9.3 VM as a Tool for Caching
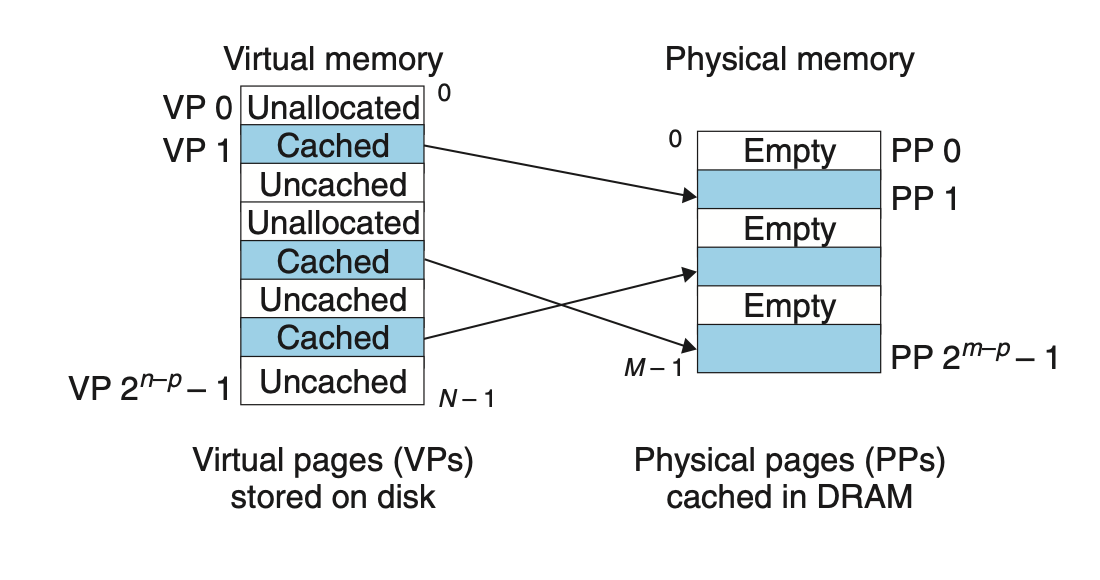
Conceptually, a virtual memory is organized as an array of N contiguous byte-size cells stored on disk. Each byte has a unique virtual address that serves as an index into the array. The contents of the array on disk are cached in main memory.
개념적으로, 가상 메모리는 디스크에 저장된 N개의 바이트 크기의 셀 배열로 구성된다. 각각의 바이트는 고유한 가상 주소를 가지며, 배열의 인덱스로 작용한다. 디스크 안의 배열 정보는 메인 메모리에 캐시된다.
As with any other cache in the memory hierarchy, the data on disk (the lower level) is partitioned into blocks that serve as the transfer units between the disk and the main memory (the upper level).
여타 다른 캐시들 처럼, 메모리 계층구조 안에 있는 캐시는 블록 단위로 분할이 되며, 디스크와 메인 메모리 사이에 징검다리 역할을 한다.
VM systems handle this by partitioning the virtual memory into fixed-size blocks called virtual pages
가상 메모리 시스템은 'Virtual pages' 라는 고정된 가상 블록으로 나누는 것으로 가상 메모리를 관리한다.
- Unallocated
Pages that have not yet been allocated (or created) by the VM system. Unallocated blocks do not have any data associated with them, and thus do not occupy any space on disk. - Cached
Allocated pages that are currently cached in physical memory. - Uncached.
Allocated pages that are not cached in physical memory.
- Unallocated
아직 가상 메모리 시스템에 의해 할당되지 않은 페이지. 할당되지 않은 블록들은 데이터를 갖고 있지 않으며 공간 또한 차지하지 않는다.- Cached
물리 메모리에 캐시되어 할당된 페이지들- Uncahed
물리 메모리에 캐시되는 않았지만, VM에는 할당된 페이지.
9.3.1 DRAM Cache Organization
To help us keep the different caches in the memory hierarchy straight, we will use the term SRAM cache to denote the L1, L2, and L3 cache memories between the CPU and main memory, and the term DRAM cache to denote the VM system’s cache that caches virtual pages in main memory.
