
서론
지난 시간에 테스트 도구의 종류를 알아보고 직접 사용해봤다.
이번 시간에는 내 나름의 근거를 주장하면서 성능을 개선해보려고한다.
다음과 같은 단계를 통해 성능 개선을 해보자.
- 운영중인 서비스의 핵심 기능을 파악한다.
- 핵심 기능의 성능 목표치를 정한다.
- 성능테스트 도구를 활용하여 성능이 목표치에 부합하는지 확인한다.
- 만약 목표치에 부합하지 않는다면 성능 개선점을 찾아본다.
단, 성능 개선 과정에서 비용을 추가적으로 지출하지 않아야한다. (단순 스케일업은 최최최후의 보루)
핵심 기능 파악하기
학생들에게 편의를 제공해주는 코인(Koreatech In) 사이트를 운영하고 있다. 이 서비스에 대한 이야기를 주로 다룰 예정이다.
사이트 링크: https://koreatech.in
나는 주변 상점 정보를 다루고있는 비즈니스 팀에 속해있다. 이에 비즈니스팀의 핵심 기능에 대해 파악해보고자 한다.
학생들이 앱에 접속했을 때 가장 많은 빈도수로 일어나는 작업이 식단확인, 주변 상점 정보 확인이다.
식단 도메인은 비즈니스팀의 영역이 아니기에 주변 상점 정보를 확인하는 부분을 살펴보자.
모든 상점의 정보를 불러오는 행위가 가장 빈도수가 많을 것으로 예상된다.
실제로 그러한지 Datadog으로 호출 빈도수를 확인해보자.
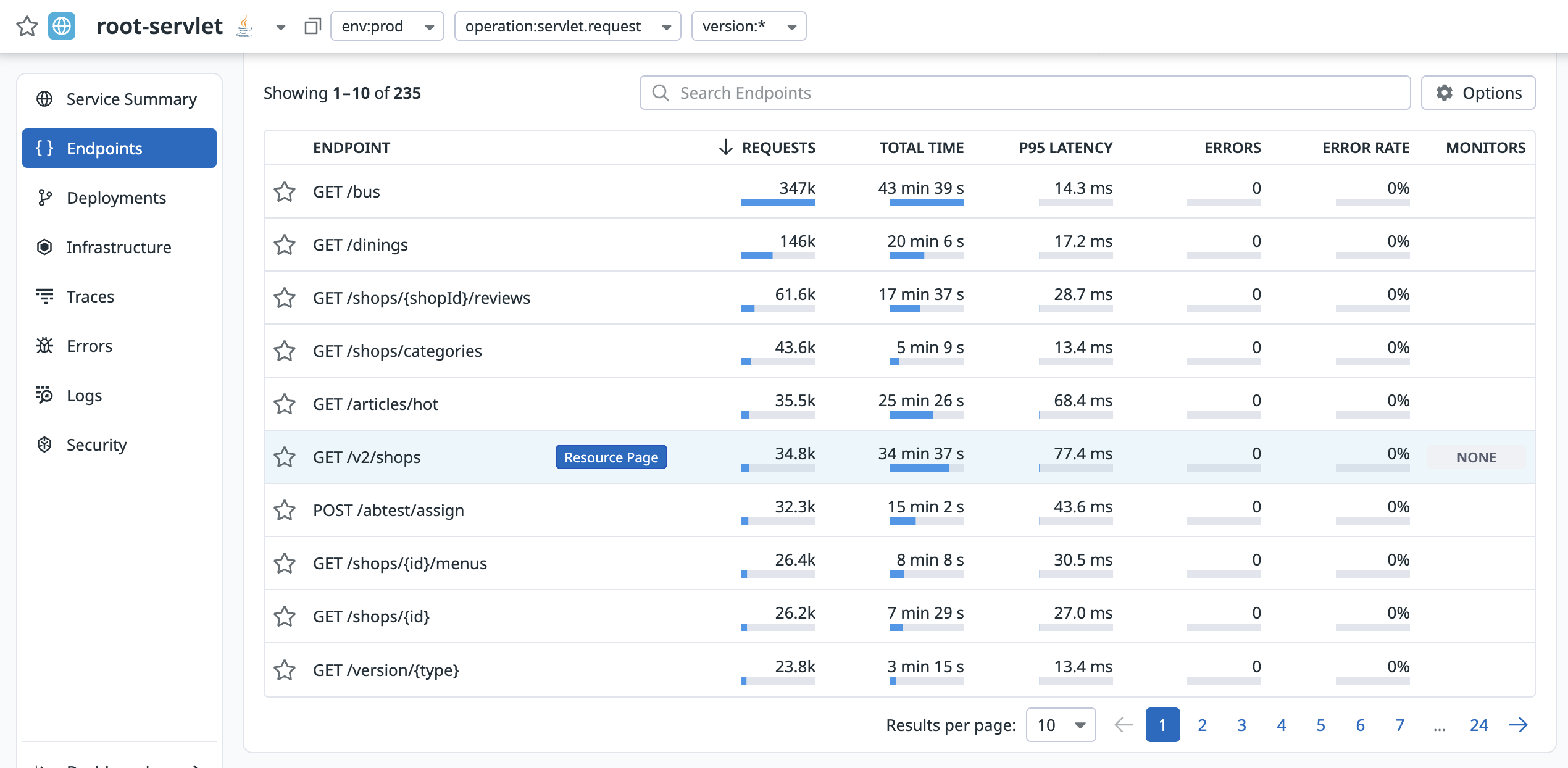
지난 1달간 API 호출 횟수를 내림차순으로 정렬한 결과다.
GET /v2/shops가 모든 상점을 조회하는 API로 6번째로 많이 호출되는것을 확인할 수 있다.
근데 가만보면 호출 횟수로 보니
GET /shops/{shopId}/reviews가 제일 많이 호출된다.서비스 플로우상
상점 목록 조회>상점 상세정보 조회>리뷰 조회의 흐름으로 진행되어야한다고 생각이 드는데 뭔가 이상하다.확인해보니 클라이언트 측에서 따닥 요청을 보내고 있는것으로 확인되었다.. 이건 클라이언트에게 따닥 요청에 대해 개선해달라고 부탁하는 방향으로 넘어가고 다시 /v2/shops API로 넘어가보자.
현재 GET /v2/shops의 평균 응답시간은 77.4ms로 매우 안정적인 응답시간을 보여주고있다.
여담이지만 Google Developer 가이드 중 웹 사이트 성능 개선에 대한 글 중 하나에서는 서버의 응답시간을 200ms 이내로 줄여야한다고 권장하고있다.
구글이 정한 200ms 라는 기준에는 아주 잘 부합한다고 볼 수 있겠다.
성능 목표치 정하기
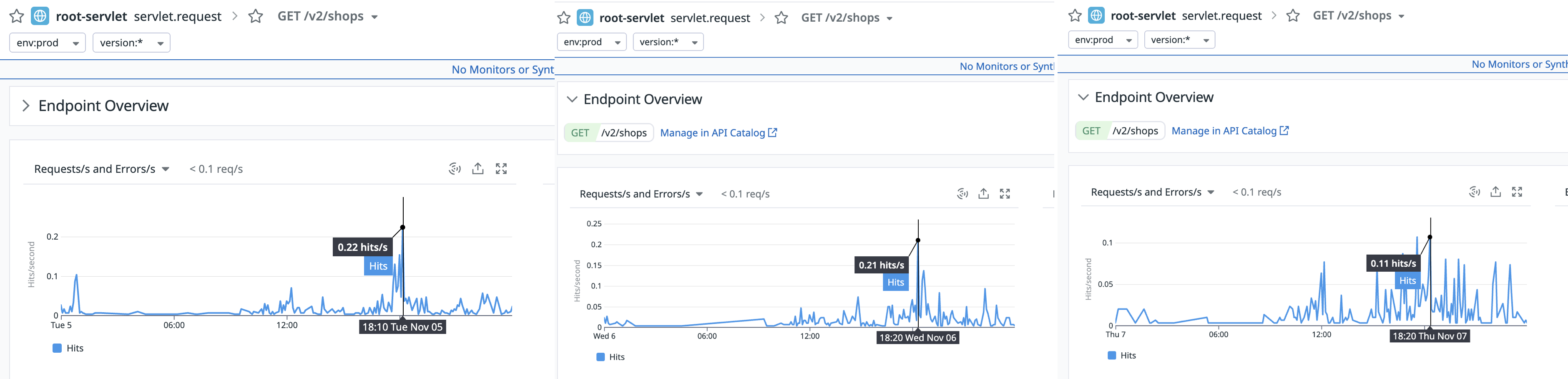
우선 이번 주의 실제 사용자 패턴을 확인해보면 오후 6시쯤이 되면 학생들이 배달음식을 시켜먹으려고 몰려드는 모습이 보인다.
이 때 몰려드는 트래픽의 수는 0.11 ~ 0.22 hit/s다.. 1초에 0.22번 호출이라니 교내 학생을 대상으로 한 서비스다보니 대용량 트래픽은 어림도 없어보인다 😅
일단 트래픽이 몰리는 시간은 평균적으로 약 10분가량 지속되는것을 확인했으니 이 시간을 기준으로 다양한 시나리오를 잡아보자.
