
이제 본격적으로 출발해 볼까요?
의미보다는 함수와 코드로 사용법을 통해 알아보도록 하겠습니다.
배열 이해
[용어]
axis: 배열의 각 축
rank: 축의 개수
shape: 축의 길이, 배열의 크기
numpy의 1차원 배열부터 3차원까지 각 축인 axis의 순서입니다.
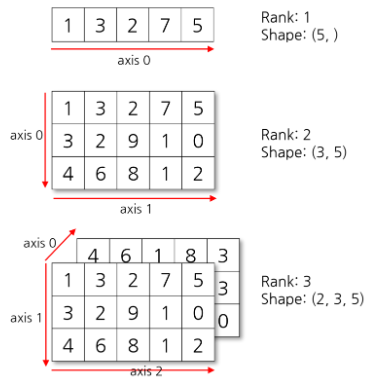
🔒 Axis0의 의미
- 배열의 첫번째 축
- 데이터의 건수
- 2차원 데이터: (1000,2)
- 10개의 값(컬럼)으로 구성된 데이터 1000개 - 3차원 데이터: (2500, 28, 28)
- 28행 28열(28X28) 크기의 2차원 데이터가 2500건
기본속성
| 속성 | 의미 | + |
|---|---|---|
| shape | 배열의 형태 확인 튜플로 표시 | - 1차원: (x, ) - 2차원: (x, y) - 3차원: (x, y, z) - 앞에서 부터 axis 0, axis 1, axis 2의 크기를 의미합니다. |
| dtype | 요소들의 자료형 변환 | array는 한 가지 자료형만 가질 수 있다. |
| ndim | 배열의 차원 |
추가 내용 및 코드
import numpy as np
>>> a = np.arange(15).reshape(3, 5)
>>> a
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
>>> a.shape
(3, 5)
>>> a.ndim
2
>>> a.dtype
dtype('int32')
>>> print(a.dtype)
int32
>>> a.dtype.name
'int32'
>>> a.itemsize
8
>>> a.size
15
>>> type(a)
<class 'numpy.ndarray'>
b = np.array([6, 7, 8])
>>> b
array([6, 7, 8])
>>> print(b)
[6 7 8]👉 몰랐던 사실은 jupyter lab에서 실행해보고 있는데 print()로 출력했을 때와 자동출력 기능을 사용해서 결과 값이 나오는 거랑 종종 다른걸 볼 수 있다.
👉 np 출력 결과가 [6 7 8]은 리스트가 아님으로 콤마가 없다는 차이가 있다.
함수
| 기능 | 의미 | + |
|---|---|---|
| reshape() | 다양한 형태(shape)로 변환 *요소의 개수가 사라지지 않은 형태에서 자유롭게 변환 가능 | (m, -1) 또는 (-1, n) 처럼 사용해 행 또는 열 크기 한 쪽만 지정 가능 |
| mean() | np.mean(): 입력 가능한 형태(리스트, 튜플, 등) np array로 변환하여 평균 구함 np_array.mean(): np array변수만 사용 가능함 |
코드로 확인
a = np.array([[1, 2, 3],
[4, 5, 6]])
# 1차원 배열로 Reshape
c = a.reshape(6) # c = a.reshape(6,) 동일한 결과
print(a.reshape(1, -1))
# 선언
a = [1,2,3] # 리스트
b = (1,2,3) # 튜플
c = np.array([1,2,3]) # 배열
# 평균 구하기 : 함수
print(np.mean(a))
print(np.mean(b))
print(np.mean(c))
# 평균 구하기 : 메서드 방식
print(a.mean())
# AttributeError: 'list' object
has no attribute 'mean'
print(b.mean())
# AttributeError: 'tuple' object
has no attribute 'mean'
print(c.mean()
👉 np.mean()과 array변수.mean()의 차이를 알 수 있다.
배열 인덱싱/슬라이싱
다양한 인덱싱 표현법들이 있어 종종 헷갈린다.
♟인덱싱
- arr[0,2]
- arr[0][2]
- arr[1]
- arr[[0,2]]
- arr[[0],[2]]
- arr[[0],[2]]
- arr[[0,2],[1,2]] : arr[0,2] 와 arr[2,2]
#2차원 배열 생성
>>> a = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
>>> print(arr[0,2])
>>> print(arr[0][2])
>>> print(arr[1])
>>> print(arr[[0,2]])
>>> print(arr[[0],[2]])
>>> print(arr[[0,2],[1,2]])
# 결과
3
3
[4 5 6]
[[1 2 3]
[7 8 9]]
[3]
[2 9]♟슬라이싱
배열[행1:행N,열1:열N] 형태로 지정해 그 위치의 요소를 조회합니다.
