
DataFrame과 Sereis
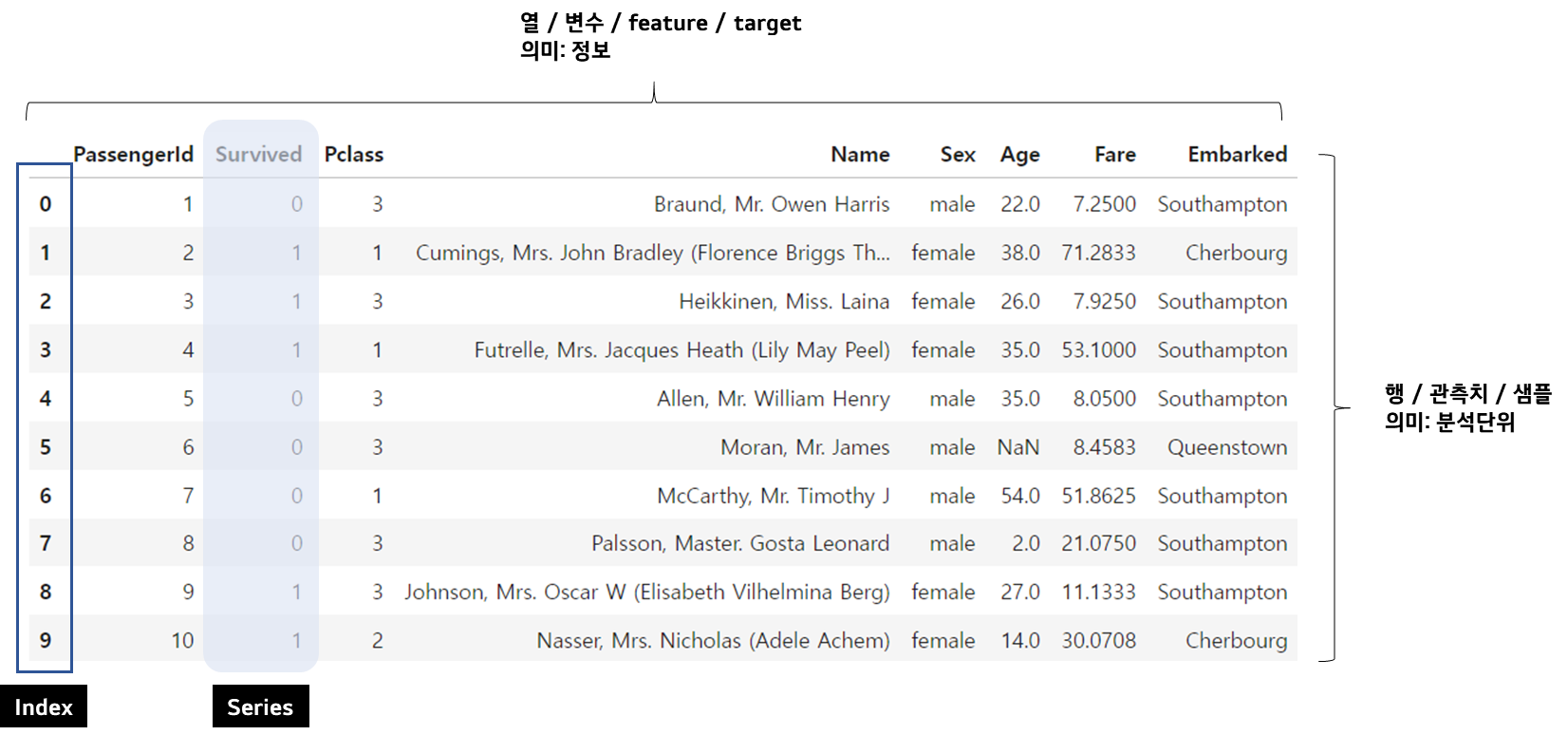
데이터프레임(DataFrame)란?
2차원 데이터 구조 형태
시리즈(Series)란?
하나의 정보에 대한 데이터들의 집합
데이터프레임에서 하나의 열을 떼어낸 것 (1차원!)
