개요
동시성 환경에서 재고 관리는 정확성이 핵심입니다.
100개의 제품이 있다면 정확히 100개만 판매되어야 합니다.
동시성 제어가 실패하면:
- 101개 판매: 실제 재고보다 많이 팔려 사용자에게 피해 발생
- 99개 판매: 재고가 있는데도 팔지 못해 판매사에게 피해 발생
이 글에서는 동시성 문제를 해결하는 세 가지 방법을 성능 테스트로 비교합니다:
MySQL 비관적 락, Redis 네임드 락, Redis Atomic 연산을 활용한 재고 관리.
성능 테스트 시나리오
K6를 활용해 4가지 상황에서 성능을 측정했습니다.
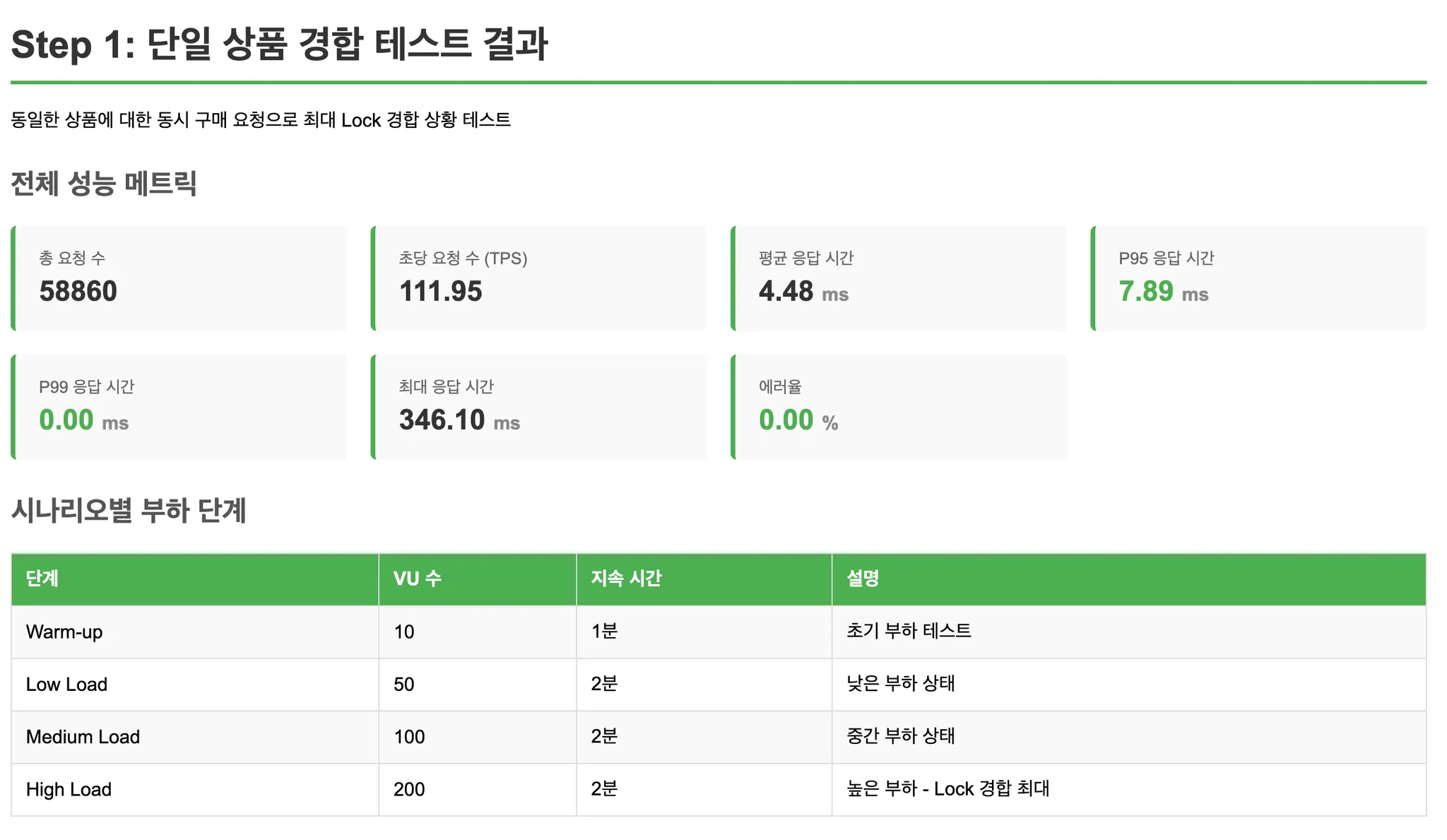
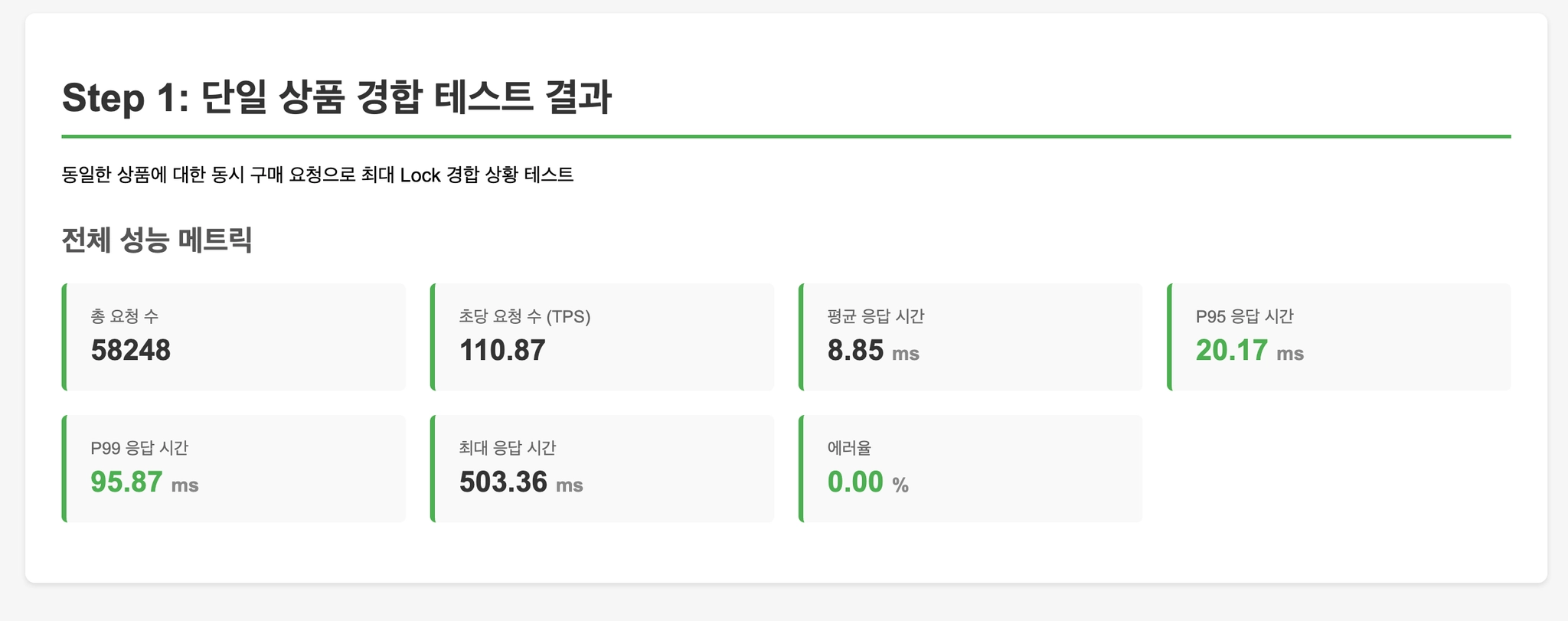
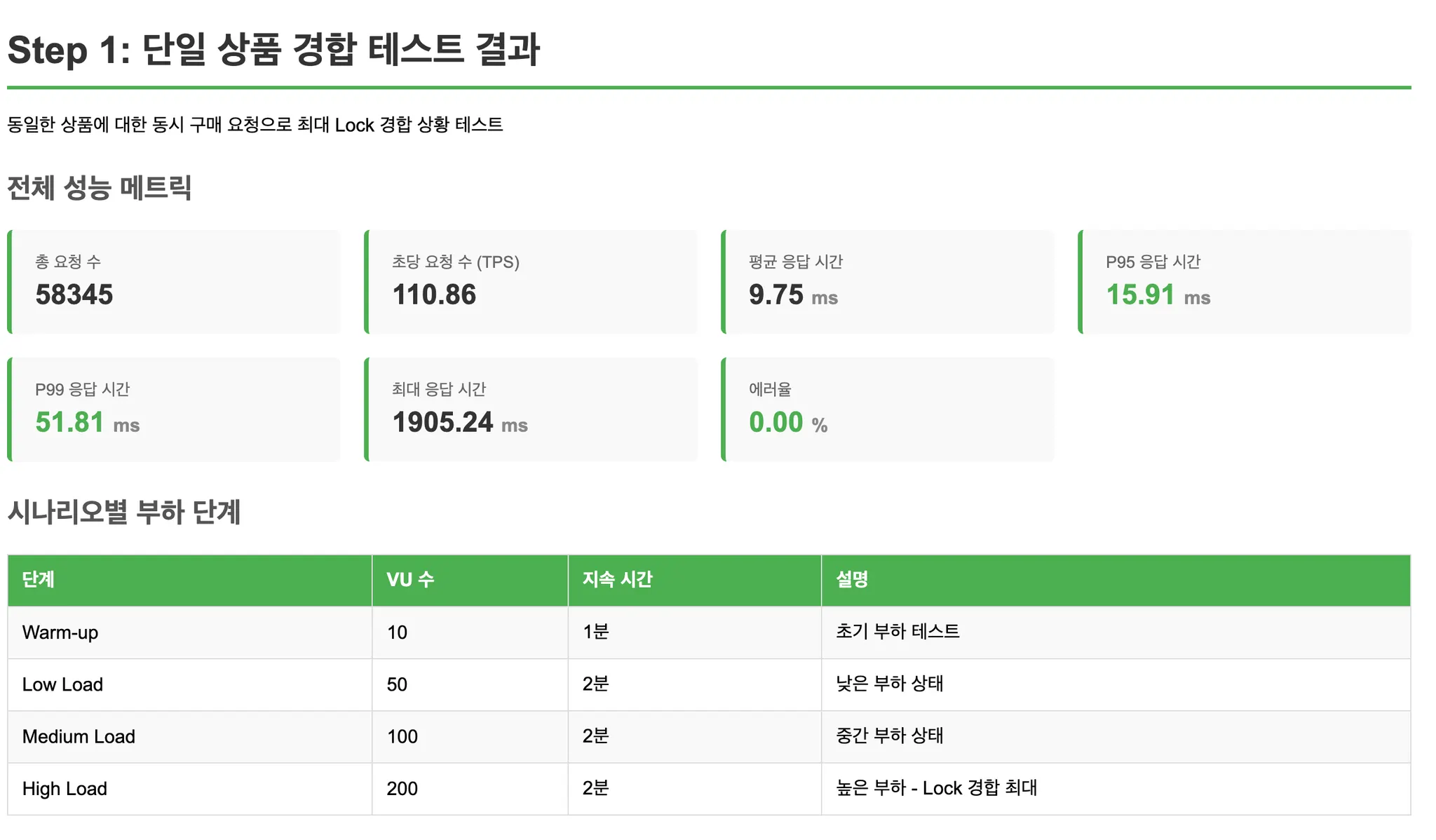
Step 1: 단일 상품 집중 (최악의 경합)
모든 요청이 동일한 상품(ID=1)을 구매합니다.
Lock 경합이 최대화되는 최악의 케이스를 측정합니다.
