6.3.1 Caching in the Memory Hierarchy
In general, a cache (pronounced “cash”) is a small, fast storage device that acts as a staging area for the data objects stored in a larger, slower device. The process of using a cache is known as caching (pronounced “cashing”).
The central idea of a memory hierarchy is that for each k, the faster and smaller storage device at level k serves as a cache for the larger and slower storage device at level k + 1. In other words, each level in the hierarchy caches data objects from the next lower level. For example, the local disk serves as a cache for files (such as Web pages) retrieved from remote disks over the network, the main memory serves as a cache for data on the local disks, and so on, until we get to the smallest cache of all, the set of CPU registers.
일반론적으로, cache는 보다 크고 느린 디바이스에 저장된 데이터 객체를 위한 준비 영역으로 사용하는 작고 빠른 저장장치이다.
메모리 계층구조의 핵심은, 더 빠르고 더 작은 저장 장치 k 라는 녀석이 k+1레벨의 저장장치에게 캐시 서비스를 제공해준다는 것이다.
예를 들어서, 로컬 디스크는 원격 디스크인 네트워크에 대한 캐시이며, 메모리는 로컨 디스크에 대한 캐시입니다. 결과적으로 CPU에 대한 CPU register 캐시들이 있습니다!
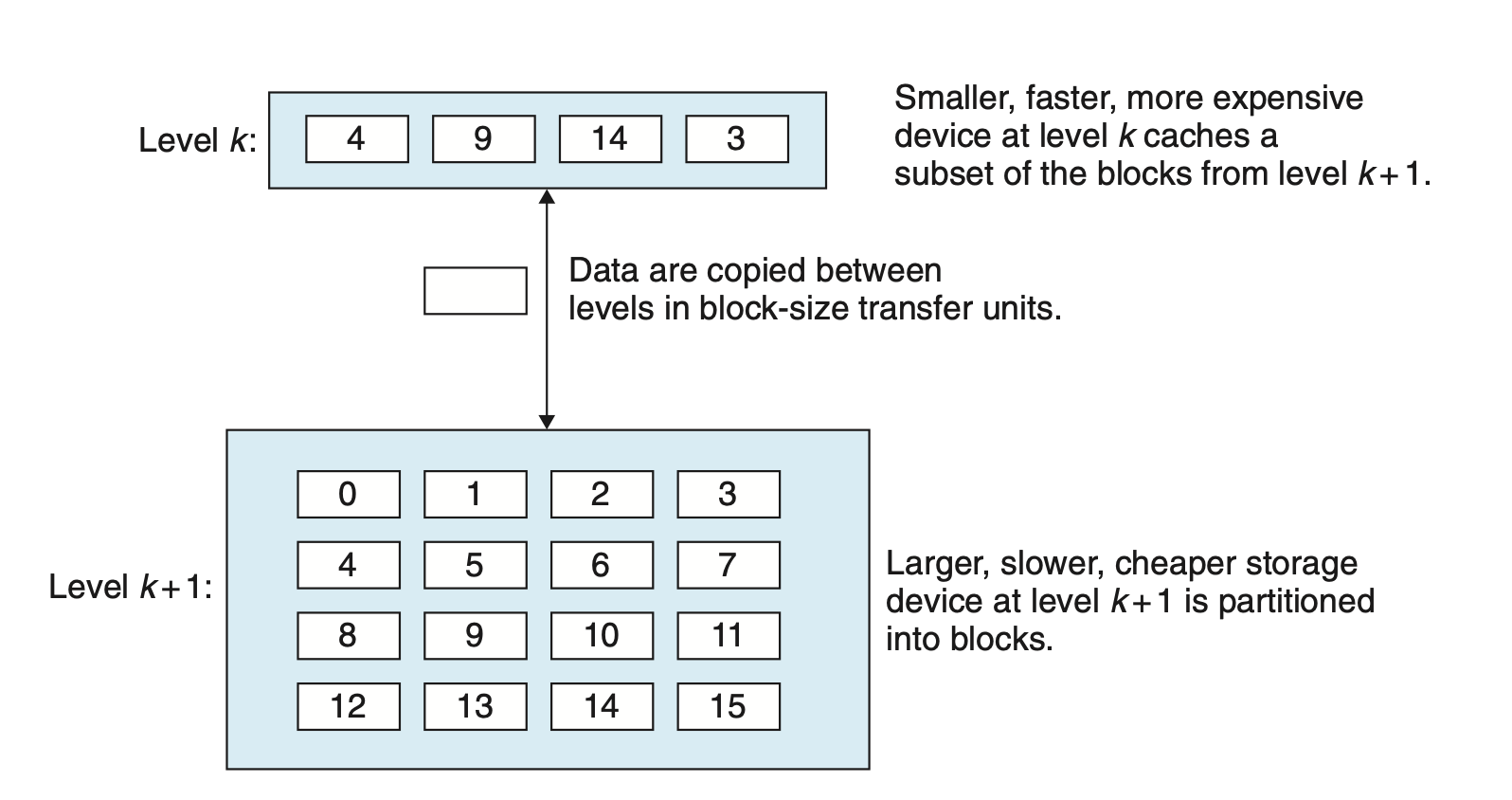