정보확인
| 메소드 | 의미 | 예시 |
|---|---|---|
| head() | 앞쪽 데이터 | df.head(10) |
| tail() | 뒤쪽 데이터 | df.tail(10) |
| shape | 데이터 행열의 개수 | df.shape |
| columns | 데이터 행열의 개수 | df.columns |
| dtypes | pandas.DataFrame 컬럼 타입 확인 | int64: 정수형 데이터(int) float64: 실수형 데이터(float) object: 문자열 데이터(string) |
| dtype | pandas.Series 컬럼 타입 확인 | |
| info() | 인덱스, 열, 값 개수, 데이터 형식 | df.info() |
| describe() | 기초 통계량 정보 | df.describe(), df.describe(include='all') #수치형 데이터 외에도 전부 출력 |
| unique() | 고유 값 | df['컬럼'].unique() |
| values | DataFrame을 Numpy로 변경 | df['컬럼'].values, df.values <리턴타입: numpy.ndarray> |
| value_counts() | 고유 값과 그 개수 확인 | df['컬럼'].value_counts(normalize=True) |
| df.select_dtypes() | 특정 데이터 타입만 df 추출 | df.select_dtypes(include='O') // include='object'와 동일 |
예제는 타이타닉 데이터를 사용하였다.
[titanic_simple 데이터 셋 정보]
- PassengerId : 승객번호
- Survived : 생존여부(1:생존, 0:사망)
- Pclass : 객실등급(1:1등급, 2:2등급, 3:3등급)
- Name : 승객이름
- Sex : 성별(male, female)
- Age : 나이
- Fare : 운임($)
- Embarked : 승선지역(Southhampton, Cherbourg, Queenstown)
data = pd.read_csv('경로') #csv파일인 경우
print(data.shape) #(891, 8)
print(data.columns) # <class 'pandas.core.indexes.base.Index'>
print(data.columns.values) # 'numpy.ndarray'>
#-------결과-----------
Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'Fare',
'Embarked'],
dtype='object')
['PassengerId' 'Survived' 'Pclass' 'Name' 'Sex' 'Age' 'Fare' 'Embarked']
print(list(data))
['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'Fare', 'Embarked']
print(data.dtypes)
#-------결과-----------
PassengerId int64
Survived int64
Pclass int64
Name object
Sex object
Age float64
Fare float64
Embarked object
dtype: object
print(data.info())
#-------결과-----------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 Fare 891 non-null float64
7 Embarked 889 non-null object
dtypes: float64(2), int64(3), object(3)
memory usage: 55.8+ KB
print(data.describe())
#결과는 생략
#속성별로 개수(count), 평균(mean), 표준편차(std), 최솟값(min), 사분위값(25%, 50%, 75%), 최댓값(max) 표시
print(data['Pclass'].unique())
#결과: [3 1 2]
print(data['Pclass'].value_counts())
#-------결과-------
3 491
1 216
2 184
Name: Pclass, dtype: int64
print(titanic[['Survived','Pclass']].value_counts())
# --- 결과 ---
Survived Pclass
0 3 372
1 1 136
3 119
0 2 97
1 2 87
0 1 80
dtype: int64🚀 데이터 정렬
sort_index()
- index기준으로 정렬
예시:data.sort_index(ascending=False)
reset_index()
- index 초기화 + index열 생성 , drop=False(default)
- index 초기화, drop = True
예시:data.reset_index(drop = True)
sort_values()
-
특정 열/속성을 기준으로 정렬
-
ascending: 오름차순, 내림차순을 설정할 수 있다.
- ascending=True: 오름차순 정렬(기본값)
- ascending=False: 내림차순 정렬
-
예시 (by는 생략가능)
data.sort_values(by='Age', ascending=False)
data.sort_values(by=['Age', 'Fare'], ascending=[True, False]):Age로 정렬하는데 Age가 같을 경우 Fare로 정렬하고 정렬기준도 각각 설정 가능하다.
🚀 조건 조회
특정 열 조회
1) 1차원 시리즈로 조회하기
- data['Age']
- data.Age
둘다 같은 방법이지만 상위 표현법 선호
2) 2차원 데이터프레임으로 조회
- data[['Age']]
- data[['Age','Gender']]
- ✖ data['Age','Gender'] 오류 발생
기본적으로 수행하는 컬럼이 여러개인 경우 리스트를 이용해 묶는다.
혹은 시리즈가 아닌 데이터프레임형태로 나타내고 싶을 때도 []를 묶어 2차원으로 변경한다.
조건으로 특정 열 조회 : .loc[행조건, 열이름]
✅ 행조건: 조건문
✅ 열이름: 생략가능
조회할 열 이름 1개면 시리즈
열 이름이 여러개면 리스트로 묶고 결과는 데이터프레임
1) 단일 조건
data.loc[data['Age'] > 10]
#data[data['Age'] > 10] # 와 결과는 같다.2) 여러 조건문인 경우
- and와 or 대신 &, | 를 사용한다.
