브라우저에서 requests를 받을 때 웹 페이지의 유형에 따라 다른 종류의 데이터를 받아온다.
정적페이지: JSON데이터
동적페이지: HTML데이터
이번에는 selninum라이브러리 없이 데이터 가져오는 방법
진행 절차
- URL분석
- 서버에 데이터 요청
- 받아온 데이터 파싱 : json(str)>list,dict>DataFrame
- 간단한 데이터 분석 진행
1. 웹페이지분석, URL
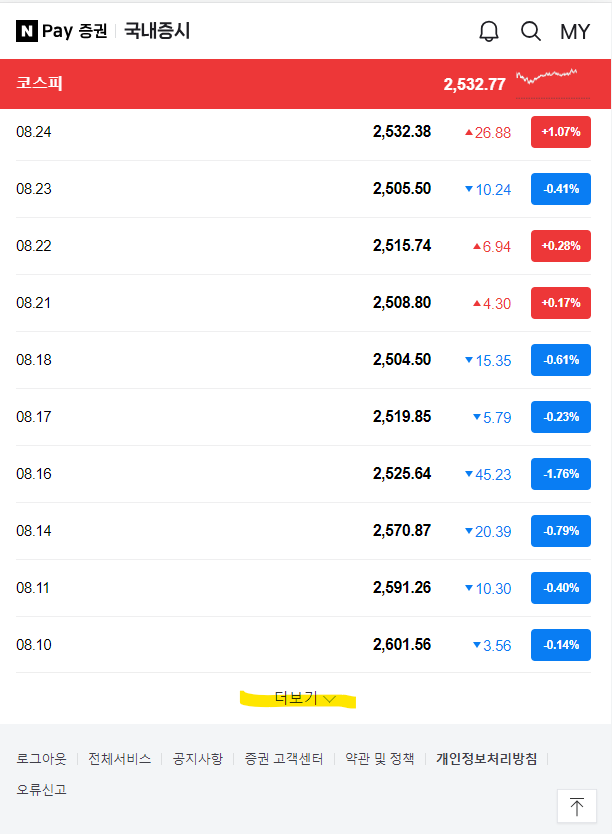
네이버 증권사이트에서 코스피, 코스닥, 환율의 일별 시세를 가져오고자 한다. 중요한 것은 어느 시점에서 데이터가 불러와지는 지를 알아내는 것이다. 아래 네이버 국내증시의 코스피를 예시로 하는데 페이지 더보기 버튼 클릭하면 데이터가 불러와진다.
URL : https://m.stock.naver.com/domestic/index/KOSPI/total
💡 TIP
PC버전보다는 모바일 화면 랜더링이 간단함으로 개발자모드를 통해 모바일버전으로 변경하여 웹페이지를 분석한다.
Fexth/XHR은?
동적페이지에서 json으로 받아온 경우의 정보를 보여준다.
개발자 모드에서 > 상단 Network탭 클릭 > clear network log (Ctrl+L)을 통해 지우고 > Filter를 Fetch/XHR을 클릭한다.
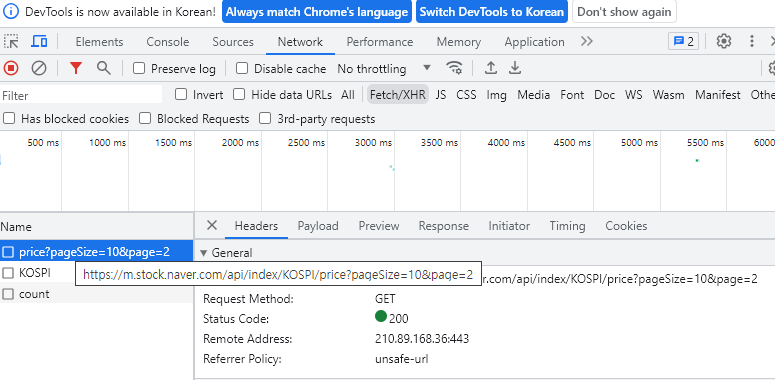
더보기를 눌러 잡힌 Reuqest URL의 정보를 확인한다.
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
import requests, json
page, pagesize = 1,60
url = f'https://m.stock.naver.com/api/index/{code}/price?pageSize={pagesize}&page={page}'2. 서버 데이터 요청
#requests라이브러리를 통해 서버에 데이터를 요청한다.
response = requests.get(url)
# 데이터 확인
rsponse #<Response [200]>
reponse.text #내용 확인
# json형태로 변경하여 data출력을 통해 형태를 먼저 파악한다. 이번 예제는 결과값이 바로 출력됨으로 따로 key값을 선택하지 않아도 된다.
data = response.json()
#데이터 항목 선택
columns = ["localTradedAt", "closePrice"]🔒 response 응답이 200이 아닌경우는?
일반적으로 <Response [403]> 이 나올 수 있다.
이는 server측에서 다양한 이유로 비정상적 접근을 막은 것이다.
보통 요청오는 useragent 값으로 판별하는 경우가 많아서 크롤링 할 때 request의 header를 변경해서 보내본다.
분석하는 웹 url로 들어가서 Network탭 > Header > Requests Header 의 항목 중에서 Referer, User-Agent 값을 복사하여 header로 설정한다.
headers={
'User-Agent': '',
'Referer': '',
}
response = request.get(url, headers=headers)3. 데이터 파싱
kospi = pd.DataFrame(data)[columns]이러한 방법으로 코스닥과 환율도 각각 구해본다.
