개요
프로젝트 Memes의 주간, 월간, 총 좋아요 수에 따른 리더보드를 구현하려고 한다.
JPQL에서 QueryDSL 그리고 Redis의 Sorted Set으로 변경되기 까지의 과정을 적어보려고 한다.
JPQL 사용, 잘못된 Query
@Query("SELECT ms FROM Memes ms WHERE ms.createdAt >= :time ORDER BY ms.likeCount DESC")
@EntityGraph(attributePaths = {"meme"})
List<Memes> findTopMemesByLikeCountForPeriod(Pageable pageable, LocalDateTime time);- 기간에 따른 인기차트를 DB에서 가져오는 JPQL 코드
- 문제는 기간의 기준이 좋아요가 기준이 아닌 게시물의
createdAt즉 생성 날짜라는 것이다.- 우리의 API는 “빌보드 16주차 1위” 과 같은 문장을 만들 수 없다는 의미다.
- 위와 같이 16주차 동안 1위를 유지하려면
createdAt이 기준이 아닌, 특정 기간 동안 받은likeCount즉 좋아요 수를 기준으로 작성해야한다.
해결 방안
Memes에다가 주간 카운트 필드랑 월간 카운트 필드를 만드는 것은 어떨까?- 엄청난 조회가 발생할 수 있다고 생각했다.
Memes의 튜플 하나당 쿼리가 하나씩 나가는 것이기 때문에 조회 한 번에 엄청난 양의 쿼리가 발생할 수 있다.
- 엄청난 조회가 발생할 수 있다고 생각했다.
Group By를 활용?- 굳이
Memes에서SELECT를 할 것이 아니라,Like테이블에서 GROUP BY를 통해서 인기차트를 구현하면 되는 것 아닌가? - 쿼리 한 번으로, 인기차트를 뽑아올 수 있을 것 같다.
- 굳이
QueryDsl을 통한 해결
@Override
public List<MemesInfo> findTopMemesByLikeCountForPeriod(LocalDateTime time) {
return jpaQueryFactory.select(memesQDtoFactory.qMemesInfoSetLike())
.from(like)
.join(like.memes, memes)
.groupBy(memes.id)
.where(like.createdAt.goe(time))
.orderBy(memes.count().desc())
.limit(TOP_TEN)
.fetch();
}Like을 테이블에서memesId를 통해 그룹화 한다음 집계함수Count를 활용하여, 좋아요 수 내림차순으로 구한다.WHERE절을 통해서,LIKE튜플의 생성 날짜를 기준으로 튜플들을 가져오게 된다.
JOIN을 통해서memesId를 활용해LIKE와MEMES테이블에서 원하는 칼럼을LIMIT를 통해서 10개만 가져온다.- API마다 하나의 쿼리를 보낼 수 있게 되었다. 하지만
JOIN,GROUP BY,ORDER BY,LIMIT등 너무 많은 연산이 들어가서 데이터가 많아지면 DB에 부하가 생길 수 있을 것 같다는 생각을 했다.
해결 방안
- DB의
VIEW를 활용하는 방식은 안될까?- DB
VIEW를 활용하여, 집계함수COUNT가 가장 높은 상위 10개를 DB 차원에서 지속적으로 업데이트 하는 것- 부하가 심할까? 실현 가능한 것인가?
- DB
- 캐시를 사용하는 방법
- 데이터의 변화는 적은데 조회는 빈번한 데이터
- 순위는 조회는 빈번한데 변화는 적은가?
- 좋아요가 적게 쌓이는 상황, 즉 사용자가 적을 경우에는 순위 변동이 클 수 있다.
- 하지만 사용자가 많아져 좋아요가 충분하게 쌓여있는 상황일 경우에는, 좋아요 하나하나가 순위에 큰 영향을 미칠 가능성이 적다.
- Sorted Set을 활용한 방법
- Redis의 Sorted Set을 활용하는 방법으로 리더보드를 구현할 때 대중적으로 활용되고 있다.
- 책 “개발자를 위한 레디스” 에서 리더보드를 구현하는 방법을 사용하기로 했다.