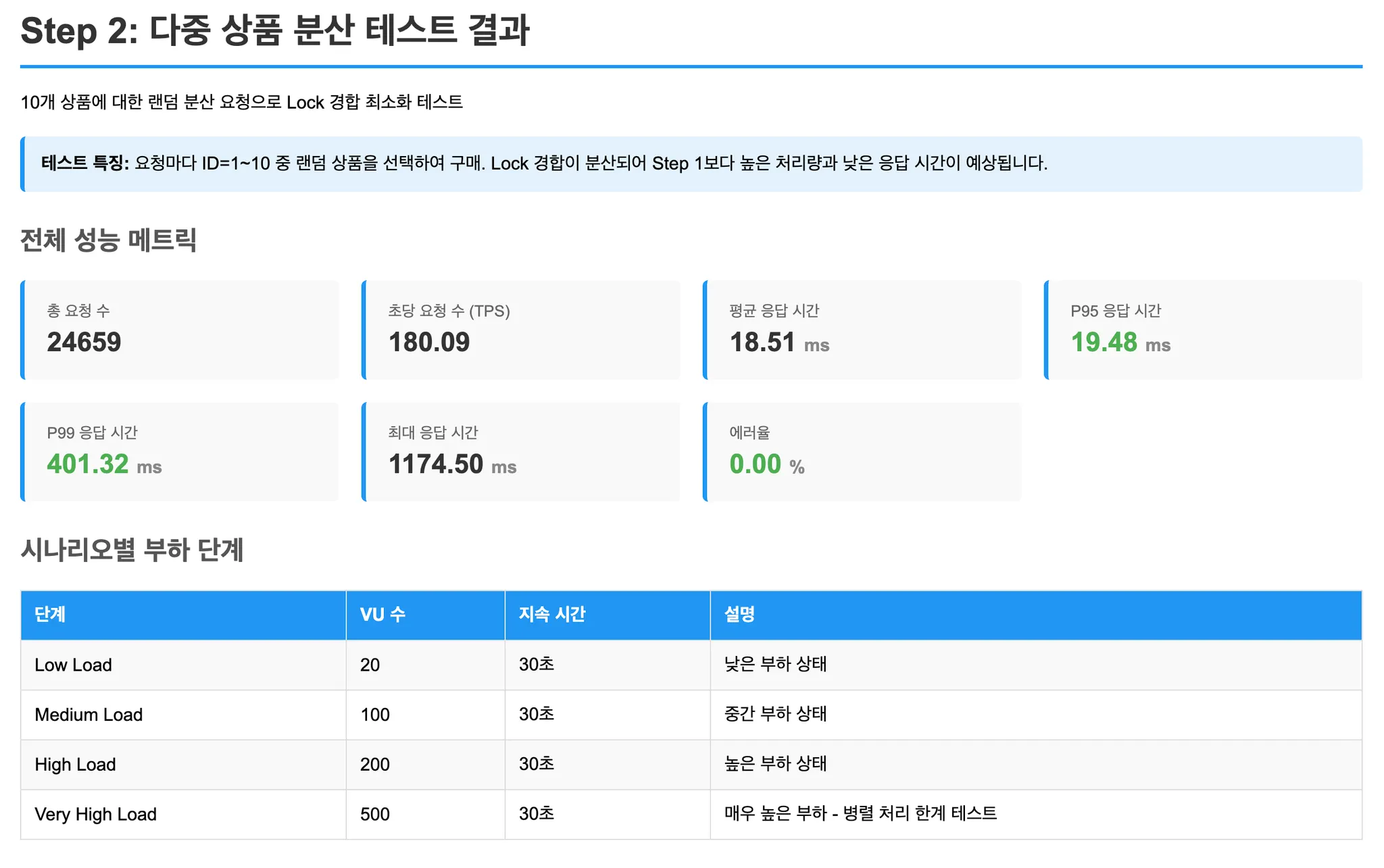
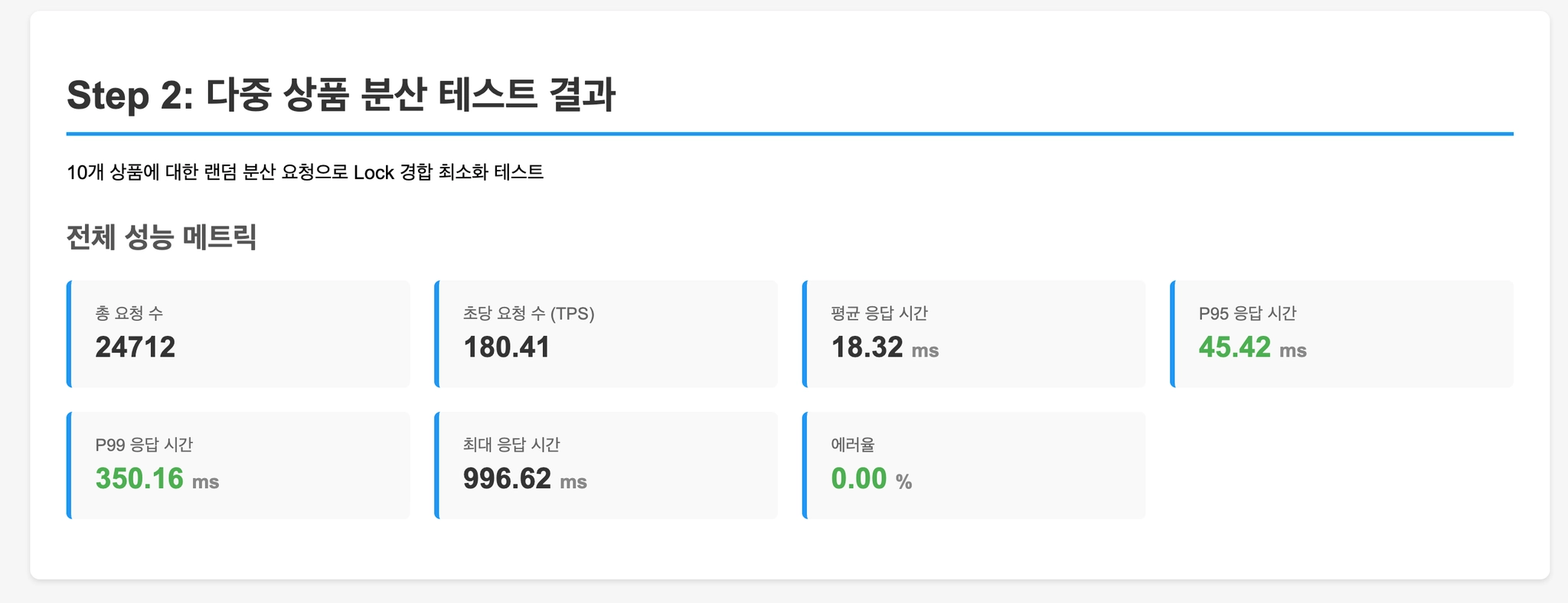
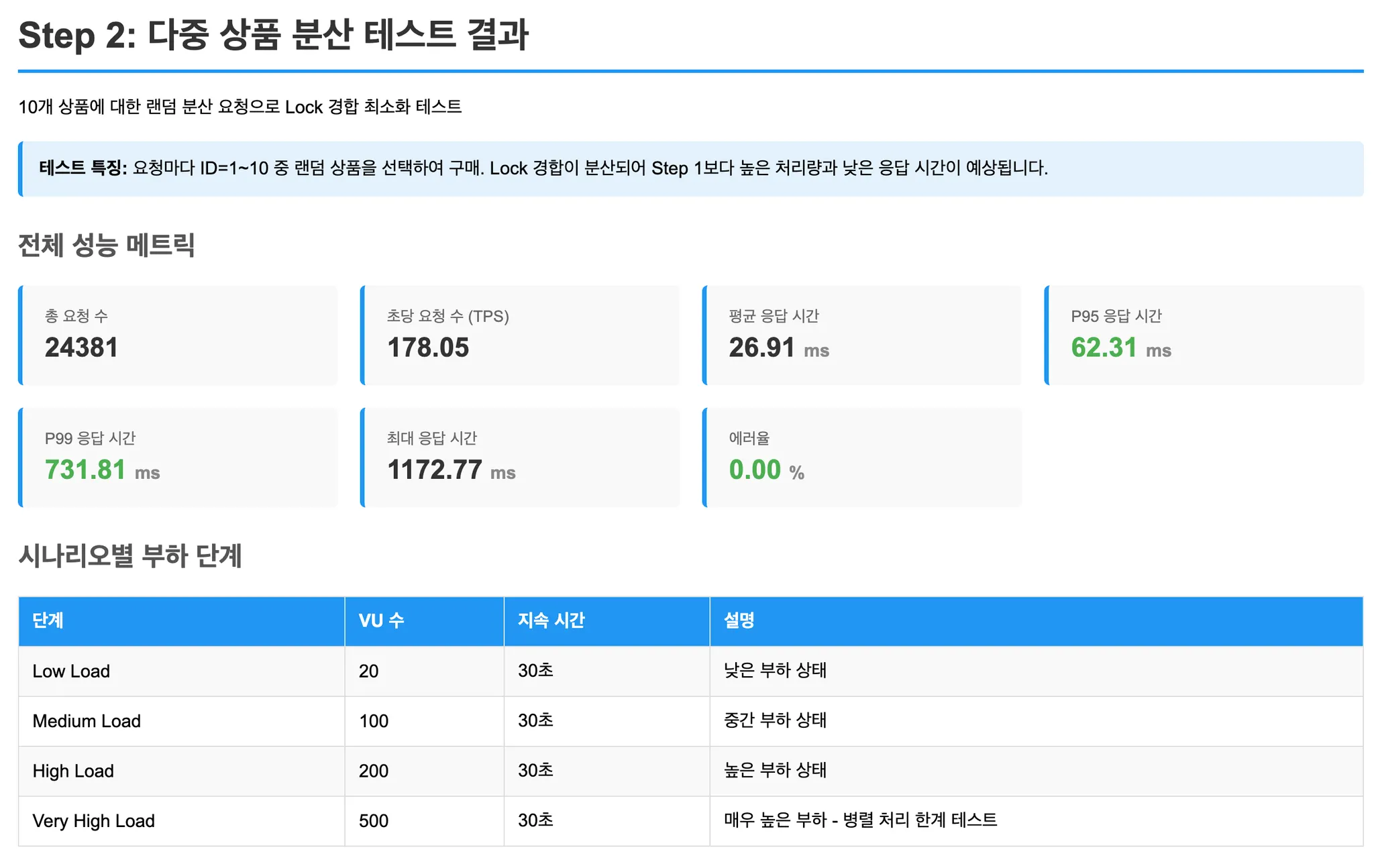
Step 2: 다중 상품 분산 (경합 최소화)
각 요청이 1~10번 상품 중 랜덤하게 선택합니다.
Lock 경합이 분산될 때의 성능을 측정합니다.
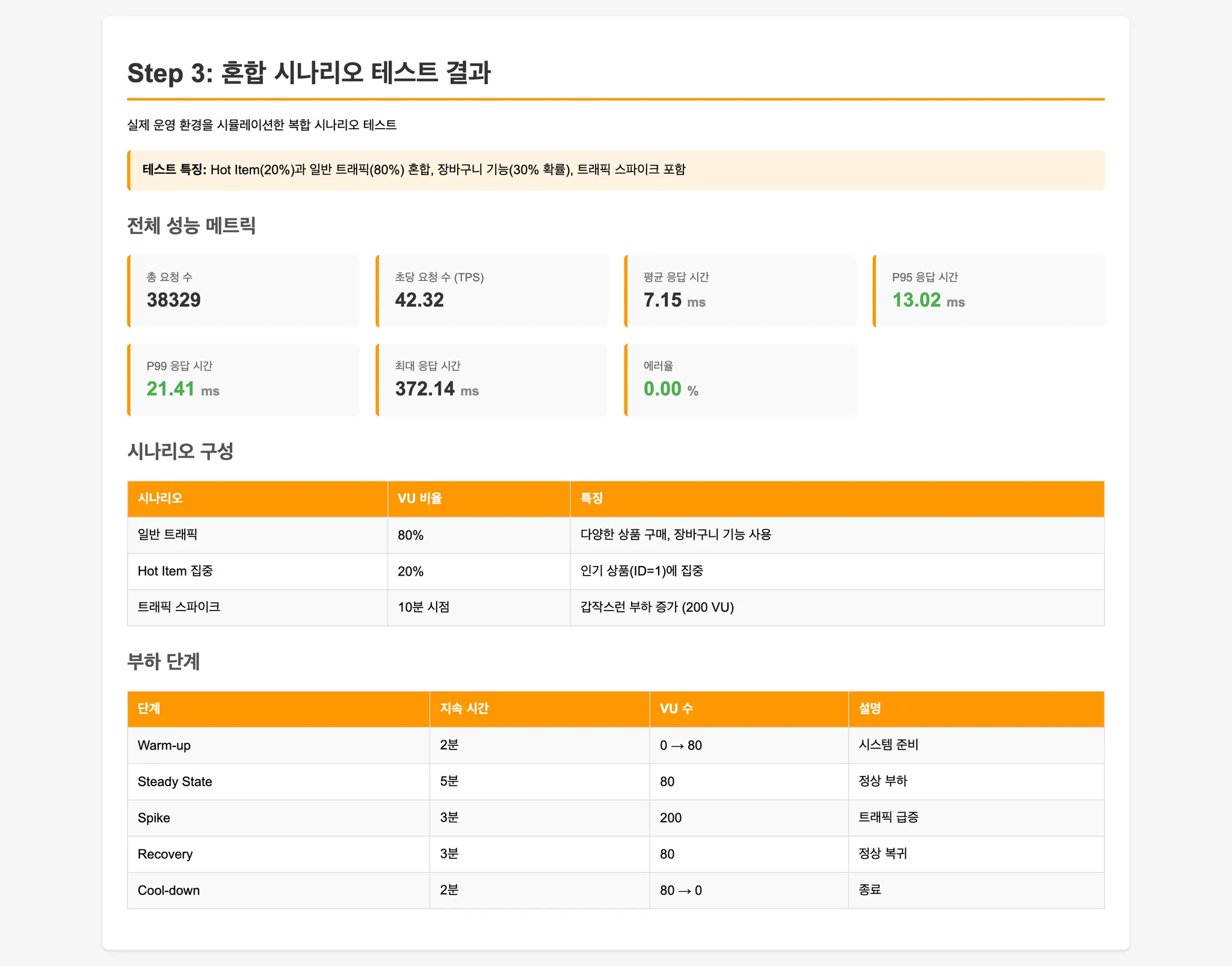