사실 측정되는 데이터 수가 너무 적어 실제 사용자 수를 기반으로 성능테스트의 시나리오를 잡는것에 큰 의미가 없어보인다. 그래도 성능 목표치에 부합하는지 시나리오는 만들어보자.
- 측정된 트래픽을 기반으로 시나리오 작성 (10분간 지속)
- 평균 부하테스트: 1명의 유저가 5초에 1회씩 요청을 보내는 환경에서 API 응답 분포를 확인한다.
(0.2 req/s) - 스트레스 테스트: 1명의 유저가 1초에 1회씩 요청을 보내는 환경에서 API 응답 분포를 확인한다.
(1 req/s) - 스파이크 테스트: 200명의 유저가 1초에 1회씩 요청을 보내는 환경에서 API 응답 분포를 확인한다.
(200 req/s) - 브레이크 포인트 테스트: 유저수를 늘리면서 API가 수용할 수 있는 처리량의 한계치를 확인한다.
(INF req/s)
- 평균 부하테스트: 1명의 유저가 5초에 1회씩 요청을 보내는 환경에서 API 응답 분포를 확인한다.
테스트 수행하기
GUI로 실행계획과 결과를 확인할 수 있는 nGrinder를 이용하여 테스트를 수행해보려고한다.
단순한 테스트에서 짜임새 있는 기반코드를 제공해주는 nGrinder가 가장 매력적으로 다가왔기 때문이다.
평균부하, 스트레스 테스트의 요청 수를 보면 너무나 당연히 처리할 수 있을 것으로 보이지만 그래도 시나리오대로 차근차근 성능테스트를 진행해보자 😅
평균 부하테스트
- 평균 부하테스트: 1명의 유저가 5초에 1회씩 요청을 보내는 환경에서 API 응답 분포를 확인한다.
(0.2 req/s)
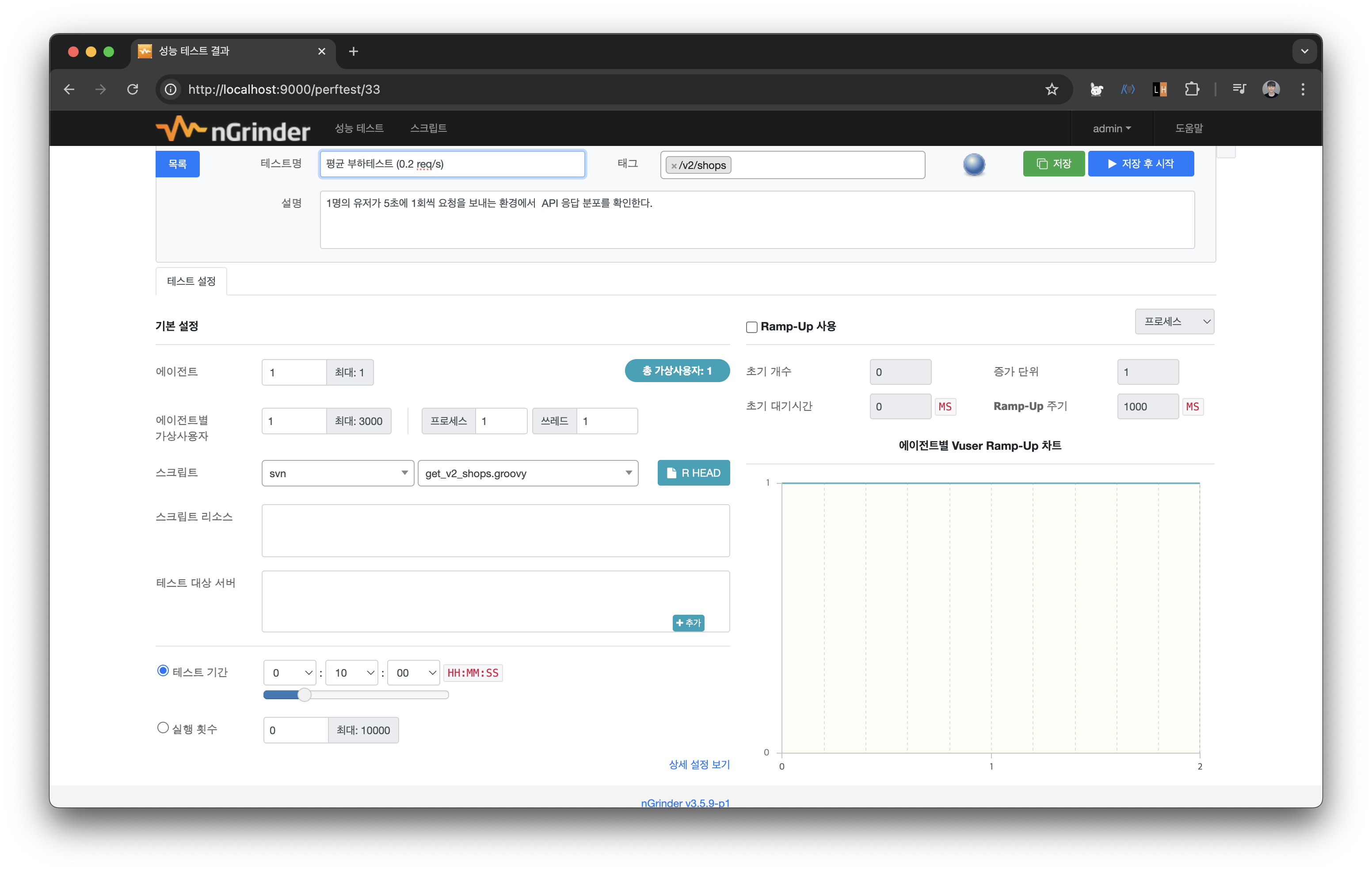
스크립트의 before에 grinder.sleep(5000)으로 설정하여 5초에 1번 요청을 보내도록 구성했다. vUser는 1명으로 설정하여 테스트를 구동해본다.
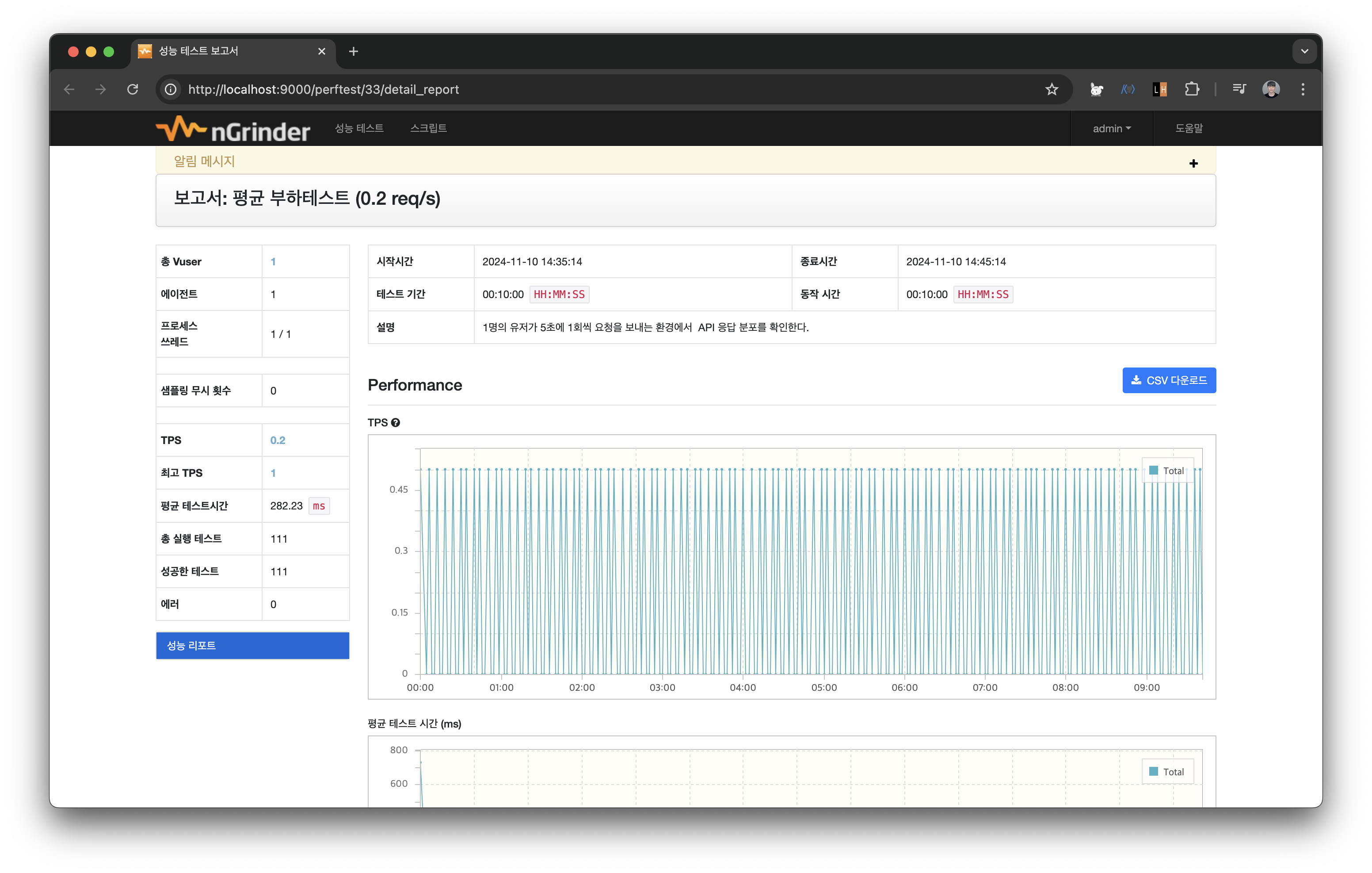
10분간 주어진 요청을 에러 없이 충분히 처리하는 모습을 볼 수 있다. 이를 통해 운영에는 문제가 없다고 판단할 수 있다.