- 요약하면, Key 값을
날짜, Value를memesId, Score를LikeCount로 하여 Redis에 저장한다. - 주간, 월간은 Redis의
ZUNIONSTORE를 활용하여 일주일, 한달치 Key를 결합한 후, 저장하여 사용자에게 반환하면 된다.
- 요약하면, Key 값을
Sorted Set을 통한 해결
Redis Sorted Set
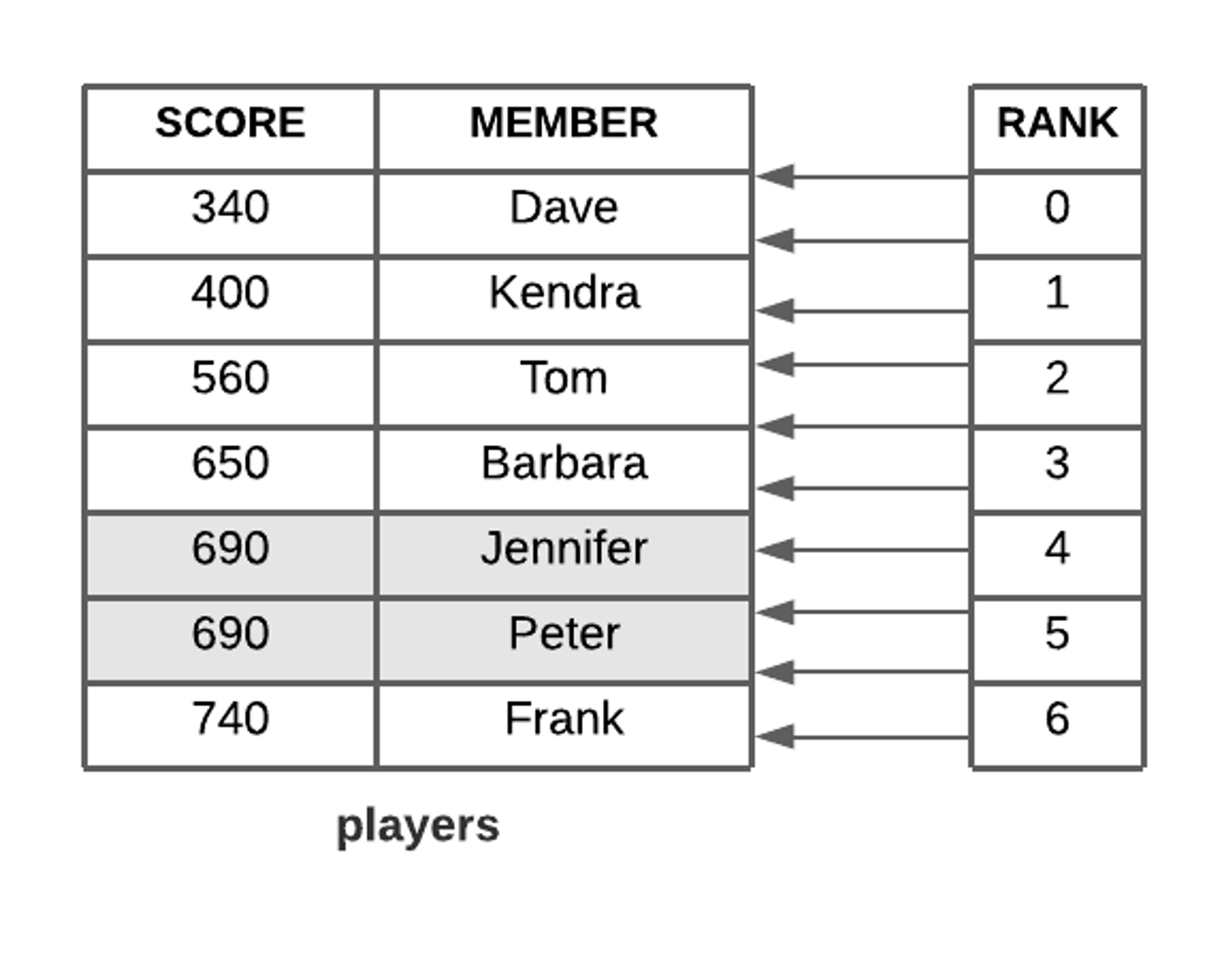
- 스코어(Score) 값에 따라 정렬되는 고유한 문자열의 집합이다.
