
Business Understanding 다음에 수행하는 Data Understanding(데이터탐색)에 대하여 알아보고자 합니다. 간단하게 Business Understanding에 대해 간단하게만 집고 넘어가본다.
Business Understanding - 가설수립
문제를 정의하고 요인을 파악하기 위해 가설을 수립힌다.
🐼 가설 수립 절차
x: feature y: target
① 해결해야 할 문제는? (목표, 관심사, y)
② y를 설명하기 위한 요인 (x)
③ 가설의 구조를 정의 (x->y)
✔ 귀무가설: 기존 연구 결과로 이어져 내려오는 정설이다. 간단하게는 차이가 없다, 연관성이 없다, 효과가 없다와 같은 보수적인 입장. 현재의 가설
ex: 매장지역(x)에 다라 수요량(y)의 차이가 없다.
✔ 대립가설: 기존의 가설과 대립하는 새로운 연구 가설이다. 간단하게는 차이가 있다, 연관성이 있다, 효과가 있다와 같은 새로운 가설.
ex: 매장지역(x)에 다라 수요량(y)의 차이가 있다.
🐼 데이터 원본 식별
가용 가능 데이터 (기존 그대로 사용, 가공하여 사용, 새로 취득 가능한 데이터)
가용 불가능 데이터 (취득불가 데이터)
Data Understanding - 데이터 탐색
EDA (Exploratory Data Analysis, 탐색적 데이터 분석)
개별 데이터의 분포, 가설이 맞는지 확인, NA & 이상치 파악
🔎 그래프, 통계량
CDA (Confirmatory Data Analysis, 확증적 데이터 분석)
탐색으로 파악한 정보를 실제 통계분석도구(가설 검정) 사용하여 증명
🔎가설검정, 실험
앞으로 진행할 내용은 언제 어떤 그래프를, 통계량을, 가설검정 방법을 사용하고 해석할지 알아보겠습니다.
(들어가기 전)
데이터는 타이타닉 데이터를 사용하고 있습니다.
- PassengerId : 승객번호
- Survived : 생존여부(1:생존, 0:사망)
- Pclass : 객실등급(1:1등급, 2:2등급, 3:3등급)
- Name : 승객이름
- Sex : 성별(male, female)
- Age : 나이
- Fare : 운임($)
- Embarked : 승선지역(Southhampton, Cherbourg, Queenstown)
단변량 분석
1. 변수가 내포하고 있는 의미는?