스트레스 테스트
- 스트레스 테스트: 1명의 유저가 1초에 1회씩 요청을 보내는 환경에서 API 응답 분포를 확인한다.
(1 req/s)
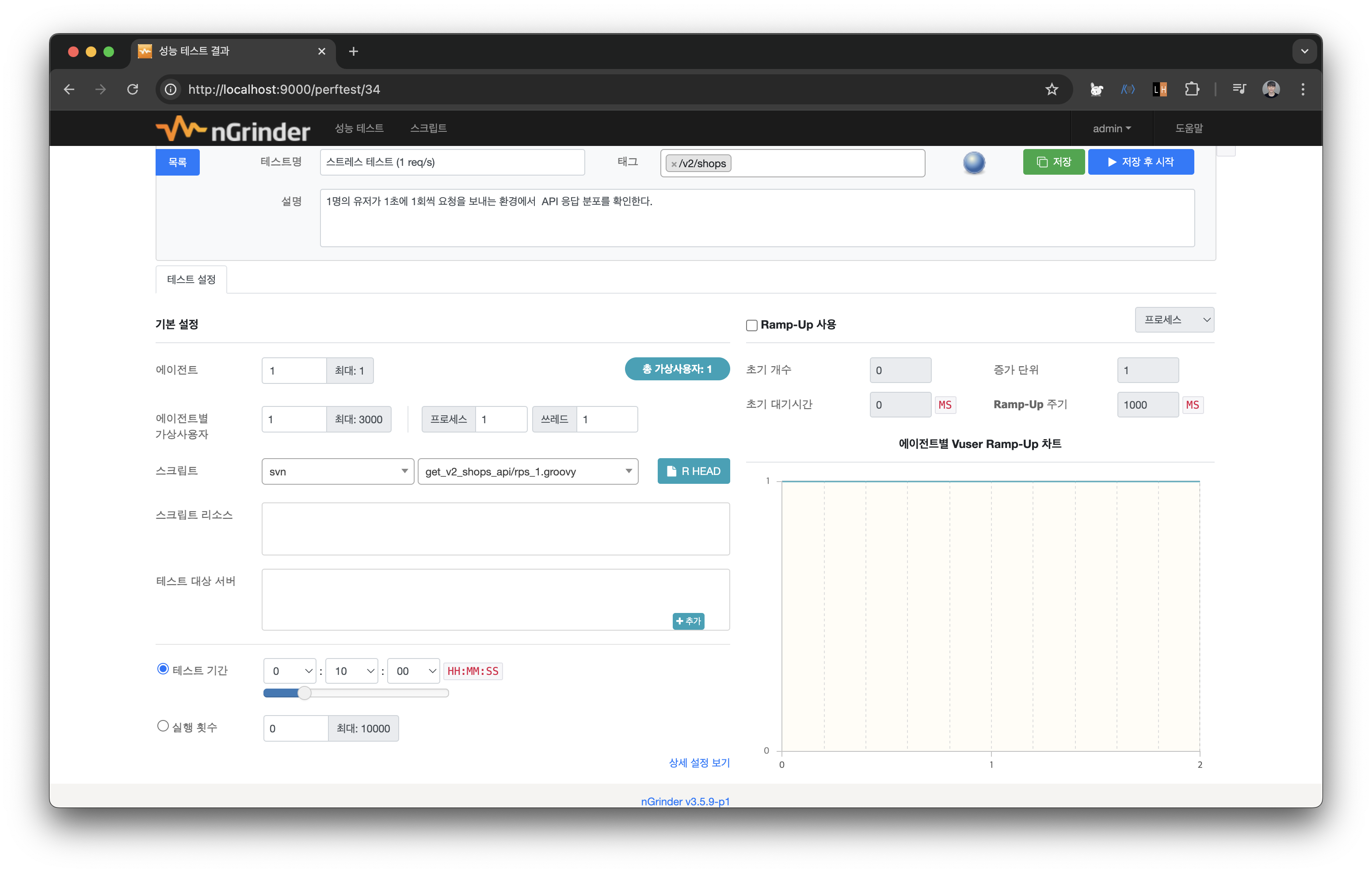
스크립트의 before에 grinder.sleep(1000)으로 설정하여 1초에 1번 요청을 보내도록 구성했다. 마찬가지로 vUser는 1명으로 설정하여 테스트를 구동해본다.
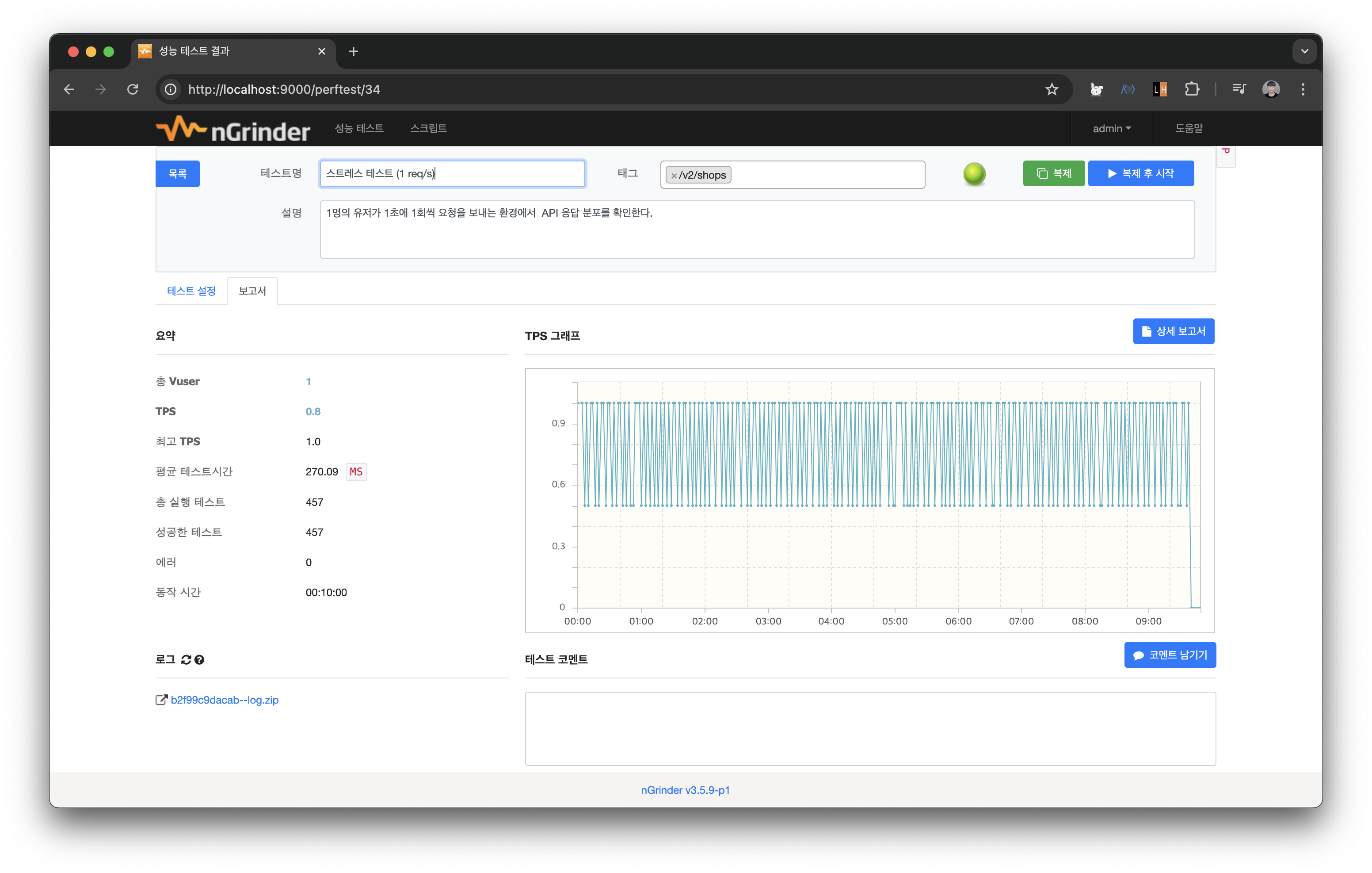
마찬가지로 10분간 주어진 요청을 에러 없이 충분히 처리하는 모습을 볼 수 있다.
스파이크 테스트
- 스파이크 테스트: 200명의 유저가 1초에 1회씩 요청을 보내는 환경에서 API 응답 분포를 확인한다.