- 조건들은 (조건1) & (조건2) 형태로 괄호로 묶는다.
data.loc[(data['Age'] > 10) & (data['Pclass'] == 4)]
#data.loc[(data['Age'] > 10) and (data['Pclass'] == 4)] #오류
#data.loc[(data['Age'] > 10) && (data['Pclass'] == 4)] #오류
2) isin()메소드 사용
* 주의 isin 안에는 리스트 형태로 입력해야 한다.
data.loc[data['Pclass'].isin([1,3])]
data.loc[ti['Embarked'].isin(['Southampton', 'Queenstown'])]3) between()메소드 사용
- between(값1, 값2, inclusive='both')
- both일때는 between(값1, 값2) 만 작성 가능
- inclusive = 'both'(기본값), 'left', 'right', 'neither'
data.loc[data['Age'].between(25, 30)] #범위: 25~30 (모두 포함)
data.loc[data['Age'].between(25,30,inclusive='left')] #범위: 25~29
data.loc[data['Age'].between(25,30,inclusive='right')] #범위: 26~30
data.loc[data['Age'].between(25,30,inclusive='neither')] #범위: 26~294) 조건에 맞는 일부 열 조회
data.loc[data['Age'] >= 40, 'Survived'] #1차원 시리즈
data.loc[data['Age'] >= 40, ['Survived']] #2차원 데이터프레임
data.loc[data['Age'] >= 40, ['Survived', 'Embarked', 'Age']]pandas.Series.str.contains
df[df['address1'].str.contains('망원동')]pandas.Series.str.extract
s = pd.Series(['a1', 'b2', 'c3'])
s.str.extract(r'([ab])(\d)')
0 1
0 a 1
1 b 2
2 NaN NaN🚀 기본 집계
| 메소드 | 예시 |
|---|---|
| sum() | data['Age'].sum() |
| count() | data['Age'].count() |
| min() | data['Age'].min() |
| max() | data['Age'].max() |
| mean() | data['Age'].mean() |
| median() | data['Age'].median() |
# 'Age', 'Fare' 각각 열 평균값 확인
print(data[['Age', 'Fare']].mean()) #avg가 아닌 mean()임을 주의한다!
# -----결과-----
Age 29.699118
Fare 32.204208
dtype: float64groupby() 함수
dataframe.groupby('집계기준변수',as_index=)['집계대상변수'].집계함수
-
as_index = True
집계기준변수가 인덱스 열로 사용 -
as_index = False
행 번호를 기반으로한 정수값 인덱스 설정 (따라서 보통 False로 많이 사용)
집계대상변수가 하나라도 데이터프레임으로 반환 (아래 예제 확인) -
집계대상변수를 지정하지 않으면, 집계기준 변수이외의 모든 열에 대한 집계가 수행된다. 그러나 사라질 가능성이 있다는 의미의 경고가 뜬다.
-
집계기준변수, 집계대상변수, 집계함수 모두 여러개의 값으로 추출할 수 있다.
집계함수가 여러 개 일때는.agg()를 사용한다.
# 목표: 성별별로 나이의 평균 구하기
data.groupby('Sex', as_index=True)['Age'].mean()
# --- 결과 ---
Sex
female 27.915709
male 30.726645
Name: Age, dtype: float64
data.groupby('Sex', as_index=True)[['Age']].mean()
# --- 결과 ---
Age
Sex
female 27.915709
male 30.726645
data.groupby('Sex', as_index=False)['Age'].mean()
#--- 결과 ---
Sex Age
0 female 27.915709
1 male 30.726645
# 목표: 성별별로 나이와 지불요금의 평균 구하기 (집계대상변수가 여러개)
data.groupby('Sex', as_index=False)[['Age','Fare']].mean()
Sex Age Fare
0 female 27.915709 44.479818
1 male 30.726645 25.523893
# 목표: 성별, 생존여부 별로 나이와 지불요금의 평균 구하기 (집계기준변수, 집계대상변수 여러개)
data.groupby(['Sex','Survived'], as_index=False)[['Age','Fare']].mean()
# ---- 결과 ----
Sex Survived Age Fare
0 female 0 25.046875 23.024385
1 female 1 28.847716 51.938573
2 male 0 31.618056 21.960993
3 male 1 27.276022 40.821484
# 집계함수가 여러 개인 경우
data.groupby(['Sex','Survived'], as_index=False)[['Age','Fare']].agg(['mean', 'min', 'max'])
# --- 결과 ---
Age Fare
mean min max mean min max
Sex Survived
female 0 25.046875 2.00 57.0 23.024385 6.750 151.5500
1 28.847716 0.75 63.0 51.938573 7.225 512.3292
male 0 31.618056 1.00 74.0 21.960993 0.000 263.0000
1 27.276022 0.42 80.0 40.821484 0.000 512.3292