요구사항 정의
대량 데이터 기준 설정
대량의 상품을 INSERT하는 기능을 구현하기 위해, 먼저 "대량"의 기준을 정의할 필요가 있었습니다. 실제 이커머스 플랫폼의 데이터를 조사했습니다.
- 쿠팡 주요 브랜드 상품 수
- 애플 → 3241개의 상품 shop.coupang.com
- 삼성 전자 → 3874개의 상품 shop.coupang.com
- LG 전자 → 2548 개 shop.coupang.com
- 애플 → 3241개의 상품 shop.coupang.com
- 무신사 주요 브랜드 상품 수
- 나이키 → 2035 개 나이키(NIKE) | 무신사 추천 브랜드
- 아디다스 → 3479 개 아디다스 | 무신사 추천 상품
- 나이키 → 2035 개 나이키(NIKE) | 무신사 추천 브랜드
조사 결과 쿠팡의 삼성전자가 3,874개로 가장 많았습니다. 여유를 두고 한 번에 최대 5,000개의 상품이 등록될 수 있다고 가정했습니다.
동시 요청 수 산정
동시 요청 수는 어떻게 잡아야할지 궁금하였고 이는 쿠팡관련 기사를 통해서 수립할 수 있었습니다.
쿠팡의 성장세로 전체 쿠팡 입점 판매자의 75%인 중소기업들의 성장폭도 가팔라지고 있다는 평가가 나온다. 실제 국내 쿠팡의 입점 중소상공인 수는 2015년 1만2161명에서 2023년 23만명으로 19배 늘었다.
쿠팡 사상 첫 매출 '40조원' 돌파…"중소기업 23만곳도 로켓 올라타"
- 2015년: 12,161명
- 2023년: 230,000명
- 증가: 217,839명 (8년간)
- 일평균 약 75명의 신규 판매자 유입
단순 계산하면 하루 75명은 시간당 약 3명 정도입니다. 하지만 실제로는 특정 시간대(오전 업무 시작 시간 등)에 몰릴 가능성이 높다고 생각했습니다. 또한 한 판매자가 한 번에 여러 개의 상품을 등록할 수 있으므로, 피크 시간대에 5~10개 브랜드가 동시에 대량 상품 등록을 시도하는 상황을 가정했습니다.
테스트 시나리오 수립
위 자료를 바탕으로 Claude를 활용하여 수립한 테스트 시나리오입니다.
기본 성능 측정
- 100개, 500개, 1000개, 3000개, 5000개 단위로 단계별 테스트
- 각 구간에서 처리 시간, 메모리 사용량, DB 커넥션 수 측정
동시성 테스트
- 5개 브랜드가 동시에 상품 등록하는 상황 시뮬레이션
- 예: 3개 브랜드는 3000개씩, 2개 브랜드는 5000개씩 동시 요청
- 목표: 실제 여러 브랜드 입점 시나리오 반영
극한 테스트
- 10개 브랜드가 동시에 5000개씩 등록 (총 50,000개)
- 시스템 한계점 파악
해당 글에서는 극한 테스트 시나리오만 다룹니다.
부분 성공 및 중복 처리 전략
대량 데이터 INSERT 시 하나의 row 실패로 전체를 롤백하면 다음과 같은 문제가 발생합니다.
- 불필요한 네트워크 비용 증가
- 사용자의 반복적인 재시도 필요
따라서 부분 성공을 허용하는 방식으로 설계했습니다.
중복 처리 방식 선택
product_code에 unique 제약조건이 걸려있어 중복 처리 전략이 필요했습니다.
처음에는 "먼저 조회하고 없으면 삽입"하는 방식을 생각했습니다. 하지만 동시성 환경에서 문제가 있었습니다. product_code를 점유(락)하지 않는 이상, "조회 → 삽입" 사이에 다른 스레드가 먼저 삽입할 수 있기 때문입니다.
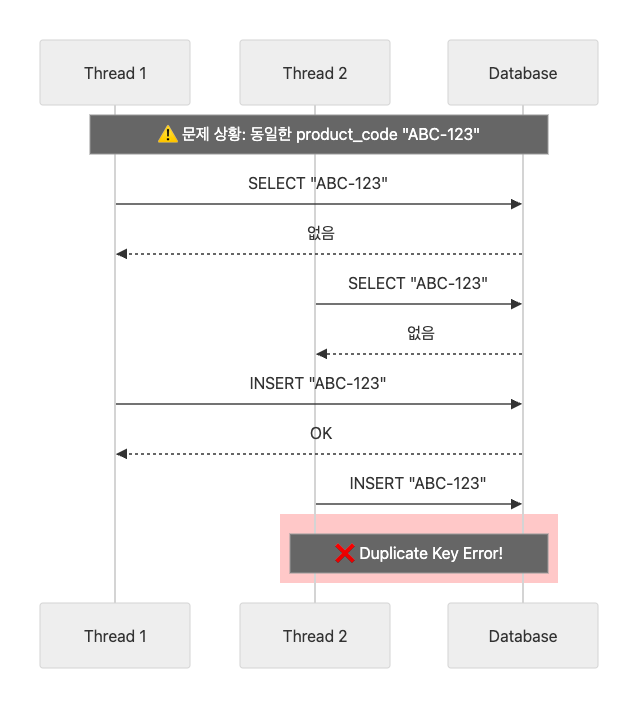
이런 경쟁 상태(race condition)를 피하기 위해, 먼저 삽입을 시도하고 DB에서 발생하는 중복 예외를 통해 핸들링하는 방식을 선택했습니다.