(200 req/s)
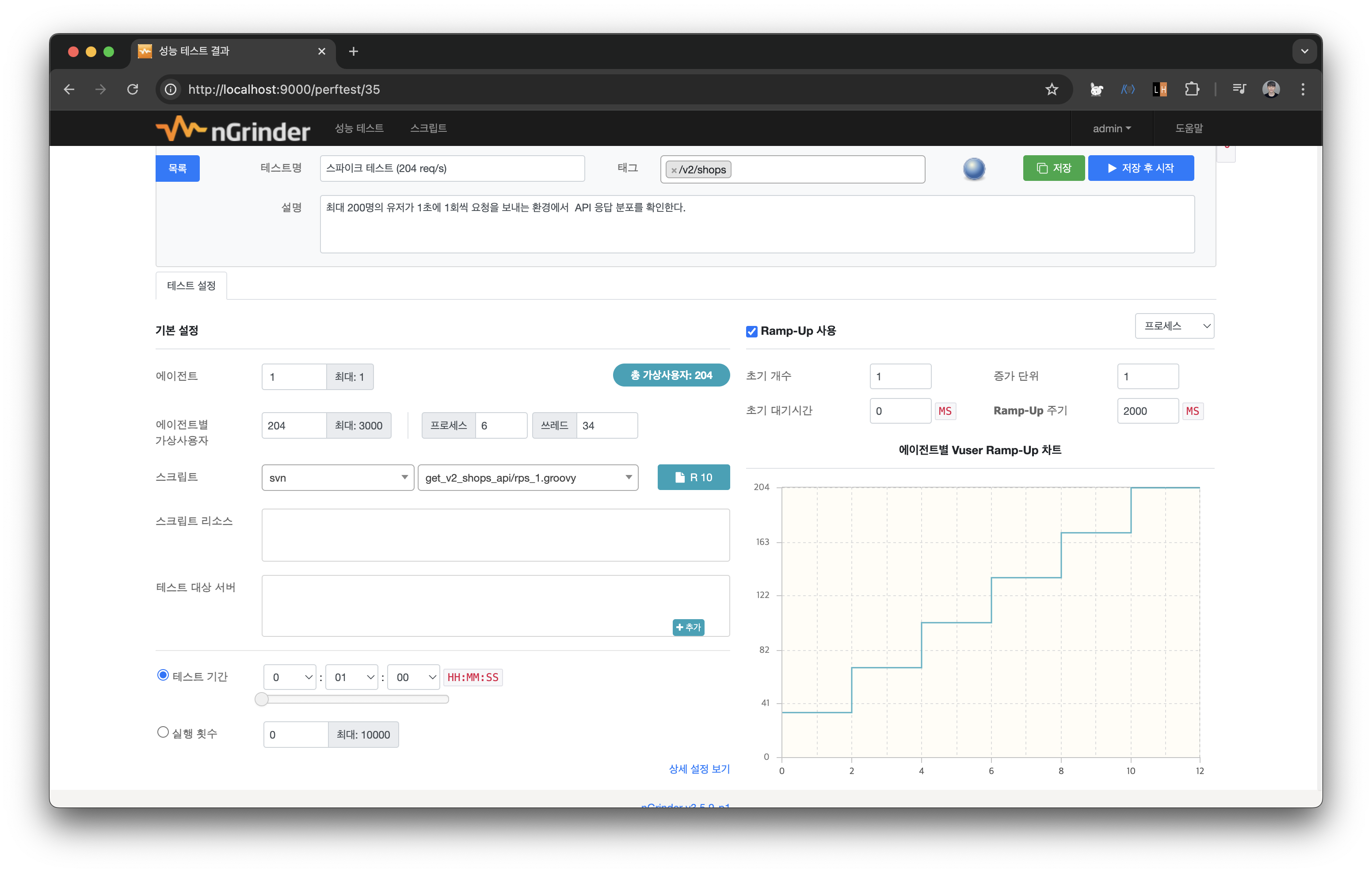
스크립트는 동일하나 vUser의 개수가 다르다.
순간적으로 요청이 솟구쳤을 때를 테스트해보기 위함이므로 시간을 비교적 짧게 설정하고, 브레이크가 걸리는 현상을 대비하여 Ramp Up을 설정한다. 10초 가량 지났을 때 스파이크 지점에 도달하게 된다.
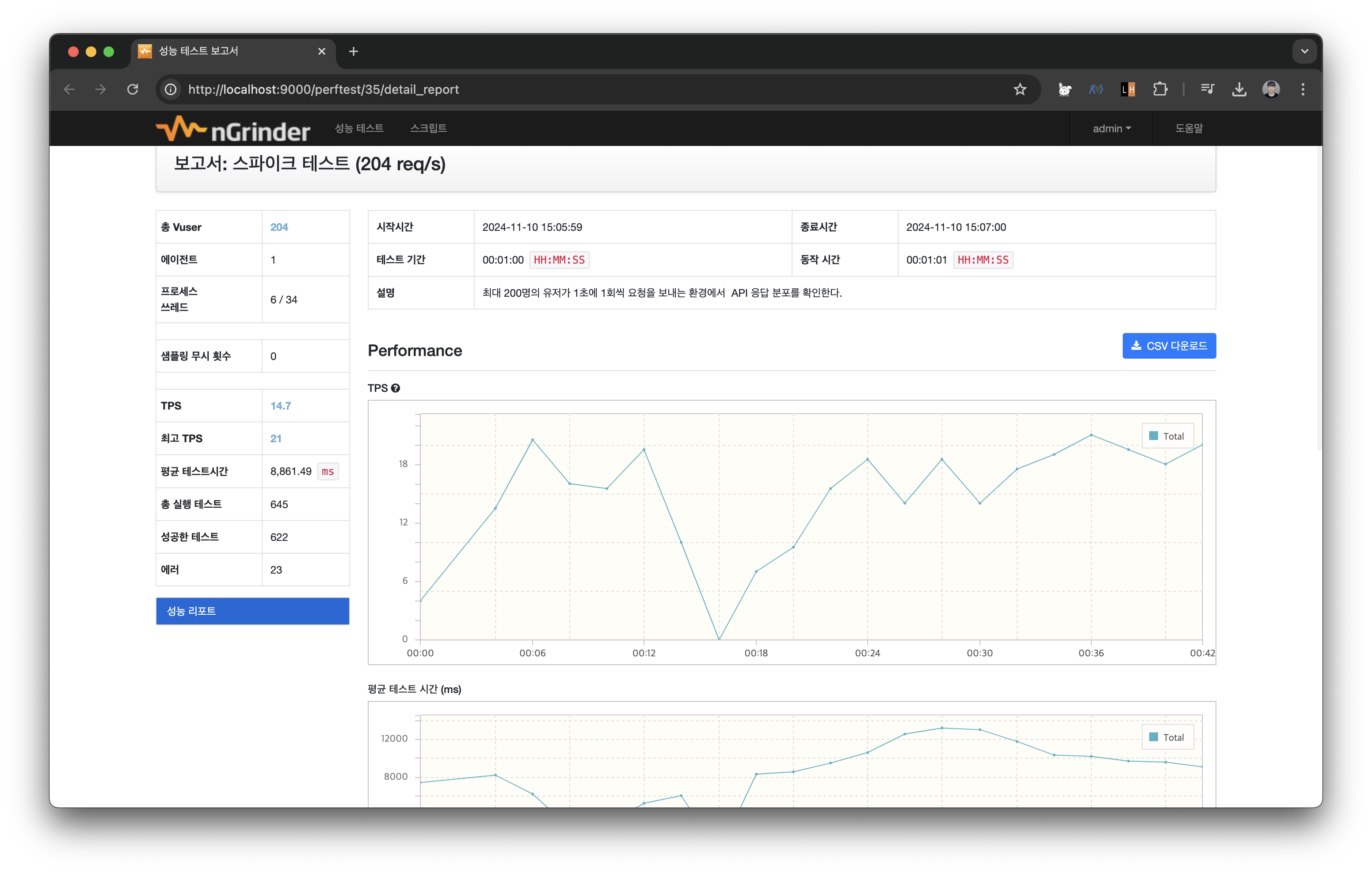
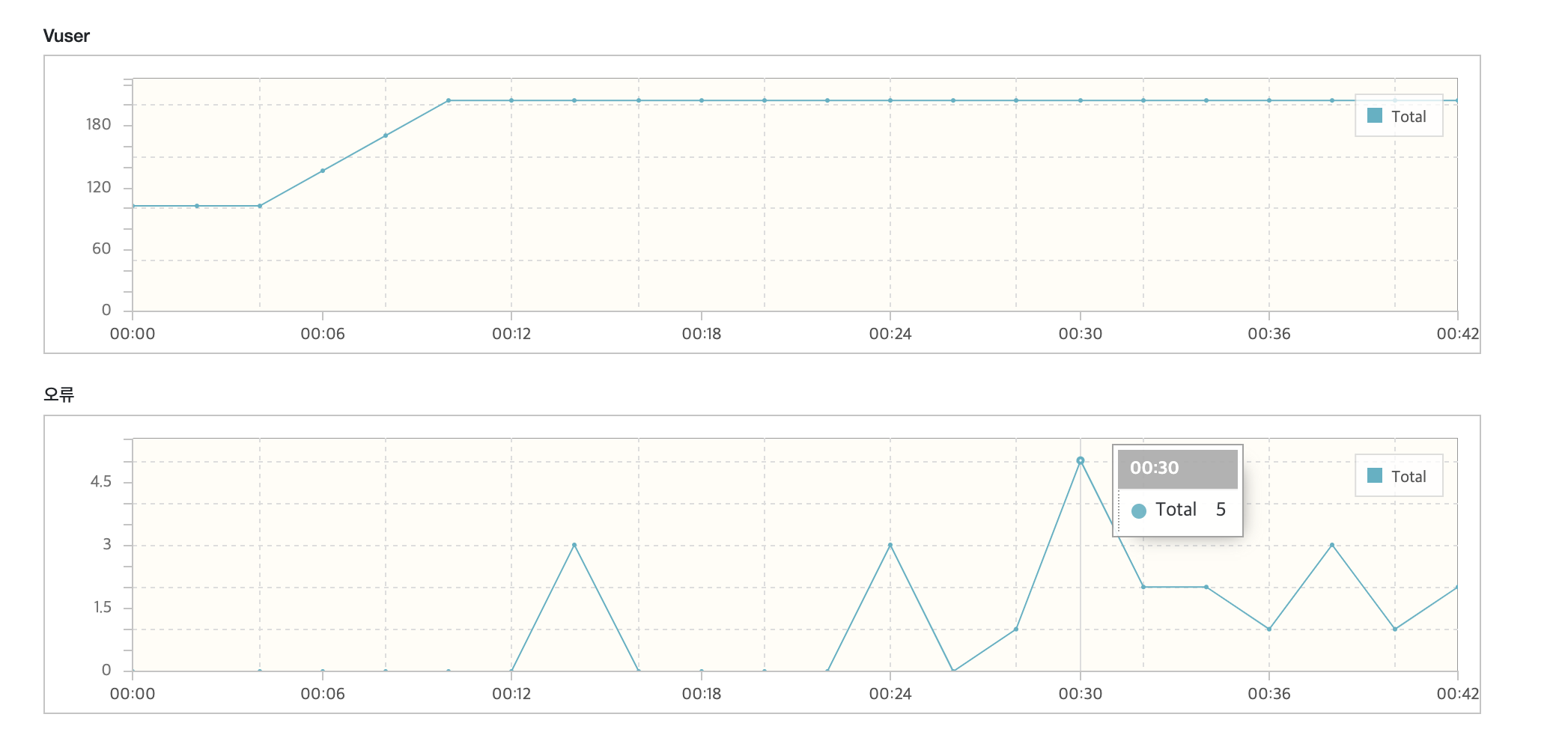
이번에는 오류가 발생한 모습을 볼 수 있다.