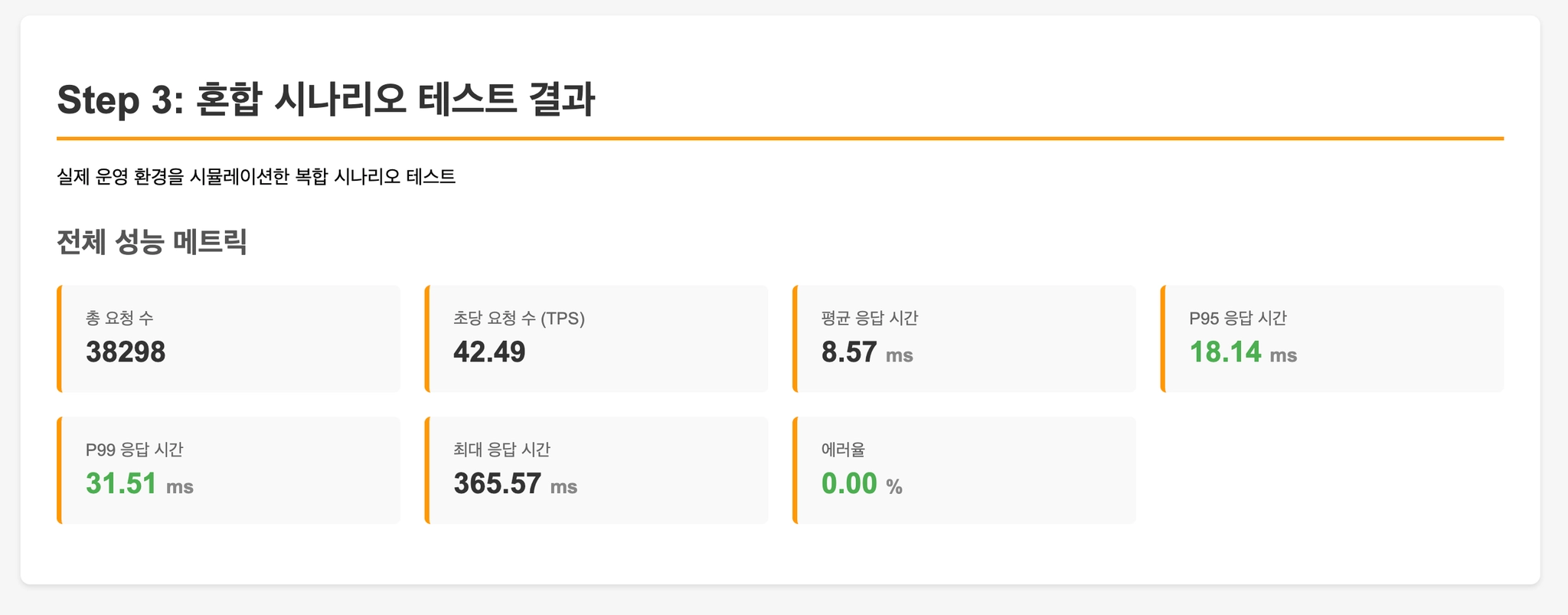
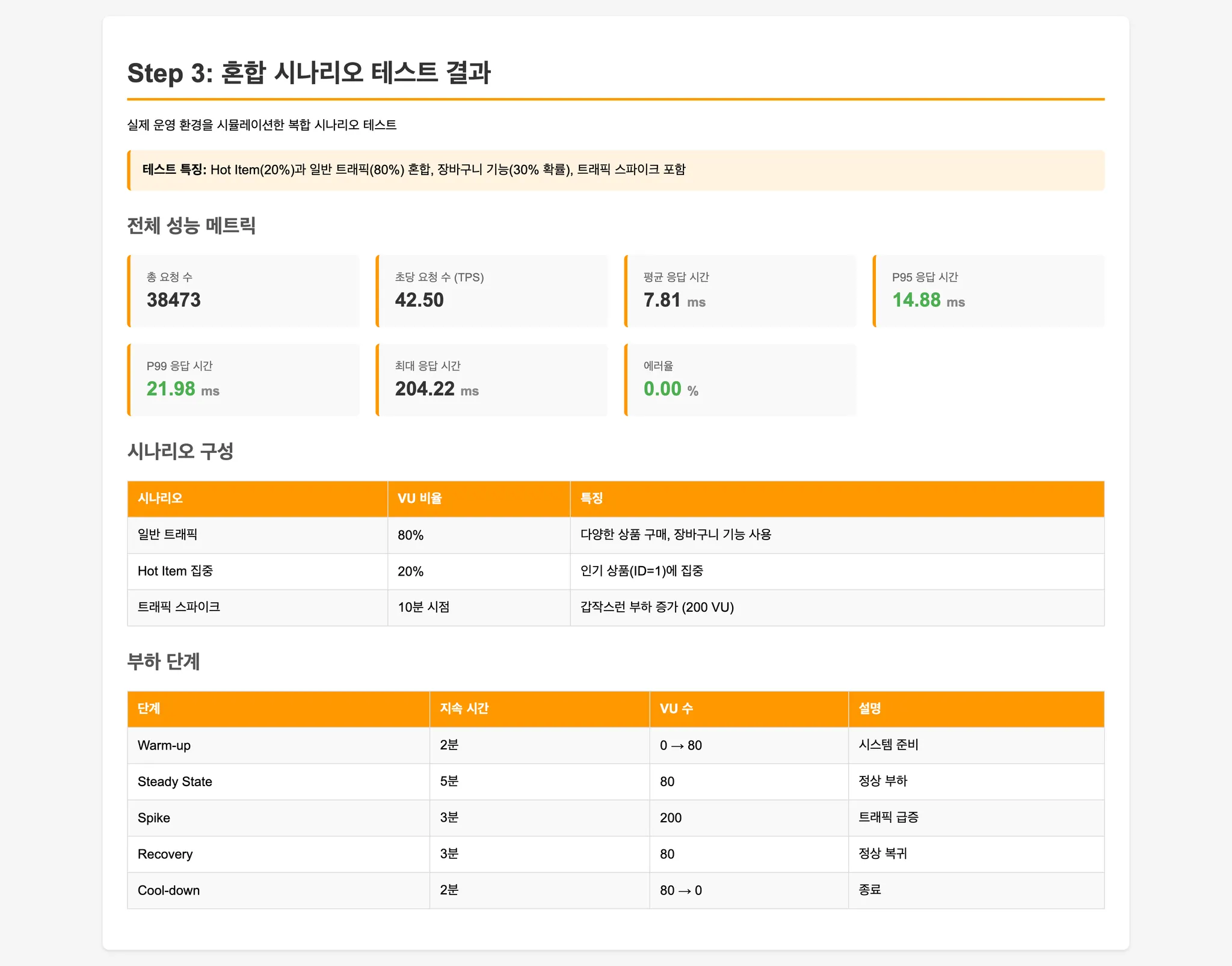
Step 3: 실제 운영 환경 시뮬레이션
- Hot Item: 20% 요청이 인기 상품에 집중
- 일반 트래픽: 80% 요청이 다양한 상품 구매
- 장바구니: 30% 확률로 여러 상품 동시 구매
- 트래픽 스파이크: 중간에 갑작스러운 부하 급증
실제 쇼핑몰 환경과 유사한 혼합 패턴을 재현합니다.