INSERT 후속 작업 동기화
INSERT가 완료된 후에는 Redis 재고 등록, 검색 엔진 인덱싱 등의 후속 작업이 필요했습니다. 이런 후속 작업들은 비동기로 처리 하기로 결정했습니다. 사용자는 INSERT 완료 즉시 응답을 받고, 나머지 작업은 백그라운드에서 진행됩니다.
후속 작업을 위해서는 어떤 상품이 성공적으로 저장되었는지 알아야 했습니다.
재시도 전략
대량 INSERT 과정에서 일시적인 오류가 발생할 수 있습니다.
재시도 가능한 예외 선택
Spring의 TransientDataAccessException은 "애플리케이션 코드 수정 없이 재시도만으로 성공할 수 있는 일시적 오류"를 의미합니다. 이는 JDBC의 SQLTransientException을 Spring이 변환한 예외입니다.
일시적 오류의 종류:
- 데드락
- Lock 타임아웃
- 일시적 네트워크 문제
- DB 서버 일시적 과부하
이런 경우는 재시도로 해결할 수 있을 것 같았습니다.
커넥션 풀 고갈도 재시도해볼까?
커넥션 풀 고갈(CannotGetJdbcConnectionException)은 NonTransientDataAccessResourceException의 하위 클래스입니다. Spring에서는 재시도해도 해결되지 않는 비일시적 오류로 분류하고 있었습니다.
하지만 저는 "커넥션 풀도 조금 기다리면 반납되니까 일시적인 것 아닌가?"라고 생각했습니다. Spring의 분류가 너무 보수적인 것 같았고, 재시도 정책에 포함시켜보기로 했습니다.
실제로 적용한 결과:
- 10개 브랜드가 동시에 5000개씩
INSERT요청 - 커넥션 풀 고갈로 일부 요청 실패
- 실패한 요청들이 재시도 시작
- 기존 요청으로 이미 고갈된 상태에서 재시도 요청까지 커넥션을 요구
- 잘 처리되던 요청들까지 블로킹됨
- 전체 동시성 환경에서 처리량(throughput) 급격히 저하
오히려 성능이 더 나빠졌습니다.
결론:
Spring이 커넥션 풀 고갈을 NonTransientDataAccessResourceException으로 분류한 데는 이유가 있었습니다. 리소스가 부족한 상황에서 재시도는 문제를 악화시킬 뿐입니다. 대기 큐만 길어지고 전체가 느려집니다.
결국 TransientDataAccessException만 재시도하도록 원복했습니다. 근본적인 해결책은 재시도가 아닌 INSERT 성능 자체를 개선하는 것이었습니다.
테스트 환경
기술 스택
Spring Boot(Kotlin), MySQL, Redis, K6, Docker
데이터 구조
성능 테스트를 위해 다루게 될 상품 테이블의 구조입니다.
create table products
(
id bigint auto_increment primary key,
created_at datetime(6) not null,
deleted_at datetime(6) null,
updated_at datetime(6) not null,
product_code varchar(255) null,
name varchar(20) null,
owner_id bigint null,
product_price decimal(19, 2) null,
product_currency_code enum ('KOR') null,
stock bigint null,
constraint UK922x4t23nx64422orei4meb2y
unique (product_code)
);product_code에 unique 제약조건이 걸려있어 대량 INSERT 시 중복 처리가 중요한 포인트가 될 것으로 예상했습니다.
하드웨어 스펙
MacBook M1 Pro, RAM 16GB
EC2 t2.micro 환경을 재현하기 위해 Docker로 애플리케이션의 리소스를 제한했습니다.
# EC2 t2.micro equivalent: 1 vCPU, 1GB RAM
deploy:
resources:
limits:
cpus: '1.0'
memory: 1G
reservations:
cpus: '0.5'
memory: 512M성능 개선 과정
JDBC BatchUpdate와 INSERT IGNORE 활용
기술 선택 이유
JDBC BatchUpdate
여러 개의 SQL문을 하나의 그룹으로 묶어 단 한 번의 네트워크 통신으로 전송/실행하는 기능입니다. 네트워크 비용을 줄여 성능을 개선하고자 선택했습니다.
MySQL INSERT IGNORE
데이터 삽입 시 발생하는 특정 에러(중복 등)를 무시하고 쿼리를 계속 진행하는 명령어입니다. 하나의 실패로 전체가 롤백되는 것을 방지하기 위해 사용했습니다.
두 기술을 조합하면 대량 데이터 삽입 성능과 부분 성공 두 마리 토끼를 잡을 수 있을 것으로 기대했습니다.