vUser가 200명정도 되었을 때 최대 5회의 오류가 발생하는 것을 볼 수 있다.
테스트 로그를 살펴보니 Connection 문제가 있는것이 확인된다.
2024-11-10 06:06:30,328 ERROR java.util.concurrent.ExecutionException: org.apache.hc.core5.http.ConnectionClosedException: Connection is closed
org.apache.hc.core5.http.ConnectionClosedException: Connection is closed
at org.apache.hc.core5.http.impl.nio.ClientHttp1StreamDuplexer.disconnected(ClientHttp1StreamDuplexer.java:219)
at org.apache.hc.core5.http.impl.nio.AbstractHttp1StreamDuplexer.onDisconnect(AbstractHttp1StreamDuplexer.java:398)
at org.apache.hc.core5.http.impl.nio.AbstractHttp1IOEventHandler.disconnected(AbstractHttp1IOEventHandler.java:95)
at org.apache.hc.core5.http.impl.nio.ClientHttp1IOEventHandler.disconnected(ClientHttp1IOEventHandler.java:39)
at org.apache.hc.core5.reactor.ssl.SSLIOSession$1.disconnected(SSLIOSession.java:212)
at org.apache.hc.core5.reactor.InternalDataChannel.disconnected(InternalDataChannel.java:174)
at org.apache.hc.core5.reactor.SingleCoreIOReactor.processClosedSessions(SingleCoreIOReactor.java:229)
at org.apache.hc.core5.reactor.SingleCoreIOReactor.doExecute(SingleCoreIOReactor.java:134)
at org.apache.hc.core5.reactor.AbstractSingleCoreIOReactor.execute(AbstractSingleCoreIOReactor.java:85)
at org.apache.hc.core5.reactor.IOReactorWorker.run(IOReactorWorker.java:44)해당 문제를 검색해봤을 때는 https 커넥션 설정을 계속 다시 맺어서 생기는 커넥션 자원 고갈 이슈로 판단된다.
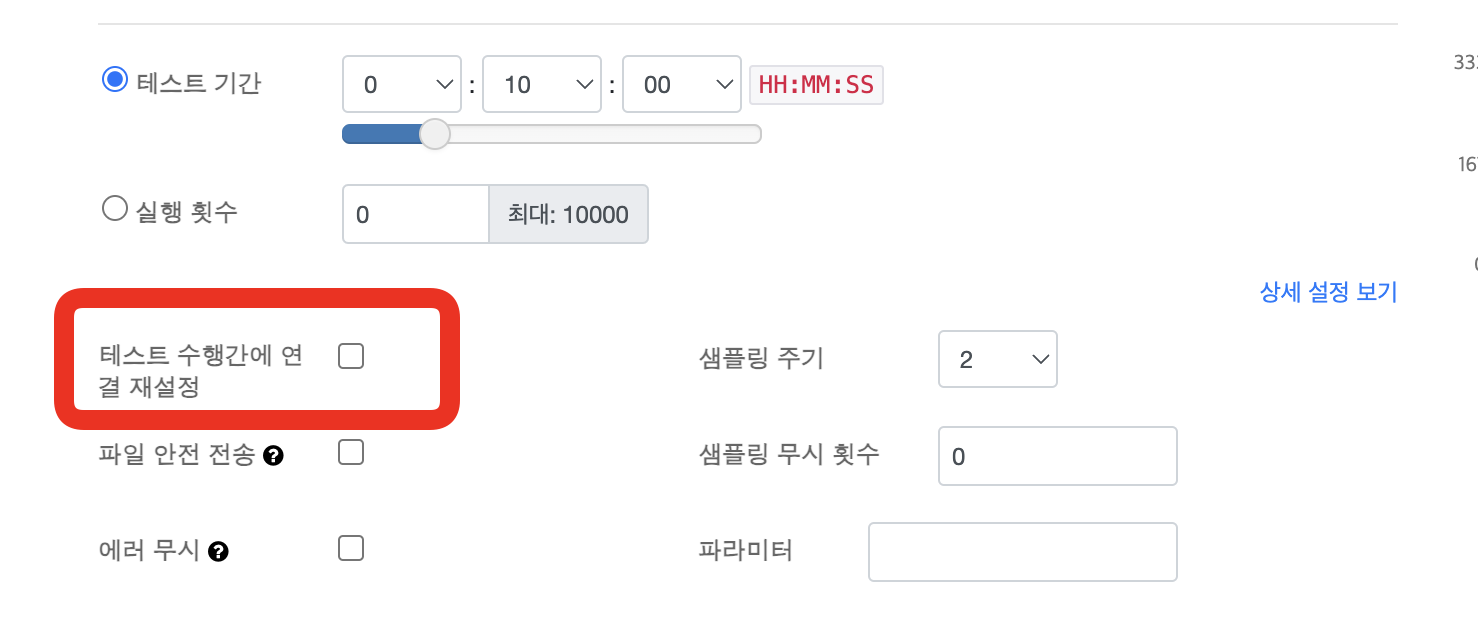
테스트 수행간에 연결 재설정 옵션을 끄고 다시 테스트해보니 오류율이 많이 줄어든 것을 볼 수 있었다.