SRAM : L1, L2, L3 는 CPU와 MM의 캐시메모리를 칭하고
DRAM : 가상 페이지를 메인 메모리로 캐싱하응 VM 시스템 캐시를 칭할 것 입니다.
The position of the DRAM cache in the memory hierarchy has a big impact on the way that it is organized. Recall that a DRAM is at least 10 times slower than an SRAM and that disk is about 100,000 times slower than a DRAM. Thus, misses in DRAM caches are very expensive compared to misses in SRAM caches because DRAM cache misses are served from disk, while SRAM cache misses are usually served from DRAM-based main memory. Further, the cost of reading the first byte from a disk sector is about 100,000 times slower than reading successive bytes in the sector. The bottom line is that the organization of the DRAM cache is driven entirely by the enormous cost of misses.
DRAM은 최소 SRAM 보다 10배는 느리고, 디스크는 DRAM보다 약 100,000 배 느리다. 따라서 DRAM의 캐시 미스는 SRAM 캐시 미스에 비해서 그 값이 매우 비싸다. 그 이유로는 DRAML 캐시 미스는 디스크에서 처리되지만, SRAM 캐시 미스는 DRAM 기반 메인 메모리로부터 지원받기 때문이다.
9.3.2 Page Tables
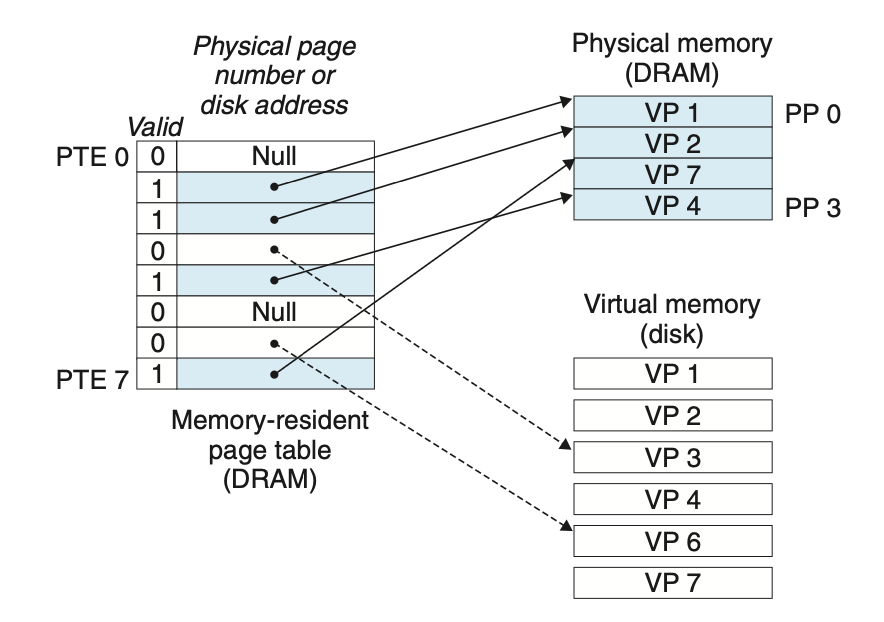
As with any cache, the VM system must have some way to determine if a virtual page is cached somewhere in DRAM. If so, the system must determine which physical page it is cached in. If there is a miss, the system must determine where the virtual page is stored on disk, select a victim page in physical memory, and copy the virtual page from disk to DRAM, replacing the victim page.
어떠한 경우에서라도, VM System은 가상 페이지가 DRAM에 캐싱됐는지 판단할 수 있어야 합니다.
만약 캐시가 됐다면, 어떤 물리적 페이지를 캐싱 했는지도 알아야 합니다.
만약 캐시가 되지 않았다면, 가상 페이지가 디스크의 어떤 곳에 있는지 알아야 하며, 대체할 '희생자 페이지를' 물리 메모리에서 선택한 뒤, 가상 페이지를 디스크에서 DRAM으로 카피해야 합니다.
These capabilities are provided by a combination of operating system software, address translation hardware in the MMU (memory management unit), and a data structure stored in physical memory known as a page table that maps virtual pages to physical pages.