It shows the general concept of caching in a memory hierarchy. The storage at level k + 1 is partitioned into contiguous chunks of data objects called blocks. Each block has a unique address or name that distinguishes it from other blocks. Blocks can be either fixed size (the usual case) or variable size (e.g., the remote HTML files stored on Web servers). For example, the level k + 1 storage in Figure 6.22 is partitioned into 16 fixed-size blocks, numbered 0 to 15.
위 그림은 캐시 메모리의 일반적인 계층구조를 나타냅니다.
k+1 레벨에 데이터 블록들이 있습니다. 각각의 블록에는 다른 블록과 구별 가능한 고유한 '주소'나 '이름' 이 있습니다.
k+1 레벨에는 0~15, 즉 16개의 블록들이 있습니다.
Similarly, the storage at level k is partitioned into a smaller set of blocks that are the same size as the blocks at level k + 1. At any point in time, the cache at level k contains copies of a subset of the blocks from level k + 1. For example, in Figure 6.22, the cache at level k has room for four blocks and currently contains copies of blocks 4, 9, 14, and 3.
이와 비슷하게, k 레벨에는 k+1 레벨에 있는 동일한 사이즈의 블록들이 있지만, 더 적은 수의 블록을 갖고 있습니다.
어느 시점에서든지 , k 레벨에 있는 캐시는 k+1 레벨의 블록에 있는 카피된 데이터를 갖고 있습니다.
Data are always copied back and forth between level k and level k + 1 in block-size transfer units. It is important to realize that while the block size is fixed between any particular pair of adjacent levels in the hierarchy, other pairs of levels can have different block sizes.
데이터는 항상 k ~ k+1 레벨에서 블록사이즈 단위로 이동합니다. 인접 레벨들간의 블록 사이즈는 동일하지만, 다른 레벨의 캐시들은 다른 블록 사이들을 갖을 수 있습니다.