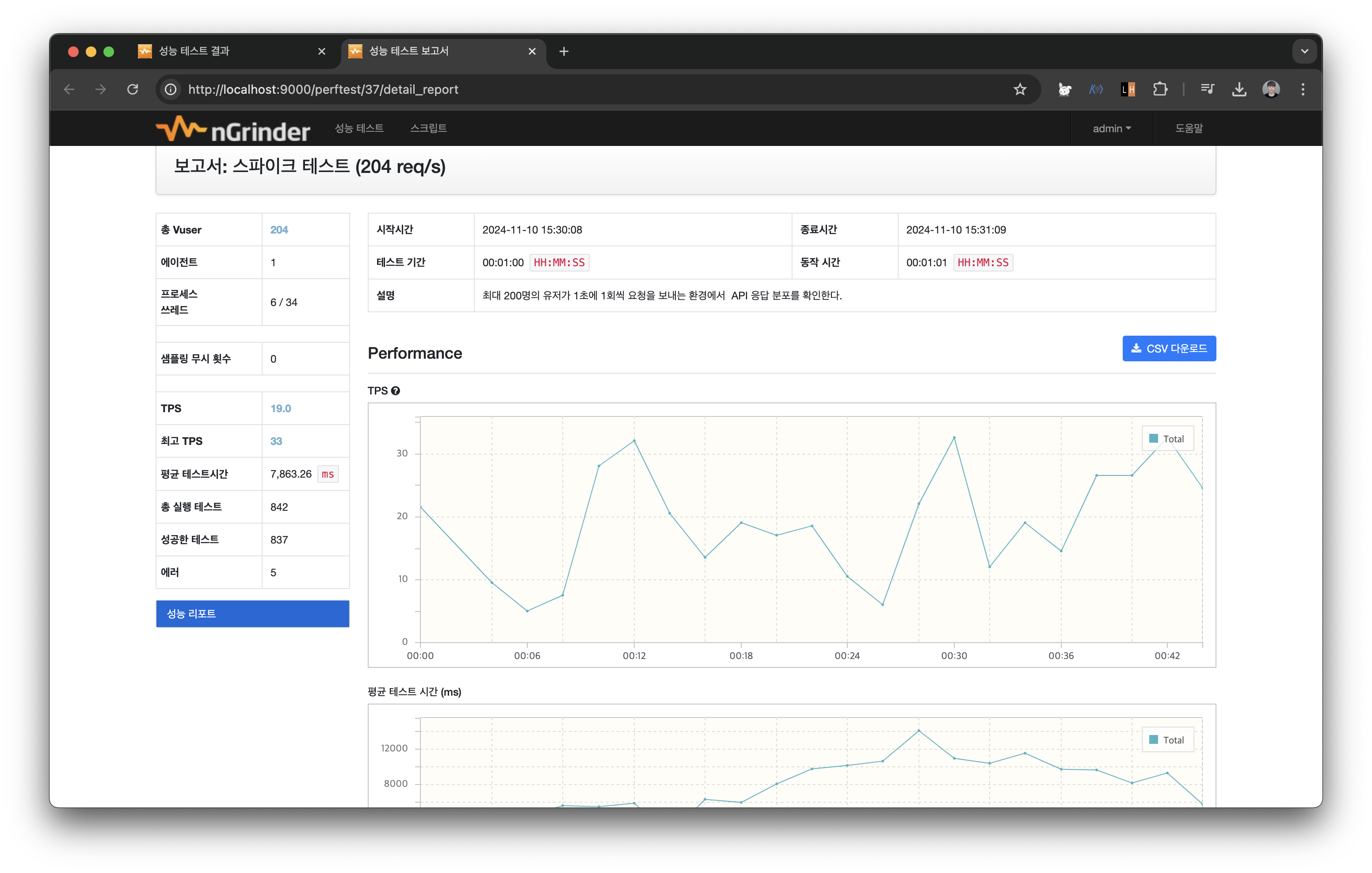
정확한 원인 분석 및 개선은 다음 글에서 이어나가보려고 한다.
브레이크 포인트 테스트
- 브레이크 포인트 테스트: 유저수를 늘리면서 API가 수용할 수 있는 처리량의 한계치를 확인한다.
(INF req/s)
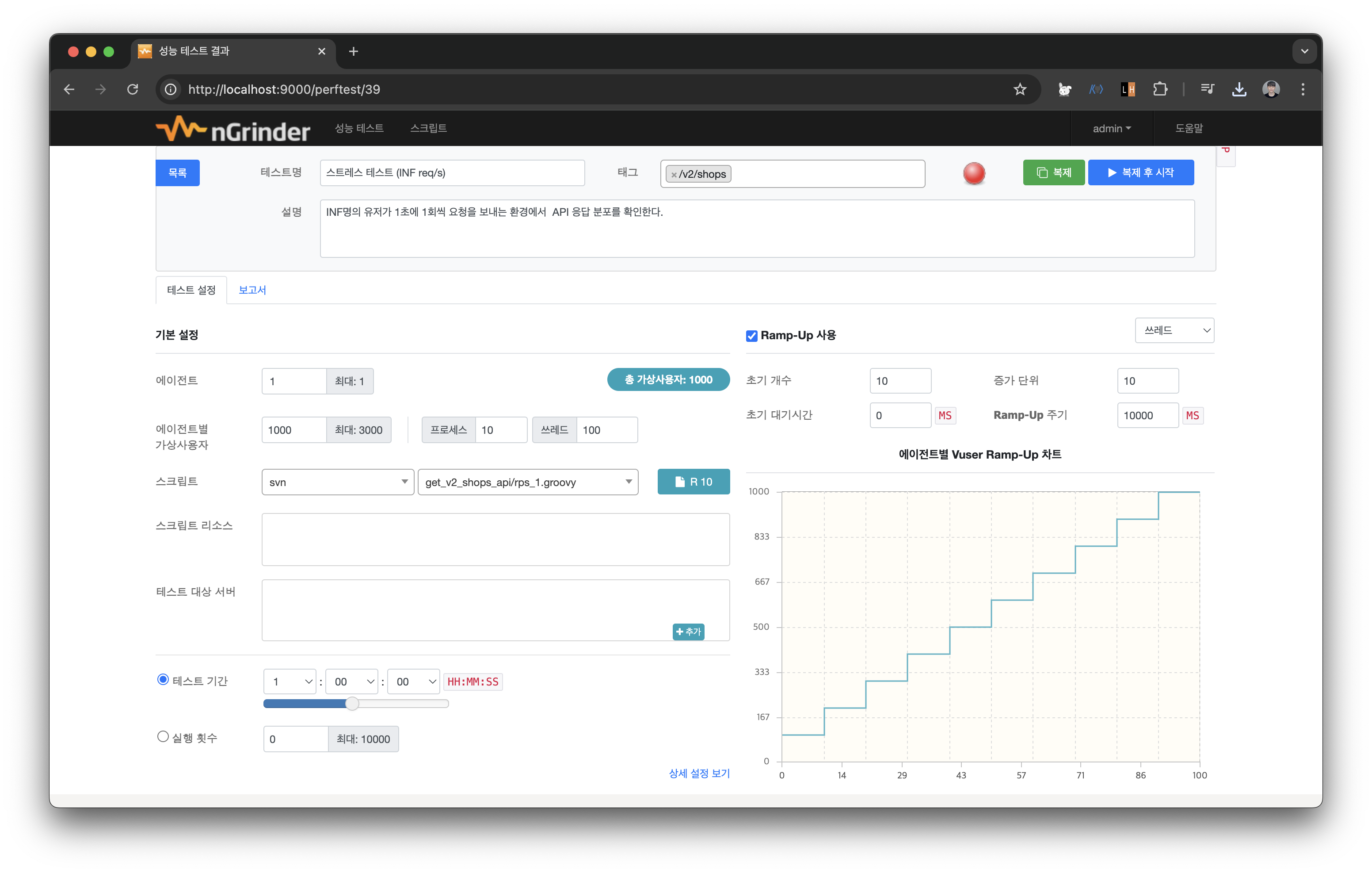
10초에 vUser를 10명씩 늘리면서 최대 1000명의 vUser까지 생성해본다.
아마 1000개의 vUser까지는 로컬 환경이 못버틸거같지만 위 스파이크 테스트에서 200명 정도의 vUser에서 오류가 발생했던걸 보면 1000명의 유저에 도달하기 전에 테스트가 종료되지 않을까 싶다.
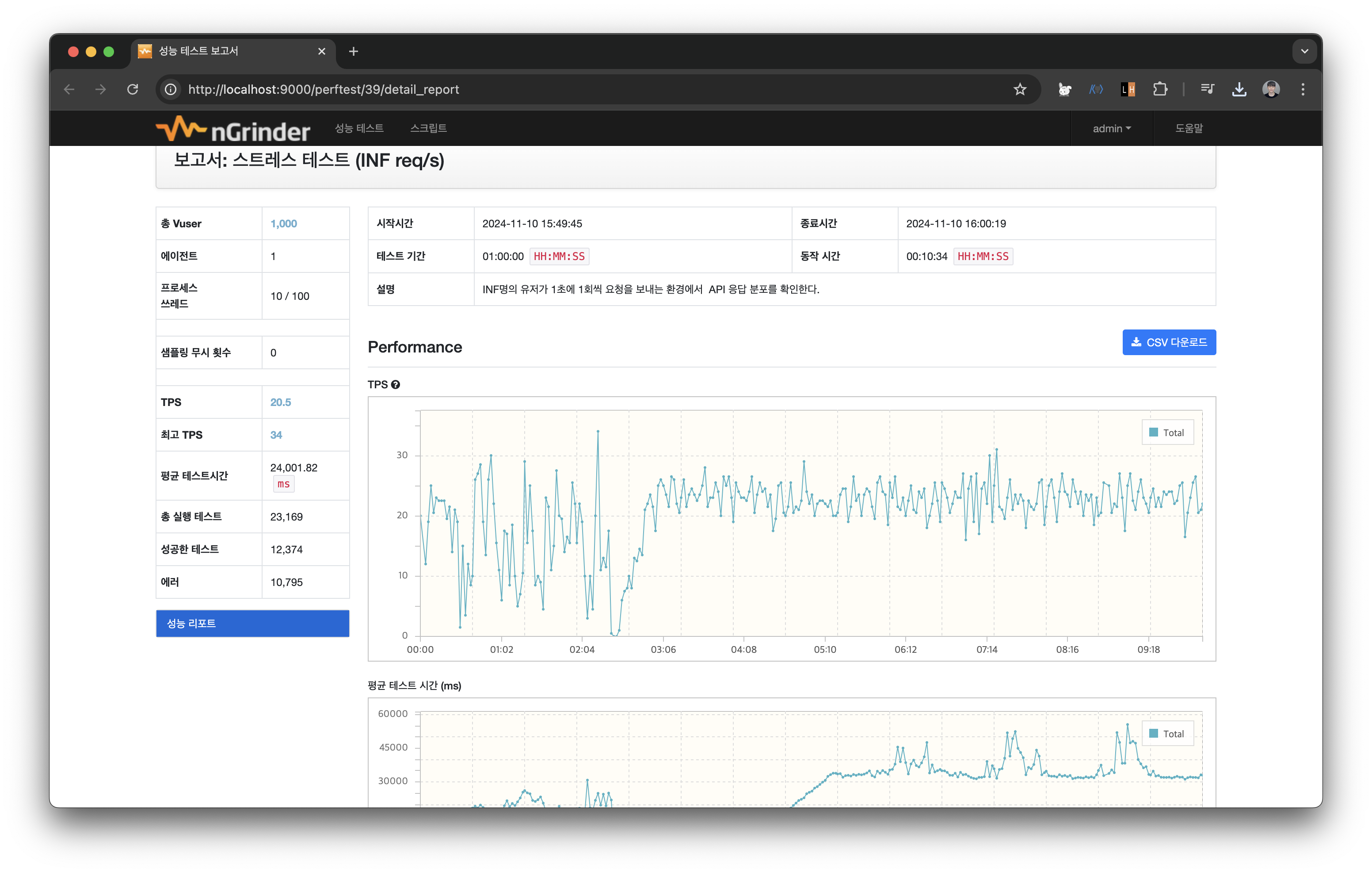
꽤 흥미로운 결과가 나왔다.