4. 전처리
- 데이터 병합 (여러 DataFrame 결합)
- 데이터 타입 변경 (문자형 object -> 숫치형 float/int)
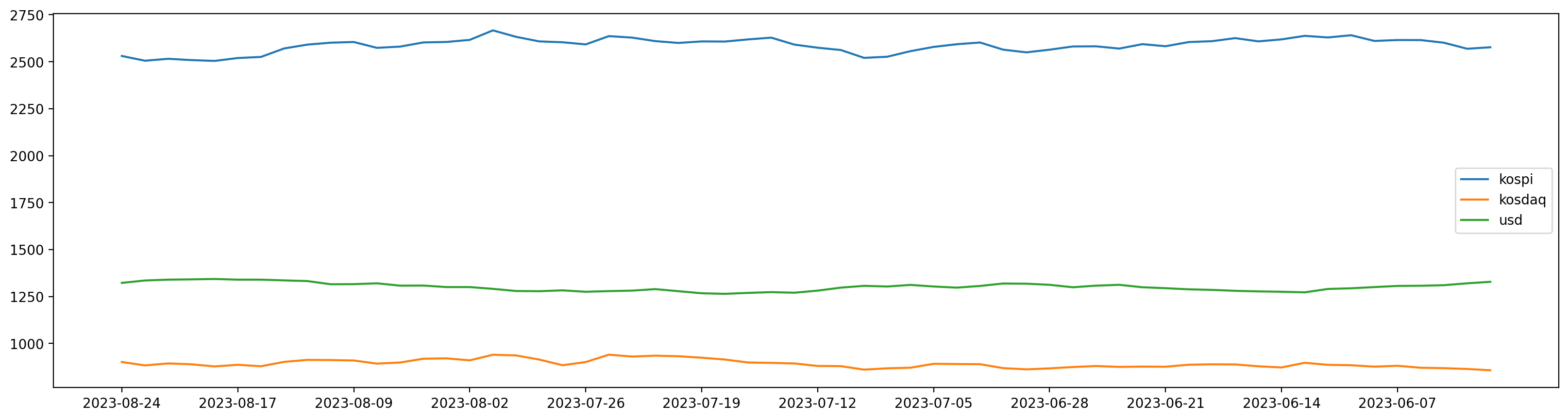
5. 시각화
%config InlineBackend.figure_formats = {'png','retina'} #해상도 높이기
plt.figure(figsize=(20,5))
plt.plot(df['date'], df['kospi'], label='kospi')
plt.plot(df['date'], df['kosdaq'] , label='kosdaq')
plt.plot(df['date'], df['usd'],label='usd')
plt.xticks(df['date'][::5]) # 날짜를 5개씩 묶음
plt.legend()
plt.show()
데이터의 범위가 재각각임으로 정규화 (min max scalling) 진행
위에와 같은 코드이지만 값에다가 minmax_scale함수를 적용
from sklearn.preprocessing import minmax_scale
plt.figure(figsize=(20,5))
plt.plot(df['date'], minmax_scale(df['kospi']), label='kospi')
plt.plot(df['date'], minmax_scale(df['kosdaq']) , label='kosdaq')
plt.plot(df['date'], minmax_scale(df['usd']), label='usd')
plt.xticks(df['date'][::5])
plt.legend()
plt.show()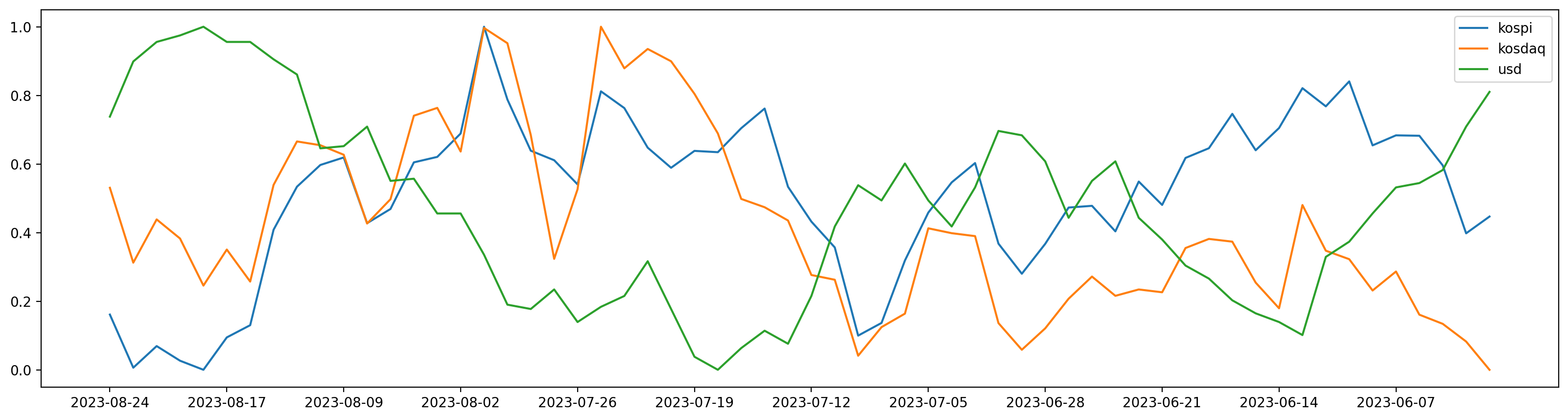
6. 상관관계 분석
피어슨 상관계수 (Pearson Correlation Coefficient)
[상관계수 해석]
- -1에 가까울수록 서로 반대방향으로 움직임
- 1에 가까울수록 서로 같은방향으로 움직임
- 0에 가까울수록 두 데이터는 관계가 없음
df.corr() 분석결과
코스피가 높으면 원달라 환율이 낮고, 코스피가 낮으면 원달러 환율이 높다.