초기 구현
private fun saveAndReturnedResult(products: List<Product>): List<Result<Long>> {
val sql = """
INSERT IGNORE INTO products
(owner_id, product_code, ..., created_at, updated_at)
VALUES (?, ?, ?, ?, ?, ?, ?, ?)
""".trimIndent()
return jdbcTemplate.execute { conn ->
conn.prepareStatement(sql, Statement.RETURN_GENERATED_KEYS).use { ps ->
products.forEach { product ->
// 파라미터 설정
ps.addBatch()
}
val rows = ps.executeBatch()
val generatedKeys = ps.generatedKeys
// 결과 매핑
buildList {
products.forEachIndexed { idx, product ->
when {
rows[idx] == 0 -> add(Result.failure(...)) // 중복
generatedKeys.next() -> add(Result.success(generatedKeys.getLong(1))) // 성공
else -> add(Result.failure(...)) // 예외
}
}
}
}
} ?: emptyList()
}
RETURN_GENERATED_KEYS를 사용한 이유는 INSERT 성공한 데이터의 ID를 받아서 Redis에 재고를 등록할 때 사용하기 위함입니다.
[테스트 결과: 초기 구현]
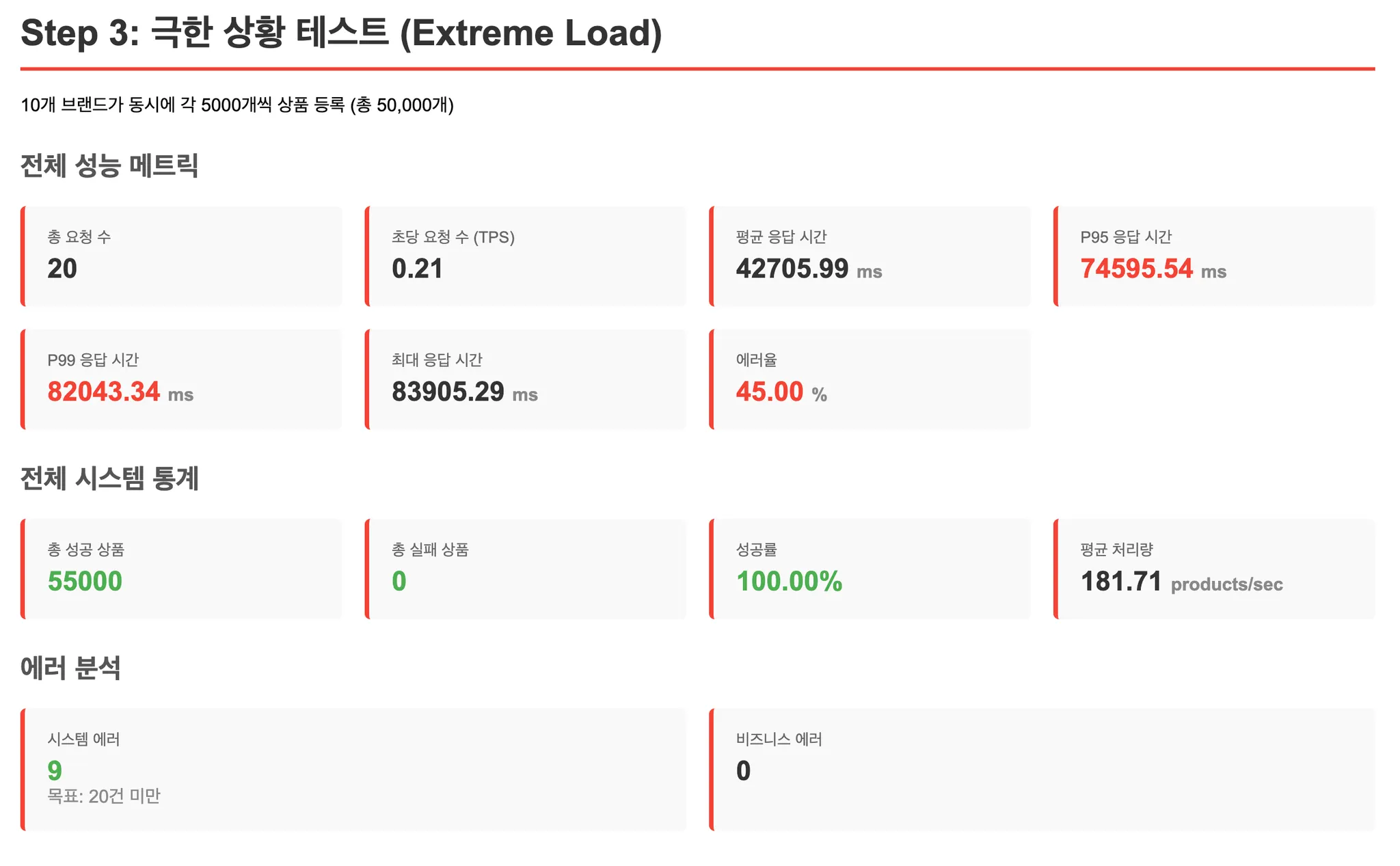
문제 발견: 커넥션 풀 고갈
극한 테스트(10개 브랜드 동시 5000개씩)를 돌렸더니 예외가 발생했습니다.