TPS가 위아래로 요동치고, 특정 지점에서는 TPS가 바닥을 찍는 모습을 보여줬다.
로컬에서 1000명의 유저를 생성하지 못해서 생기는 오류인가? 싶어 로그를 살펴봤다.
java.lang.AssertionError:
Expected: is <200>
got: <500>
at org.hamcrest.MatcherAssert.assertThat(MatcherAssert.java:21)
at TestRunner.test(rps_1.groovy:67)
at jdk.internal.reflect.GeneratedMethodAccessor107.invoke(Unknown Source)
at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at net.grinder.scriptengine.groovy.junit.GrinderRunner.run(GrinderRunner.java:164)
at net.grinder.scriptengine.groovy.GroovyScriptEngine$GroovyWorkerRunnable.run(GroovyScriptEngine.java:147)
at net.grinder.engine.process.GrinderThread.run(GrinderThread.java:118)서버로부터 500 에러를 응답받는 경우가 있었다.
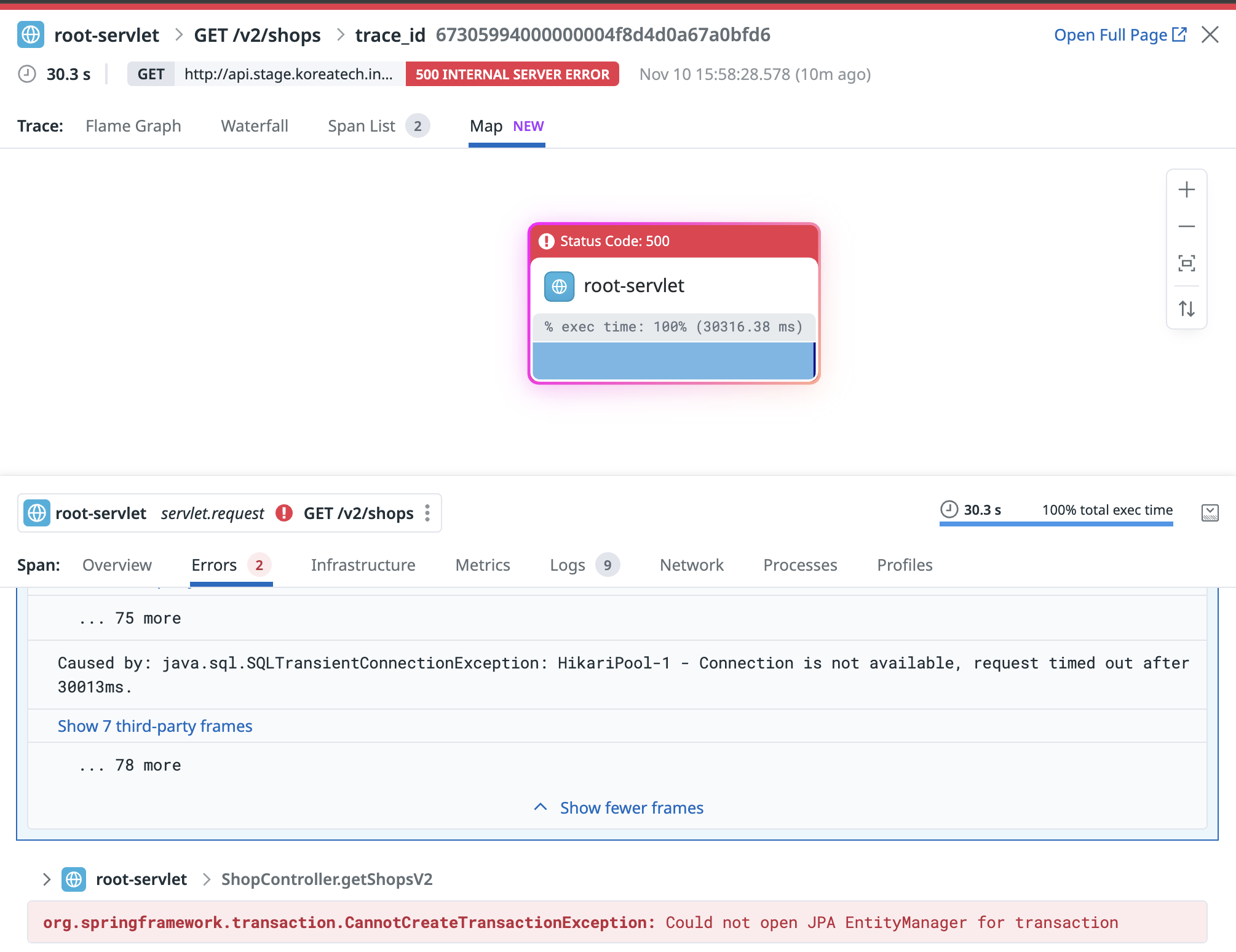
30초동안 Connection Pool을 획득하지 못해 timeOut으로 500이 반환되었다는 것을 확인할 수 있었다.
2024-11-10 07:00:19,307 ERROR java.util.concurrent.ExecutionException: org.apache.hc.core5.http.ConnectionClosedException: Connection is closed
org.apache.hc.core5.http.ConnectionClosedException: Connection is closed
at org.apache.hc.core5.http.nio.command.CommandSupport.cancelCommands(CommandSupport.java:76)
at org.apache.hc.core5.http2.impl.nio.ClientHttpProtocolNegotiator.disconnected(ClientHttpProtocolNegotiator.java:207)
at org.apache.hc.core5.reactor.ssl.SSLIOSession$1.disconnected(SSLIOSession.java:212)
at org.apache.hc.core5.reactor.InternalDataChannel.disconnected(InternalDataChannel.java:174)
at org.apache.hc.core5.reactor.SingleCoreIOReactor.processClosedSessions(SingleCoreIOReactor.java:229)
at org.apache.hc.core5.reactor.SingleCoreIOReactor.doExecute(SingleCoreIOReactor.java:134)
at org.apache.hc.core5.reactor.AbstractSingleCoreIOReactor.execute(AbstractSingleCoreIOReactor.java:85)
at org.apache.hc.core5.reactor.IOReactorWorker.run(IOReactorWorker.java:44)스파이크 테스트와 동일하게 맺을 수 있는 Https Connection의 개수를 초과해서 나는 에러로 추정되는 로그도 보인다.
브레이크 포인트 테스트 - 여유를 두고 다시 테스트
유저 수가 너무 빠르게 급등해서 생긴 문제일 수도 있겠다고 생각이 들어 Ramp Up Time을 20초로 늘려서 다시 테스트해봤다.