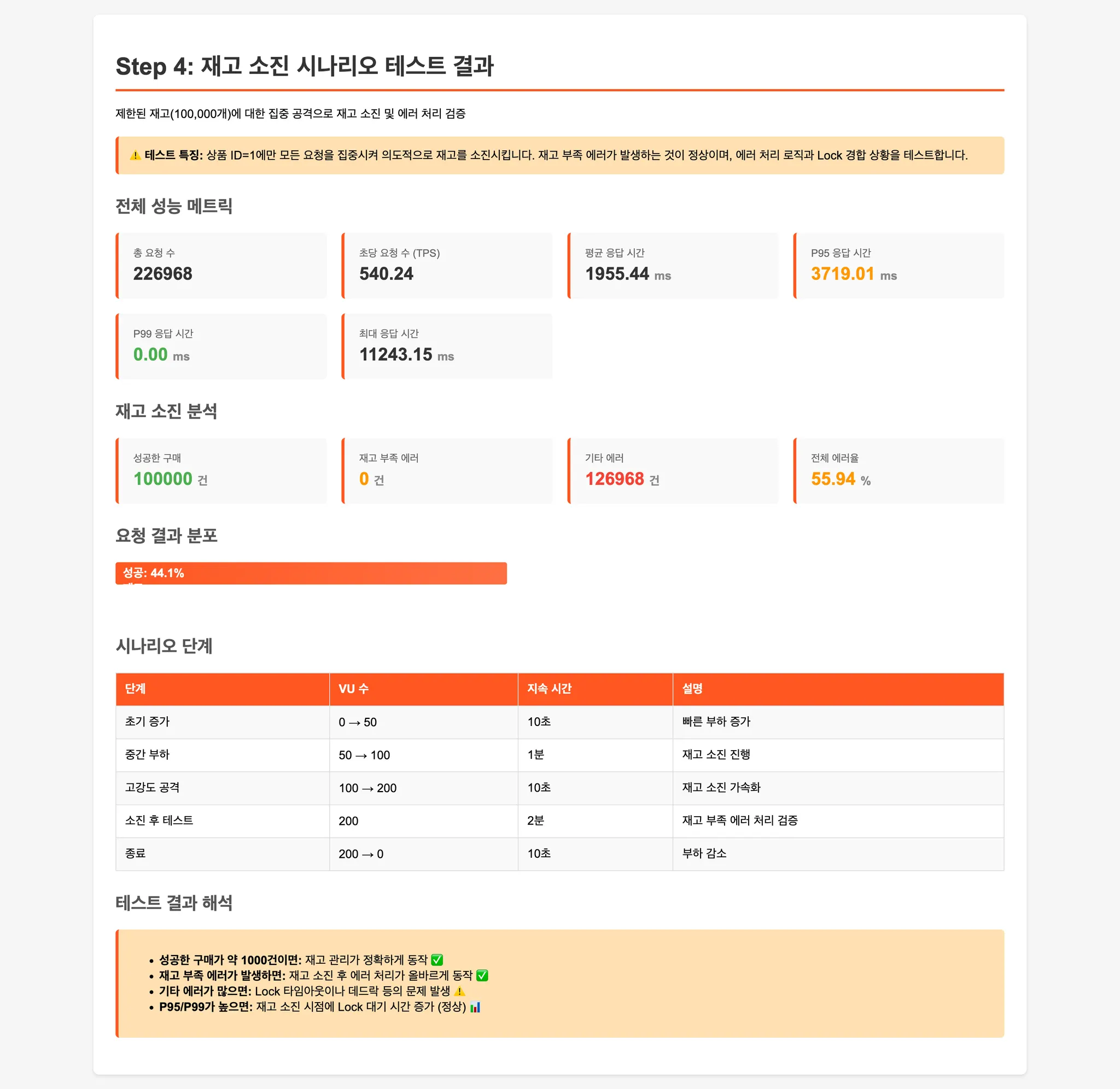
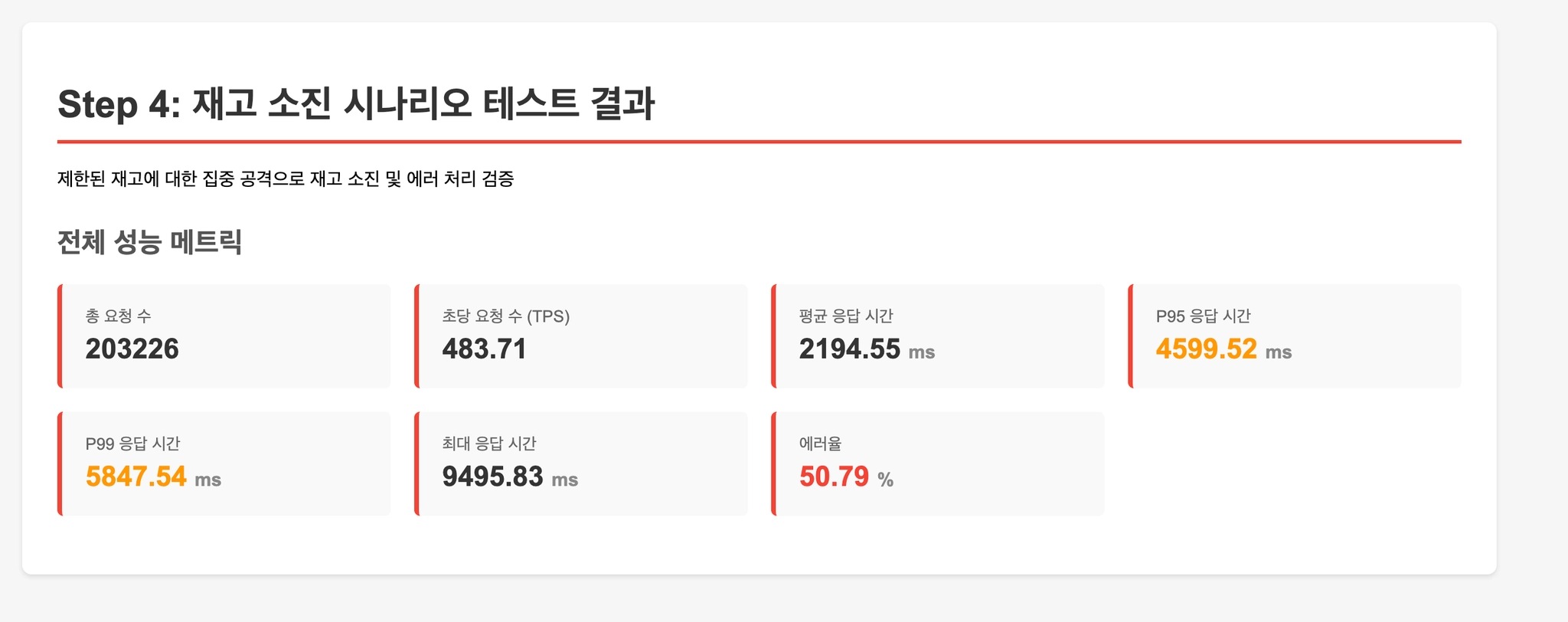
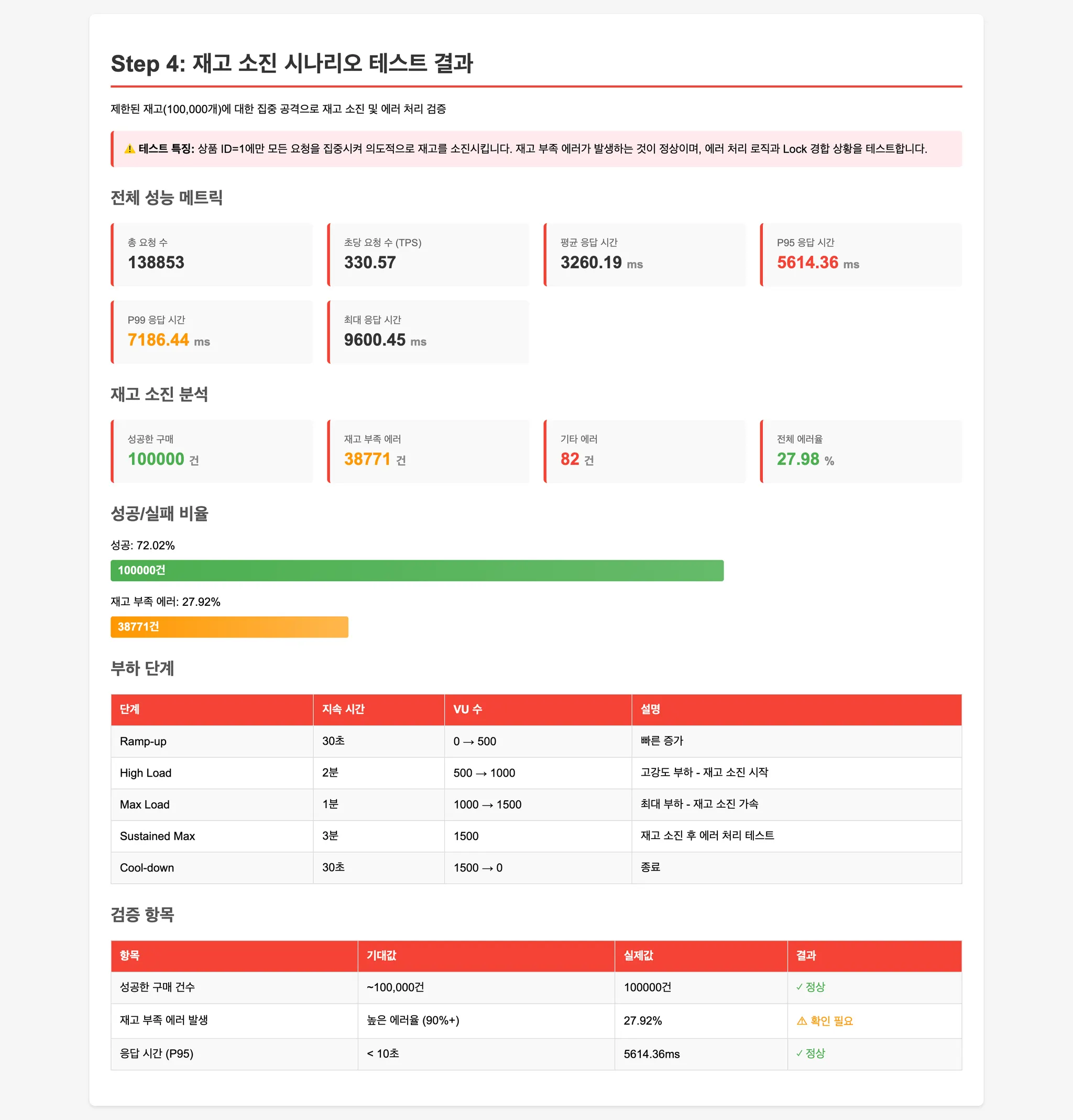
Step 4: 재고 소진 상황 (에러 처리 검증)
단일 상품에 초고강도 부하를 가해 재고를 빠르게 소진시킵니다.