org.springframework.jdbc.CannotGetJdbcConnectionException: Failed to obtain JDBC Connection
at org.springframework.jdbc.datasource.DataSourceUtils.getConnection(DataSourceUtils.java:84)
커넥션 풀이 고갈된 상황이었습니다. 커넥션을 빠르게 반납하려면 DB 쿼리 성능이 중요하다고 생각했고, MySQL 쿼리 로그를 확인해봤습니다.
rewriteBatchedStatements 옵션 추가
MySQL 쿼리 로그를 확인하니 예상과 달랐습니다.
-- 기대: 하나의 multi-value INSERT
INSERT INTO products VALUES (...), (...), (...)
-- 실제: 개별 INSERT
INSERT INTO products VALUES (...)
INSERT INTO products VALUES (...)
분명 addBatch()로 묶어서 보냈는데 왜 개별로 나갈까요?
검색 결과, MySQL JDBC 드라이버는 기본적으로 batch를 개별 쿼리로 실행한다는 것을 알게 되었습니다. rewriteBatchedStatements=true 옵션을 설정하면 드라이버가 자동으로 multi-value INSERT로 변환해준다고 합니다.
datasource:
url: jdbc:mysql://localhost:3306/...&rewriteBatchedStatements=true
문제 발견: 개별 쿼리 실행
옵션을 추가하고 다시 테스트했습니다.
[테스트 비교 : 좌 설정 전, 우 설정 후]
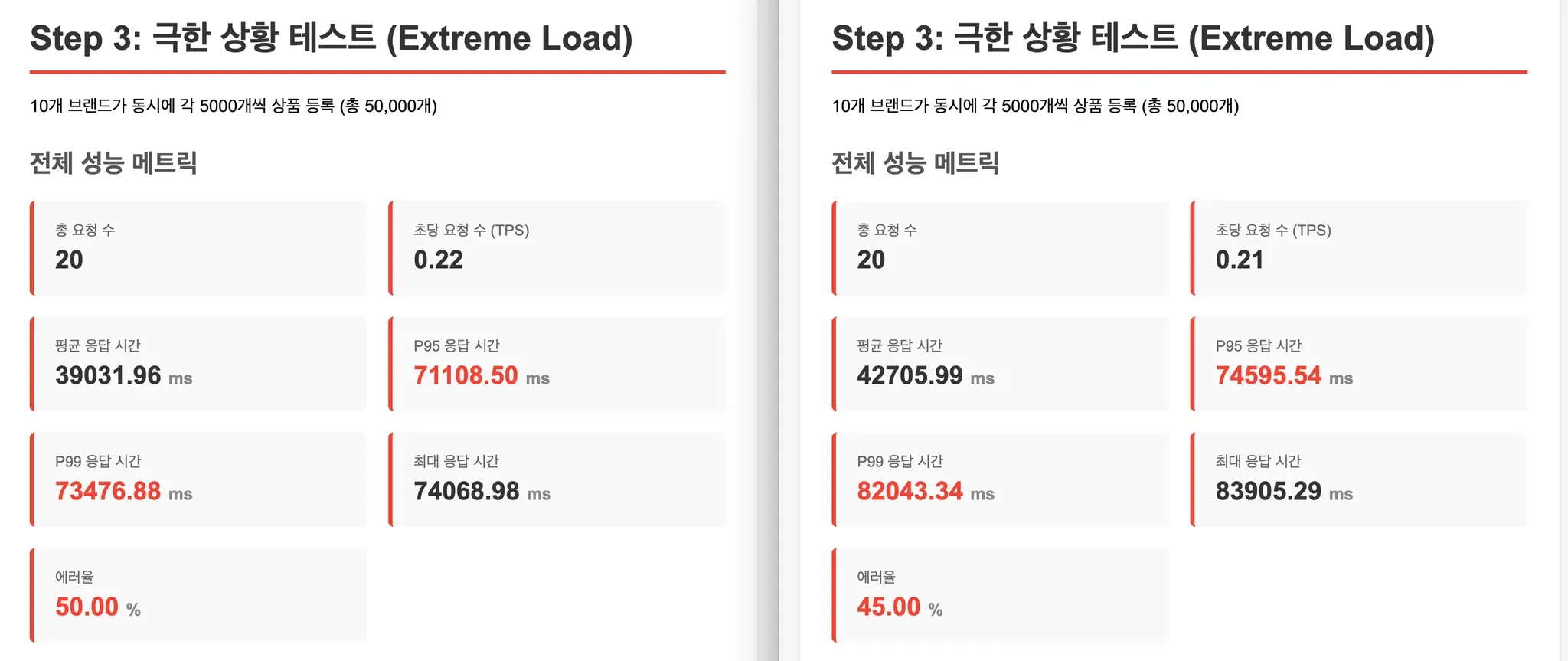
성능 개선이 없었습니다. 다시 MySQL 로그를 확인했는데... 여전히 개별 쿼리로 나가고 있었습니다.