이러한 능력은 운영체제와 MMU칩 내의 주소 번역 하드웨어, 그리고 가상 페이지를 물리적 페이지로 매핑하는 페이지 테이블(물리 메모리에 저장된 자료 구조)에 의해 제공된다.
The address translation hardware reads the page table each time it converts a virtual address to a physical address. The operating system is responsible for maintaining the contents of the page table and transferring pages back and forth between disk and DRAM.
주소 번역기 하드웨어는 가상 주소를 물리주소로 번역할 때 마다 페이지 테이블을 읽는다. 운영체제는 페이지 테이블의 콘텐츠 관리와 페이지들을 디스크와 DRAM 사이에서 왔다 갔다 하는 것을 관장한다.
9.3.3 Page Hits
Consider what happens when the CPU reads a word of virtual memory contained in VP 2, which is cached in DRAM (Figure 9.5). Using a technique we will describe in detail in Section 9.6, the address translation hardware uses the virtual address as an index to locate PTE 2 and read it from memory. Since the valid bit is set, the address translation hardware knows that VP 2 is cached in memory. So it uses the physical memory address in the PTE (which points to the start of the cached page in PP 1) to construct the physical address of the word.
DRAM에 캐시된 VP2를 CPU가 가상 메모리로부터 읽는 상황을 생각해보자. 주소 번역 하드웨어 (MMU)는 가상 주소를 사용해서 메모리로부터 읽어옵니다.
9.3.4 Page Faults
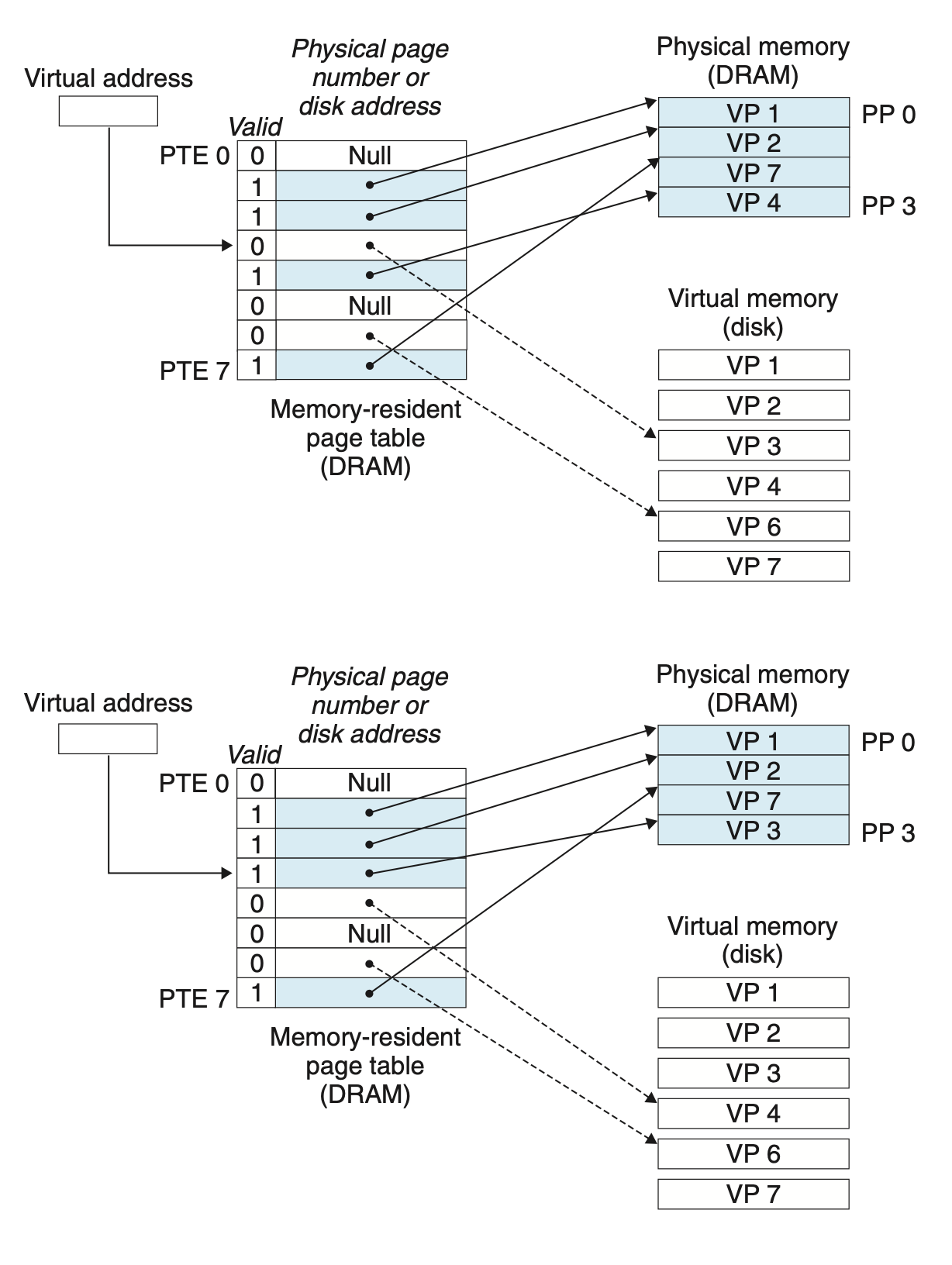
