1. Web scraping
웹 상에 존재하는 데이터를 직접 수집하는 방법
1) 정적 웹 스크래핑
* Requests 패키지 사용
-web 상 url을 사용해서 python에 불러오는 역할
import requests
req = requests.get('url')
html = req.text*BeautifulSoup 패키지 사용
-불러온 html을 parsing하는 패키지
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
-html 내 필요한 정보들을 불러올 수 있음
soup.find('a', attrs = {'class':'element1", "info":"element2"})
soup.find_all('a', attrs = {'class':'element1", "info":"element2"})*예시1) 네이버 웹툰 제목 평점 장르 크롤링
라이브러리 불러오기
import requests
from bs4 import BeautifulSoup
import timeRequsets, BeautifulSoup
url = 'https://comic.naver.com/webtoon/weekdayList?week=mon'
html = requests.get(url).text
soup = BeautifulSoup(html, 'html.parser')페이지 정보 추출하기
url_tag_list = list(map(lambda x: x.find('a'), soup.find_all('dt')))태그에서 title, href 추출하기
title_list = []
href_list = []
for url_tag in url_tag_list:
title = url_tag.get('title')
href = url_tag.get('href')
if title:
title_list.append(title)
if href:
href_list.append(href)
href_list = href_list[3:]
평점 추출하기
url_rating_list = list(map(lambda x: x.find('strong'),soup.find_all('div', 'rating_type')))
rating_list = []
for url_rating in url_rating_list:
rating = float(url_rating.get_text())
rating_list.append(rating)
장르, 좋아요 추출하기기
for url in href_list:
new_url = 'https://comic.naver.com' + url
req = requests.get(new_url)
html = req.text
new_soup = BeautifulSoup(html, 'html.parser')
story, genre = new_soup.find('span', 'genre').text.split(', ')[0], new_soup.find('span', 'genre').text.split(', ')[1]전체 요일별 추출하기
comic_rating_list = []
url_list = []
for day in ['mon', 'tue', 'wed', 'thu', 'fri', 'sat', 'sun']:
url_list.append('https://comic.naver.com/webtoon/weekdayList?week=' + day)
for url in url_list:
req = requests.get(url)
html = req.text
soup = BeautifulSoup(html, 'html.parser')
url_tag_list = list(map(lambda x: x.find('a'), soup.find_all('dt')))
title_list = []
href_list = []
for url_tag in url_tag_list:
title = url_tag.get('title')
href = url_tag.get('href')
if title:
title_list.append(title)
if href:
href_list.append(href)
href_list = href_list[3:]
url_rating_list = list(map(lambda x: x.find('strong'),soup.find_all('div', 'rating_type')))
rating_list = []
for url_rating in url_rating_list:
rating = float(url_rating.get_text())
rating_list.append(rating)
story_list = []
genre_list = []
for url in href_list:
new_url = 'https://comic.naver.com' + url
req = requests.get(new_url)
html = req.text
new_soup = BeautifulSoup(html, 'html.parser')
story, genre = new_soup.find('span', 'genre').text.split(', ')[0], new_soup.find('span', 'genre').text.split(', ')[1]
story_list.append(story)
genre_list.append(genre)
webtoon_list = []
for i in range(len(rating_list)):
webtoon_list.append([title_list[i], rating_list[i], story_list[i], genre_list[i]])
comic_rating_list.append(webtoon_list)2) 동적 웹 스크래핑
정적인 페이지 하나에서의 정보 이상의 정보가 필요할 때 사용한다.
로그인이 필요할 때, 커서의 이동이 필요하고 페이지가 수시로 변하면서 데이터를 수집할 때는 정적인 페이지 하나를 사용하는 requests 패키지로는 불가하다.
* Selenium 패키지 사용
- 패키지 설치
Seleinum 패키지는 구글 colab 혹은 jupyter notebook에서 지원하지 않기 때문에 따로 다운로드를 해줘야 한다.
https://chancoding.tistory.com/136
자세한 내용은 위 블로그에 나와있다. - 패키지 사용
인스타그램에서 사진을 크롤링 하는 예시를 보며 설명.
라이브러리 불러오기
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
from urllib.request import urlretrieveChromedriver 불러오기
driver = webdriver.Chrome('chromedriver')검색어 url 불러오기
keyword = '남자머리'
url = 'https://www.instagram.com/explore/tags/' + keyword + '/'
driver.get(url)로그인 버튼 누르기
btn = driver.find_element(By.XPATH, '//*[@id="mount_0_0_XD"]/div/div/div/div[1]/div/div/div/div[1]/section/nav/div[2]/div/div/div[3]/div/div[2]/div[1]/a/button')
btn.click()- Selenium 패키지에서 find_elements_by ~ 함수가 없어지고 find_element 함수만 남아있다. 그러므로 By 함수를 import 해준 후 위와 같은 방법으로 button의 xpath를 찾아줄 수 있다.