저는 처음에 "옵션이 제대로 적용 안 됐나?" 싶었습니다. 하지만 설정을 여러 번 확인해도 문제가 없었습니다.
혹시 RETURN_GENERATED_KEYS나 INSERT IGNORE가 문제일까 싶어 Claude에게 물어봤습니다.
Claude의 답변:
RETURN_GENERATED_KEYS 사용 시:
jdbcTemplate.batchUpdate(sql, products, PreparedStatement.RETURN_GENERATED_KEYS) { ps, product -> // ... }rewrite가 안 되는 이유:
- Multi-value INSERT:
INSERT INTO table VALUES (1,'a'),(2,'b'),(3,'c')- 생성된 ID가 [101, 102, 103] 이라면, 어느 행이 어느 ID인지 순서 매칭 불확실
- MySQL 드라이버가 안전하게 개별 INSERT로 처리
INSERT IGNORE 사용 시:
INSERT IGNORE INTO table VALUES (?,?)rewrite가 안 되는 이유:
- Multi-value로 합치면:
INSERT IGNORE INTO table VALUES (1,'a'),(2,'b'),(3,'c')- 중간에 하나 실패(중복) 시 어느 행이 성공/실패했는지 불명확
- 개별 처리해야 각 행의 결과를 정확히 알 수 있음
ON DUPLICATE KEY UPDATE로 변경
기술적 딜레마
IGNORE가 문제였습니다. 이제 선택해야 했습니다.
- 성능을 위해
IGNORE를 포기할 것인가? - 부분 성공을 위해
rewriteBatchedStatements를 포기할 것인가?
둘 다 포기할 수 없었습니다. 다른 방법을 고민하다가 ON DUPLICATE KEY UPDATE를 떠올렸습니다.
INSERT INTO products (...)
VALUES (?, ?, ?, ...)
ON DUPLICATE KEY UPDATE product_code = product_code
ON DUPLICATE KEY UPDATE product_code = product_code는 기존 값을 그대로 덮어쓰는 no-op 구문입니다. 중복 시 예외를 던지지 않고 조용히 넘어갑니다. 이렇게 하면 IGNORE와 같은 효과를 내면서도 rewriteBatchedStatements가 작동할 것으로 기대했습니다.
검증: multi-value INSERT 확인
IGNORE를 ON DUPLICATE KEY UPDATE로 바꾸면 rewriteBatchedStatements가 작동할까요? MySQL 로그를 확인해봤습니다.
INSERT INTO products (owner_id, product_code, product_price, product_currency_code, stock, name, created_at, updated_at)
VALUES
(1, 'B100-1766991082352-1-0-0-U8NLFL', 344756, 'KOR', 29, '타구5처소w후zhej다', '2025-12-29 15:51:22.39824', '2025-12-29 15:51:22.39824'),
(1, 'B100-1766991082352-1-0-1-CAU5AX', 506014, 'KOR', 853, '바yO러라커T우조오주', '2025-12-29 15:51:22.39824', '2025-12-29 15:51:22.39824'),
...
ON DUPLICATE KEY UPDATE product_code = product_code;여러 row가 하나의 INSERT문으로 묶여서 나갔습니다.
새로운 문제: 중복 판별
그런데 새로운 고민이 생겼습니다. ON DUPLICATE KEY UPDATE는 중복이어도 성공으로 처리됩니다. 어떻게 신규 삽입과 중복을 구분할까요?
저는 created_at을 활용하기로 했습니다.
- JDBC로 삽입할 때
created_at을 직접 주입 (JPA Auditing 사용 불가) - 삽입 후
product_code IN (...)로 조회 - DB의
created_at과 삽입 시 사용한created_at비교 - 같으면 신규, 다르면 중복
함정: LocalDateTime 정밀도
여기서 한 가지 문제가 있었습니다. MySQL의 DATETIME(6)는 마이크로초 단위지만, Java의 LocalDateTime은 나노초 단위입니다. 그냥 비교하면 같은 시간인데도 false가 나올 수 있습니다.
DB마다 정밀도가 다를 수 있어서(H2는 나노초 등), 밀리초로 통일하여 비교하기로 했습니다.