조회 결과는 2차원 배열이 됩니다.
즉, 배열[1:M, 2:N]이라면 1 ~ M-1행, 2 ~ N-1열이 조회 대상이 됩니다.
a = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
print(a[0:2]) # print(a[0:2, :])와 동일
print(a[0, 0:2])
print(a[0:3, 1:3])
print(a[1:, 1:])
print(a[:,1]) #1차원
print(a[:,1:2]) #2차원
#결과
[[1 2 3]
[4 5 6]]
[1 2]
[[2 3]
[5 6]
[8 9]]
[[5 6]
[8 9]]
[2 5 8]
[[2]
[5]
[8]]👉 2차원 배열에서 행은 무조건 지정해야 한다. 열을 지정하려면 행을 명시해야 하지만 행만 추출할 때는 열은 지정하지 않아도 된다.
👉 마지막 1차원과 2차원의 인덱스지정으로 인한 차이를 알아둔다.
조건 조회
>>> score= np.array([[78, 91, 84, 89, 93, 65],
[82, 87, 96, 79, 91, 73]])
>>> score >= 90
array([[False, True, False, False, True, False],
[False, False, True, False, True, False]])
>>> print(score[score >= 90])
[91 93 96 91]
>>> print(score[(score >= 90) & (score <= 95)])
[91 93 91]👉 numpy에서 여러 조건연산자는 &, | 를 사용한다.
➕and 연산자를 사용했을 때의 오류
ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all()
➕ && 연산자를 사용했을 때의 오류
SyntaxError: invalid syntax
배열 연산 및 기타
| 함수 | 의미 | + |
|---|---|---|
| np.add() | 배열 더하기 | np배열 + np배열 |
| np.substarct() | 배열 빼기 | np배열 - np배열 |
| np.multiply() | 배열 곱하기 | np배열 * np배열 |
| np.divide() | 배열 나누기 | np배열 / np배열 |
| np.remainder() | 배열 나머지 | np배열 % np배열 |
| np.power() | 배열 제곱 | |
| np.T | 전치 행렬 | (여기서는 깊게 다루지 않음) |
| np.sum() | [집계 함수] 배열의 합 | |
| np.mean() | [집계 함수] 배열의 평균 | |
| np.std() | [집계 함수] 배열의 표준편차 | |
| np.argmax(array, axis = n) | 가장 큰(작은) 인덱스 반환 | |
| np.where(조건문, 참일 때 값, 거짓일 때 값) | 조건에 따른 값 지정 |
기본 연산
x = np.array([[1, 2], [3, 4]])
y = np.array([[5, 6], [7, 8]])
print(x + y)
print(np.add(x, y))
print(x - y)
print(np.subtract(x, y))
print(x * y)
print(np.multiply(x, y))
print(x / y)
print(np.divide(x, y))
print(x % y)
print(np.remainder(x,y))
print(x ** y)
print(np.power(x, y))배열 집계
🔥axis = 0 : 열 기준 집계 (행 방향 집계)
🔥axis = 1 : 행 기준 집계 (열 방향 집계)
생략시 전체 집계
[보충설명]
2차원의 np의 형태는 (x, y) 이고 순서대로 axis0, axis1로 위에서 설명하였는데 axis=0이 왜 열의 기준 집계인지 혼동될 수 있다.
=> 위 '배열 이해' 그림에서 표시했듯이 x는 행이 맞지만 인덱스가 증가하는 방향(위->아래)가 되면 결과적으로 열의 합계가 된다.
a = np.array([[1,3,2,7]
,[3,2,9,1]
,[4,6,8,1]])
#전체 합계
print(np.sum(a))
#열 기준 합계
print(np.sum(a, axis= 0))
#행 기준 합계
print(np.sum(a, axis= 1)
#결과
47
[ 8 11 19 9]
[13 15 19]가장 큰/작은 인덱스 반환
📣 값이 아니라 인덱스 반환함을 기억하자!
# 전체 중에서 가장 큰 값의 인덱스
print(np.argmax(a))
# 열 기준 큰 값의 인덱스
print(np.argmax(a, axis = 0))
# 행 기준 큰 값의 인덱스
print(np.argmax(a, axis = 1))
#결과
6
[2 2 1 0]
[3 2 2]조건함수 where
a = np.array([1,3,2,7]) # 조건
np.where(a>2, 1, 0)
#결과
array([0, 1, 0, 1])