- 스코어는 배정밀도 부동소수점 숫자를 문자열로 표현한 값이어야 한다.
- 모든 아이템은 스코어-값 쌍을 가지며, 저장될 때 부터 스코어 값으로 정렬돼 저장된다.
- 정렬은 Score의 오름차순으로 정렬되어 있다.
- 같은 스코어를 가진 아이템은 데이터의 사전 순으로 정렬돼 저장된다.
- 데이터는 중복 없이 유일하게 저장되므로 set과 유사하다고 볼 수 있다.
- 각 아이템은 스코어라는 데이터에 연결돼 있어 이 점에서는 hash와 유사하다고 볼 수 있다.
{Key} : {Sorted Set : {Value : Score}}형태로 되어있다.
설계
- 일간, 주간, 월간에 대한 리더보드(순위표) 구현 가능
- Sorted Set Key :
DATE, Value :MemesId, Score :LIKE_COUNTDATE를 일주일 전 혹은 한달 전을 기준으로 합계를 계산하여, 랭킹을 매기는 방식- 구현 가능한 방법, 따라서 해당 방법을 적용하면 될 듯 하다.
- 일, 주, 월간 Key를 생성
- Key는 언제 업데이트?
- 조회시? 좋아요 눌렀을 시?
- 조회시 생성하면, 좋아요 눌렀을 때는 어떻게 함?
- 좋아요 눌렀을 때 생성하면, 조회시 어떻게 함?
- 둘 다?
- 예외를 활용?
- 다형성을 활용? clean 코드 최근에 배운 기술
- 조회시? 좋아요 눌렀을 시?
- Value는 언제 업데이트?
- 조회시? 좋아요 눌렀을 시?
- 조회시 생성하면, 좋아요 눌렀을 때는 어떻게 함?
- 좋아요 눌렀을 때 생성하면, 조회시 어떻게 함?
- 조회시 업데이트시 둘 다?
- 조회시? 좋아요 눌렀을 시?
- 일간은 변하는 데이터
- 일간을 제외한 주간, 월간은 변하지 않는 데이터
- Key는 언제 업데이트?
- 주간 월간 랭킹을 구할 때마다
ZUNION을 활용하면 Redis에 부하가 가지 않을까?ZUNION을 활용하면 그냥 합쳐주지만 이라는 시간복잡도가 존재하기 때문에 매 요청마다ZUNION을 활용하는 건 좋은 방법같지 않다.- 첫 조회가 일어날 때만 오늘을 제외한 기간까지
ZUNION을 해두고 이후 조회마다ZUNION을 실행하면서 조회를 할까? - 첫 조회가 발생할 때, 월간, 주간, 일간 조회를 생성하고, 좋아요를 누를 때 마다 월간, 주간, 일간 랭킹에 변동을 넣는다.
- 결론은 Key에 대한 첫번째 접근, 즉 처음으로 조회랑 좋아요를 누르거나 취소했을 때 Key를
ZUNION하여 주간과 월간 Key를 생성하도록 설계했다.
구현
RedisConfig
@Configuration
@EnableRedisRepositories
// Transaction을 활용할 것을 어노테이션을 통해서 지정해준다.
**@EnableTransactionManagement**
public class RedisConfig {
@Value("${spring.redis.host}")
private String host;
@Value("${spring.redis.port}")
private int port;
// Lettuce 라이브러리를 통해서 Redis와 연결합니다.
@Bean
public RedisConnectionFactory redisConnectionFactory() {
return new LettuceConnectionFactory(new RedisStandaloneConfiguration(host, port));
}
// RedisTemplate로 저장할 Redis의 Key와 Value의 직렬화, 역직렬화할 형식을 지정합니다.