2. 변수가 수치형인지, 범주형인지
df['변수'].unique() : 고유한 값 반환
df['변수'].nunique() : nunique는 고유한 값 갯수 반환
df['변수'].value_counts() : 범주별 갯수 반환 type=Series
df['변수'].value_counts(normalize=True) : 0~1 사이로 표준화(비율)
3. 결측치 존재 여부 및 조치 방안
df.info() dataframe.isna().sum()
NaN 제외한 DataFrame생성: temp = df.loc[df['컬럼명'].notnull()]
4. 기초 통계량 / 도수분포표 확인
df.descrbie() df['변수'].describe()
titanic[['Pclass']].describe().T #행열전환
titanic.describe(include='all').T
titanic['Pclass'].value_counts()
titanic['Pclass'].value_counts(normalize=True)① 기초통계량, 정보의 대푯값
-
평균(mean)
-
중앙값(median)
-
최빈값(mode)
-
사분위수(Quantile)
사분위수범위(Interquartile range;IQR) = Q3-Q1
전체 자료의 50%를 포함하는 범위
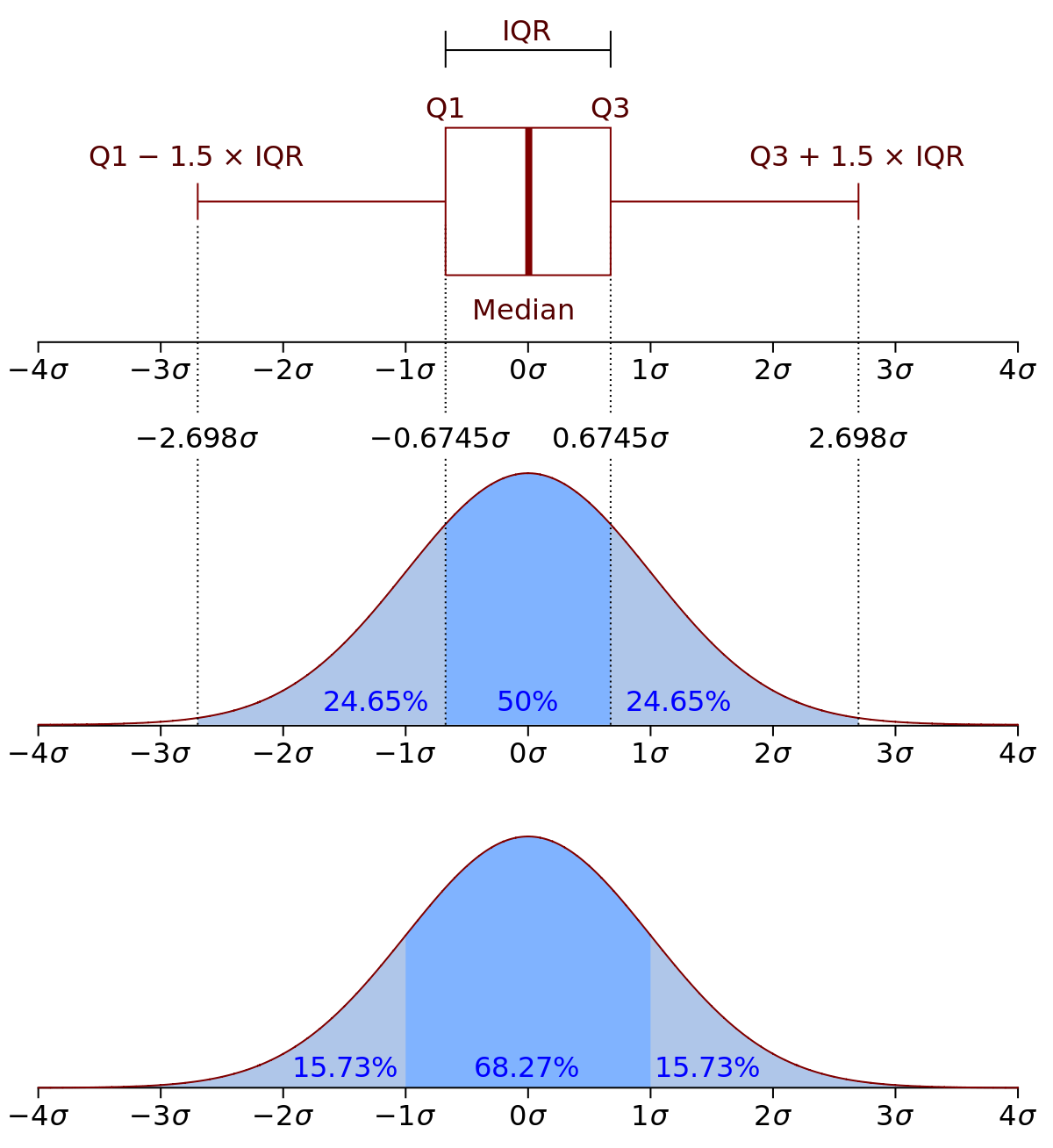

Whisker(수염) 은?
- 1.5 * IQR 범위 이내의 최소, 최대 값 (즉, 수염 범위에 포함되는 최소값, 최대값)
- Min ~ Q1(Lower Quartile)
- Q3(Upper Quartile) ~ Max
/코드 예시/
titanic['Fare'].mean()
titanic['Fare'].median()
titanic['Fare'].mode()
titanic.describe()
# ---- 결과 ----
count 714.000000 #count: NaN을 제외한 데이터갯수
mean 29.699118
std 14.526497
min 0.420000
25% 20.125000 #25%: 1사분위수(Q1)
50% 28.000000 #50%: 2사분위수(Q2)
75% 38.000000 #75%: 3사분위수(Q3)
max 80.000000
② 도수분포표
데이터를 구간으로 나누고 각 구간의 빈도를 나타낸 표
