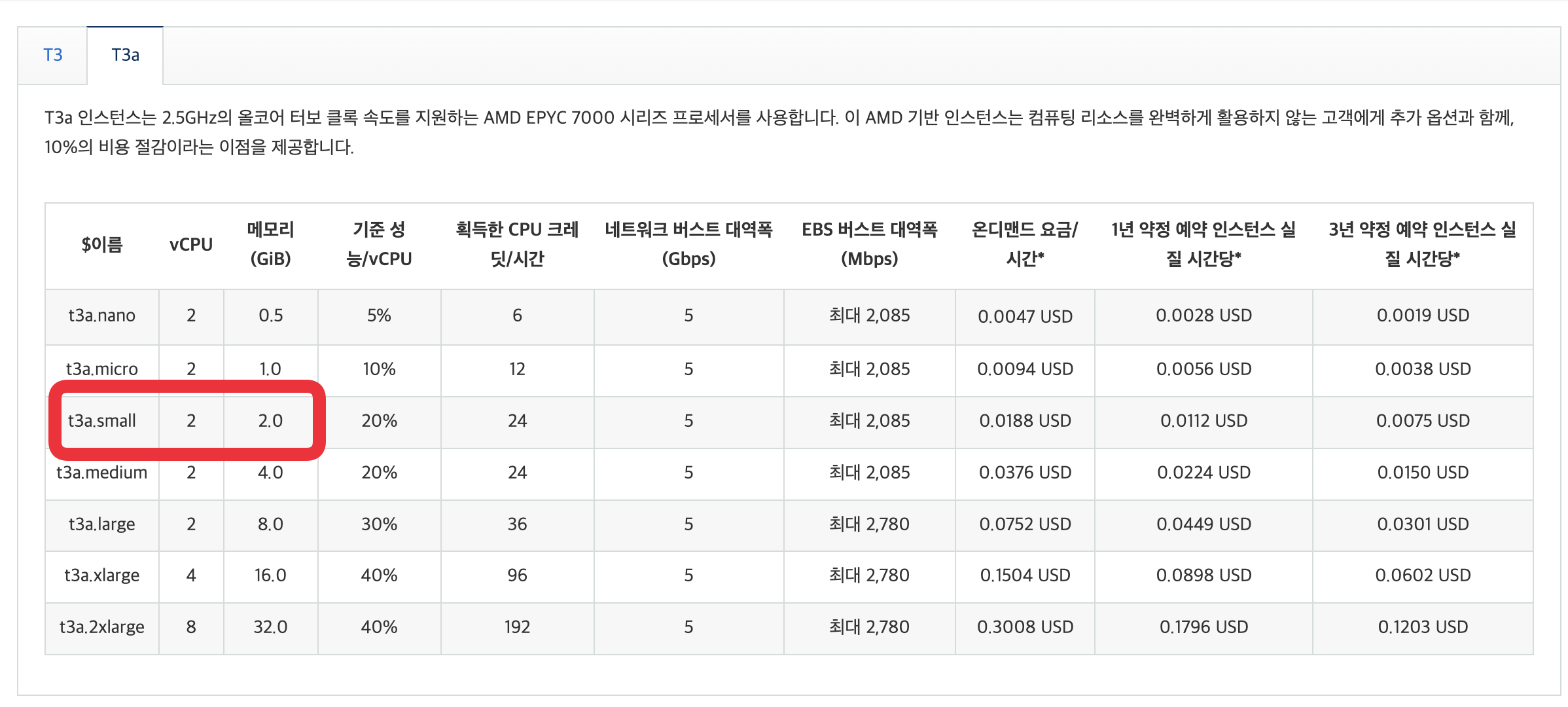
서버의 자원은 CPU 2코어, 메모리 2GB다.
HikariCP Wiki - About Pool Sizing 을 보면 공식을 하나 제시하고있다.
Connection Pool의 적정 값은 서버의 코어수 x 2 + 1 현재 서버의 사양과는 맞지 않는 양임을 알 수 있다.
커넥션 풀 10개를 꽃아도 서버가 그만한 연산을 처리하지 못해 커넥션 타임아웃이 나고, 커넥션풀 할당도 제때 일어나지 않는 그런 문제들이 일어나는 것 같다.
정리
네트워크 호출 시점부터 DB를 찍는 지점까지 내려와봤다.
얼추 개선점을 크게 몇가지 정리해보면 다음과 같다.
- 네트워크 레벨의 성능 개선
Http/2 (혹은 Http/3)을 도입해서 TCP 커넥션의 개수를 줄이고 멀티플렉싱하는 방식을 통해 성능 개선을 기대해볼 수 있겠다.
- Tomcat Http connectionTimeout 값 조정
60초면 유저 이탈이 충분히 일어날 시간이라고 예상된다. 서비스의 특성, 트래픽을 고려하여 커넥션 타임아웃 시간을 조정해 사용자에게 빠른 피드백을 줄 수 있겠다.
- HikariCP 커넥션풀 개수 조정
서버 사양에 비해 커넥션 풀의 개수가 많은것을 확인했다.
커넥션 풀 개수를 조절하면서 성능테스트를 수행하고 적정 선을 찾을 필요가 있어보인다. (공식 상 4~5개가 적정선이지만 실제 테스트가 필요해보인다.)
다음 시간부터는 위에서 확인한 문제들을 하나씩 잡아가며 성능을 개선해보려고한다.
Reference
- https://velog.io/@fastdodge7/%EC%9A%B0%EB%A6%AC%EA%B0%80-%EC%A3%BC%EC%86%8C%EC%B0%BD%EC%97%90-naver.com%EC%9D%84-%EC%B3%A4%EC%9D%84-%EB%95%8C-%EC%9D%BC%EC%96%B4%EB%82%98%EB%8A%94-%EC%9D%BC
- https://justforchangesake.wordpress.com/2014/05/07/spring-mvc-request-life-cycle/
- https://www.geeksforgeeks.org/tcp-3-way-handshake-process/
- https://www.cloudflare.com/ko-kr/learning/ssl/what-happens-in-a-tls-handshake/
- https://freecontent.manning.com/.well-known/sgcaptcha/?r=%2Fmental-model-graphic-how-is-http-1-1-different-from-http-2%2F&y=ipc:35.166.24.88:1731742117.702


네트워크 시간에서 배운게 그대로 나오네