@Bean(name = "rankingRedisTemplate")
public RedisTemplate<String, Long> rankingRedisTemplate() {
RedisTemplate<String, Long> redisTemplate = new RedisTemplate<>();
redisTemplate.setKeySerializer(new StringRedisSerializer());
**redisTemplate.setValueSerializer(new Jackson2JsonRedisSerializer(Long.class));**
// Redis을 @Transactional 지원하도록 한 설정입니다.
redisTemplate.setEnableTransactionSupport(true);
**redisTemplate.setConnectionFactory(redisConnectionFactory());**
return redisTemplate;
}
// Redis Sorted Set을 사용하기 위한 ZSetOperations 객체를 반환하는 Bean 입니다.
@Bean(name = "rankingZSetOperations")
public ZSetOperations<String, Long> rankingZSetOperations(
@Qualifier("rankingRedisTemplate") RedisTemplate<String, Long> redisTemplate) {
return redisTemplate.opsForZSet();
}
// 'Transaction management는 PlatformTransactionManager를 필요로 하지만,
// Spring Data Redis는 PlatformTransactionManager의 구현체를 포함하고 있지 않다.
// 다른 구현체인 JpaTransactionManager를 빌려서 Transaction을 설정했다.
@Bean
public PlatformTransactionManager transactionManager() {
return new JpaTransactionManager();
}
}Lettuce를 활용한 Redis 에 접근을 위한Bean설정 코드Redis에 접근할 때 직렬화와 역직렬화를 설정할RedisTemplate설정 후 반환 코드Sorted Set을 제어하는ZSetOperations객체 반환 코드- Redis 의 트랜잭션 사용을 설정하는 코드가 구현되어 있다.
-
Redis는 롤백을 지원하지 않는다.
-
단지 명령어를 하나의 큐에 넣고 큐에 쌓인 명령어를 실행되는 동안 다른 명령어가 실행되지 않음을 보장할 뿐이다.
Redis에 대한 테스트를 진행할 때는, 롤백을 통해 Redis가 테스트 전과 후가 같은 상황을 기대할 수 없습다. 따라서 배포 환경과 테스트 환경의 Redis를 분리하고 Redis의 단위 테스트 시작전에,
redisConnectionFactory.getConnection().flushAll();로 Redis를 비우는 작업을 하여 단위 테스트를 진행하고 있다.
-
RankingService
- Sorted Set 을 제어하는
ZSetOperations의 메서드들의 공식문서이다.
ZSetOperations (Spring Data Redis 3.3.0 API)
@RequiredArgsConstructor
@Service
public class RankingService {
private final String PREFIX = "LIKE_RANKING_DATE::";
private final String POSTFIX_WEEK = "::WEEK";
private final String POSTFIX_MONTH = "::MONTH";
private final Long TOP_TEN = 9L;
private final ZSetOperations<String, Long> rankingZSet;
@Transactional
public void increaseTodayMemesLikeCountFromMemesId(Long memesId) {
String key = PREFIX + LocalDate.now();
increaseMemesLikeCountForToday(key, memesId);
increaseMemesLikeCountForLastWeek(key, memesId);
increaseMemesLikeCountForLastMonth(key, memesId);
}
private void increaseMemesLikeCountForToday(String key, Long memesId) {
rankingZSet.incrementScore(key, memesId, 1);
}
private void increaseMemesLikeCountForLastWeek(String key, Long memesId) {
key += POSTFIX_WEEK;
unionMemesIfKeyNotExists(key, 7);
rankingZSet.incrementScore(key, memesId, 1);
}
private void increaseMemesLikeCountForLastMonth(String key, Long memesId) {
key += POSTFIX_MONTH;
unionMemesIfKeyNotExists(key, 30);
rankingZSet.incrementScore(key, memesId, 1);
}