데이터타입이 category일 때
5. 시각화하기
수치형
① 기초 통계량
📌 boxplot
- 사전에 반드시 NaN을 제거 (sns.boxplot은 NaN 알아서 제외)
- vert옵션: False(횡), True(종, 기본값)
plt.boxplot(temp['Age'])
plt.boxplot(temp['Age'] , vert = False) #가로로 
② 도수분표포
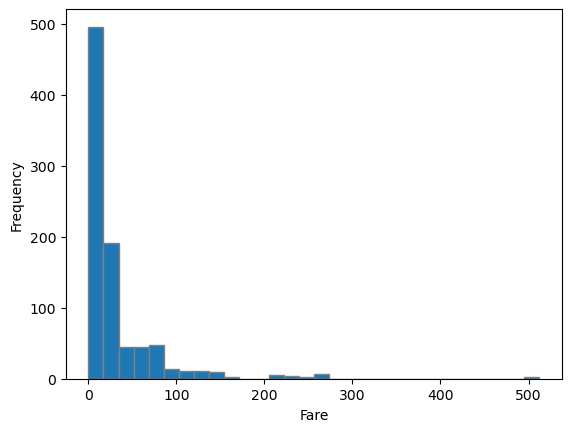
📌 histplot(histogram)
plt.hist(titanic.Age, bins = 30, edgecolor = 'gray') #x축 age의 간격을 bins로 조절
sns.histplot(x='Age', data=titanic, bins=15)[matplotlib - hist]
[seaborn - hisplot]
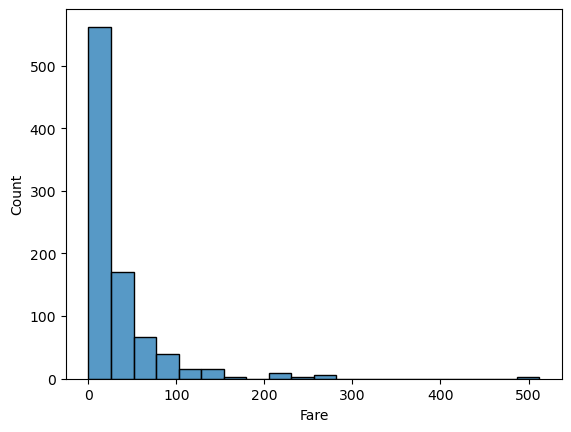
📌 kdeplot(Density plot)
- kde(Kernal Densitiy Estimation)
- 데이터 커널 밀도 추정 방식이다.
- 전체 면적은 '1'
- 면적으로 구간에 대한 확률을 추정한 것이다.
sns.kdeplot(x='Fare', data = titanic)🔥 histplot, kdeplot 같이 한번에 나타내기도 함
sns.histplot(x=titanic['Age'], kde=True, data=titanic)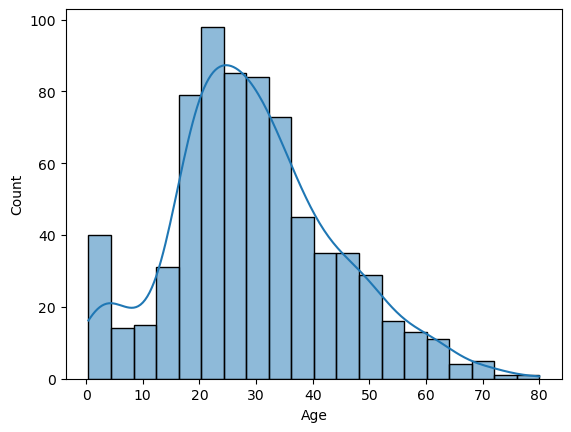
범주형
📌countplot
- plt.bar()를 이용하려면 집계한 데이터를 가지고 그래프를 그려야한다.
- sns.coutplot()은 집계와 bar plot()을 동시에 처리
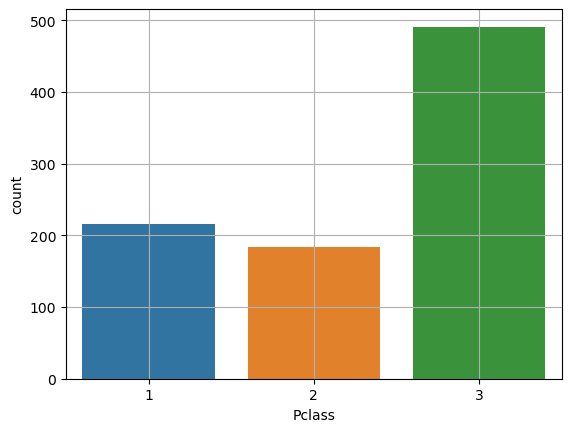
sns.countplot(x = 'Pclass', data = titanic)📌pie(Pie Chart)
- 먼저 집계를 한 후 그래프를 그려야 한다.
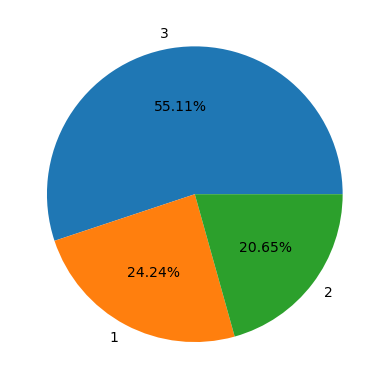
temp = titanic['Pclass'].value_counts()
plt.pie(temp.values, labels = temp.index, autopct = '%.2f%%') #소수점2자리 %붙임