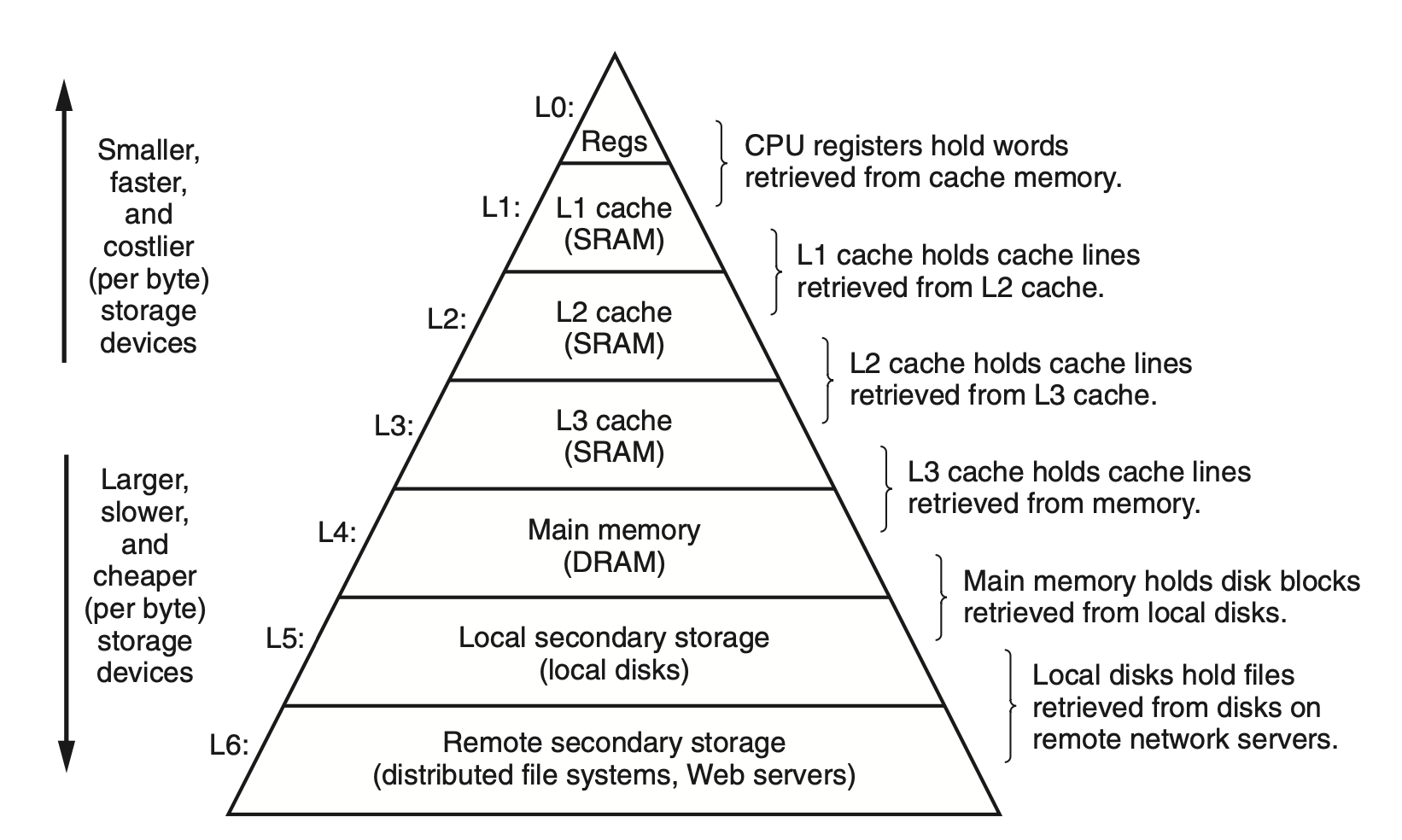
For example, in Figure 6.21, transfers between L1 and L0 typically use word-size blocks. Transfers between L2 and L1 (and L3 and L2, and L4 and L3) typically use blocks of tens of bytes. And transfers between L5 and L4 use blocks with hundreds or thousands of bytes. In general, devices lower in the hierarchy (further from the CPU) have longer access times, and thus tend to use larger block sizes in order to amortize these longer access times.
예를 들어, L1~L0 간의 데이터 이동에는 일반족으로 word-size 블록이 사용됩니다.
(L1~L2), (L2~L3), (L3~L4) 의 블록들은 수십개의 바이트들을이 옮겨집니다.
(L4~L5) (Main Memory <---> Local Disks ) 는 수백 수천의 바이트들이 옮겨집니다.