- 인스타그램 페이지 로딩을 할 때마다 버튼의 xpath값이 달라지는 것 같다... 그래서 새로고침 할 때마다 xpath를 새로 구해주어야 한다
아이디 비밀번호 입력 후 로그인
user_id = input("ID: ")
user_password = input("PASSWORD: ")
driver.find_element(By.XPATH, '//*[@id="loginForm"]/div/div[1]/div/label/input').send_keys(user_id)
driver.find_element(By.XPATH, '//*[@id="loginForm"]/div/div[2]/div/label/input').send_keys(user_password)
driver.find_element(By.XPATH, '//*[@id="loginForm"]/div/div[3]/button').click()팝업 알림 처리하기
driver.find_element(By.XPATH, '//*[@id="mount_0_0_eS"]/div/div/div/div[1]/div/div/div/div[1]/div[1]/div[2]/section/main/div/div/div/div/button').click()scroll 지정하기
body = driver.find_element(By.CSS_SELECTOR, 'body')- 지정한 scroll에 ('body'로 지정되어 있음) key 값을 넣어주면서 scroll을 올리고 내리는 효과를 낼 수 있다. 예를 들어, End key를 send 해주면 맨 밑으로 스크롤 한 효과를 낸다.
이미지 crawling 후 저장하기
from selenium.webdriver.common.keys import Keys
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
n = 1
for i in range(5):
url_list = list(map(lambda x: x.get('src'), soup.find_all('img', attrs = {'crossorigin':'anonymous', 'style':'object-fit: cover;'})))
for image in url_list:
urlretrieve(image, filename = '/Users/iwonjoon/Desktop/instagram/' + keyword + str(n) + '.jpg')
n += 1
body.send_keys(Keys.END)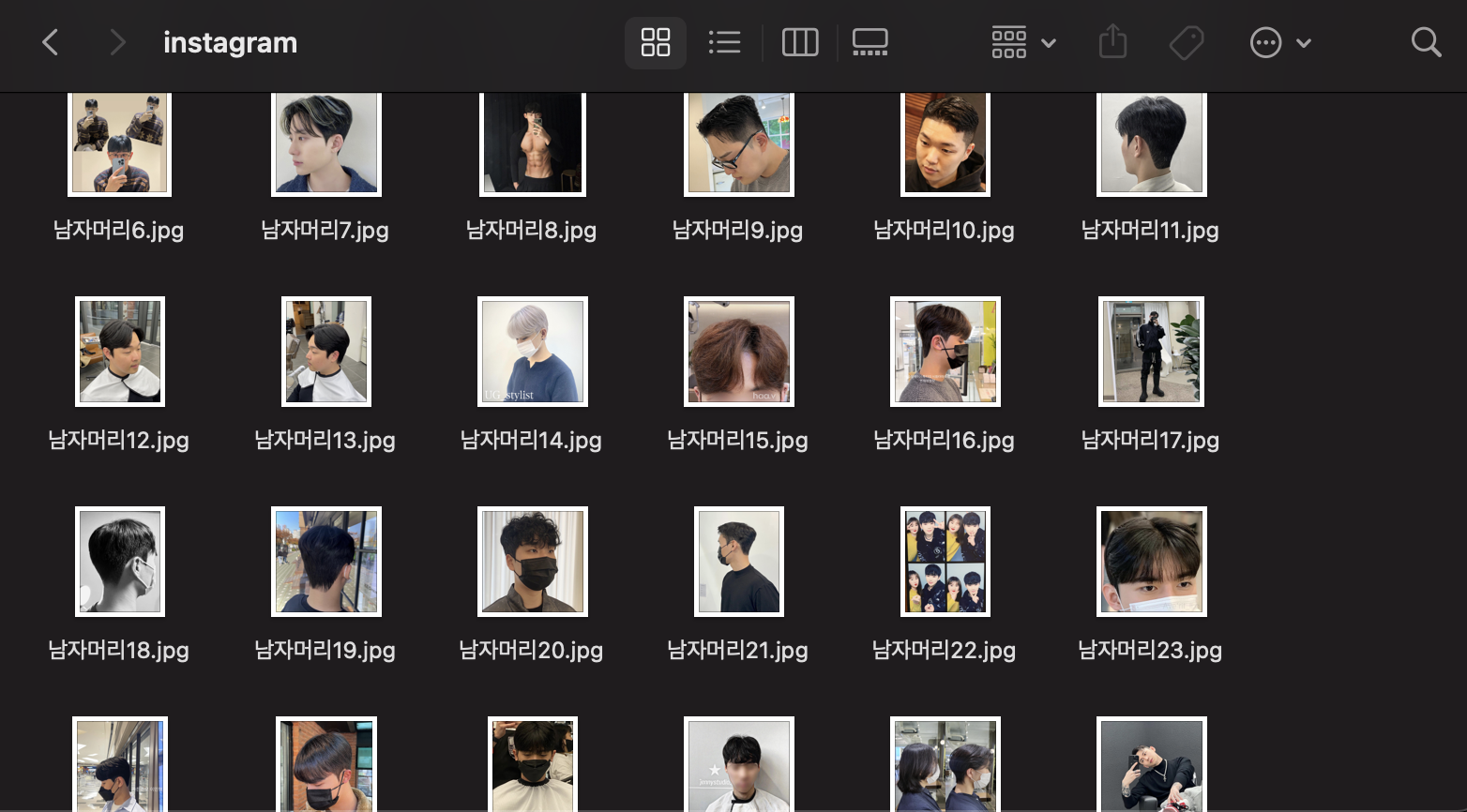
사진이 잘 저장된 것을 볼 수 있다.

안녕하세요:)