재고 부족 시 에러 처리가 정상적으로 동작하는지 검증합니다.
테스트 환경
- 초기 재고: 각 상품당 100,000개
- VU (Virtual Users): 10~1,500 (시나리오별 상이)
- 총 테스트 시간: 약 33분
MySQL의 비관적 락
구현
@Transactional
fun decreaseStock(commands: List<PurchaseProductCommand>): List<PurchaseProductResult> {
val products = productRepository.findAllByIdsWithLock(commands.map { it.productId })
for (product in products) {
val quantity = commands.find { it.productId == product.id }!!.amount
product.decrease(quantity)
}
return products.map { PurchaseProductResult(it.id) }
}interface ProductRepository : JpaRepository<Product, Long>, ProductBulkInsertRepository {
// 데드락 방지를 위해 정렬
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("SELECT p FROM Product AS p WHERE p.id IN :ids ORDER BY p.id")
fun findAllByIdsWithLock(@Param("ids") ids: List<Long>): List<Product>
}
Hibernate: select p1_0.id,p1_0.product_code,p1_0.created_at,p1_0.deleted_at,p1_0.name,p1_0.owner_id,p1_0.product_price,p1_0.product_currency_code,p1_0.stock,p1_0.updated_at
from products p1_0
where p1_0.id in (?,?,?)
order by p1_0.id for updateJPA의 @Lock(LockModeType.PESSIMISTIC_WRITE)를 사용하여 비관적 락을 구현하였습니다.
테스트 결과
SQL UPDATE 문
구현
override fun reserve(vararg changes: StockChange) {
val sorted = changes.sortedBy { it.productId }
val reserved = mutableListOf<StockChange>()
sorted.forEach { change ->
val updated = jpaProductRepository.updateProductStock(
change.productId,
-change.quantity,
)
if (updated == 0) {
reserved.forEach { r ->
jpaProductRepository.updateProductStock(r.productId, r.quantity)
}
throw ProductOutOfStockException()
}
reserved.add(change)
}
}@Transactional
@Modifying
@Query("UPDATE Product p SET p.stock = p.stock + :quantity WHERE p.id = :productId AND p.stock + :quantity >= 0")
fun updateProductStock(
@Param("productId") productId: Long,
@Param("quantity") quantity: Long,
): IntLock을 사용하지 않고 SQL UPDATE 문의 WHERE 조건으로 동시성을 제어하는 방식입니다.
p.stock + :quantity >= 0 조건을 통해 재고가 부족하면 업데이트가 반영되지 않고, 영향받은 행 수(0)를 반환하여 재고 부족을 감지합니다. 이미 성공한 차감은 보상 로직으로 롤백합니다.
테스트 결과
Redis의 Named Lock
구현
fun decreaseStock(commands: List<PurchaseProductCommand>): List<PurchaseProductResult> {
val keys = commands.map { PRODUCT_PREFIX + it.productId }.toTypedArray()
return lockRepository.executeWithLock(*keys) {
val products = productRepository.findAllById(commands.map { it.productId }).toList()
for (product in products) {
val quantity = commands.find { it.productId == product.id }!!.amount
product.decrease(quantity)
}
productRepository.saveAll(products).map { PurchaseProductResult(it.id) }
}
}@Component
class RedisLockRepositoryImpl(
private val redissonClient: RedissonClient
) : LockRepository {
override fun <T> executeWithLock(vararg keys: String, action: () -> T): T {
val locks = keys.sorted().map { redissonClient.getLock(it) }.toTypedArray()
val multiLock = redissonClient.getMultiLock(*locks)
// 3초 대기, 30초마다 Lock을 갱신
return if (multiLock.tryLock(3, -1, TimeUnit.SECONDS)) {
try {
action()
} finally {
runCatching { multiLock.unlock() }
}
} else {
throw RuntimeException("Lock 획득 실패")
}
}
}Redisson의 MultiLock을 사용하여 분산 락을 구현하였습니다.
테스트 결과
Redis의 Atomic을 활용한 재고관리
구현
fun decreaseStock(commands: List<PurchaseProductCommand>): List<PurchaseProductResult> {
val stockItems = commands.map {
StockItem(
productId = it.productId, quantity = it.amount
)
}
try {
stockRepository.decreaseStock(*stockItems.toTypedArray())
} catch (e: Exception) {
val event = FailedProductStockDecreasedEvent(stockItems.map {
FailedProductStockDecreasedEvent.ProductStock(
productId = it.productId, stock = it.quantity
)
})
applicationEventPublisher.publishEvent(event)
throw e
}
return commands.map { PurchaseProductResult(it.productId) }
}override fun decreaseStock(vararg productItems: StockItem) {
val batch = redisson.createBatch(
BatchOptions.defaults()
// 순차적으로 실행 원자성 보장 X
.executionMode(BatchOptions.ExecutionMode.IN_MEMORY)
.responseTimeout(3, TimeUnit.SECONDS)
)
// 데드락 방지를 위해 정렬
productItems.sortedBy { it.productId }.forEach {
batch.getAtomicLong(generateKey(it.productId))
.addAndGetAsync(-it.quantity)
}
val result = batch.execute().responses.map { it as Long }
if (result.any { it < 0 }) throw ProductOutOfStockException()
}
private fun generateKey(id: Long): String {
return PRODUCT_KEY_PREFIX + id
}Redisson의 batch를 활용하여 Redis에 한 번에 데이터를 전송하는 파이프라인으로 구현하였습니다.