(20초에 10명씩 유저가 늘어나는 상황)
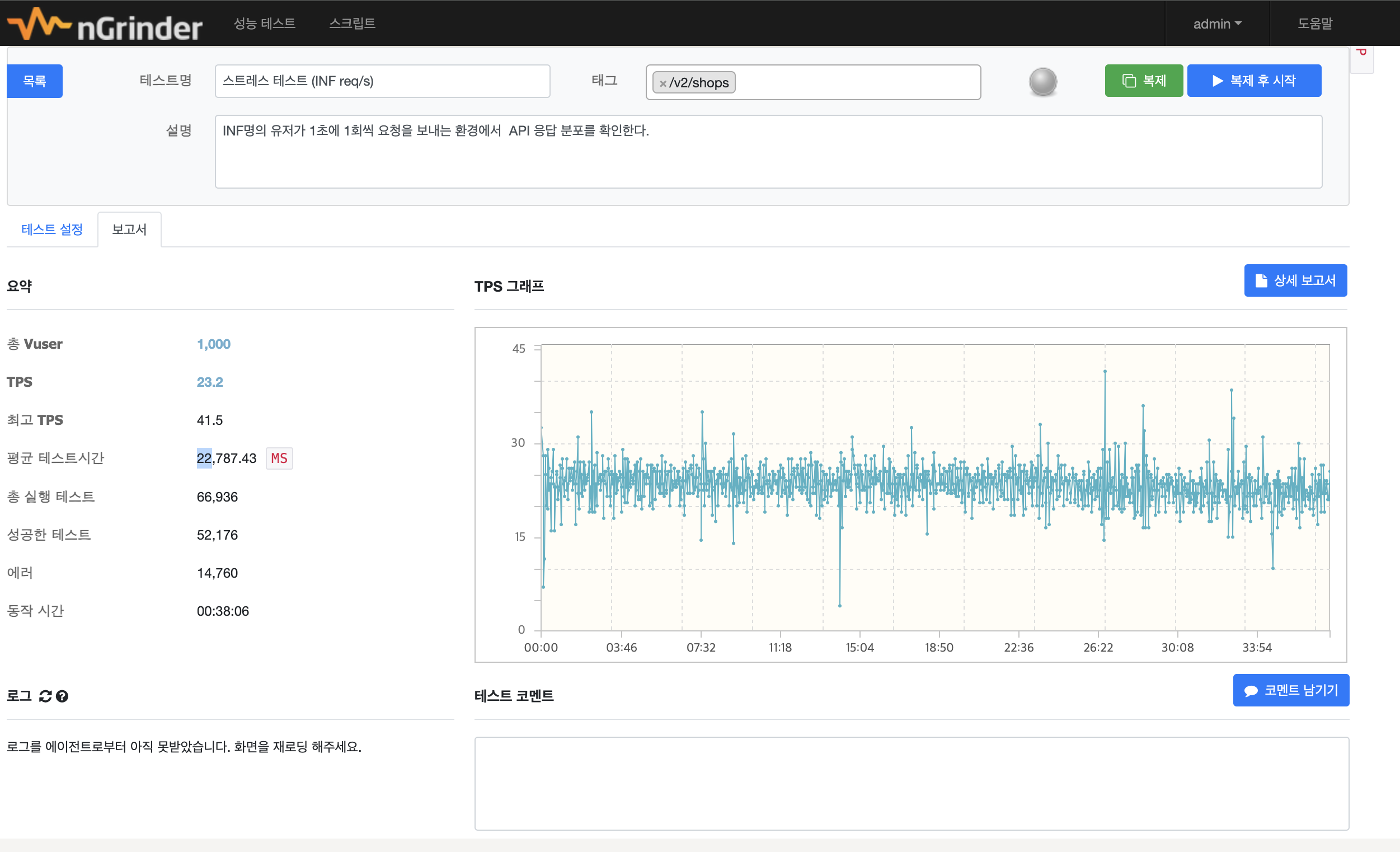
야금야금 테스트가 이어지긴하지만 평균 처리량이 20초를 넘어가서 무의미한 측정이라고 판단했다. 누가 20초나 기다리겠는가 ㅠㅠ
30분가량 테스트를 진행하고 테스트를 중지했다.
서버 & 맥북 에어: 으악!! 살려주세요 ㅠㅠ

정리
단건 하나의 요청을 보낼때는 77ms정도의 응답시간을 보여주던 API가 요청수가 많아진다고 레이턴시가 왕창 증가하는것을 보여주고있다.
이전에 우테코에서 피움 서비스를 가지고 테스트해봤던 과정을 되짚어보면 Tomcat의 Thread Pool과 DB의 Connection Pool의 상관관계를 분석하면서 원인을 찾아봤던 기억이 새록새록 생각난다.
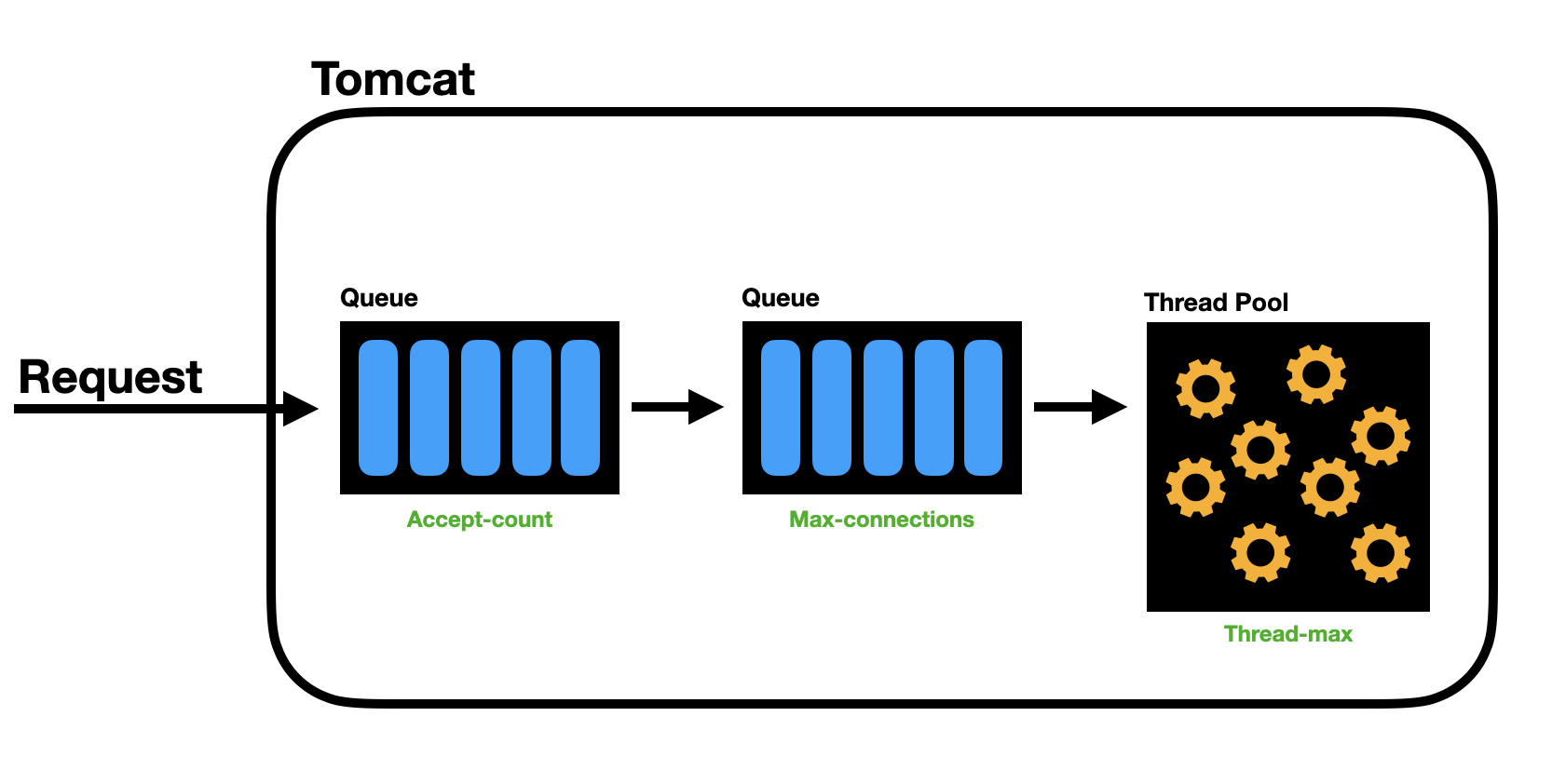
아마 8192개만큼의 max-connections Queue가 쌓이고 난 뒤부터 Connection이 Refuse되면서 오류가 팡팡 터지는게 아닐까 싶다.
그 사이에 Thread Pool에서는 야금야금 저 요청들을 처리하고있을거고, 30초가 Connection Timeout 시간인 30초가 지나지않는 이상 계속해서 야금야금.. 처리하는것으로 예상된다.
아무리 생각해도 저거 처리하겠다고 30초나 기다리는건 말이 안된다고 생각한다 😞
Tomcat Thread Pool이 default 200개인데 처리속도가 왤캐 느려? 라고 말할 수도 있다. 하지만 저 로직은 DB 연산을 요구하고 있기 때문에 DB의 Connection Pool을 보는게 적절할것 같다.
정확한 성능 측정을 하기 위해서는 성능테스트 도구와 기타 네트워크 대한 이해도 필요하다는 것을 알 수 있었다.
nGrinder에서 내부적으로 요청마다 커넥션을 다시 연결하는 옵션이 있다는것도 알았고, 서버에서 https 커넥션 요청을 받는 한계가 있다는 것도 알았다.
결론
평균 부하테스트, 스트레스 테스트를 통해 서비스가 운영되는데 충분히 문제 없음을 파악할 수 있었고, 스파이크 테스트를 통해 Https 커넥션의 개수 설정 문제가 있을 수 있음을 예상할 수 있었다.
또한 브레이크 포인트 테스트를 통해 처리량이 무지막지하게 증가함에 따라 레이턴시가 대폭 증가하는 것을 확인 할 수 있었다.
다음 시간에는 왜 이런 현상이 생기는거고, 어떻게 개선할 수 있을지 알아보려고한다.
예고편)
우리 서비스가 처리할 수 있는 최대 처리량과 적절한 타임아웃 시간을 찾아가보면서 최적의 설정을 갖춰보자.
Reference