/**
* DB 환경에 독립적인 시간 비교
*/
private fun compareLocalDateTime(
time1: LocalDateTime, time2: LocalDateTime
): Boolean {
return time1.truncatedTo(ChronoUnit.MILLIS)
.isEqual(time2.truncatedTo(ChronoUnit.MILLIS))
}[테스트 결과: ON DUPLICATE KEY UPDATE 적용 후]
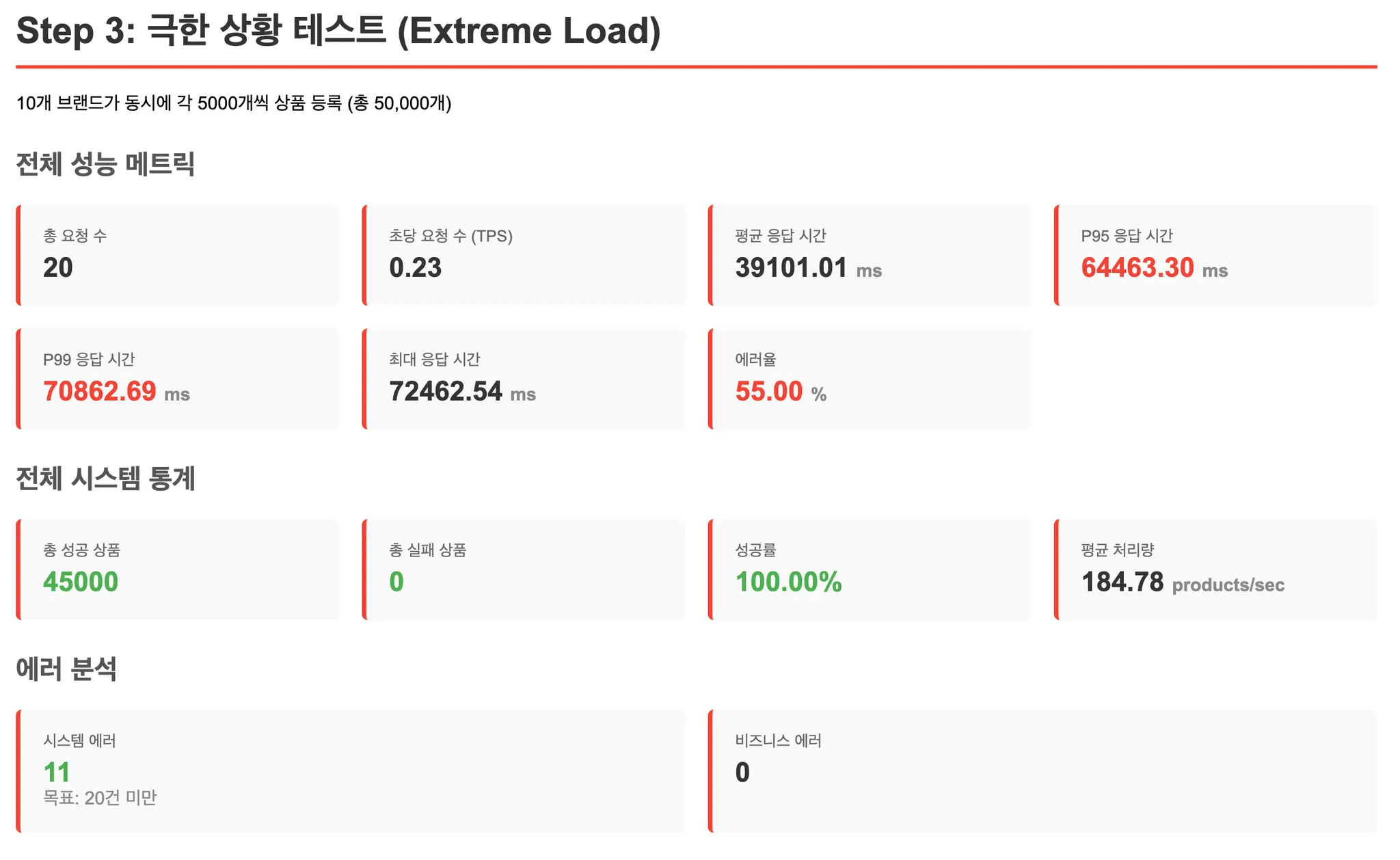
성능이 미미하지만 개선되었습니다.
조회 성능 개선
INSERT 성능을 개선했으니, 이제 후속 작업(Redis 재고 업데이트)을 위한 조회 성능도 개선하고 싶었습니다.
기존 방식의 문제
기존에는 삽입한 상품들을 다시 조회할 때 이렇게 했습니다:
SELECT * FROM products
WHERE product_code IN (...); -- 5000개이 쿼리는 테이블을 full-scan하면서 5000개의 product_code와 일치하는 row를 찾아야 합니다. 검색 범위를 줄일 방법이 없을까요?
해결 시도: created_at 조건 추가
저는 삽입할 때 created_at을 직접 주입했기 때문에 이 값을 알고 있습니다.
핵심 아이디어: 전체 테이블을 스캔하며 product_code를 찾기보다, created_at으로 먼저 범위를 좁힌 다음 그 안에서 product_code를 찾으면 훨씬 효율적일 것입니다.
SELECT *
FROM products
WHERE created_at = ?
AND product_code IN (...);
추가 시도: 인덱스 생성
조회 성능을 더 높이기 위해 복합 인덱스를 추가했습니다.