테스트 결과
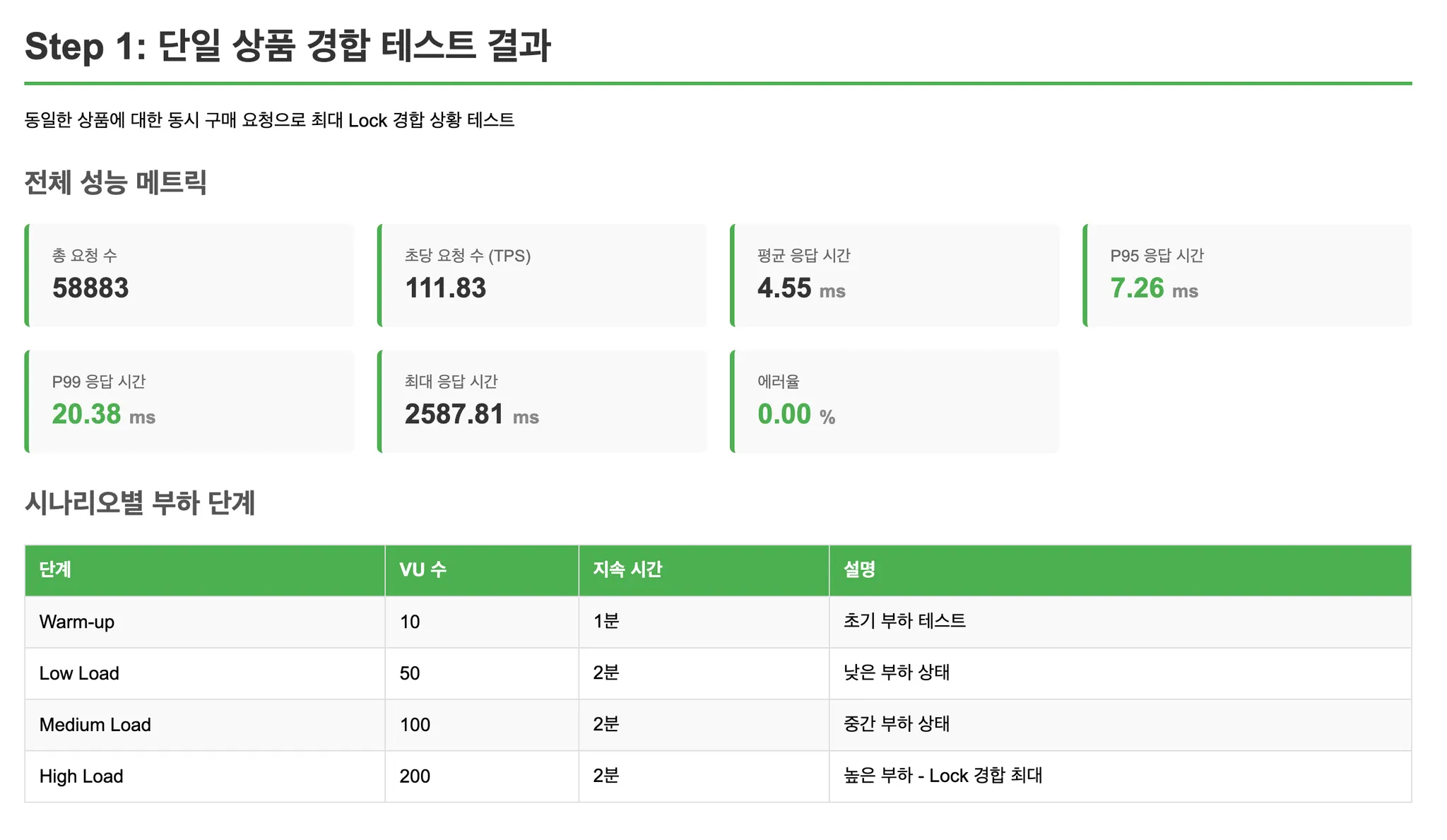
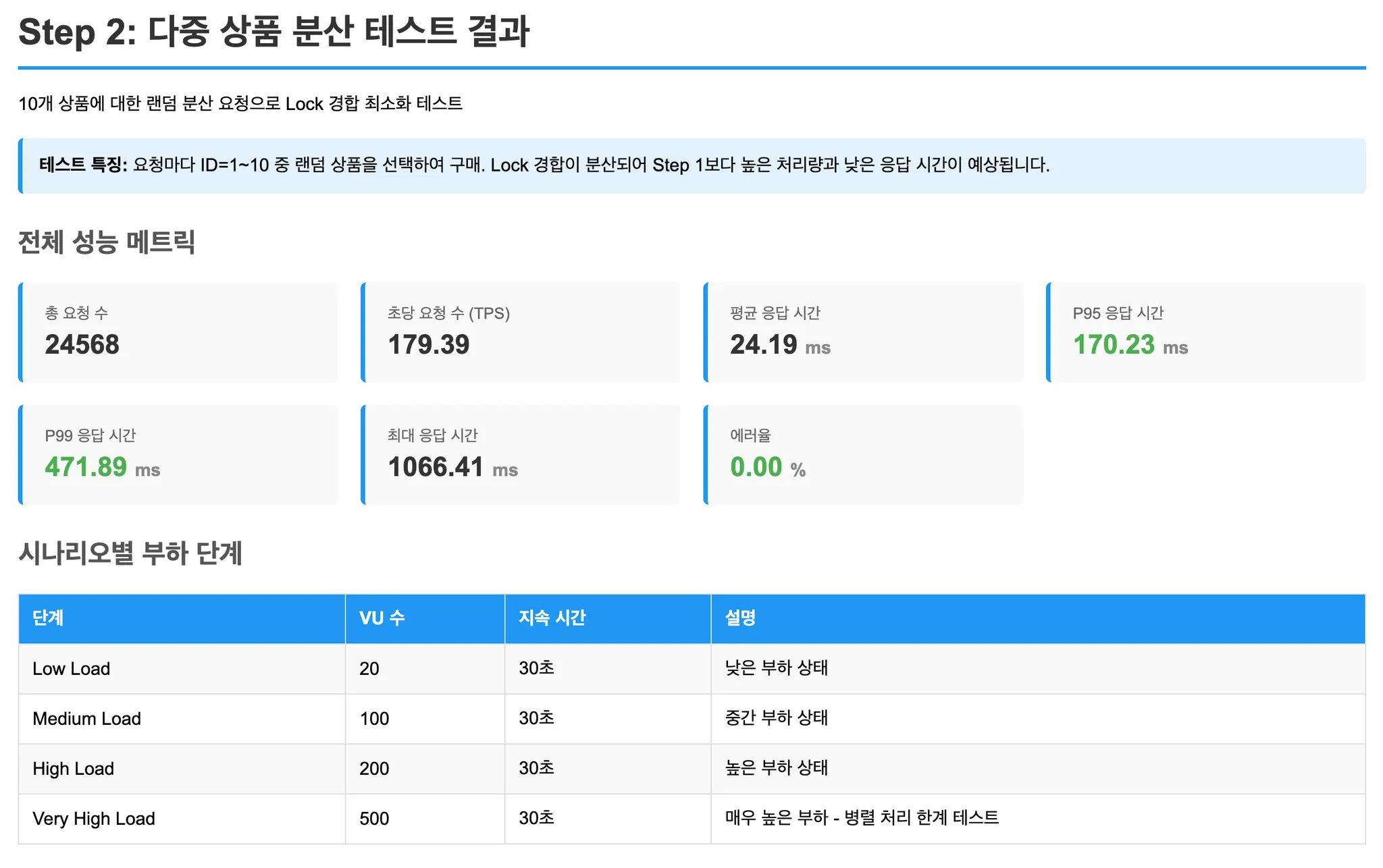
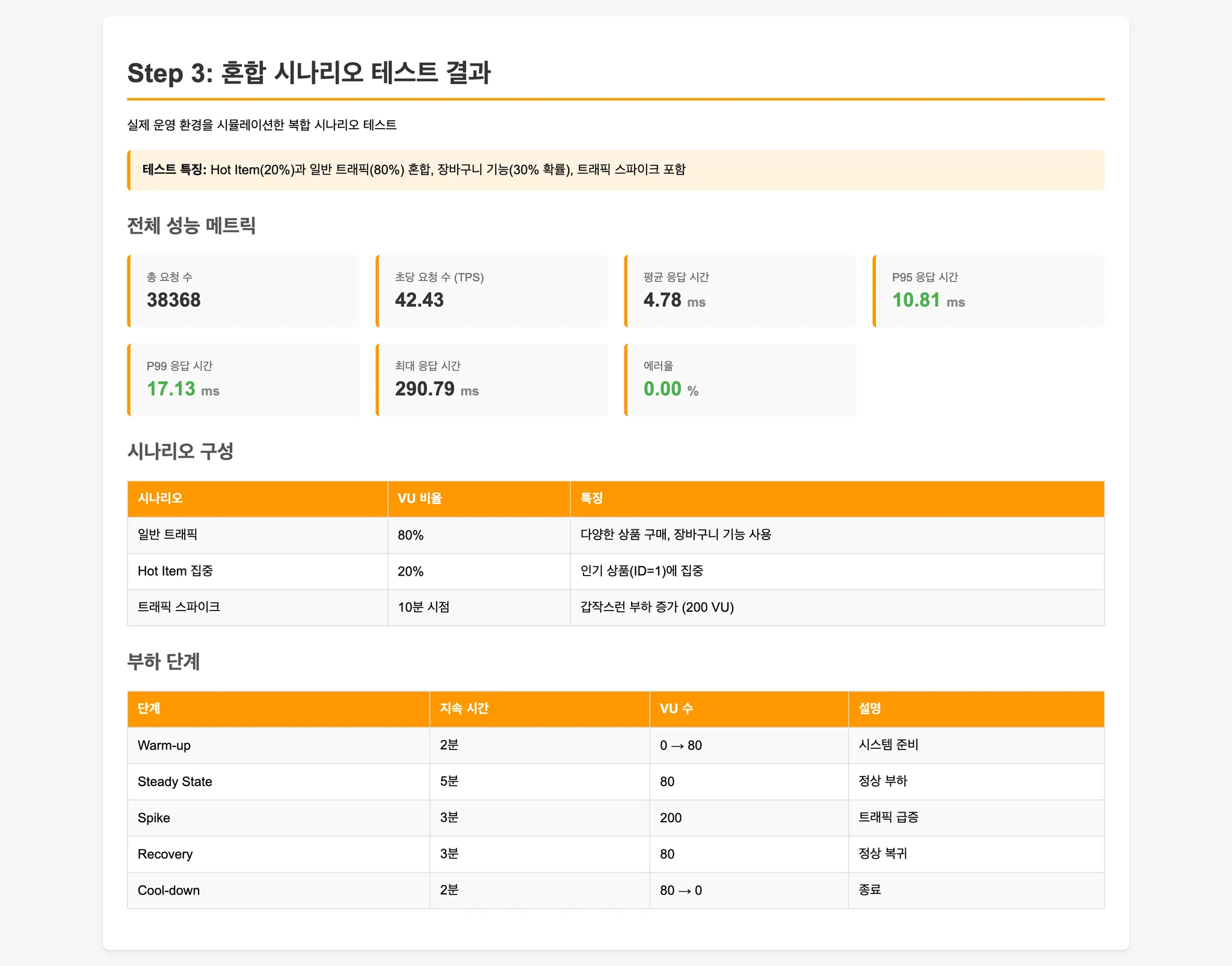
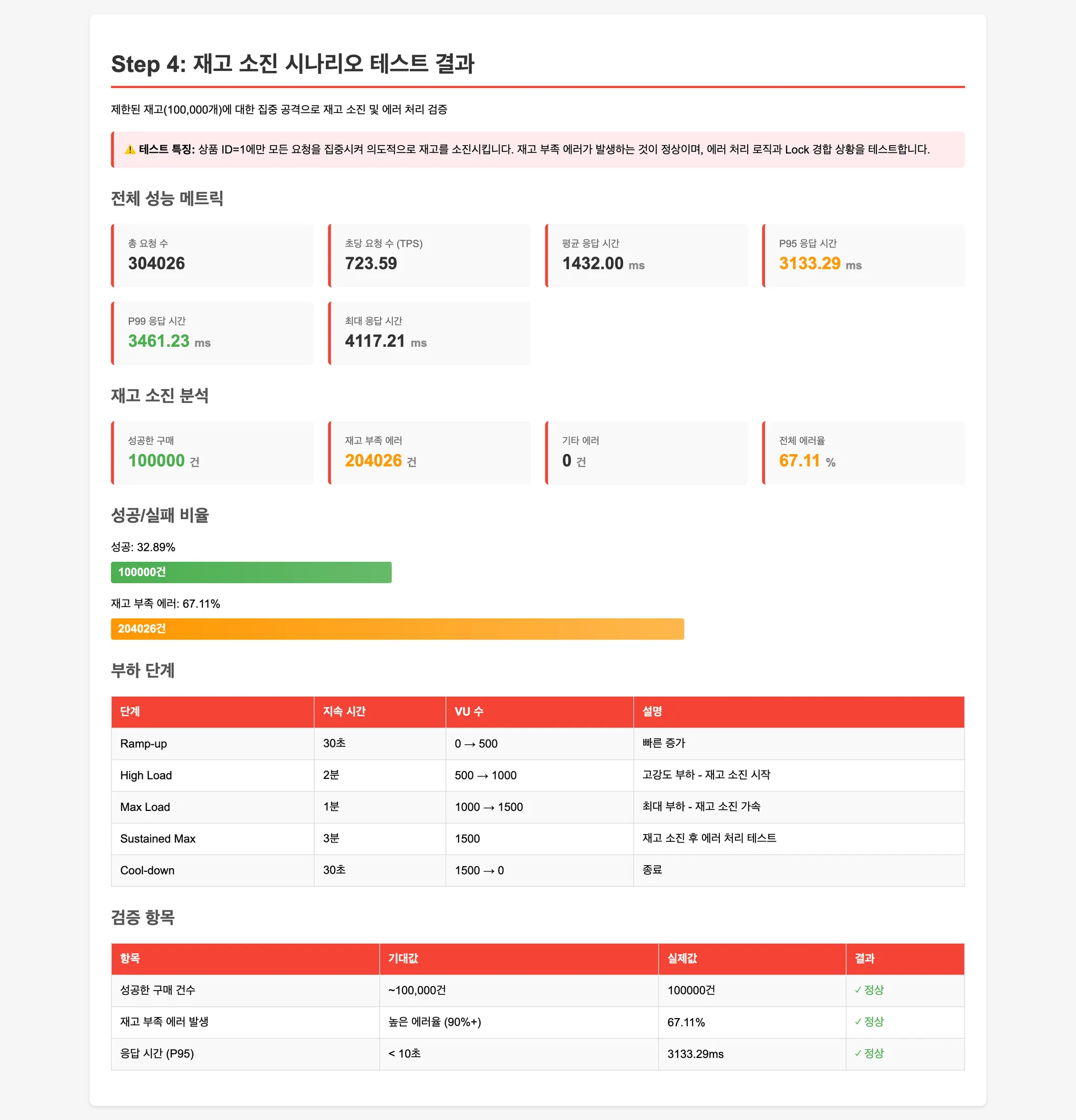
성능 테스트 결과
- Step 1 (단일 상품 집중): 모든 방식에서 Lock 경합으로 인한 성능 저하 발생. Redis Atomic이 가장 우수한 성능 유지.
- Step 2 (다중 상품 분산): Lock 경합이 분산되면서 모든 방식의 TPS가 크게 향상. 비관적 락의 상대적 성능 개선.
- Step 3 (실제 운영 환경): Hot Item과 일반 트래픽이 혼재된 환경에서 Redis Atomic이 안정적인 성능 유지.
Step 4: 재고 소진 테스트 비교
| 구분 | MySQL 비관적 락 | Redis Named Lock | Redis Atomic | SQL UPDATE |
|---|---|---|---|---|
| 평균 응답시간 | 1955.44 ms | 3260.19 ms | 1432.00 ms | 2194.55 ms |
| P95 응답시간 | 3719.01 ms | 5614.36 ms | 3133.29 ms | 4599.52 ms |
| P99 응답시간 | - | 7186.44 ms | 3461.23 ms | 5847.54 ms |
| 최대 응답시간 | 11243.15 ms | 9600.45 ms | 4117.21 ms | 9495.83 ms |
| 평균 TPS | 540.24 req/s | 330.57 req/s | 723.59 req/s | 483.71 req/s |
각 방식의 병목 지점
같은 상품에 동시에 100명이 구매하면, 어떤 방식이든 순서를 정해야 합니다. 그 "순서를 정하는 비용"이 각각 다릅니다.
MySQL 비관적 락 — 락 보유 시간이 김
SELECT FOR UPDATE로 행을 잠그고 → 애플리케이션에서 로직을 처리하고 → UPDATE하고 → 커밋할 때까지 다른 요청은 전부 대기합니다. 락을 잡고 있는 시간이 트랜잭션 전체 구간이라, 대기 큐가 깊어질수록 응답시간이 급격히 올라갑니다.
SQL UPDATE — 보상 롤백 비용