일반론적으로, (CPU에서 멀리 떨어진) 계층에서 낮은 장치는 액세스 시간이 더 길기 때문에 이러한 더 긴 액세스 시간을 상각(부동산 용어)하기 위해 더 큰 블록 크기를 사용하는 경향이 있습니다.
In general, the storage devices get slower, cheaper, and larger as we move from higher to lower levels. At the highest level (L0) are a small number of fast CPU registers that the CPU can access in a single clock cycle. Next are one or more small to moderate-size SRAM-based cache memories that can be accessed in a few CPU clock cycles.
일반론적으로, 메모리 구조에서 아래로 갈수록 더 느리고, 값은 싸지며, 크기는 커집니다. 가장 높은 레벨(L0)에는 CPU가 한 clock 사이클만에 도달할 수 있는 빠른 레지스터들이 존재합니다. 다음에는 몇 개의 CPU 클럭 사이클로 액세스할 수 있는 하나 이상의 소형 내지 중간 크기의 SRAM 기반 캐시 메모리입니다.
These are followed by a large DRAM-based main memory that can be accessed in tens to hundreds of clock cycles. Next are slow but enormous local disks. Finally, some systems even include an additional level of disks on remote servers that can be accessed over a network.
그 후로는 큰 수십~수백 사이클 클록안에 접근할 수 있는 DRAM-베이스의 Main Memory가 있습니다. 그 이후로는 느리지만 거대한 로컬 디스크가 있으며, 마지막으로 네트워크로 접근 가능한 원격 서버들이 있습니다.
For example, distributed file systems such as the Andrew File System (AFS) or the Network File System (NFS) allow a program to access files that are stored on remote network-connected servers. Similarly, the World Wide Web allows programs to access remote files stored on Web servers anywhere in the world.
분산 파일 시스템인 Andrew File System(AFS) 혹은,
네트워크 파일 시스템인 Network File System(NFS)가 원격으로 연결된 서버에 있는 파일들을 접근할 수 있게 해줍니다.
Cache Hits
When a program needs a particular data object d from level k + 1, it first looks for d in one of the blocks currently stored at level k. If d happens to be cached at level k, then we have what is called a cache hit. The program reads d directly from level k, which by the nature of the memory hierarchy is faster than reading d from level k + 1. For example, a program with good temporal locality might read a data object from block 14, resulting in a cache hit from level k.
프로그램이 d 라는 특정한 데이터를 k+1레벨에서 요구한다면, 프로그램은 k 레벨에 있는 블록들을 찾아봅니다. 만약 k 레벨에 캐시가 되어있다면, d 는 k에 cache hit 됐다고 표현합니다.
프로그램은 k에서 d를 직접적으로 읽습니다.
Cache Misses
If, on the other hand, the data object d is not cached at level k, then we have what is called a cache miss. When there is a miss, the cache at level k fetches the block containing d from the cache at level k + 1, possibly overwriting an existing block if the level k cache is already full.
데이터 d 가 레벨 k에서 캐시되지 않았다면, 우리는 이것을 cache miss 라고 부릅니다. cache miss가 일어나면, 캐시레벨 k 에서 k+1로 data를 fetch 합니다. 만약 k의 cache가 가득 찼다면 overwriting을 하야겠지요?
This process of overwriting an existing block is known as replacing or evicting the block. The block that is evicted is sometimes referred to as a victim block. The decision about which block to replace is governed by the cache’s replacement policy. For example, a cache with a random replacement policy would choose a random victim block. A cache with a least recently used (LRU) replacement policy would choose the block that was last accessed the furthest in the past.
이미 데이터가 있는 블록을 overwriting하는 것을 replacing 혹은 evicting 한다고 합니다. evicted 된 block을 victim block 이라고도 한답니다.
예를 들어, 랜덤 교체 정책은 랜덤하게 victim block을 정합니다. Least Recently Used 정책은 최근에 가장 적은 빈도로 사용된 블록을 제거합니다.