In virtual memory parlance, a DRAM cache miss is known as a page fault. Figure 9.6 shows the state of our example page table before the fault. The CPU has referenced a word in VP 3, which is not cached in DRAM. The address translation hardware reads PTE 3 from memory, infers from the valid bit that VP 3 is not cached, and triggers a page fault exception. The page fault exception invokes a page fault exception handler in the kernel, which selects a victim page—in this case, VP 4 stored in PP 3. If VP 4 has been modified, then the kernel copies it back to disk. In either case, the kernel modifies the page table entry for VP 4 to reflect the fact that VP 4 is no longer cached in main memory.
가상메모리의 어조로 풀자면, DRAM 캐시 미스는 페이지 폴트 라고 알려져 있습니다. CPU가 DRAM에 캐시되지 않은 VP3의 워드를 참조하고있습니다. 주소 번역 하드웨어 (MMU)는 메모리로부터 PTE3를 읽습니다. 그런데 이것은 캐시되지 않아서 페이지 폴트 Exception이 일어납니다.
페이지 폴트 익셉션은 커널에 있는 익셉션 핸들러를 인보크 시키고, 희생자 페이지를 찾습니다. 이후 페이지 변경된 테이블을 갱신합니다!
9.3.5 Allocating Pages
Figure 9.8 shows the effect on our example page table when the operating system allocates a new page of virtual memory for example, as a result of calling malloc. In the example, VP 5 is allocated by creating room on disk and updating PTE 5 to point to the newly created page on disk.
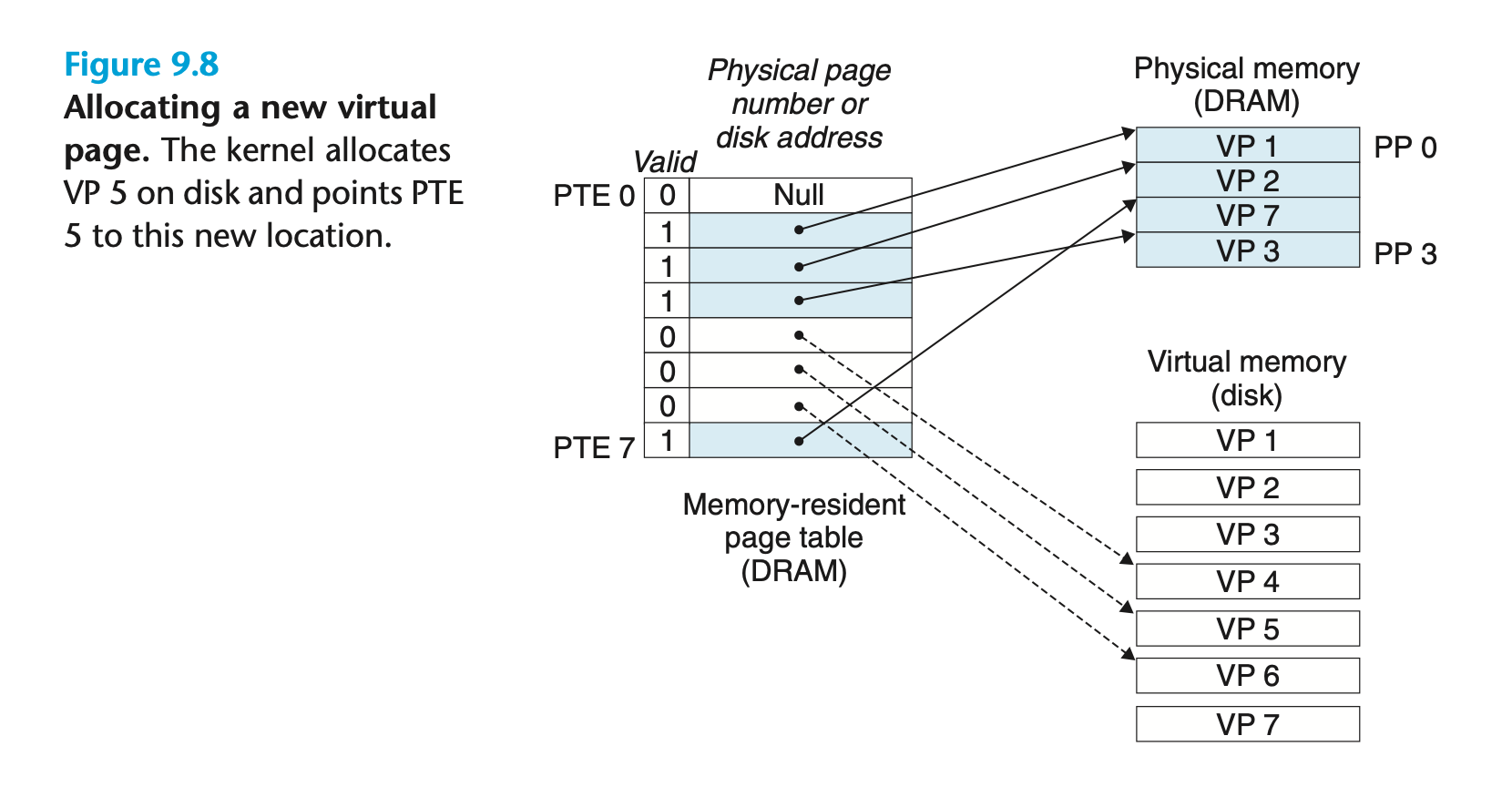
위의 그림은 malloc의 결과로 디스크에 VP5가 할당이 된 상황입니다. 그리고 PTE 5가 이를 가르키고 있습니다.
When many of us learn about the idea of virtual memory, our first impression is often that it must be terribly inefficient. Given the large miss penalties, we worry that paging will destroy program performance. In practice, virtual memory works well, mainly because of our old friend locality.