UPDATE 한 문장으로 끝나서 락 보유 시간 자체는 짧습니다. 하지만 여러 상품을 한 번에 구매할 때 N번째 상품에서 재고 부족이 나면, 앞서 성공한 1~(N-1)번 상품의 차감을 되돌리는 UPDATE를 추가로 쳐야 합니다. 재고가 소진되는 구간에서 이 보상 쿼리들이 쌓이면서 비관적 락(1955ms)보다 오히려 느린 결과(2194ms)가 나왔습니다.
Redis Named Lock — 이중 네트워크 통신
Redis에서 락을 잡고 → MySQL에서 데이터를 읽고 쓰고 → 다시 Redis에서 락을 해제합니다. 요청 하나마다 Redis ↔ App ↔ MySQL을 왕복해야 해서, 네트워크 비용이 두 배로 듭니다.
Redis Atomic — 거의 없음 (대신 복잡도가 높음)
메모리에서 원자적 연산으로 처리하니 락 대기도 없고 디스크 I/O도 없습니다. batch 파이프라이닝으로 네트워크 비용도 최소화됩니다. 가장 빠르지만, Redis와 MySQL 간 데이터 정합성을 맞추는 보상 로직(이벤트 처리, 음수 복구 등)을 직접 구현해야 하는 트레이드오프가 있습니다.
공통: MySQL 방식이 Redis Atomic보다 느린 근본적인 이유
MySQL은 트랜잭션을 커밋할 때마다 디스크에 데이터를 써야 합니다(WAL 로그, redo log flush 등). 반면 Redis Atomic은 모든 연산이 메모리에서 처리됩니다. 이 디스크 기반 vs 메모리 기반의 차이가 TPS 격차의 핵심입니다.
인사이트
Redis가 무조건 빠른 것이 아니라 어떻게 사용하느냐가 중요합니다. Named Lock은 이중 네트워크 구조로 인해 단순 재고 차감에서는 오히려 MySQL 비관적 락보다 느리지만, 여러 자원에 걸친 복잡한 트랜잭션이나 추상화된 작업 단위를 제어할 때 더 효율적으로 사용할 수 있습니다.
결론
결국 규모에 맞게 설계하는 것이 중요합니다.
중저 규모: MySQL 비관적 락
- 구현이 간단하고 정합성 보장이 확실함
- 단일 상품 집중 상황에서도 540 TPS면 충분한 경우가 많음
- 추가 인프라 없이 동작
대규모: Redis Atomic
- 높은 TPS가 필수적인 환경
- MySQL 정합성 관리 복잡도를 감수할 만한 가치가 있을 때
- 이벤트 기반 아키텍처 구축 가능한 팀
기술 선택은 "무엇이 더 빠른가"가 아니라 "우리 상황에 무엇이 적합한가"로 접근해야 합니다.