private void unionMemesIfKeyNotExists(String key, int day) {
if (isNotExistedKey(key)) {
unionMemesFromKeyAndDay(key, day);
}
}
private boolean isNotExistedKey(String key) {
Set<Long> check = rankingZSet.range(key, 0, 1);
return check.isEmpty();
}
private void unionMemesFromKeyAndDay(String key, int day) {
List<String> keyList = new ArrayList<>();
LocalDate today = LocalDate.now();
for (int i = 1; i < day; i++) {
LocalDate date = today.minusDays(i);
keyList.add(PREFIX + date);
}
rankingZSet.unionAndStore(key, keyList, key);
}
@Transactional
public void decreaseTodayMemesLikeCountFromMemesId(Long memesId) {
String key = PREFIX + LocalDate.now();
decreaseMemesLikeCountForToday(key, memesId);
decreaseMemesLikeCountForLastWeek(key, memesId);
decreaseMemesLikeCountForLastMonth(key, memesId);
}
private void decreaseMemesLikeCountForToday(String key, Long memesId) {
rankingZSet.incrementScore(key, memesId, -1);
}
private void decreaseMemesLikeCountForLastWeek(String key, Long memesId) {
key += POSTFIX_WEEK;
unionMemesIfKeyNotExists(key, 7);
rankingZSet.incrementScore(key, memesId, -1);
}
private void decreaseMemesLikeCountForLastMonth(String key, Long memesId) {
key += POSTFIX_MONTH;
unionMemesIfKeyNotExists(key, 30);
rankingZSet.incrementScore(key, memesId, -1);
}
@Transactional(readOnly = true)
public List<MemesRankDto> findTopTenMemesLikeCountForWeek() {
String key = PREFIX + LocalDate.now() + POSTFIX_WEEK;
unionMemesIfKeyNotExists(key, 7);
Set<ZSetOperations.TypedTuple<Long>> rankTuple = rankingZSet.reverseRangeWithScores(key, 0, TOP_TEN);
List<MemesRankDto> result = rankTuple.stream().map(MemesRankDto::of).toList();
return result;
}
@Transactional(readOnly = true)
public List<MemesRankDto> findTopTenMemesLikeCountForMonth() {
String key = PREFIX + LocalDate.now() + POSTFIX_MONTH;
unionMemesIfKeyNotExists(key, 30);
Set<ZSetOperations.TypedTuple<Long>> rankTuple = rankingZSet.reverseRangeWithScores(key, 0, TOP_TEN);
List<MemesRankDto> result = rankTuple.stream().map(MemesRankDto::of).toList();
return result;
}
}- 중요한 점
- 조회와 좋아요에 대한 업데이트가 생겼을 때, Key가 없으면 업데이트하는 코드
- 좋아요를 눌렀을 때 일간, 주간, 월간에 대한 Value(MemesId)에 대한 업데이트가 일어난다.
후기
클린 코드를 읽고나서 코드와 사이드 이펙트와 같은 점을 곰곰히 생각하면서 작성한 첫 코드다. 당장은 나의 최선이라고 생각하는 코드지만, 나중에 혹은 당장 내일 다시보면 더럽다고 느껴질 수 있을 것 같다. 지금도 중복과 상수를 좀 더 깔끔하게 표현하는 방법이 있을까에 대한 고민을 하고 있다. 코드가 작동하기만 하면 그냥 넘어갔던 과거에 비해 변수명부터 메서드명까지 하나하나 고민하면서 짠 코드라는 점에서 성장한 것 같아서 기분이 좋기도하다.
계속해서 클린코드를 지향하면서 코드 자체가 문서가 될 수 있도록 발전하는 것이 나의 목표다
개발자는 작가다. 작가는 독자를 이해시킬 필요가 있다.
추후 고민할 점
- 코드의 중복이 많다고 느껴진다. 해당 부분의 중복을 어떡하면 줄일 수 있을까?
- 클린 코드에 의하면 코드 자체가 문서가 될 수 있게 작성해야 한다.
- 내 코드는 문서자체가 될 수있을까?에 대한 끊임없는 고민이 필요할 것 같다.
- 추후 상위 10개의 Memes에 대해 캐시를 적용하는 코드를 작성해도 좋을 것 같다.
Reference