가상메모리를 처음 접하면, 진짜 비효율적인 것 처럼 보인다. 하지만 실제로 가상 메모리는 우리의 오랜 친구인 '지역성' 덕분에 아주 잘 동작한답니다!
Although the total number of distinct pages that programs reference during an entire run might exceed the total size of physical memory, the principle of locality promises that at any point in time they will tend to work on a smaller set of active pages known as the working set or resident set. After an initial overhead where the working set is paged into memory, subsequent references to the working set result in hits, with no additional disk traffic.
비록, 프로그램이 실행하는 동안 참조하는 서로 다른 페이지의 수가 전체 물리메모리의 크기보다 더 클지라도, '지역성의 원리'는 어느 시간상에서도 이들이 working set 이라는 국소적인 페이지에서 동작하는 경향을 보장해줍니다.
즉, 쓴 놈들을 주로 쓴다! 라는 뜻 입니다.
As long as our programs have good temporal locality, virtual memory systems work quite well. But of course, not all programs exhibit good temporal locality. If the working set size exceeds the size of physical memory, then the program can produce an unfortunate situation known as thrashing, where pages are swapped in and out continuously. Although virtual memory is usually efficient, if a program’s performance slows to a crawl, the wise programmer will consider the possibility that it is thrashing.
그러나, working set 사이즈기 물리 메모리를 초과하면, Thrashing 이라는 상황을 초래하게 만들고 페이지 스왑이 빈번하게 일어나서 버버버벅 거리는 상황이 초래됩니다!