Kinds of Cache Misses
It is sometimes helpful to distinguish between different kinds of cache misses. If the cache at level k is empty, then any access of any data object will miss. An empty cache is sometimes referred to as a cold cache, and misses of this kind are called compulsory misses or cold misses. Cold misses are important because they are often transient events that might not occur in steady state, after the cache has been warmed up by repeated memory accesses.
만약 k 레벨의 캐시가 비어 있다면, 어떤 데이터 접근도 cache miss가 날 것 입니다. 빈 cache는 cold cache 라고 불리며
이러한 종류의 miss 는 compulsory misses 혹은 cold misses라 불립니다.
cold cache는 캐시가 반복적인 메모리 액세스로 예열된 후(즉, 캐시에 데이터가 있는 상황) 정상 상태에서는 발생할 수 없는 일시적인 이벤트이기 때문에 중요합니다.
Whenever there is a miss, the cache at level k must implement some placement policy that determines where to place the block it has retrieved from level k + 1. The most flexible placement policy is to allow any block from level k + 1 to be stored in any block at level k. For caches high in the memory hierarchy (close to the CPU) that are implemented in hardware and where speed is at a premium, this policy is usually too expensive to implement because randomly placed blocks are expensive to locate.
cache miss가 있을 때마다 레벨 k의 캐시는 레벨 k + 1에서 검색한 블록을 배치할 위치를 결정하는 배치 정책을 구현해야 합니다.
가장 유연한 배치 정책은 레벨 k + 1의 모든 블록을 레벨 k의 모든 블록에 저장할 수 있도록 하는 것입니다. 하드웨어로 구현되고 속도가 매우 빠른 메모리 계층 구조가 높은 캐시의 경우 무작위로 배치된 블록을 찾는 데 비용이 많이 들기 때문에 이 정책을 구현하기에는 일반적으로 비용이 너무 많이 듭니다.
Restrictive placement policies of this kind lead to a type of miss known as a conflict miss, in which the cache is large enough to hold the referenced data objects, but because they map to the same cache block, the cache keeps missing. For example, in Figure 6.22, if the program requests block 0, then block 8, then block 0, then block 8, and so on, each of the references to these two blocks would miss in the cache at level k, even though this cache can hold a total of four blocks.
이런 종류의 제한적인 배치 정책은 충돌 미스(conflict miss)라고 알려진 유형의 미스로 이어지는데, 이 미스는 캐시가 참조된 데이터 객체를 보유할 만큼 충분히 크지만 동일한 캐시 블록에 매핑되기 때문에 캐시가 계속 누락됩니다.
예를 들어 그림 6.22에서 프로그램이 블록 0을 요청하고, 블록 8를 요청하고, 0,8 등을 연속적으로 요청하면 이 캐시가 총 4개의 블록을 보유할 수 있음에도 불구하고 이 두 블록에 대한 각 참조가 k 수준의 캐시에서 누락됩니다.
Programs often run as a sequence of phases (e.g., loops) where each phase accesses some reasonably constant set of cache blocks. For example, a nested loop might access the elements of the same array over and over again. This set of blocks is called the working set of the phase. When the size of the working set exceeds the size of the cache, the cache will experience what are known as capacity misses. In other words, the cache is just too small to handle this particular working set.
프로그램은 종종 각 단계가 일정한 캐시 블록 세트에 액세스하는 단계(루프)의 시퀀스로 실행됩니다. 예를 들어, 중첩된 루프는 동일한 어레이의 요소에 계속해서 액세스할 수 있습니다. 이 블록 세트는 Working set 라고 불립니다. Working set의 크기가 캐시의 크기를 초과하면, 캐시는 용량 누락으로 알려진 것을 경험할 것입니다. 다시 말해서, 캐시는 이 특정 작업 세트를 처리하기에는 너무 작습니다.