CREATE INDEX idx_created_product ON products(created_at DESC, product_code);
인덱스 순서 선택 이유:
created_at DESC를 첫 번째로: 방금 INSERT한 데이터이므로 내림차순으로 정렬하면 인덱스 앞쪽에서 바로 찾을 수 있어 검색 비용이 감소할 것으로 생각했습니다.product_code를 두 번째로: created_at으로 좁힌 범위 내에서 IN절 매칭
[테스트 결과: WHERE 절 변경 및 인덱스 추가 후]
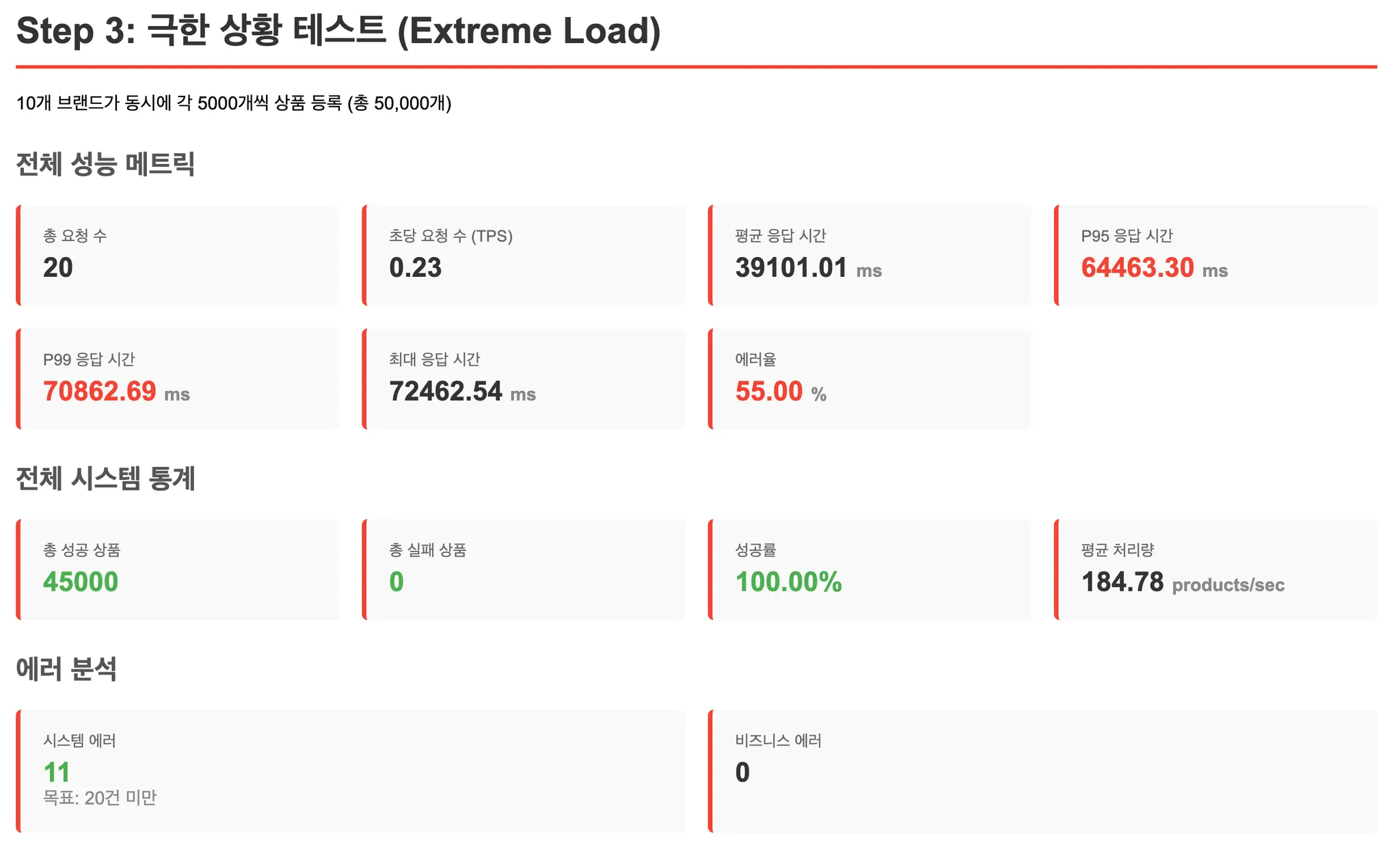
오히려 성능이 떨어졌습니다.
원인 분석: INSERT 비용 증가
왜 인덱스를 추가했는데 느려졌을까요?
Real MySQL에서 읽었던 내용이 떠올랐습니다. 인덱스는 SELECT 성능을 높이지만, INSERT 시에는 인덱스를 함께 업데이트해야 하므로 쓰기 비용이 증가합니다.
Real MySQL - 인덱스의
INSERT비용테이블에 레코드를 추가하는 작업 비용을 1이라고 가정하면, 해당 테이블의 인덱스에 키를 추가하는 작업 비용은 1.5정도로 예측할 수 있습니다.