Cache Management
As we have noted, the essence of the memory hierarchy is that the storage device at each level is a cache for the next lower level. At each level, some form of logic must manage the cache. By this we mean that something has to partition the cache storage into blocks, transfer blocks between different levels, decide when there are hits and misses, and then deal with them. The logic that manages the cache can be hardware, software, or a combination of the two.
앞서 언급했듯이 메모리 계층 구조의 본질은 각 레벨의 스토리지 장치가 다음 하위 레벨을 위한 캐시라는 것입니다. 각 레벨에서 어떠한 로직이 캐시를 관리해야 합니다. 이는 캐시 스토리지를 블록으로 분할하고, 여러 레벨 사이에 블록을 전송하고, 히트와 미스가 있을 때를 결정한 다음 이를 처리해야 한다는 것을 의미합니다. 캐시를 관리하는 논리는 하드웨어, 소프트웨어 또는 이 둘의 조합일 수 있습니다.
For example, the compiler manages the register file, the highest level of the cache hierarchy. It decides when to issue loads when there are misses, and determines which register to store the data in. The caches at levels L1, L2, and L3 are managed entirely by hardware logic built into the caches.
예를 들어 컴파일러는 캐시 계층 구조의 최상위 계층인 레지스터 파일을 관리합니다. 누락된 부분이 있을 때 로드를 발행할 시기를 결정하고 데이터를 저장할 레지스터를 결정합니다. L1, L2, L3 수준의 캐시는 캐시에 내장된 하드웨어 로직에 의해 전적으로 관리됩니다.
In a system with virtual memory, the DRAM main memory serves as a cache for data blocks stored on disk, and is managed by a combination of operating system software and address translation hardware on the CPU. For a machine with a distributed file system such as AFS, the local disk serves as a cache that is managed by the AFS client process running on the local machine. In most cases, caches operate automatically and do not require any specific or explicit actions from the program.
가상 메모리가 있는 시스템에서 DRAM 메인 메모리는 디스크에 저장된 데이터 블록의 캐시 역할을 하며 CPU의 운영 체제 소프트웨어와 주소 변환 하드웨어의 조합에 의해 관리됩니다. AFS와 같은 분산 파일 시스템이 있는 시스템의 경우 로컬 디스크는 로컬 시스템에서 실행되는 AFS 클라이언트 프로세스에 의해 관리되는 캐시 역할을 합니다. 대부분의 경우 캐시는 자동으로 작동하며 프로그램의 특정 작업이나 명시적인 작업을 필요로 하지 않습니다.

6.3.2 Summary of Memory Hierarchy Concepts
To summarize, memory hierarchies based on caching work because slower storage is cheaper than faster storage and because programs tend to exhibit locality:
Exploiting temporal locality.
Because of temporal locality,the same data objects are likely to be reused multiple times. Once a data object has been copied into the cache on the first miss, we can expect a number of subsequent hits on that object. Since the cache is faster than the storage at the next lower level, these subsequent hits can be served much faster than the original miss.
시간 지역성 때문에, 동일한 데이터 객체들은 여러 번 재사용될 가능성이 높습니다. 첫 번째 cache miss에서 데이터 객체가 캐시에 복사되면, 우리는 그 객체에 대한 다수의 후속 히트들을 기대할 수 있습니다. 캐시가 다음 하위 레벨의 스토리지보다 빠르기 때문에, 이러한 후속 히트들은 원래 미스보다 훨씬 더 빠르게 서비스될 수 있습니다.
Exploiting spatial locality.
Blocks usually contain multiple data objects. Because of spatial locality, we can expect that the cost of copying a block after a miss will be amortized by subsequent references to other objects within that block.
블록은 일반적으로 여러 개의 데이터 객체를 포함합니다. 공간 지역성 때문에 누락된 후 블록을 복사하는 비용은 해당 블록 내의 다른 객체를 참조하여 상각(부동산 용어)될 것으로 예상할 수 있습니다.