일반적으로 테이블에 인덱스가 3개(모두 B-Tree 인덱스)가 있다면:
- 인덱스가 하나도 없는 경우: 작업 비용 1
- 인덱스가 3개인 경우: 작업 비용 5.5 정도 (1.5 × 3 + 1)
제가 추가한 인덱스로 인해 INSERT 비용이 1.5배 증가한 것입니다. 대량 INSERT가 주요 작업인 이 케이스에서는 인덱스 유지 비용이 조회 성능 향상보다 더 크게 작용한 것 같았습니다.
검증을 위해 인덱스를 제거하고 다시 테스트했습니다.
[테스트 결과: 인덱스 제거 후]
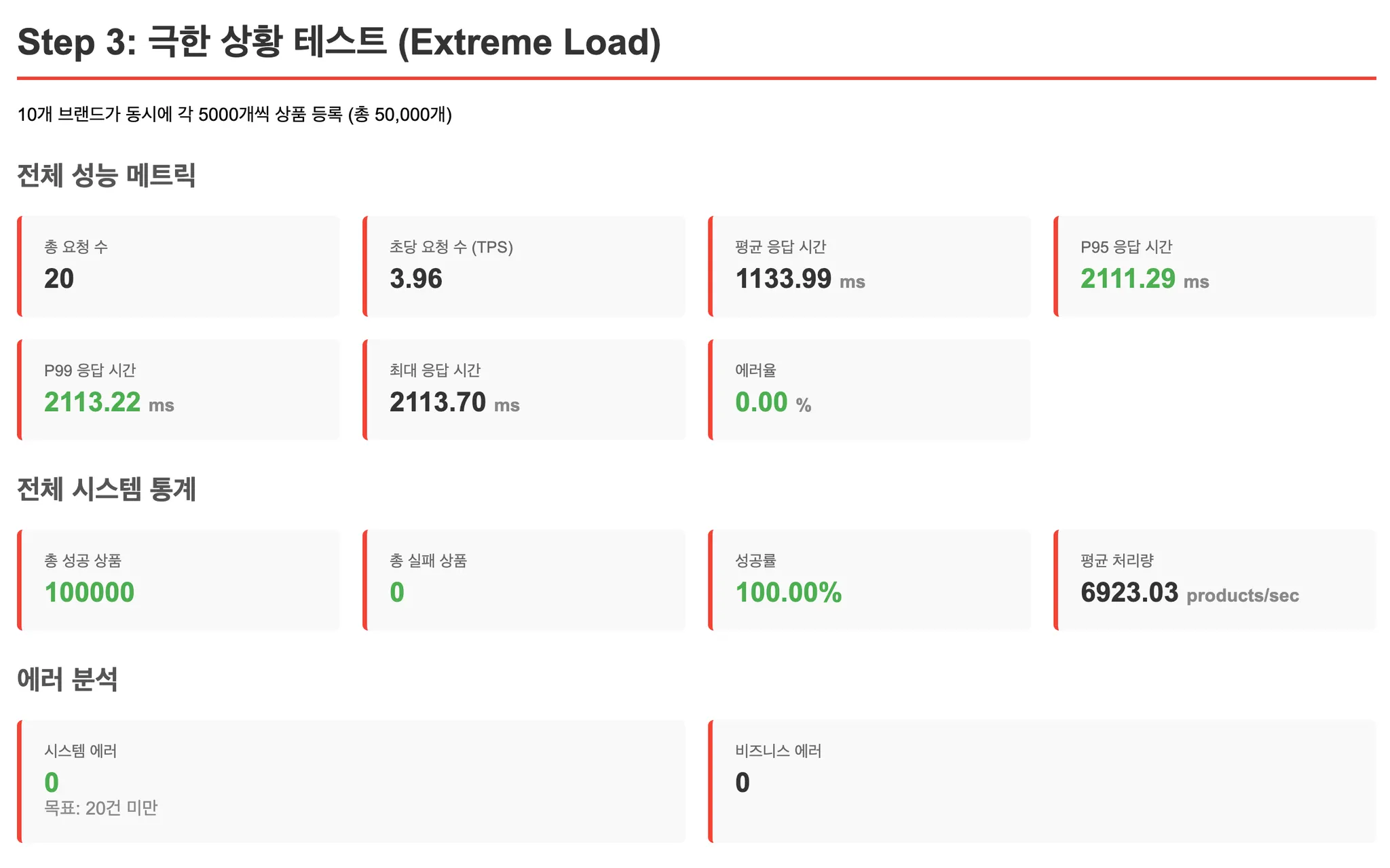
성능이 대폭 상승했습니다!
결론: 조회는 created_at으로 범위를 충분히 좁혔기 때문에 인덱스 없이도 빠르게 처리되었습니다. 오히려 인덱스 유지 비용이 대량 INSERT의 발목을 잡았던 것입니다. 모든 상황에 인덱스가 답은 아니라는 것을 배웠습니다.
마치며
성능 개선 결과
극한 테스트(10개 브랜드 × 5,000개 동시 INSERT)에서:
- INSERT IGNORE → ON DUPLICATE KEY UPDATE로 multi-value INSERT 활성화
- created_at 조건 추가로 조회 시 full-scan 방지
- 올바른 재시도 전략으로 안정성 확보
